一种基于节点表示的主题社团发现方法与流程
本发明涉及一种主题社团发现方法,具体涉及一种基于节点表示的 主题社团发现方法。
背景技术:
随着社交媒体的迅速发展,在线社交网络对人们的信息获取、思考 及生活方式等诸多方面都在产生着不可低估的影响。社交网络已成为我 们生活中重要的一种信息载体和形式,具有很高的研究价值.,对它的分 析能够应用于节点分类、链接预测、社团发现等任务。同时,人们在社 交网络中参与的社团活动也在快速地增长,有共同兴趣爱好的用户会在 一起分享自己的想法、观念以及专业见解,交互共同的话题内容,形成 主题社团。它能帮助研究者了解用户的兴趣特点,辅助进行个性化服务、 社会推荐等任务。在市场营销、选举、股票指数等诸多现实的应用场景 中,主题社团都体现着它的意义和重要性。
目前的社团发现方法可总结为以下三类:(1)基于用户之间链接关 系的社团发现方法。这种方法通常从拓扑结构考虑,利用图论的基本思 想划分网络来发现社区,如图划分、层次聚类、谱聚类等算法。(2)基 于用户生成内容的社团发现方法。基于用户本身属性、文本内容等信息 将用户聚类从而识别出潜在的社团。此类方法不考虑用户之间的链接关 系,只借助用户产生的内容。(3)基于链接关系和文本内容的社团发现 方法。该类方法同时考虑用户之间的关系以及用户产生的内容聚类并发 现潜在社团,以往的主题社团发现方法大多以概率模型为基础建模,然 而没有考虑用户节点向量、社团向量及社团发现实现主题社团的发现
技术实现要素:
本发明的目的在于克服上述现有技术的缺点,提供了一种基于节点 表示的主题社团发现方法,该方法能够综合考虑用户节点向量、社团向 量及社团发现实现主题社团的发现。
为达到上述目的,本发明所述的基于节点表示的主题社团发现方法 包括以下步骤:
1)基于用户文本模型和社交关系模型对用户节点进行表示;
2)利用用户文本模型及社交关系模型中的用户节点特征,建立基于 节点向量、社团向量及社团发现共同优化的主题社团发现模型,并利用 基于节点向量、社团向量及社团发现共同优化的主题社团发现模型进行 主题社团的发现;
3)基于步骤2)得到的主题社团发现的结果,将每个用户节点划分 到不同的社团中,再通过作者主题模型得到每个用户的主题分布特征, 然后利用每个用户的主题分布特征对所有用户的主题分布取均值,进而 得到每个社团的主题特征,完成基于节点表示的主题社团发现。
所述基于用户文本模型和社交关系模型对用户节点进行表示包括基 于文本学习进行用户特征的表示、基于社交关系进行用户特征的表示以 及基于用户的文本与社交关系进行用户特征的表示。
基于文本学习进行用户特征的表示的具体过程为:
对于每个用户vi∈V,设为用户发布的文本构成的 词序列,NS为S中词的个数,C(w)为词w的前t个词所构成的上下文,设 每个词wi生成的概率与与其邻接词组成的上下文C(wi)及其所属文本的 用户vi有关,则有:
其中,k维向量表示需要学习的用户vi的特征向量,
每个词wi在用户文本模型中以词向量作为输入, 为词典集合,xAvg为上下文中所有词的词向量以 及用户的特征向量的加和平均,用户的特征向量与词向量维度相同;
