基于XGBoost的算法生成域名检测模型的方法与流程
本发明涉及一种域名检测模型的生成方法。
背景技术:
据cnnic统计发现,截至2017年12月底,网民数量达到7个多亿,“.cn”域名数增长到2085万个。与此同时,来自网络安全方面的威胁也层出不穷。在互联网刚兴起的时候,缺乏对安全问题的考虑,许多网络应用存在隐藏威胁,例如域名服务系统(domainnamesystem,dns)作为完全开放的服务系统,最初是以彼此信任为基础建立的,由于它对域名的高度信任使其成为恶意网络行为的重要组成部分,比如恶意域名攻击就是利用其特性来进行的。
识别一个网络行为是否具有恶意性,需要检测该行为实际上是否会产生恶意行为以及是否造成伤害,也即是对网页内容是否包含恶意代码来进行判断,或者采用蜜罐技术等方式来进行检测。而dns作为网站以及邮件等很多应用的第一步,很多行为的恶意性在域名上会有所体现,如恶意域名。不法者在经济利益的驱动下,使用恶意域名促进僵尸网络发展和扩大,窃取用户个人信息或设备终端数据,致使分布式拒绝服务攻击愈加泛滥,导致受害者遭到终端被控制或破坏等恶意攻击行为等。同时还引入了算法生成大量恶意域名,即使用域名生成算法dga生成大量恶意域名,从而采用域名轮换技术(domainflux)增强恶意网络的生存能力,用于自身的组织和控制,以增强自身的健壮性,使其进行的相关危害活动更具高效性和灵活性,也增加了检测的难度。比如,根据360的netlab公布的数据显示,cryptolocker每周能生成1000个域名,而conficker-a每天能产生250个域名,恶意域名检测非常紧迫并且对创建安全的网络环境至关重要。本发明中将dga生成的域名统称为agds(algorithmically-generateddomains)。
技术实现要素:
本发明为了解决域名生成算法生成大量恶意域名的检测问题,提供了一种基于xgboost的算法生成域名检测模型的方法。本发明针对域名生成算法生成的域名具有一定迁移性和跳变性的特点,提出一种白名单与分类算法相结合的检测模型,使用白名单对良性域名进行有效过滤,减轻后续分类模型的压力,对比svm和nb,采用xgboost作为分类算法能提升检测的准确率。
本发明的目的是通过以下技术方案实现的:
一种基于xgboost的算法生成域名检测模型的方法,包括如下步骤:
步骤一、根据dns数据报文的格式,采用图2以及表1所示方法,从域名中提取网络属性的特征,如从dns的rr记录中解析出ip以及ns、ttl等,从而计算出ip分散度、ip重合度、ns个数以及ttl特性等,并从域名中提取基于词汇的特征,如字符的随机性、可发音性、差异性和字符连续性,然后进行数据筛选,从而滤除缺失和重复的数据;
所述随机性采用以2为底的香农熵h(x)量化,即:
式中:
p(xi)表示字符xi出现的概率,count(xi)表示字符xi出现的次数,len(domain)表示域名的长度;n表示域名中不重复字符的数目。
所述可发音性用二元马尔科夫链模型量化,即:
式中:p(xi|xi-1)代表i序列在第i-1序列出现后出现的条件概率,c(xi-1)表示xi-1在同一字符串中出现的次数,c(xi-1,xi)表示xi-1xi在待测字符串中彼此相接出现的次数;
所述差异性利用n-gram模型进行判断,即:
unigram的概率:
bigram的概率:
trigram的概率:
式中,p(suni)、p(sbi)、p(stri)分别表示n取1、2、3时n-gram模型的概率,分别使用unigram、bigram、trigram分析字符组成并将三者平均排名的平均值和标准差作为区分特征,m表示字符序列的个数;
步骤二、对步骤一处理后的数据特征进行归一化处理,即:
其中,x(i)为原始数据特征值,其中,xmax(i)和xmin(i)分别表示操作前x(i)的最大值和最小值,x′(i)为操作后的值;
步骤三、选择xgboost算法对步骤二归一化处理后的数据进行进行训练和分类。
相比于现有技术,本发明具有如下优点:
1、本发明采用白名单与机器学习的方法相结合,逐层过滤,协同工作,平均情况下,访问过程中正常域名的访问比较多,将正常域名建立白名单能有效进行过滤。
2、xgboost作为目前最好、最快速的开源的boostedtree工具包,运行速度快且支持并行化化构建cart树,可以用于分类和回归的问题中,精度非常高同时支持各种编程语言,本发明提取域名网址词汇特征以及网络属性特征,采用xgboost来进行训练和分类。
3、在网址词汇特征方面主要用香农熵量化随机性以及用二阶马尔科夫和n-gram来量化域名的可发音性和差异性,而网络属性方面主要提取基于ttl、ip和whois等特征,最后通过实验对比分析svm、nb,xgboost在精确率、召回率等各项指标均取得更好的效果。
附图说明
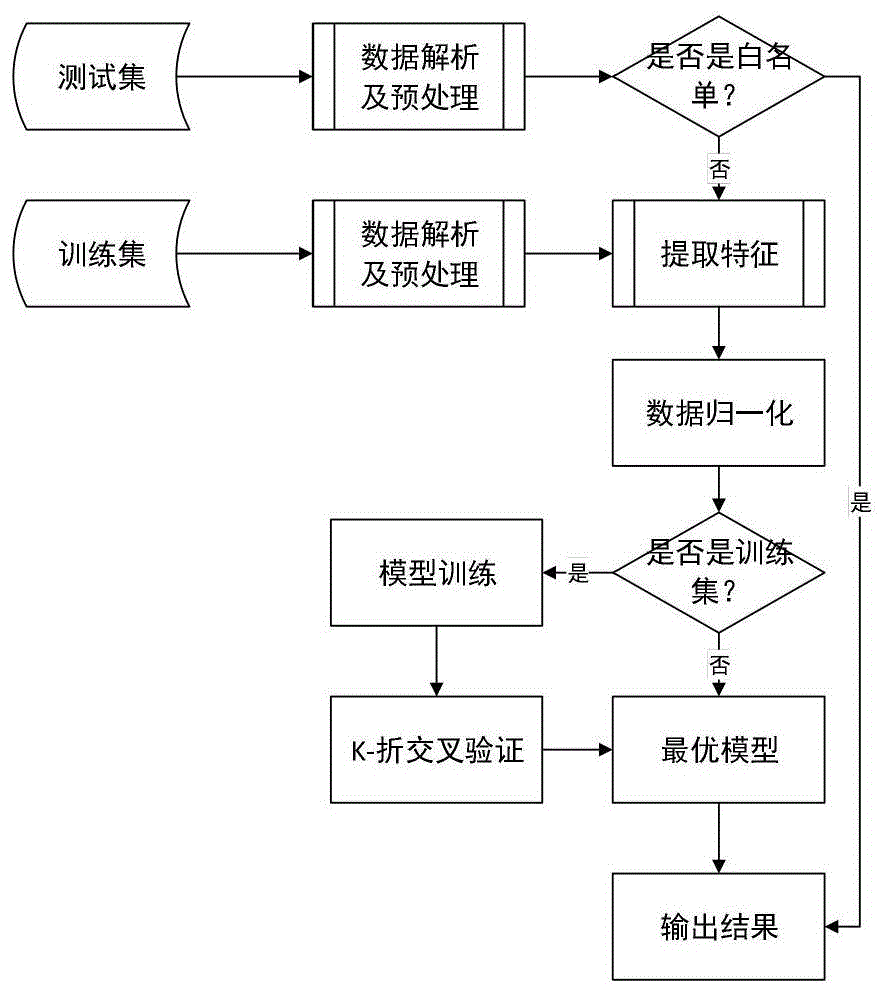
图1为整体框架图;
图2为请求域名解析流程图;
图3为分类结果对比图;
图4为误报率对比图。
具体实施方式
下面结合附图对本发明的技术方案作进一步的说明,但并不局限于此,凡是对本发明技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围,均应涵盖在本发明的保护范围中。
本发明提供了一种基于xgboost的算法生成域名检测模型的方法,agds检测的模型整体框架如图1所示,主要分为训练模块和测试模块。在提取特征的时候,对于网络属性特征,本发明主要采用实验室搭建的协议栈平台来实现抓包及分析数据流量的功能,然后采用c/c++语言代码解析dns数据流量并提取需要的信息,该模块的处理算法如表1所示:
表1
其中,请求域名的解析流程如图2所示,whois信息完整度用实际条目数与总条目数的比例来量化,提取ip特征时,dns响应数据中包含域名解析的ip地址。agds由于自身的特性会频繁切换ip,如fast-flux,从而避开安全系统的检测。因此攻击者通常会为agds分配多个ip。同样的,cdn的ip情况与agds的ip情况也有异同之处,首先,前者对应ip外在表现为其长时间处于使用状态且分布均匀,而fast-flux感染的主机通常是普通终端,容易失去控制,ip弃用率高且更换频繁,所以ip分布比较发散。
因此,本发明选取解析ip的个数以及ip分散度作为特征,可以通过查询实验室的ip地址库来获得ip归属地,同时为了数值化ip分散的程度,通过右移后进行二进制位与操作来计算ip的前16bit值作为计算对象,并对其采用信息熵来量化这种分散性。设ip集为β,p(x)是ip前16bit值x与β的比值,则:
式中:
其中,
