一种合欢皮识别平台和利用该平台的合欢皮识别方法与流程
本申请涉及中药检测技术领域,具体涉及一种合欢皮识别平台和合欢皮识别方法。
背景技术:
复杂样本的化合物构成具有极端复杂性。中药即是典型的复杂样本,所含成分极其复杂,结构多样、种类繁多,常见类型包括酚类、生物碱类、皂苷类、萜类、黄酮类、内酯类、蒽酮类、有机酸类以及鞣质类等,单一中药即包含数百上千计的次生代谢产物和小分子成分,由多种中药组合的中药复方制剂的成分则更多。相应地,复杂样本中蕴含海量信息。如中药化合物之间的相互关系、不同中药的药性药效差异、同属药材化学成分异同及产地、年份、生长环境对药材质量的影响等科学问题都蕴藏其中。
目前对于复杂样本的研究面临两个重要瓶颈:一方面,研究大多采用碎片化、点状的低维数据,如色谱保留时间,m/z值,子离子碎片信息等,这些低维数据忽视也无法体现上述大量化学成分间的关联。高维数据恰是海量信息的有力载体。与低维数据相比,高维数据能够有效地表示样本中各数据点的空间信息从而反映它们的空间关系。因此,获取复杂样本化合物的高维数据才能真正实现从复杂样本中得到、处理、挖掘那些高价值信息。另一方面,实验产生的数据资源庞大却零散,相关研究产生的数据不能整合利用,导致科研工作中人力、物力、时间等投入的成本高,产出却不显著。数据库技术是一种计算机辅助管理、整合数据的方法。将高维数据与数据库技术结合建立高维数据数据库正是解决上述难题的方向。
高维数据的获取需要联用仪器来实现。色谱-质谱联用技术将应用范围极广的分离方法-色谱法与灵敏、专属、能提供分子量和结构信息的质谱法结合起来,显然是复杂样本高维数据获取的理想手段。目前,已有一些基于色谱-质谱联用技术的数据库,大致可以分为两类:
1.标准化合物质谱数据库:如美国国家科学技术研究院(nist)出版的nist标准化合物质谱数据库,收录了几万张标准质谱图,在以gc-ms平台的代谢组学研究中发挥巨大作用;又如人类代谢组数据库(humanmetabolomedatabase,hmdb)是目前最完整且最全面的人类代谢物和人类代谢数据库。这类数据库在许多研究领域得到了广泛的应用。然而该类型数据库能够提供的化合物数目是有限的,并且没有提供化合物的色谱保留信息。张加余等(药学学报,2012,47(9):1187-1192)利用高效液相-电喷雾离子阱串联质谱(hplc-esiit-ms/ms),以商业化工作站谱库编辑程序为平台建立了含有636个天然化合物(包括黄酮、香豆素、木质素、萜及其苷类、甾体及其苷类、有机酸、生物碱、蒽醌、氨基酸等常见类型的天然产物)的液相色谱-质谱-数据库(lc-ms-ds),用于天然产物未知组分的鉴定和靶向分离。该数据库属于标准化合物质谱数据库,且可通过匹配未知组分和对照品的保留时间、紫外吸收光谱或者比较未知组分和对照品的多级质谱图中主要离子碎片是否相同来评价谱库检索的可信度,从而提高结果的可信度。该数据库仅能用作化合物的鉴定,无法用于包括天然产物在内的生物样本的鉴定。
2.化合物信息库:waters公司推出的unifi中药数据库包含了2010版中国药典中所列所有草药以及与这些草药相关的几千种化合物信息(文献已报道的主要化合物)。该数据库需以超高效液相色谱(uplc)和四极杆飞行时间质谱(qtofms)为基础获得待测中药的色谱-质谱数据,根据精确分子量推测分子式并与数据库中的化合物结构匹配,将软件计算的理论碎片与采集的二级离子进行匹配进行确证。该数据库的优势在于整合了2010版中国药典中所有草药及主要化合物,化合物规模达几千种。相对于标准物质来源有限的标准化合物质谱数据库,该数据库的化合物数目规模增加的可行性是显而易见的。但该数据库实际上并没有每个化合物的真实色谱-质谱数据,化合物的鉴定仅利用高分辨质谱获得精确分子量推测分子式,通过结合理论计算二级碎片匹配提高可信度。尽管高分辨质谱能够提供化合物的精确分子量来推测可能的分子式,但同一分子式对应的可能候选物数量很多,尽管该数据库化合物总数达几千个,但每种中药平均化合物仅几十个,且多为高含量常见化合物。中药化学成分具有典型的复杂多样性,每种中药可能存在成百上千种成分,该数据库中的化合物可能仅包含待测中药中很小一部分化学成分,对于中低含量成分的鉴定能力十分有限。并且理论计算二级碎片技术目前尚未成熟,准确性不高,匹配结果可能存在偏差,造成假阳性或者假阴性。该数据库同样存在兼容性的问题,仅适用于waters工作站系统。