一种基于实时流式计算的数据平台系统的制作方法
本发明涉及计算机互联网数据仓库设计技术,尤其涉及一种基于实时流式计算的数据平台系统。
背景技术:
实时流式计算是对数据流进行分段操作,分解成一系列短小的批处理作业,然后将分段的数据流传输到数据批处理引擎中,在数据引擎中对数据进行清洗、提取、转化操作,并将得到的数据处理结果保存在内存中。
传统标准化的数据仓库,主要利用oracle的定时任务以及触发器、分区表等机制对入库数据进行准实时统计分析,在性能和功能方面,已经难以满足用户对数据处理分析的及时性、准确性的需求。
随着互联网的飞速发展,大数据时代已经到来,数据呈现爆炸式增长,传统数据处理模式已经不适用对海量数据的分析,需要一种新的数据处理方式来实时处理复杂业务逻辑。
技术实现要素:
本发明要解决的技术问题是建立一套成熟的实时流式计算系统,可以快速有效的提供精准的数据服务。为了解决上述技术问题,本发明提供了一种基于实时流式计算的数据平台系统,包括数据源模块、实时数据计算模块、数据看板展示模块和作业调度管理平台;
其中,所述数据源模块负责配置数据源连接信息,抽取业务需要计算和实时同步的数据;
所述实时数据计算模块负责实时数据计算和存储,并负责每个节点的资源管理和调度;
所述数据看板展示模块用于交互分析;
所述作业调度管理平台负责工作流的配置、实时计算调度任务的正常运行以及定时调度工作流,确保数据的准确性。
所述数据源模块包括数据量模块和数据来源模块;
所述数据量模块用于区分数据是否需要进行初始化,当数据量的大小小于10w+数据时,只需要把数据进行同步,全表加载数据,不需要初始化;
所述数据来源模块包括结构化数据。例如:oracle数据库、mysql数据库、结构化文件、hive表等以及业务需要计算和实时同步的数据,比如:销售额、销售订单、会员数、凭证数等;
所述实时数据计算模块包括实时数据同步模块、yarn分布式管理系统、数据存储模块和数据计算模块;
所述实时数据同步模块包括数据量模块和数据来源模块;
所述数据量模块和数据来源模块的功能与数据源模块中的功能相同;
所述yarn分布式管理系统用于集群各个节点的资源调度,以便达到高效的资源管理,例如:当数据需要存储时,yarn分布式管理系统上的主节点reourcemanager会根据从节点nodemanager的资源请求,来合理分配资源;
所述数据存储模块用于通过sparksql微批处理抓取数据到hdfs(hadoop分布式文件系统)上进行同步,并存储在内存中,通过处理,最后数据存在集群的各个节点中;
所述数据计算模块用于将集群内存中的数据通过注册成临时表,并利用sql语句来进行逻辑计算,例如:把数据从数据源实时微批抽取到hive后,利用sql语句把数据进行筛选以及和其他表进行关联和计算,从而得到需要的指标数据;
所述数据看板展示模块包括交互分析模块、报表展示模块和权限控制模块;
所述交互分析模块用于数据集的逻辑计算以及根据不同的维度、不同的主题进行分析和处理,例如:同一张表的数据,根据时间维度,把数据按天进行统计和指标计算,或者按照地区维度,根据不同省份,来进行划分,已达到不同的数据集,完成不同的报表;
所述报表展示模块用于将数据通过不同的数据图表来展示,例如:柱状图、曲线图、文本框等。
