一种带有区域放大操作的改进SSD目标检测算法的制作方法
本发明属于计算机视觉技术领域,主要涉及深度学习和目标检测,尤其是一种带有区域放大操作的改进ssd目标检测算法。
背景技术:
目标检测是计算机视觉的核心课题,几十年来引起了人们的广泛关注。近年来,随着深度学习的出现,目标检测技术得到了显著的发展。深度学习是一种强大的从输入数据中自主学习特征表示的方法,具有高准确性和高鲁棒性的特点,卷积神经网络(cnn,convolutionalneuralnetworks)作为深度学习中重要的算法,广泛应用于目标分类、目标检测等领域中,近年来提出了很多基于卷积神经网络的目标检测方法。theoverfeatnetwork是第一种基于cnn的目标检测器,其通过滑动窗口的方法将每个图像分割成多个部分,并使用cnn网络对每个部分进行分类。然后,结合前两个过程的输出获得最终的位置和类别检测值。基于这种思路而设计的网络亦极具影响力,包括区域卷积网络(r-cnn,region-basedconvolutionalnetwork)、fast-rcnn和faster-rcnn。虽然这些网络在目标检测上取得了较好的精度,但其在检测速度上不能满足实时检测的需求,而之后出现基于回归方式的卷积网络在保持更好检测精度的同时,具有实时性和节省内存的优点,目前流行的回归卷积网络有ssd(shotmultiboxdetector)和yolo(youonlylookonce)。ssd中包含训练特征金字塔,其通过在不同分辨率特征图上的每个单元格上生成默认框实现目标检测。yolo在输入图像上划分网格,并在每个网格上直接进行目标位置和类别检测。在pascalvoc2007测试中,ssd可以在nvidiatitanx上以每秒59帧图像的速度,在尺寸为300×300的输入图像上检测精度为74.3%,检测效果相对更好。由于ssd只有一层低层特征用于检测,特征信息不够丰富,导致小目标检测性能较差。
为提高ssd对小目标检测效果很多学者进行了研究。dssd(deconvolutionalssd),其采用特征提取更强的网络resnet-101替换ssd主干网络vgg16,结合反卷积模块提高网络小目标检测能力。rssd(rainbowssd)改进特征融合方式检测到更多的小目标。fssd(featurefusionssd)利用特征融合和下采样重构多尺度特征提高在小目标的检测效果。
在ssd网络中,只有一个低层卷积层conv4_3用于检测小目标,小目标的特征细节信息不够充分,而在conv4_3之上有五个卷积层,其特征图分辨率逐层下降,这些层可以为大目标检测提供足够的信息,但对于中目标检测效果仍然不够。本发明重点研究如何提高ssd网络对小、中目标检测的性能。为此,本发明提出了一种结合建议区域和反卷积操作的方法,首先,为了提高对小目标的检测能力,采用区域放大方法对低层特征进行有针对性的放大,即将ssd网络作为建议区域提取网络,并结合反卷积进行区域特征放大,以丰富低层特征细节信息,这将有助于提升小目标检测精度。其次,为改善对中目标检测效果,利用ssd网络中已有的多个高层卷积层进行特征层提取,组成新的网络层,增强网络特征提取能力,以提供更多关于中目标的特征信息。最后,将所有新添加层进行特征金字塔重构,并反馈给类别和位置检测层,通过在已训练好的ssd模型基础上进行再训练,得到最终的模型。
技术实现要素:
为了提高ssd网络对于小、中目标的检测效果,本发明提供了一种带有区域放大操作的改进ssd目标检测算法,
实现本发明技术方案是:
(1)使用ssd网络,在大量公开数据集上训练获得ssd模型;