给定用户vi,则其所有文本texti生成的概率为:
以使得式(3)计算得到的概率最大化为目标,建立目标函数为:
令用户的特征表示的 梯度为:
基于社交关系进行用户特征的表示的具体过程为:
设Gi={v|g(v,vi)=1}表示与用户vi有社交关系的其他用户的集合, g(v,vi)=1表示用户vi与用户v是朋友,在社交网络中用户vi与用户v对应的 节点有边相连,g(v,vi)=0表示用户vi与用户v之间不存在联系,P(Gi|vi)为 用户vi的社交关系的似然概率,则有:
其中,表示用户vi作为社交关系模型输入去预测其他用户时的向量 表示,φ′v为用户vi社交关系中用户v作为被预测对象时的向量 表示,
以使得式(11)计算得到的概率最大化为目标,建立目标函数为:
令则将用户vi社交关系 中每个用户v对应向量表示φv的梯度更新为:
基于用户的文本与社交关系进行用户特征的表示的具体过程为:
基于用户的文本与社交关系,得最终的目标函数为:
其中,Φ为用户作为输入时的向量表示,Φ′为用户作为被预测对象 时的向量表示,E为所有用户的文本信息构成的语料中所有词构成的词向 量矩阵,E′为词作为被预测对象时的词向量矩阵。
设G=(V,E)表示社交网络,V为社交网络中节点的集合,E为边的集 合;
设社交网络G中包含K个社团,对于每个节点vi∈V,zi为其所属社团 编号,zi∈{1,2,...,K},基于高斯混合模型,设定一个社团k的向量表示为 低维空间中的一组向量(ψk,∑k),其中,k∈{1,2,...,K},为高斯混 合模型的均值向量,为高斯混合模型的协方 差矩阵;
对于每个节点向量φi,其所属社团zi=k,则其由社团k对应的多元 高斯分布产生,对于在节点集合V中的所有节点,建立如式(21) 所述的似然概率,其中,:
其中,p(zi=k)表示节点vi属于社团k的概率,记为在社团发现的过程中,πik属于隐变量,p(vi|zi=k;φi,ψk,∑k)表 示从社团k对应的高斯分布生成节点vi的概率,其中,
使用EM算法对式(20)中的参数进行求解,得每个节点vi属于每个 社团k的概率πik以及每个社团对应的子高斯分布的参数(ψk,∑k)。
对任意一个节点vi,其文本信息为texti,wj∈texti为其文本的单词, 节点vi的优化目标为:
其中,表示词wj作为被预测对象时的向量表示,为用 户节点向量φi与词wj的上下文中的词向量加和平均,即:
wl~Pn(wl)表示对任意负样本词wl进行负采样,对所有训练样本节 点,通过最小化式(25)所述的目标函数来学习保存文本语义信息的节 点表示,即
考虑节点的社交网络的结构特征,采用DeepWalk算法对每一个节点 通过随机游走的方式生成节点序列,设对任意一个节点vi,其上下文为Ci, vj∈Ci为其上下文中的节点,则其优化目标为:
其中,表示节点vi向量表示,表示其上下文的向量表示, vl~Pn(vl)表示负采样过程,即对任意负样本节点vl以概率Pn(vl)进行采样, 对所有训练样本节点,通过最小化式(27)所示的目标函数来学习保存 网络结构信息的节点表示,即
