一种基于回归树上下文特征自动编码的偏置张量分解方法与流程
本发明属于个性化推荐领域,具体涉及一种基于回归树上下文特征自动编码的偏置张量分解方法。
背景技术:
互联网和移动通讯设备的发展使得信息的产生和获取变得越来越容易,为了帮助用户解决信息过载问题,诞生了两种互联网技术,分别是搜索引擎和推荐系统。
其中推荐系统的主要任务是综合用户的历史行为等信息,向用户提供个性化的信息服务。其原理是分析和挖掘用户和物品间的二元关系,进而帮助用户从海量的信息中找到他们最有可能感兴趣的信息,从而大大减少用户找到有用信息的时间,改善用户体验。
传统的推荐算法仅利用用户的行为数据来挖掘用户兴趣。这类算法是基于用户的兴趣不会在短期内发生变化这一假设,因而可以通过历史数据训练出模型来对用户将来的兴趣进行预测。事实上,这一假设只适用于部分场景。虽然用户的一般兴趣可能相对稳定,但是用户的兴趣还受很多额外因素的影响。例如,在电影推荐系统中,用户对电影的需求与观影时间(如春节、圣诞节、情人节等),以及观影时的同伴(如情侣、父母、同学、同事等)有关。在推荐过程中使用上下文信息,有助于向用户提供更加个性化的推荐。
张量分解是较常用的上下文推荐算法,通过把数据建模成用户-物品-上下文n维张量的形式,张量分解可以灵活地整合上下文信息。然后通过基于已知数据对张量进行分解可以求得模型参数并依据该模型对新的数据进行预测。但是现有的张量分解算法存在以下问题:
1、未考虑用户偏置、物品偏置、上下文偏置及全局平均分等因素对评分的影响;
2、张量分解模型的模型参数随上下文类别呈指数增长,计算成本高。
技术实现要素:
针对现有技术中存在的上述技术问题,本发明提出了一种基于回归树上下文特征自动编码的偏置张量分解方法,设计合理,克服了现有技术的不足,具有良好的效果。
为了实现上述目的,本发明采用如下技术方案:
一种基于回归树上下文特征自动编码的偏置张量分解方法,包括如下步骤:
步骤1:输入:b,u,v,c,λ,α;
其中,b表示偏置信息,u表示用户特征矩阵,v表示物品特征矩阵,c表示上下文特征矩阵,λ表示正则化参数,α表示学习率;
步骤2:计算μ,bm,bi并构造{(feature1,target1),...,(featuren,targetn)};
其中,μ表示全局平均分,bm表示用户偏置,bi表示物品偏置,featuren表示训练样本n中的上下文特征,targetn为用户打分去掉全局平均分、用户偏置、物品偏置后剩余的部分;
步骤3:训练回归树t,构造新上下文特征;
步骤4:随机初始化bm,bi,bk,um,vi,ck;
步骤5:当ymik∈y′时,计算目标函数
其中,y′表示原评分张量y中非空的部分,ymik和fmik分别代表用户m在上下文k下对物品i的实际评分和预测评分,bk表示上下文偏置,umd表示用户m的d维隐语义向量的第d个元素,vid表示物品i的d维隐语义向量的第d个元素,ckd表示上下文k的d维隐语义向量的第d个元素;
步骤6:按如下公式迭代目标函数中各个因子;
bm←bm+α·(ymik-fmik-λ·bm);
bi←bi+α·(ymik-fmik-λ·bi);
bk←bk+α·(ymik-fmik-λ·bk);
um←um+α·(vi⊙ck·(ymik-fmik)-λ·um);
vi←vi+α·(um⊙ck·(ymik-fmik)-λ·vi);
ck←ck+α·(um⊙vi·(ymik-fmik)-λ·ck);
其中,⊙表示向量对应元素相乘的运算;
步骤7:使用sgd(stochasticgradientdescent,随机梯度下降)方法对目标函数进行优化,通过sgd方法遍历训练集中的每一个评分,对步骤6中的目标函数中的参数进行更新,然后通过计算rmse(rootmeansquarederror,均方根误差),判断训练模型是否收敛;
若:前后两次优化得到的均方根误差的差值小于设定的极小值,则判断为已收敛,然后执行步骤8;
或前后两次优化得到的均方根误差的差值大于或者等于设定的极小值,则判断为未收敛,然后执行步骤5;
步骤8:输出:b,u,v,c及回归树t;