所述权限控制模块用于控制每张报表查看和修改的权限,对不同的业务方给与相对应的权限。
所述作业调度管理平台模块用于spark任务准实时调度管理;
所述spark任务准实时调度管理包括workflow配置、coordinator配置、工作流监控管理;工作流能够并行调度,也能够串行调度,工作流允许失败重刷机制,能够重新开始执行工作流调度;
所述workflow配置用于调度运行spark任务,每个spark任务都需要配置一个作业,同一类别的作业需要配置一个工作流,且多个工作流并行调度过程中,一个spark任务失败不会影响到同一个工作流中的其他任务运行;
所述coordinator配置用于管理工作流的定时调度,需要指定相对应的一个工作流以及调度时间、调度的频率;
所述工作流监控管理用于监控每个spark任务运行的状态和时间。
所述数据存储模块用于通过sparksql微批处理抓取数据到hdfs上进行同步,在hdfs上同步的数据是一个dataframe(结构化数据集),它能够注册成临时表,以便使用sql进行操作。
所述yarn分布式管理系统负责集群资源管理和调度,用于将数据源模块的数据分布式存储在hdfs上的每个节点上以及每个节点资源的调度。
所述在hdfs上分布式存储的数据通过映射到greenplum的外部表。
所述greenplum外部表的数据通过存储过程,进行逻辑计算,插入到greenplum内部表。
所述所述greenplum外部表的数据通过存储过程,进行逻辑计算,插入到greenplum内部表,包括如下步骤:
步骤1,利用sparksql微批抽取数据源模块的数据;
步骤2,把抽取的数据注册成临时表;
步骤3,把临时表的数据插入到hive外部表中;
步骤4,通过hive外部表把数据映射到greenplum外部表中;
步骤5,greenplum外部表通过存储过程把数据进行逻辑计算之后(逻辑计算通过sql语句完成),插入到greenplum的内部表;
步骤6,把内部表的数据写到数据集中,通过报表展示。
本发明具有以下控制优点:
利用sparksql获取预定数据的行为数据信息并存储,将所述预定数据转换成一系列短小的数据流,可以实现高吞吐量的、具备容错机制的实时流数据的处理,将大批量数据转换成微批量数据,并通过分布式方式对数据进行快速计算,达到吞吐量大、低延迟的效果;
所述yarn分布式管理系统用于负责集群各个节点的资源调度,以便达到资源利用的最大化;
分布式数据存储系统通过网络使用每台服务器上的磁盘空间,将分散的存储资源构成一个虚拟的存储设备,数据分散存储在网络中的各个角落,以达到资源效率高、安全性高的特点;
实时数据计算将数据转化成rdd数据集缓存到内存中,由于频繁使用到数据集,减少了中间结果的io操作、网络传输、重新计算的时间,显著地提高了应用运行的速度,达到准实时数据的同步和计算;
交互分析模块根据不同的需求,可以指定不同的维度和主题,来完成相对应的报表;
权限控制模块控制不同用户、不同报表的权限,可以根据用户的需求,对用户和报表设置相对应的权限,达成用户可以看到与自己相关联的;
作业监控:通过作业、作业名称、状态(就绪、成功、运行、失败、告警),实时查看作业运行状态,通过重置按钮实现作业重跑。
附图说明
下面结合附图和具体实施方式对本发明做更进一步的具体说明,本发明的上述或其他方面的优点将会变得更加清楚。