此外,同一个域名会对应多个ip,同样一个ip也是会有多个域名与之对应。由于拥有相同的公共系统资源,同一dga生成的域名,对应的ip会指向同一ip集合。虽然存在一些硬件和软件上的局限,不能收集到agds所有的ip,但依然可以计算待测域名的ip与agds对应ip集合的重合度,在一定程度上能够量化上述特点。采用whois信息查询与构建dns请求数据包并解析对应的响应数据相结合的方式,获取已知恶意域名ip,与一些公开的c&c的ip去重后构成恶意ip集合dip。对于新增域名d,如果其ip集合dd满足
对于域名词汇特征,从域名数据中提取如下特征:
(1)随机性
agds和合法域名视觉上不一样的原因就是前者更具随机性,字符的混杂程度更高,而后者的重复字母比较多。可用香农熵来量化这种随机性,即:
式中:
式(5)中count(xi)表示字符xi出现的次数,可计算域名字符串中每个字符的出现频率。式(4)计算时以2为基数,计算出的熵值可量化域名的随机性,熵值越大则越随机,这意味着域名的字符更紧密的混合在一起。这一特征能够明显地区分sjlqecdh.com和google.com,但是很多合法域名如baidu.com的熵值和agds之间并非是绝对差距,所以仅凭这个随机性特征并不足以作为最终判断标准。
(2)可发音性及差异性
大多数情况下,合法的企业组织或者公众服务单位注册使用的域名都是可发音性强从而更有利于记忆的字符串,如yahoo、google等都比sfsydpjxkhl.com更朗朗上口,是否容易发音可以作为域名恶意性判断的一个标准,采用n-gram与马尔科夫链结合来计算概率值用作可发音性的度量标准。在概率论中,马尔科夫假设是指假设当前的状态st仅取决于当前一个状态st-1,即p(st|s1,s2,s3,…,st-1)=p(st|st-1)。而满足马尔科夫假设的随机过程x1,x2,x3,…,xn就是马尔可夫链,状态转移过程每个状态值与当前状态之前的有限个状态有关,满足:
式中,m是有限的,这样的马尔科夫模型称为m阶马尔科夫模型,m=1时是标准的马尔科夫模型,利用二阶马尔科夫模型能够将域名语义性转化为统计信息特征。
一般情况下,n-gram在特定的文本或语料库的前提下,可以用来对语句是否合法进行预测或评估,n的取值范围是自然数,n=1是unigram,n=2是bigram,n=3则称为trigram。比如域名google的bigram序列为{^g,go,oo,og,gl,le,e$},其中^和$代表字符串的开头和结尾。此时为了计算s易发音的概率p(s)则有:
其中,p(xi)表示i序列出现的概率,p(xj|xi)是j序列在第i序列出现后出现的条件概率,显然逐项计算并不方便。于是利用马尔科夫链的假设,假定当前的分词序列只和前面的m个序列相关,则:
bigram的概率:
则最终问题为计算p(xi|xi-1),根据条件概率的计算方式,需要估算出联合概率p(xi-1,xi)和边缘概率p(xi-1),对两者进行估算时,首先对语料库进行训练,然后分别统计xi-1在同一字符串中出现的次数和xi-1xi在待测字符串中彼此相接出现的次数c(xi-1,xi),并将两个结果与语料库的大小求比值,从而计算出各自对应的相对频度。在统计量足够多的情况下,可得到计算公式:
由此得到的二元马尔科夫链模型,能够作为域名字符串可发音性的量化,且良性域名更易于发音。
此外,n-gram模型同样可以用于判断字符串的差异程度,良性域名多数采用常见的分词组合,而agds对应的分词序列则比较随意,若将n-gram进行排序,前者n-gram频率会高于后者,分别使用unigram、bigram、trigram分析字符组成并将三者平均排名的平均值和标准差作为区分特征。