(2)在ssd网络的低层卷积层上采用区域放大策略,由于小目标在顶层特征图保留的特征信息极少,浅层特征图可以保存更多的特征信息,而如果选择层太浅,细节信息丰富,但是不会有足够的语义信息,因此本发明选择低层卷积层conv3_3、conv4_3上进行改进。conv4_3是ssd网络用于检测小目标的卷积层,其特征细节信息不够丰富,为增强其细节信息,引入反卷积操作,将尺寸为38×38的conv4_3放大至300×300,利用步骤(1)中的ssd模型的输出作为当前输入图像的(300×300)中目标对应的建议区域,将建议区域映射到反卷积后的特征图上获得区域映射特征图并池化为固定尺寸,进而丰富特征信息。另外,通过特征提取操作额外引入conv3_3获得尺寸为75×75特征图,同样将ssd模型的输出作为建议区域,映射到特征图上获得区域映射特征图并池化为固定尺寸以进一步丰富特征信息,通过区域放大策略以提高ssd网络对小目标的检测精度。
区域映射公式为:
其中rw/h为建议区域在待映射特征图上宽度和高度,dw/h为建议区域宽度和高度,fw/h为待映射特征图宽度和高度,imgw/h为输入图像宽度和高度。通过区域映射公式,根据特征图与输入图像之间的尺寸比例关系,可将建议区域映射到特征图目标对应位置处,实现目标特征区域放大。
反卷积公式为:
d=s×(i-1)+k-2p
其中,s代表步长,k代表反卷积核尺寸,d为反卷积图尺寸,i为对应卷积图尺寸,p为补零。在改进conv4_3时,设定步长s=8、k=6,p=1对尺寸为38×38的特征层conv4_3进行反卷积得到尺寸为300×300反卷积图。
(3)通过特征提取操作,对ssd网络相应的高层进行特征提取,构成新的网络层,增加深度,并在步骤(1)中训练的ssd模型中已有参数基础上进行再训练以改善中目标检测精度;
(4)将改进的ssd网络低层和高层进行结合,重构特征金字塔用于检测,利用ssd网络卷积检测的方式,针对改进低层和高层分别添加新的类别和位置卷积检测层,将所有检测的结果进行合并,并通过非极大值抑制算法进行筛选实现目标检测。首先,通过在改进的用于检测的特征层上生成不同尺度默认框。其次,利用新添的卷积检测层预测默认框的类别和位置信息。最后,将预测值与真实框信息进行对比获得最终检测结果。其中,默认框生成机制是通过默认框映射建立起图像中目标位置和对应特征之间的关系,即在特征图的每个单元格上根据映射原理在输入图像对应位置处生成默认框。本发明对低层和高层采用不同改进方法,其对应的默认框映射机制也是不同的。
低层默认框映射公式:
其中,fw/h为用于产生默认框的特征图宽度和高度,fx/ycenter为默认框在输入图像对应位置的中心点坐标,cx/y为默认框在特征图上的中心坐标,
高层默认框映射公式:
其中,fw/h为用于产生默认框的特征图宽度和高度,imgw/h为输入图像的宽度和高度,cx/y为默认框在特征图上的中心坐标,imgcx/cy为默认框映射到输入图像的中心坐标,wk/hk为默认框映射到输入图像上的宽度和高度,(xmin,ymin,xmax,ymax)为默认框边界框坐标对应于左上角和右下角。
(5)根据改进方法,在步骤(1)中训练的ssd模型基础上进行参数再训练以获得最终的模型,并与ssd网络、检测效果相对更好的改进ssd网络,即fssd网络进行对比,验证改进方法在目标检测上的有效性。
本发明优点和效果:
本发明相比ssd方法,具有如下优势:
(1)在ssd模型已有参数的基础上进行训练,降低了训练对gpu的成本和计算能力的要求。
(2)通过对ssd网络的低层和高层采用不同改进策略,提高了对小、中目标的检测精度。
附图说明
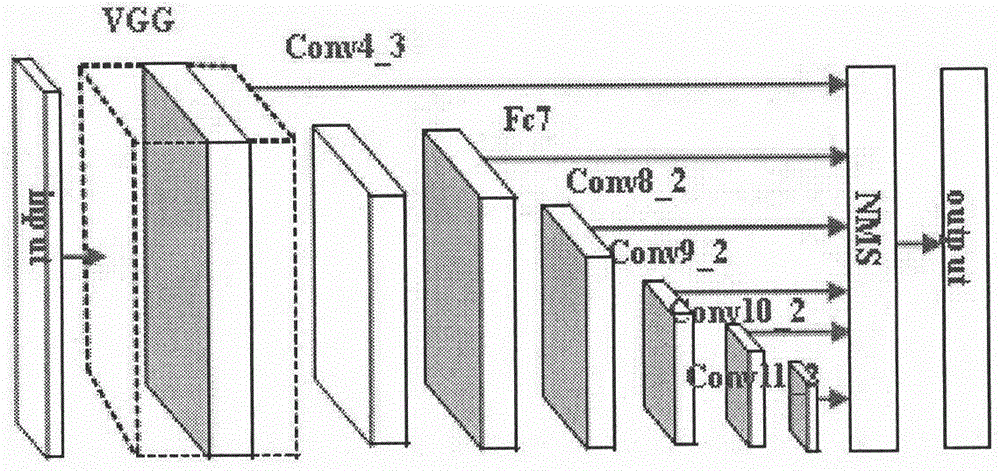