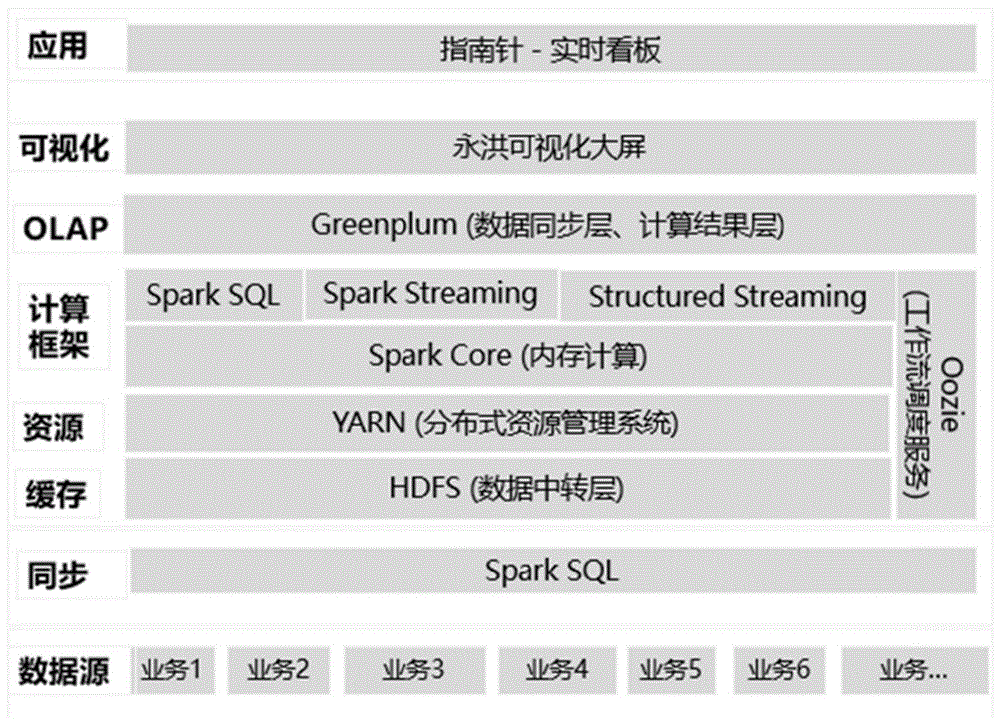
图1是本发明系统架构图。
具体实施方式
下面结合附图及实施例对本发明做进一步说明。
如图1所示,本发明公开了一个基于实时流式计算涉及的数据平台系统,是一种准实时数据同步和计算的系统,包括数据源模块、实时数据计算模块、数据看板展示模块、作业调度管理平台;
数据源模块:数据量和数据来源;
实时数据计算模块:实时数据同步模块、yarn分布式管理系统、数据存储、数据计算;
数据看板展示模块:交互分析模块、报表展示模块、权限控制模块;
作业调度管理平台:workflow配置、coordinator配置、工作流监控管理;
1、数据源模块
负责配置数据源连接信息,抽取业务需要计算和实时同步的数据;
1.1数据量
数据源的数据量较小时,可以采取每次抽取全部数据进行数据同步和计算,当数据量较大时,先抽取所有数据同步和计算,进行初始化,在后续的数据同步和计算过程中,采取往回刷一段时间的方式,实现数据实时同步;
1.2数据来源
数据来源包括结构化数据,例如:oracle数据库、mysql数据库、结构化文件、hive表等;
2、实时数据计算模块
负责实时数据计算和存储以及每个节点的资源管理和调度;
3、实时数据同步模块
实时数据同步模块利用sparksql把数据源中指标所需要的部分字段数据微批处理,实时同步到hdfs上。
4、yarn分布式管理系统
yarn分布式管理系统由resourcemanager和applicationmaster组成,resourcemanager负责整个集群的资源管理和调度,而applicationmaster负责应用程序的相关事务,比如任务调度、任务监控和容错等;
5、数据存储
数据存储由数据缓存和数据储存组成,当数据抽取到hdfs上,数据缓存在服务器的内存中,最后数据存储在服务器的各个节点上。
6、数据计算
缓存在服务器内存中的数据,通过dataframe注册成临时表,利用sql语句进行复杂的逻辑计算,结合hive外部表和greenplum外部表,解决大量数据加载速度慢的问题,以及各个系统之间数据类型不一致的问题,通过hive外部表将数据映射到greenplum外部表中,在通过调用存储过程将数据插入到计算结果层greenplum内部表中;例如:greenplum外部表通过调用存储过程,利用sql来进行复杂的逻辑计算;
7、数据看板展示模块
负责数据的交互分析模块、报表展示模块以及报表的权限控制模块;
8、交互分析模块
交互分析模块是数据在数据集中按照不同的维度、主题,进行不同的分类,从而完成;
9、报表展示模块
报表展示模块由制作报表和报表展示两部分组成,根据数据集中的指标数据,在制作报表时,直接可以把数据集中的数据进行拖拉拽,用柱状、曲线、文本框等形式展示,
根据不同的需求,设置刷新页面的时间间隔;
10、权限控制模块
权限控制模块设置用户查看报表的权限,设置用户可查看只与用户相关的报表,其他的报表不显示在用户可查看的界面中;
11、作业调度管理平台
负责工作流的配置、实时计算调度任务的正常运行以及定时调度工作流,确保数据的准确性
12、workflow配置
oozie中配置workflow,一个作业配置一个sparkprogram,一个工作流中可配置多个作业并发处理,在配置中需要导入数据源的连接包,以及项目的jar包,多个作业并发处理时,运行的状态互不影响;