其中,α为超参数,α>0;
对式(21),定义通过式(28)所示的目标函数来实现社团发现以及 社团向量的优化,同时增强节点向量表示的社团关系特征,即
其中,β为超参数,β>0;
结合用户节点表示优化以及社团发现与社团节点表示过程的优化, 建立最终的目标函数为:
其中,E={e}为单词作为输入时的词向量矩阵,E′={e′}为单词作为 被预测对象时的词向量矩阵,Ф={φi}为用户节点的向量矩阵,Ф′={φ′i} 为上下文用户节点的向量矩阵,П={πik},Ψ={ψk},∑={∑k}, i=1,2,...,|V|,k=1,2,...,|K|;
则将最终的目标函数转变为:
其中,diag(∑k)返回的是∑k的对角元素,约束diag(∑k)>0的作用为避 免在优化时的奇点问题。
本发明具有以下有益效果:
本发明所述的基于节点表示的主题社团发现方法在具体操作时,通 过建立基于节点向量、社团向量及社团发现共同优化的主题社团发现模 型,并该主题社团发现模型进行主题社团的发现,然后通过作者主题模 型得到每个用户的主题分布特征,并以此获取每个社团的主题特征,操 作方便、简单,解决了社交网络中的节点表示、主题社团发现及主题社 团主题特征表示的问题,可以为个性化服务、社会推荐及用户画像等研 究提供用户特征方面的支持。
附图说明
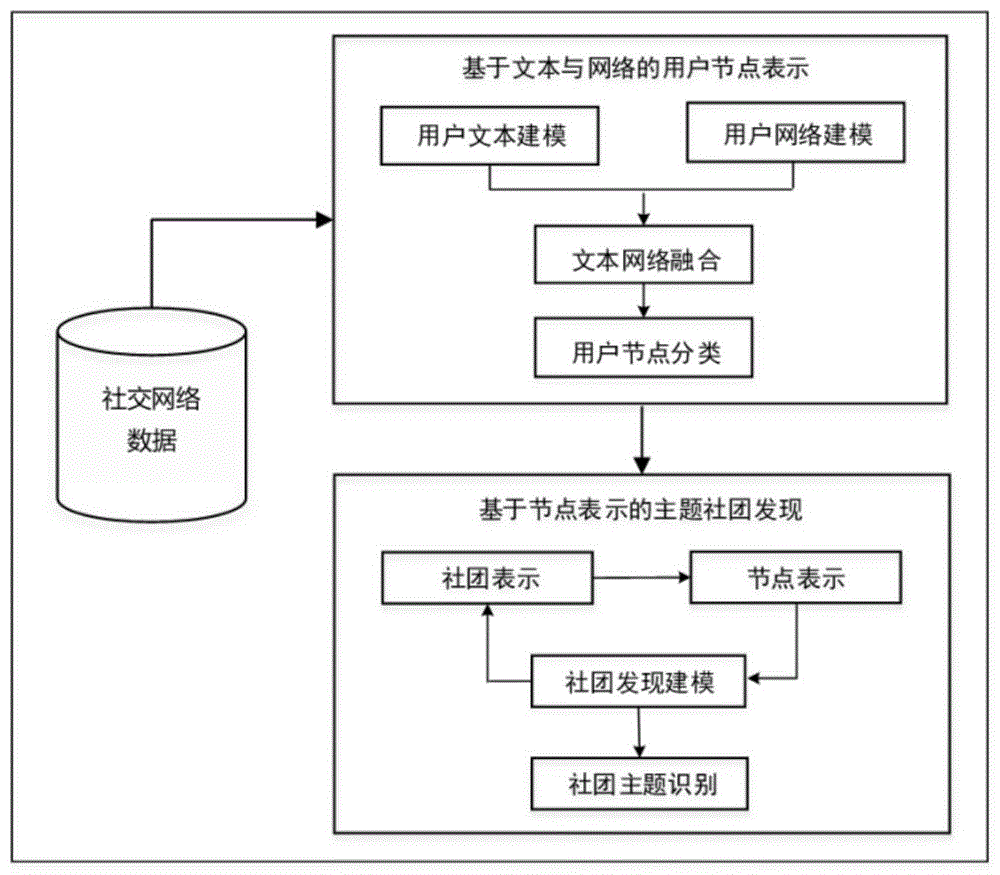
图1为本发明的流程框图;
图2为本发明中用户节点表示的处理流程图;
图3为本发明中基于文本学习用户特征表示的模型图;
图4为本发明中词根据词频映射到线段的映射示意图;
图5为本发明中基于网络学习用户特征表示的模型图。
具体实施方式
下面结合附图对本发明做进一步详细描述:
参考图1至图5,本发明所述基于节点表示的主题社团发现方法包 括以下步骤:
1)基于用户文本模型和社交关系模型对用户节点进行表示;
具体的,在社交网络中,用户发布的文本信息以及用户的社交关系 所形成的网络结构是反映用户特点最重要的两个信息来源。本发明通过 结合所述两个信息来源建立优化模型,进而学习能刻画和反映每个用户 特性的特征表示。
图2为本发明中用户节点表示方法的处理流程图,其主要包含数据 预处理、用户节点表示学习模型构建以及针对用户的分类任务,数据预 处理阶段包括:a)利用自然语言处理技术去除文本中的噪声,以提高文 本分析的效果,b)形成用户之间的网络结构,经过预处理之后,文本数 据作为用户节点表示模型中文本建模方法的输入,社交关系数据转换为 以每个用户的社交关系为一组的节点序列,作为网络建模方法的输入, 通过文本和网络两个层面建立优化目标并统一优化和训练,从而学习到 用户的节点表示,并通过多个节点分类任务验证模型效果。
11)基于用户文本的节点表示
用户生成的文本信息能够反映出用户的兴趣和关注点、个人背景以 及个性特点,因此,基于用户文本学习到的特征表示能较好刻画出用户 的这些特征。
对于每个用户vi∈V,设为用户发布的文本构成的 词序列,NS为S中词的个数,C(w)为词w的前t个词所构成的上下文,设 每个词wi生成的概率不仅依据语言模型的特点由其邻接词组成的上下文 C(wi)决定,同时还与其所属文本的用户vi有关,则有:
其中,k维向量表示要学习的用户vi的特征向量,每个 词wi在模型中以词向量作为输入,为词典集合,xAvg为上 下文中所有词的词向量以及用户的特征向量的加和平均,用户的特征向 量与词向量维度相同,它们来自于两个不同的向量空间。在预测每个单 词的概率时,模型都利用了用户文本段落的语义。一个用户对词的选择 不仅受到其上下文的影响,还会与用户本身的特征表示有关,这种假设 反映了社交网络的同质性,即向量表示相近的用户,其产生的文本信息 也更相似。因为用户的特征信息可以从他们发布的文本中体现出来,而 根据用户的特征表示预测用户产生的文本时,单词预测产生的误差会影 响用户特征表示的学习,图3为基于文本学习用户特征表示的模型图。
给定用户vi,则用户vi所有文本texti生成的概率为:
设以使得式(3)概率最大化为优化目标,建立目标函数为:
在计算式(2)时,每个词的计算都需要遍历这个词典,这样会带来 大量的计算开销,很可能无法在有效时间内得到结果。在Word2Vec模型 中,Mikolov采用层次Softmax与负采样两种优化方法加快模型的训练 速度。本发明使用负采样方法优化模型,以近似求解模型参数。负采样 是从噪声对比估计(Noise Contrastive Estimation)简化而来,它将 以Softmax函数形式预测目标词概率的计算转换为一个区分目标词(正 样本)和噪声(负样本)的二分类问题,采用Sigmoid函数避免了枚举 所有单词时带来的时间损耗,并以最大化正样本概率和最小化负样本概 率的方式建立优化目标。
设用户vi和词wi的上下文为C(wi),词w为正样本,词典中除去词w以 外的其他词为负样本,设已选取好关于词w的负样本子集Neg(wi),式(3) 可以改写为:
令对e′u求导:
其中,对e′u的梯度更新为:
对xw求导,得:
输入的上下文中每个词的词向量ew′,w′∈C(w)梯度更新为:
将用户的特征表示的梯度更新为:
负采样的过程中应保证高频词选中的概率较大,低频词选中的概率 较小,因此可以通过带权采样的方法实现,具体采样的实现方式可理解 为:将长度为1的线段根据词频按比例分配给词典中的每个词,每个词 对应线段长度为:
在Word2Vec中,词频取3/4次幂,即:
这是一种平滑策略,能够增大低频词被选到的概率,本发明通过借 鉴Word2Vec的负采样方法实现对语料中负样本的采样。
在采样前,先将长度为1的线段等分为M段且M>>V,这样能够确保每 个词对应的线段都会被划分为1/M个的小段,且每个等分的小段都会落到 某个词对应的线段上,然后建立M个等分段与词对应线段长度之间的映 射。
图4为映射示意图,其中,j为词在词 典中的编号索引,以为分割点可将区间[0,1]划分为多个非等分段 Ii=(li-1,li],i=1,2,...,N,即每个词wi所对应的线段长度,将等分节点 投影到非等分段上,则可建立映射为:
Table(i)=wk,where mi∈Ik,i=1,2,...,M-1.