(3)字符连续性
agds在生成机制上的随机性,会导致域名组成字符在域名中较为均匀地分布,同样出于域名系统存在的根本原因,良性域名易于记忆的特性使得其长度较短。除此之外,根据经验和域名产生的本质可推理,因为短域名更容易被记住,自域名出现以来短域名颇受注册者青睐,所以agds为了提高注册成功率,大多数域名长度会相对较长,单个标签长度也会增加,数字的个数较多、特殊字符的个数较多、连续数字的最大长度较大,从而数字占域名总长度的比例较高,字母占比较低,特殊字符占比略高。同时,单词作为语言的基本元素,且语言的存在是为了沟通,因此由于元音字母在词汇中起着发声的作用,基本上单词中会带有元音字母,由此可见agds中元音字母数目较少,相对的其中的辅音字母数目较多,也即是元音字母占总长度比略低,辅音字母占比略高,将元辅音占比作为区分特征之一可以有效区分域名。
实施例
(1)实验环境
实验环境如表1所示:
表1实验配置表
(2)实验方案
恶意域名数据从malwaredomainlist、thezuesblocklist数据库、360等不同数据源进行下载获得,直接下载http://data.netlab.360.com/dga/在2018年更新的agds。良性域名来自alex,为了得到一个效果良好的机器学习模型,将数据的75%作为训练集,25%作为测试集。
将初始数据进行筛选滤除缺失和重复的数据之后,对数据特征须进行归一化处理,尤其对于svm归一化是必备操作。将特征的值缩放到一个区间内,即:
其中,x(i)为原始数据特征值,其中,xmax(i)和xmin(i)分别表示操作前x(i)的最大值和最小值,x′(i)为操作后的值,则数据归一化后将数值缩放到区间[0,1]内。
建立白名单之后,进行模型训练和测试。训练模型时,对于xgboost,python中可以直接引用xgbclassifier,这是xgboost的sklearn包,能够允许xgboost使用gridsearch和并行处理,也可以引用xgboost工具包,本文使用后者,其内置了交叉验证,可以调参;对于svm直接使用sklearn对应的模型并且库中的gridsearchcv能够高效地完成自动调节参数过程,它使用网格搜索的方法全面地测试多种参数组合,然后通过对结果进行交叉验证来确定能取得最优分类性能的参数;对于nb也是直接使用其中对应的模型。本发明采用10折交叉验证结果来选出模型后用测试集进行测试评估。
(3)实验结果分析
如图3所示,xgboost在精准率、准确率、召回率以及f1值都优于svm和nb算法,其中精确率和召回率是两种使用频度很高的评价指标,直观体现了模型的分类能力,且f1作为精准率和召回率的调和平均数,在一定程度上反应分类器的综合性能,相较于svm的97.50%以及nb的94.87%的f1值,xgboost达到98.85%。
如图4所示,误报率在一定程度上描述了模型的分类能力,根据计算公式可知该值越小,说明模型效果越好。在三者中xgboost取得最小值,能获得更好的效果。
因此,虽然svm在检测过程中也能取得仅次于xgboost的效果,但是后者除了可以提升准确率之外,还支持并行化计算,能够提升检测速度。因此adgs检测模型选择xgboost作为最终的分类算法。
- 还没有人留言评论。精彩留言会获得点赞!