数字剪报制作方法与流程
本发明涉及一种数字剪报制作方法。
背景技术:
数字剪报就是简要的调查报告,简要的情况报告,简要的工作报告,简要的消息报道等,它具有简、精、快、新、实、活和连续性等特点,日常工作或生活当中,经常需要制作数字剪报。
现有的数字剪报制作方法,数据获取效率交底,数据类型比较单调,且数据检索的维度不够丰富,影响了数字剪报制作的效率和质量。
技术实现要素:
为解决现有技术的不足,本发明提供了一种可以解决上述问题的数字剪报制作方法。
为了实现上述目标,本发明采用如下的技术方案:
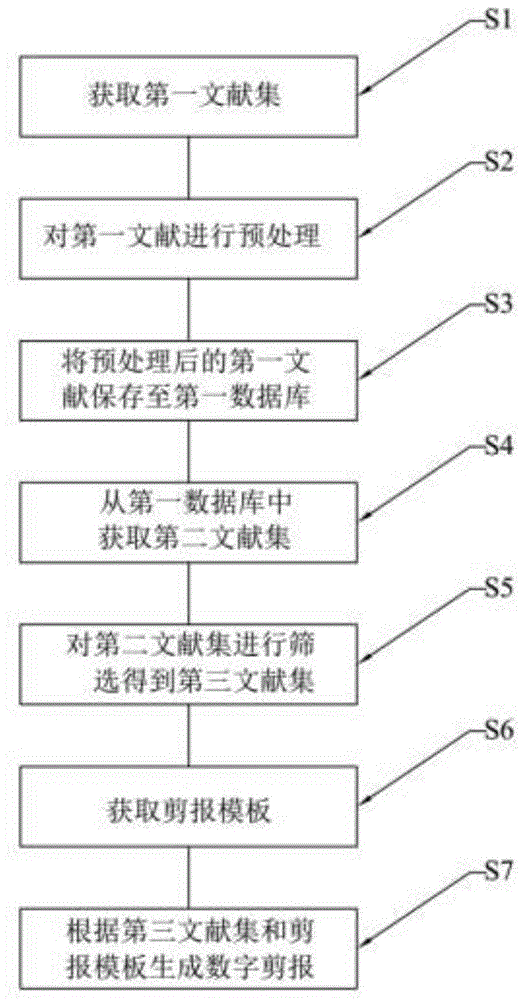
一种数字剪报制作方法,用于制作数字剪报,包含以下步骤:
获取第一文献集,第一文献集包含多个第一文献;
对第一文献进行预处理;
将预处理后的第一文献保存至用于存储文献的第一数据库;
根据数字剪报的主题从第一数据库中获取第二文献集,第二文献集包含多个第二文献;
对第二文献集进行筛选得到第三文献集,第三文献集包含多个第三文献;
获取剪报模板;
根据筛选后得到的第三文献集和剪报模板生成数字剪报。
进一步地,获取第一文献集的具体方法为:
根据第一预定检索条件从多个网络端口获取第一文献集;
多个网络端口包含数字报刊、网站、客户端、微信和微博。
进一步地,对第一文献进行预处理的具体方法为:
获取第一文献的第一类型属性,并将第一类型属性关联至第一文献。
进一步地,第一类型属性包括:
发布媒体,表示当前发布第一文献的媒体的名称;
媒体地域,表示发布媒体所处的地域信息;
发布时间,表示发布媒体发布第一文献的时间;
发布源,表示最早发布第一文献的媒体的名称;
数据类型,表示发布第一文献的网络端口。
进一步地,第一类型属性还包括:
原创性,表示第一文献是否由当前发布媒体首发;
图片数,表示第一文献所包含的图片的数量;
文献字数,表示第一文献所包含字数。
进一步地,对第一文献集中的文献进行预处理的具体方法还包括:
获取第一文献的第二类型属性,并将第二类型属性关联至对应的第一文献。
进一步地,第二类型属性为情感指数,情感指数表示第一文献的情感属性。
进一步地,获取第一文献的情感指数的具体方法为:
获取第一文献的不同种类的词组;
计算每个种类的词组的词频;
根据每个种类的词组的词频以判断第一文献的情感指数。
进一步地,获取第一文献的情感指数的方法进一步为:
获取第一文献的正面词组和负面词组;
计算正面词组和负面词组的词频;
根据正面词组和负面词组的词频以判断第一文献的情感指数。
进一步地,对第二文献集进行筛选得到第三文献集后还对第三文献集进行预处理;
并根据预处理后的第三文献集和剪报模板生成数字剪报。
本发明的有益之处在于提供的数字剪报制作方法预先获取相关的第一文献集并预处理后存入第一数据库,便于之后制作数字剪报时的文献检索工作。
本发明的有益之处还在于提供的数字剪报制作方法在获取第一文献集时选取数据的范围覆盖了数字报刊、网站、客户端、微信和微博等多个数据库,数据来源广泛,数字剪报的素材更加充分。
本发明的有益之处还在于提供的数字剪报制作方法中获取制作数字剪报的第二文献集时,检索维度包含了第一类型属性和第二类型属性,特别是添加了情感指数维度的检索,可以快速筛选表达对应情感的文献。
附图说明
图1是本发明的数字剪报制作方法的示意图。
具体实施方式
以下结合附图和具体实施例对本发明作具体的介绍。
如图1所示为本发明的一种数字剪报制作方法的流程图,该数字剪报制作方法用于制作数字剪报,其包含以下步骤:s1:获取第一文献集,第一文献集包含多个第一文献。s2:对第一文献进行预处理。s3:将预处理后的第一文献保存至用于存储文献的第一数据库。s4:根据数字剪报的主题从第一数据库中获取第二文献集,第二文献集包含多个第二文献。s5:对第二文献集进行筛选得到第三文献集,第三文献集包含多个第三文献。s6:获取剪报模板。s7:根据筛选后得到的第三文献集和剪报模板生成数字剪报。
对于s1:获取第一文献集,第一文献集包含多个第一文献。
为了提高制作剪报的效率,需要建立第一数据库,该数据库中储存制作数据剪报的所有原始文件。
建立第一数据库首先需要获取某一类型的第一文献构成第一文献集。具体方法为根据第一预定检索条件从多个网络端口获取第一文献集。一般可以通过现有的检索软件设定第一预定检索条件从互联网上的多个类型的端口获取第一文献集,比如将第一预定检索条件设定为财经、军事或娱乐等条件,检索软件根据预设条件自动从互联网的多个类型的端口中获取符合条件的第一文献。其中,多个网络端口包含数字报刊、网站、客户端、微信和微博等。