在采样时,每次生成一个在[1,M-1]之间的随机数r,Table(r)就对应 一个负样本,当采样到正样本时,直接跳过。
12)基于社交网络结构的用户节点模型
在社交网络中,用户之间通常因有共同的兴趣偏好和关注点而产生 联系,形成社交关系。因此,用户之间的社交关系对于学习用户的特征 表示也发挥着重要的作用。
本发明将词向量学习中最大化同一窗口中词共现概率的思想应用到 用户与它的社交关系中,即有朋友关系的用户可以看作是句子中出现在 同一窗口中的邻近词,它们的特征表示更相似,而那些没有朋友关系的 用户则相当于不共现的单词,它们的特征表示差异更大,通过最大化目 标用户节点和其上下文中节点在一个随机窗口内共现的概率,学习用户 的特征表示。
设Gi={v|g(v,vi)=1}表示与用户vi有社交关系的其他用户的集合。 g(v,vi)=1表示用户vi与用户v是朋友,在社交网络中用户vi与用户v对应的 两个节点有边相连;g(v,vi)=0则表示用户vi与用户v之间不存在联系。 P(Gi|vi)为用户vi的社交关系的似然概率,则有:
其中,表示用户vi作为模型输入去预测其他用户时的向量表示, φ′v为用户vi社交关系中的用户v作为被预测对象时的向量表 示,图5为基于网络学习用户特征表示的模型图。
以使得式(11)计算的概率最大化为目标,建立目标函数为:
由于模型需要遍历所有的用户样本,在任意一个社交关系中的两个 用户vi与vj都需要计算P(vi|vj)+P(vj|vi),这和通过用户vi的社交关系Gi中 的每个用户v去预测用户vi本身的方式实际是等价的,因而式(12)可改 写为:
采用负采样方法对目标函数进行优化,对于社交关系Gi中的每个用 户v,用户vi为正样本,其他用户为负样本,设已选取好关于词vi的负样 本子集Neg(vi),则希望最大化为:
通过最大化式(14)来逼近概率P(vi|v),其中,
若u为被预测的用户vi,则为正例,Yu=1,否则为负例,Yu=0。对 于所有用户样本,优化后的目标函数为:
令对φ′u求导,得:
将φ′u的梯度更新为:
根据对称性,可直接得出对φv的结果为:
用户vi社交关系中每个用户v对应向量表示φv的梯度更新为:
13)基于用户文本和社交网络关系的用户节点模型
基于用户的文本与社交关系两部分,建立目标函数为:
其中,Φ为用户作为模型输入时的向量表示,Φ′为用户作为被预测对 象时的向量表示,E为所有用户的文本信息构成的语料中所有词构成的词 向量矩阵,E′为词作为被预测对象时的词向量矩阵,其均作为辅助参数 用于对Φ的求解,通过极大似然估计的方法建立整体的优化目标,并利用 随机梯度上升求解模型参数。
本发明提出的利用文本和网络学习用户节点表示算法的具体流程如 下:
2)基于节点表示的主题社团发现
在网络表示学习中,相似的两个节点在向量空间中会被映射到相近 的位置上。节点的表示保留了网络结构信息,对于结合文本学习的模型, 得到的节点表示同时还能够体现出用户的兴趣或所关注话题等信息。在 本发明中为社团也建立低维的向量表示,使其能够反映出每个社团的特 性。由于社团是由一组联系紧密的节点组成的,社团的向量表示建模需 要能够在低维向量空间中刻画出节点在社团中的分布特点,应通过定义 一个在低维空间上的分布来实现,选择高斯混合模型来刻画节点与社团 之间的分布关系,即每个社团向量可看作是在低维空间上的一个多元高 斯分布,在通过高斯混合模型生成每个社团中节点的过程中,学习社团 的向量表示参数。对于节点而言,其向量表示隐含着它自身在文本语义 上体现出的话题特性以及链接关系所反映的结构特性,有利于帮助提高 社团发现的效果,基于此,本发明将节点的向量表示学习、社团发现过 程及社团向量表示学习三部分结合在一起形成闭环,由节点表示促进社 团发现,由社团发现的结果获知社团向量,再由社团向量优化节点的向 量表示,通过多次迭代,不断循环优化,最终得到社团发现结果。