图1为ssd网络结构图;
图2为ssd中不同特征层可视化特征图和对应检测结果;
图3为改进低层框架图;
图4为改进低层区域映射图;
图5为改进高层框架图;
图6为改进方法框架图;
图7为改进低层和ssd低层小目标检测结果对比图;
图8为改进高层和ssd高层中目标检测结果对比图;
图9为改进方法和ssd目标检测结果对比图。
具体改进方法实现步骤
下面结合附图和具体实例对本发明进行详细说明:
一种带有区域放大操作的改进ssd目标检测算法,主要包括训练ssd模型、训练集准备,低层和高层改进、训练改进模型和目标检测等步骤。软件环境为深度学习框架caffe、操作系统为ubuntu16.04。
训练集准备:从公开pascalvoc数据集中挑选图像,并在caffe的框架下将数据集转化为caffe可用的lmdb格式的数据集;
低层和高层改进:
步骤一:分析ssd网络结构,参见图1。ssd主要是在基础网络vgg上添加新的网络结构,并采用多尺度卷积检测的方式来进行目标检测,用于检测的卷积层有conv4_3、fc7、conv8_2、conv9_2、conv10_2和conv11_2,不同的卷积层检测对应不同尺寸的目标。
步骤二:ssd网络虽然可以检测出不同尺寸的目标,但其对于小、中目标的检测效果较差,参见图2。将ssd网络中用于检测的不同卷积层conv4_3、fc7和conv8_2进行可视化,并获得不同卷积层的检测结果,其中猫的检测概率值在0.1至0.77之间,存在误检为人或狗的情况,误检概率值在0.1至0.45不等,误检和漏检的情况较多,conv4_3主要用于检测小目标,正确检测猫的概率值只有0.1,多数目标误检为人,fc7、conv8_2可用于检测中目标,在猫的检测上,存在较多的误检和漏检。可见ssd网络对小、中目标的检测仍然有很大的改进空间。本发明则从ssd网络低层和高层上出发,使用不同的改进策略,以提高目标检测效果。
步骤三:改进低层结构,参见图3。对ssd网络中的conv4_3通过反卷积获得高分辨反卷积层,将已训练好的ssd模型的输出作为建议区域,通过区域映射操作映射到反卷积层上后获得deconv2层,经过区域特征池化获得固定尺度的pconv2层以便进行之后的卷积检测。浅层可获得更丰富的特征细节信息,如果选择太浅的层会缺乏语义信息,因此选择与conv4_3相邻的conv3_3进行协调权衡,由于conv3_3尺寸为conv4_3近两倍,特征图分辨率较高,从网络的计算量考虑,对conv3_3通过特征提取即可,之后依然将ssd模型的输出作为建议区域,同样经过区域映射后获得conv1层,区域特征池化后获得pconv1层。
改进低层方法的本质是对特征图中对应目标特征区域进行放大,参见图4。图4(a)为尺寸300×300的输入图像,图4(b)为尺寸38×38的conv4_3可视化特征图,图4(c)为反卷积获得的300×300高分辨率特征图,图4(d)为将建议区域映射到图4(c)上并池化得到的38×38区域特征图。图4(d)与图4(b)的特征图尺寸相同,但是图4(d)的特征信息相比于图4(b)有所增大,有助于提升对小目标检测性能。
步骤四:改进高层结构,参见图5。通过特征层提取的方法,提取ssd网络中fc7层、conv8_2层、conv9_2层、conv10_2层、conv11_2层对应的卷积特征图,分别获得conv3、conv4、conv5、conv6、conv7。
步骤五:改进方法整体结构图参见图6。通过对ssd中低层conv3_3和conv4_3使用区域放大方法,对ssd中相应高层进行特征提取,加深网络结构,重构特征金字塔,利用改进之后的低层和高层特征层分别进行目标类别和位置的检测。