对于s2:对第一文献进行预处理。
当获取到第一文献集后,对第一文献集中的每个文献进行预处理以便于后续制作数字剪报时的检索工作。
对第一文献进行预处理的具体方法为:获取第一文献的第一类型属性,并将第一类型属性关联至第一文献。其中,第一类型属性表示可以根据该文献的来源直接获取到的信息,该第一类型属性包括发布媒体、媒体地域、发布时间、发布源和数据类型。其中,发布媒体表示当前发布第一文献的媒体的名称。媒体地域表示发布媒体所处的地域信息,比如国家、省份、城市等。发布时间表示发布媒体发布第一文献的时间。发布源表示最早发布第一文献的媒体的名称。数据类型表示发布第一文献的网络端口,比如该文献是来自微信还是微博。
可以理解的是,第一类型属性还包括:原创性、图片数和文献字数。其中,原创性表示第一文献是否由当前发布媒体首发。图片数表示第一文献所包含的图片的数量。文献字数表示第一文献所包含的字数。当获取到以上维度的第一类型属性后,将该第一类型属性关联至对应的第一文献,以作为后续制作数字剪报进行文献检索时该文献可被检索的维度。
进一步地,对第一文献集中的文献进行预处理的具体方法还包括获取第一文献的第二类型属性,并将第二类型属性关联至对应的第一文献。其中,第二类型属性表示需要通过数据计算处理后能够获取到的信息。在本发明中,该第二类型属性为情感指数,该情感指数表示第一文献的情感属性。
获取第一文献的情感指数的具体方法为:获取第一文献的不同种类的词组,计算每个种类的词组的词频,根据每个种类的词组的词频以判断第一文献的情感指数。
具体而言,首先根据需要,设定表示不同情感的词组,在本实施例中,我们将文献的情感指数设定为正面和负面,进而需要根据划分,分别统计并挑选出表示正面的正面词组和表示负面的负面词组,并分别存储在正面词组库和负面词组库中。在对第一文献集进行处理时,根据正面词组库和负面词组库中存储的词组,从每个第一文献中获取到正面词组和负面词组,并计算正面词组的出现次数以及负面词组的出现的次数,根据正面词组和负面词组的词频来判定该第一文献属于正面文献或负面文献,具体的,当正面词组的词频大于负面词组的词频时,该第一文献为正面文献,反之,则为负面文献。当获取到第一文献的情感指数后,将该情感指数关联至对应的第一文献,以作为后续制作数字剪报进行文献检索时该文献可被检索的维度。
可以理解的是,在判断第一文献的情感指数时,还可以对每个正面词组和负面词组设定计算权值,此时判断第一文献的情感指数时考虑的不仅仅是词组出现的次数,还考虑每个词组的权值,最后对正面词组和负面词组进行统计计算,分别打分,最后比较正面词组和负面词组的分值大小以得出第一文献的情感指数。
同时,在本实施例中,对文献的情感指数划分为正面文献和负面文献,根据需要,情感指数的划分可以根据实际需求进行更多类型的划分。
以上处理过程均通过计算机自动进行处理。
对于s3:将预处理后的第一文献保存至用于存储文献的第一数据库。
将经过步骤s2处理好的第一文献集保存至第一数据库中,便于后续制作数字剪报时进行检索查询。
对于s4:根据数字剪报的主题从第一数据库中获取第二文献集,第二文献集包含多个第二文献。
根据数字剪报的主题在第一数据库中进行文献检索,得到第二文献集,检索的维度包含第一类型属性和第二类型属性所包含的所有维度,特别是第二类型属性的情感指数属性,可以快速筛选表达正面情感的文献或表达负面情感的文献。
对于s5:对第二文献集进行筛选得到第三文献集,第三文献集包含多个第三文献。
通过人工校对,对第二文献集进行审核校对,进一步挑选出更加符合要求的第三文献集。
进一步地,得到第三文献集后,对第三文献集中的第三文献进行预处理,比如进行相关内容删减,比如当制作不包含图片的数字剪报时,可以对第三文献包含的图片进行删除。可以理解的是,具体的预处理可以根据实际需求进行选择。
对于s6:获取剪报模板。
剪报模板决定了数字剪报的风格,可以预算制作多个剪报模板并存储在对应的模板数据库中,在制作数字剪报时根据需要选择并调用合适的剪报模板。
对于s7:根据筛选后得到的第三文献集和剪报模板生成数字剪报。
根据步骤s5得到的第三文献集和步骤s6选择的剪报模板,通过剪报制作软件自动生成数字剪报。
以上显示和描述了本发明的基本原理、主要特征和优点。本行业的技术人员应该了解,上述实施例不以任何形式限制本发明,凡采用等同替换或等效变换的方式所获得的技术方案,均落在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!