如图1所示的数据流程图,主要包括社团发现与社团向量表示学习、 用户节点表示学习以及模型融合,社团主题建模四个模块。
设G=(V,E)为一个社交网络图结构,V为社交网络中节点的集合,E 为边的集合,设社交网络G中包含K个社团,对于每个节点vi∈V,zi为其 所属社团编号,zi∈{1,2,...,K},基于高斯混合模型,一个社团的向量表 示被作如下定义。
定义1,一个社团k(k∈{1,2,...,K})的向量表示为低维空间中的一 组向量(ψk,∑k),其中,为高斯混合模型的均值向量, 为高斯混合模型的协方差矩阵。
学习目标为:1)为每个节点vi学习节点向量表示2)为 社交网络中的每个节点vi分配其所属每个社团k的概率 3)每个社团k的向量表示(ψk,∑k)。
21)社团发现与社团向量表示
本发明使用高斯混合模型对社团发现过程进行建模,使用高斯混合 模型进行社团发现时,每个社团对应一个子高斯分布,观测到的网络中 的每个用户节点是由其所属社团对应的高斯分布产生,形式化地,对于 每个节点向量φi,其所属社团zi=k,则其由社团k对应的多元高斯分布 产生,对于在节点集合V中的所有节点,可建立如下似然概率:
其中,p(zi=k)表示节点vi属于社团k的概率,记为在社团发现的过程中,πik确定着每个节点所属的社团,πik为 未知的,即πik属于隐变量,p(vi|zi=k;φi,ψk,∑k)表示从社团k对应的高斯 分布生成节点vi的概率,即:
社团向量参数(ψk,∑k)同样未知,使用EM算法对式(22)中的参数进 行求解,得每个节点vi属于每个社团k的概率πik以及每个社团对应的子 高斯分布的参数(ψk,∑k),即为社团发现的结果以及每个社团的向量表示。
22)节点表示优化
对于节点而言,基于网络结构学习的节点向量表示有利于从结构特 性上帮助提高社团发现的效果。在主题社团中,除了考虑用户之间的链 接关系,还需要挖掘出用户之间话题、兴趣等内在相关性,因此,用户 节点的向量表示还应保留语义层面的特征。
对于用户节点的语义特征,模型采用基于文本建模学习用户节点表 示的方法来保留语义信息。对任意一个节点vi,其文本信息为texti, wj∈texti为其文本的单词,其优化目标为:
其中,表示词wj作为被预测对象时的向量表示,为用 户节点向量φi与词wj的上下文中的词向量加和平均,即:
wl~Pn(wl)表示对任意负样本词wl进行负采样,负采样方法同3.3.1 所述。对所有训练样本节点,通过最小化如下目标函数来学习保存文本 语义信息的节点表示:
考虑节点的网络结构特征,模型采用DeepWalk算法对节点的建模方 式,对每一个节点通过随机游走的方式生成节点序列,将节点序列作为 伪句子应用Skip-gram模型学习节点的向量表示,对任意一个节点vi, 其上下文Ci,vj∈Ci为其上下文中的节点,其优化目标为:
其中,表示节点vi向量表示,表示节点vi上下文的向量 表示,vl~Pn(vl)表示负采样过程,即对任意负样本节点vl以概率Pn(vl)进 行采样,对所有训练样本节点,通过最小化如下目标函数来学习保存社 交网络结构信息的节点表示:
其中,α为超参数,α>0。
23)模型融合