目标检测:通过对比ssd低层和改进低层对小目标的检测效果,验证改进低层方法的有效性,参见图7。图7(a)为ssd低层对汽车的检测结果,概率值只有0.02。图7(b)为改进方法低层对汽车的检测结果,概率值为0.13,概率值提升了11%。
通过对比ssd高层和改进高层对中目标的检测效果,验证改进高层方法的有效性,参加图8。图8(a)、图8(b)和图8(c)分别对应ssd网络中fc7层、conv8_2层和conv9_2层目标检测结果,图8(d)、图8(e)和图8(f)分别对应改进方法conv3层、conv4层和conv5层目标检测结果,其中ssd方法高层检测目标为人的概率值在0.23至0.7之间不等,除最高概率值0.7以外,其余概率值小于0.45,检测值较低且存在漏检,改进方法则检测出更多的目标,检测概率值更高,检测效果更好。
图9为改进方法和ssd方法不同目标的检测结果,验证本发明的有效性。图9(a)为ssd方法检测结果,图9(b)为改进方法检测结果,绿色框为ssd方法漏检的目标,黄色框为ssd方法误检的目标,紫色框为改进方法相比于ssd方法检测概率值高的目标。改进方法检测出的小目标、中目标更多,较好的改善了误检、漏检的情况,检测概率值更高。
本发明的技术效果通过以下的实验就进行说明:
实验对象为mscoco数据集。
实验步骤:
(1)从mscoco数据集中分别挑选124张包含有小目标的图像、130张包含有中目标的图像作为测试集。
(2)使用ssd方法、fssd方法和本发明提出的改进方法分别对小目标和中目标测试集进行测试比较,检测结果用平均精度均值map(meanaverageprecision)衡量。fssd为目前流行的改进ssd检测效果更好的方法。
(3)针对人类别,从mscoco数据集挑选小目标和中目标共1100个,使用检测率衡量不同模型对于目标的检测效果,验证改进方法对于单个类别的检测敏感度。
实验数据统计:
在相同网络参数设置下,分别使用不同的模型对中目标测试集进行测试比较,得到检测结果如表1所示:
表1
从表1可看出,改进模型相比ssd模型、fssd模型在中目标的检测精度上有明显的改善,fssd模型在中等占比目标上的检测精度为67.9%,相比于ssd模型有8.8%的提升,改进模型的检测精度相比于fssd模型提升了6.8%,相比ssd模型提升15.6%。
在相同网络参数设置下,分别使用不同的模型对小目标测试集进行测试比较,得到检测结果如表2所示:
表2
从表2可知,改进模型对小目标的检测精度为42.4%,相比fssd模型有9.8%的提升,相比ssd模型提高了27.1%,而fssd模型相比ssd模型提升了17.3%,改进方法在小目标检测上亦起到了更好的作用。
表3列出了在相同网络参数设置下,不同模型对于单类别人的检测率。
表3
表3中改进模型的检测率最高为84.5%,ssd模型为74.5%,相差10%,fssd模型为76.0%,改进模型相比fssd模型提升8.5%,fssd模型相比ssd模型提升1.5%。
表4给出了不同模型在titanxpgpu上的检测速度。
表4
表4中结果表明,fssd模型的检测速度为48fps,略低于ssd模型55fps的检测速度。改进模型的fps为24,改进模型检测单张图像消耗的时间为ssd模型和fssd模型的近两倍。这是由于改进模型新增加的层虽有助于提高精度方面的性能,但也加深了网络,新加的这些层,使得模型需要进行更多的计算,从而对检测速度产生一定的影响。一般的视频流通常为每秒25帧图像,因此本发明仍能满足实时检测的要求。
- 还没有人留言评论。精彩留言会获得点赞!