步骤9:结束。
本发明所带来的有益技术效果:
1、针对当前基于张量分解的上下文感知推荐算法未考虑用户偏置、物品偏置、上下文偏置及全局平均分等因素对评分的影响的问题,本申请首先提出了用于上下文感知推荐的偏置张量分解模型。
2、针对张量分解模型的模型参数随上下文类别呈指数增长的问题,本申请提出了基于回归树的上下文特征自动编码算法,并将该算法与偏置张量分解算法相结合,提出了基于回归树上下文自动编码的偏置张量分解算法。
3、与当前已有的张量分解算法对比,本申请提高了推荐系统的推荐精度,解决了上下文维数过多的问题。
附图说明
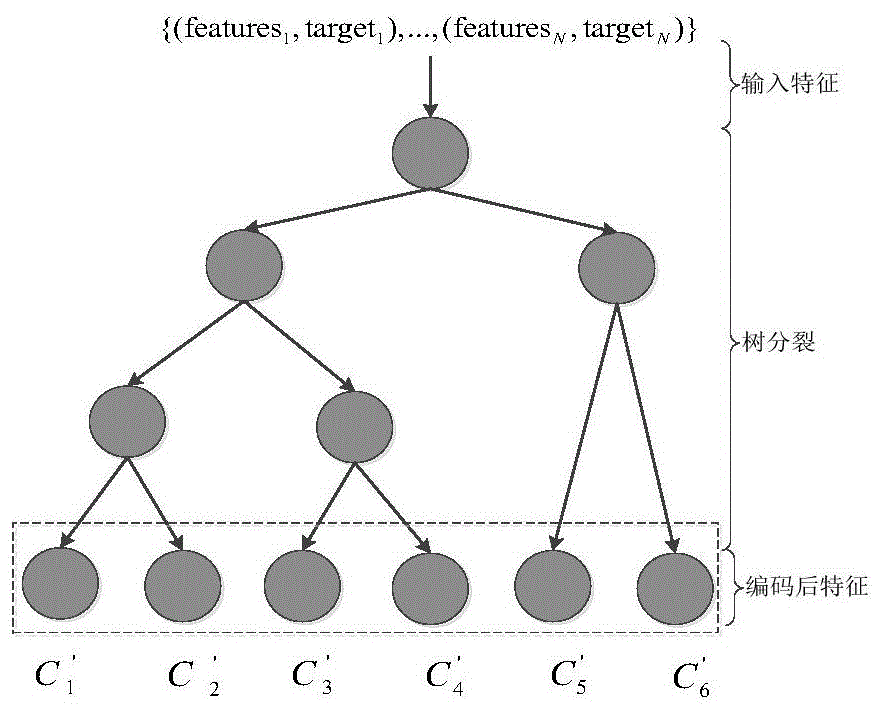
图1为基于回归树的自动上下文特征编码示意图。
图2为本发明方法的流程图。
具体实施方式
下面结合附图以及具体实施方式对本发明作进一步详细说明:
1、问题形式化定义
本申请将来自m个用户在k种上下文条件下对n个物品的打分记作张量y。y包含m×n×k个记录,每个记录表示用户m在上下文k下对物品i的打分,记作ymik,
矩阵分解模型的思想是使用低维矩阵来近似原始的交互矩阵。本申请使用张量分解对用户-物品-上下文交互信息进行建模,该方法将隐语义特征存储在
使用cp分解算法对张量进行分解,将用户m在上下文k下对物品i的评分建模如下:
其中,fmik代表用户m在上下文k下对物品i的预测评分,umd表示用户m的d维隐语义向量的第d个元素,vid表示物品i的d维隐语义向量的第d个元素,ckd表示上下文k的d维隐语义向量的第d个元素;
2、偏置张量分解模型
本申请在模型(1)的基础上进行改进,增加了全局平均分、用户偏置、物品偏置和上下文偏置,改进后的模型如下:
其中,μ代表全局平均分,bm、bi、bk分别代表用户偏置、物品偏置与上下文偏置。
在这个模型中,观测评分被分解成5个部分:全局平均分、用户偏置、物品偏置、上下文偏置以及用户-物品-上下文的交互作用,这使得每个分量只解释评分中与其相关的部分。为了防止过拟合,加入l2范数得到优化目标为:
其中,ymik代表用户m在上下文k下对物品i的实际评分,fmik代表用户m在上下文k下对物品i的预测评分,um表示用户m的d维隐语义向量,相应的vi和ck分别表示物品i和上下文k的d维隐语义向量,bm、bi、bk分别代表用户偏置、物品偏置与上下文偏置,λ为正则化参数。
本申请使用sgd(stochasticgradientdescent,随机梯度下降)方法对目标函数进行优化,sgd方法遍历训练集中的每一个评分,对模型中的参数进行更新。
训练过程详见图2。
3、基于回归树的上下文特征自动编码
本申请针对传统张量模型参数随上下文维度呈指数增长的问题,提出一种基于回归树的上下文特征编码机制,通过控制回归树的深度,不仅可以有效地控制上下文维度,同时提高了算法的精度。
自动上下文特征编码如图1所示,其中featurei表示训练样本i中的上下文特征。考虑到全局平均分,用户偏置等因素的影响,回归树训练样本的目标值targeti为用户打分去掉全局平均分、用户偏置、物品偏置剩余的部分,即:
ymik←ymik-μ-bm-bi(4);
其中,ymik为用户m在上下文k下对物品i的实际评分,μ为全局平均分,bm、bi分别为用户偏置和物品偏置。
最后,将偏置张量分解与上下文特征自动编码相结合,提出基于回归树上下文特征自动编码的偏置张量分解方法,其流程如图2所示,其中α表示学习率,λ表示正则化参数,超参数α,λ的值可以通过交叉验证得到,具体包括如下:
(1)建立起多组超参数α,λ的组合;
(2)将数据集等分为10份,取其中一份为测试集,其余九份为训练集,循环十次;
(3)依次采用不同的超参数组合进行10次交叉验证,将每种超参数组合下的推荐结果取平均值进行比较,选择推荐精度最高的一组超参数组合。
当然,上述说明并非是对本发明的限制,本发明也并不仅限于上述举例,本技术领域的技术人员在本发明的实质范围内所做出的变化、改型、添加或替换,也应属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!