13、coordinator配置
oozie中配置coordinator,先选定需要定时调度的工作流,设置定时调度的开始时间、结束时间以及定时调度的频率;
14、工作流监控管理
工作流监控管理由工作流运行状态和spark任务运行状态组成,工作流通过定时调度启动后,spark任务开始运行,通过工作流和任务名称,查看spark任务的运行状态、时间,也可查看spark任务运行的日志文件;
本实施例中,开发部署环境如下:
开发环境:
scala版本:2.10.5
spark复用现有的cdh组件
ide:idea
部署环境:
scala版本:2.10.5
spark版本:1.6.0
zookeeper版本:3.4.5
mysql版本:5.1.4
oracle版本:10g
greenplum版本:5.7.0
流式计算系统服务器部署位置见下表1:
表1
实施例
本实施例中,设定oracle数据库中某张表有260m的数据(如表2所示,是某公司销售数据),
表2
表2中,第一列orderno表示订单号,第二列memberno表示会员号,第三列totalprice表示总价,第四列orderstatus表示订单状态,第五列orgid表示所属组织编号,第六列operatorid表示操作人编号;
通过数据源模块,配置oracle数据库连接信息,包括用户名、密码、oracle驱动等,由于数据量较大,已达到120w行,需要先进行数据初始化过程,然后在进行数据同步过程;
数据初始化过程,是先利用sparksql微批抽取oracle中的所有数据;通过数据计算模块,将抽取的数据存储在内存中,转化为一个数据集,通过注册成临时表,插入到hive中,通过数据存储模块,将数据存储在服务器的各个节点上,通过yarn分布式管理系统模块,把集群的每个节点进行资源的合理分配,通过hive外部表的映射特性,将数据映射同步到greenplum的外部表中,通过调用存储过程,利用sql将外部表的数据进行所需要的逻辑处理,包括和其他表的关联、条件筛选、逻辑计算等,然后将数据插入到greenplum内部表中;
数据同步过程,也是先利用sparksql微批抽取oracle中的数据,不过是抽取当前时间往回刷一天的数据,然后接下来的过程和初始化的过程相同,不过每次都需要先清空hive外部表、greenplum外部表,然后再将数据插入进来;每次数据同步过程都是一次调度,需要通过作业调度管理平台来调度,一个作业调度需要配置代码执行的jar包、连接库的jar包、调度资源的分配、定时调度的时间等;处理完之后的结果数据,通过数据看板展示模块的交互分析模块,利用数据集将数据进行不同维度的处理,例如:以时间维度(根据不同的时间段将数据进行分类)、或者以地区维度(根据不同的地区,将数据进行分类)等,通过权限控制模块,控制每张报表、不同用户的权限,通过报表展示模块将数据进行可视化展示。
本发明提供了一种基于实时流式计算的数据平台系统,具体实现该技术方案的方法和途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。本实施例中未明确的各组成部分均可用现有技术加以实现。
- 还没有人留言评论。精彩留言会获得点赞!