基于已知的用户节点向量,通过高斯混合模型实现社团发现及社团 向量表示,即得到原本未知的每个用户属于每个社团的概率πik以及每个 社团k对应的子高斯分布参数(ψk,∑k);为了建立图1中所示的闭环结构, 还需要将社团的向量表示反馈给节点表示。反馈的过程为:在已知节点 属于每个社团的概率πik与每个社团k对应的高斯分布参数(ψk,∑k)的情况 下,生成每个社团中的用户,此时用户节点向量φi被看作是未知的。通 过这一过程,每个用户vi的向量表示φi与其所属社团k的向量表示中的均 值ψk在低维空间中更接近,属于同一个社团内的用户,其向量表示相互 之间也更相似。在通过社团向量表示对用户节点向量的反馈中,每个节 点都有了明确的社团属性,节点的向量表示被更高阶的社团关系约束而 进行优化,从而有利于提高社团发现的效果,对公式(21),定义如下目 标函数来实现社团发现以及社团向量的优化,同时增强节点向量表示的 社团关系特征:
其中,β为超参数,β>0。
结合用户节点表示优化,社团发现与社团节点表示过程的优化,模 型最终的目标函数为:
其中,E={e}为单词作为输入时的词向量矩阵,E′={e′}为单词作 为被预测对象时的词向量矩阵,Φ={φi}为用户节点的向量矩阵, Φ′={φ′i}为上下文用户节点的向量矩阵,Π={πik},Ψ={ψk},∑={∑k}, i=1,2,...,|V|,k=1,2,...,|K|。
进一步地,将目标函数最终转变为:
其中,diag(∑k)返回的是∑k的对角元素,约束diag(∑k)>0的作用是避 免在优化时的奇点问题。
24)模型推导
目标函数由节点向量表示优化和社团发现及社团向量表示优化两部 分构成,优化方法是将两部分分开,采用交替更新的方式求解各个部分 的参数。
给定(E,E′)和(Φ,Φ′)时,利用最小化带约束的公式(29)求解(Π,Ψ,∑); 给定(Π,Ψ,∑),最小化无约束的公式(29)求解(Φ,Φ′)。对于(Φ,Φ′)和(E,E′), 先随机初始化∑k>0和ψk,然后(Φ,Φ′)和(E,E′)通过EM算法求解并更新参 数:
其中:
当(Φ,Φ′)初始化合理时,约束diag(∑k)>0很容易满足, (Π,Ψ,∑)的优化也能很快收敛。
给定(Π,Ψ,∑)求解(Φ,Φ′)时,目标函数不带约束,使用随机梯度下降 法从文本信息、网络结构以及社团属性对应的公式(25)、公式(27)及 公式(28)三个目标函数分别对节点向量求导进而使其优化。由于在公 式(27)中需要对求和形式去对数,在计算节点向量梯度时很不方便, 使用最小化的上界作替代,将公式(27)转变为:
因为有则有:
对每个φi求导,有:
同时对词向量E′及上下文节点向量Φ′计算梯度:
3)社团主题识别
基于社团发现的结果,每个用户节点被划分到不同的社团中,每个 社团的语义特征从社团中用户的文本信息中进行体现,社团内用户主题 特征在一定程度上反映了该社团的主题。从用户角度出发,对用户文本 进行概率主题模型,获得每个用户节点的主题特征。利用节点向量与社 团向量表示的均值向量,可以对社团内的节点与社团之间进行相似度计 算,选取与社团相似度高的多个用户,以所述多个用户的主题特征的均 值作为社团的主题特征,用户主题特征的提取采用作者主题模型来实现。
社团主题的抽取步骤为:首先对社区网络中所有用户节点利用ATM 模型提取其主题特征,然后计算每个社团中的用户与社团向量表示的均 值向量的余弦相似度,选择相似度高的t个用户,以他们的主题特征均 值作为所在社团的主题特征。通过社团的主题特征,就能通过词反映出 社团的语义性。
本发明提出基于用户节点表示进行主题社团发现的算法流程如下:
- 还没有人留言评论。精彩留言会获得点赞!