范骁辉等发明了一种适用于天然产物质谱数据解析的数据库构建方法(申请号201510443268.7)。该方法从pubchem、ca或reaxys化合物数据库上下载相关的所有化合物,基于裂解规律对化合物进行计算机模拟裂解,获得该化合物的裂解碎片,记录化合物和碎片的相关信息,然后建立数据库。该方法较unifi中药数据库包含的化合物数量丰富,裂解规律基于已有文献报道的裂解规律结合计算机模拟裂解完成化合物鉴定,相对地增加了结果的可靠性。但与unifi中药数据库相同,该数据库数据仅基于化合物结构信息数据,没有化合物实际谱图;另外,不同仪器、不同参数对化合物的碎裂行为影响很大,该数据库对不同来源(仪器、实验条件等)的适应性不明确。
上述色谱-质谱联用数据库均以化合物为主体,关注于数据中单一维度的特征,部分数据库存在多维度数据,但没有将多维度的数据转化成高维数据整合使用。本发明建立的中药色谱-质谱高维图像数据库以中药整体为主体,既包括中药整体信息,也包括中药化合物的单点信息。本发明中药色谱-质谱高维图像数据库可用于中药的识别、分类、质量控制、数据的深度挖掘等多方面的研究使用。
需要特别指出的是,本发明中药识别方法可适用于样本分析条件相近或相似获得的数据,使得该方法的适用性大大提高。
技术实现要素:
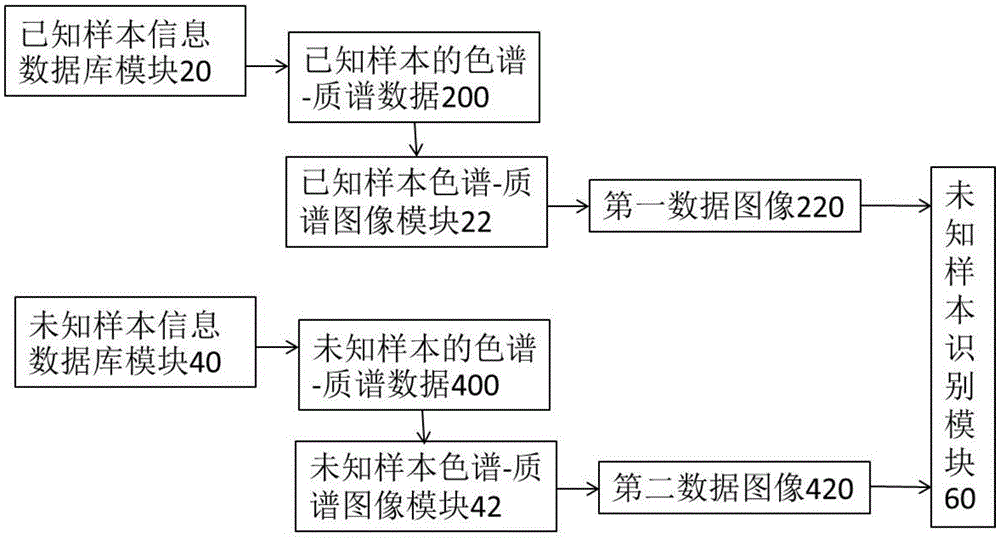
为解决现有技术中存在的问题,本发明的一个方面提供了一种合欢皮识别平台,该平台包括以下模块:
已知样本信息数据库模块、未知样本信息数据库模块、已知样本色谱-质谱图像模块、未知样本色谱-质谱图像模块和未知样本识别模块;
所述已知样本信息数据库模块向所述已知样本色谱-质谱图像模块传输已知样本的色谱-质谱数据,所述已知样本色谱-质谱图像模块输出第一数据图像;
所述未知样本信息数据库模块向所述未知样本色谱-质谱图像模块传输未知样本的色谱-质谱数据,所述未知样本色谱-质谱图像模块输出第二数据图像;
所述未知样本识别模块,用于记录所述已知样本的样本信息以及所述生成的第一数据图像,并将所述生成的第二数据图像与所述第一数据图像进行比对,以确定所述未知样本的色谱-质谱数据是否与已知样本的色谱-质谱数据匹配。
在优选的实施方式中,已知样本的色谱-质谱数据包括已知样本的原始色谱-质谱信息,未知样本的色谱-质谱数据包括未知样本的原始色谱-质谱信息。
在优选的实施方式中,已知样本的色谱-质谱数据还包括已知样本中各个化合物的高维数据,未知样本的色谱-质谱数据还包括未知样本中各个化合物的高维数据。
高维数据表达样本中各数据点间的空间信息,是以下至少一种信息构成的矩阵:数据点间的距离信息;数据点间的角度关系信息;数据点的坐标位置信息;数据点的密度信息;数据点集合的边缘范围信息;数据点的强度信息。
优选地,数据点间的距离信息包括色谱保留时间t、m/z值、m值、z值、峰强度i中的至少一种。
优选地,数据点的强度信息包括由数据点的大小或亮度的强弱反映出来的信息中的至少一种。
优选地,可将高维数据存储为表格文件或文本文件,进一步优选地,表格文件是.xls、.xlsx、.csv、.xml中的一种或多种,文本文件为.doc、.docx、.txt、.rtf中的至少一种。
在优选的实施方式中,高维数据生成的高维数据图像包括高维数据生成的原始图像、基于图像特征生成的图像、对图像进行转化处理生成的图像、利用函数构建的图像中的至少一种。
优选地,图像特征包括数据点点簇、共同粒子、样本轮廓。
优选地,图像转化处理包括将图像模糊化处理或对图像进行不同分辨率的处理中的至少一种。
优选地,函数包括色谱保留时间t、m/z、m、i中的至少一种。
优选地,高维图像是二维以上维数的图像;
优选地,可将图像文件存储为任意图像文件格式。
在优选的实施方式中,已知样本包括标准品和已知中药样本中的至少一种。
优选地,标准品包括《2015版中国药典》的中药的对照品、中药标志性成分、中药主要化学成分中的至少一种。
优选地,已知中药样本为类别信息明确的样本,类别信息包括样本的种属、产地、部位、炮制方式中的至少一种;
优选地,已知中药样本包括中药原药材、饮片、粉末中的至少一种。进一步优选地,已知中药样本包括中药的不同部位和它们的加工品中的至少一种。
在优选的实施方式中,未知样本识别模块包括图像分割工具或者聚类工具。
在优选的实施方式中,本发明提供的合欢皮识别平台中的各数据库模块中的数据库类型包括文件夹数据集、网页数据库、基于商业化工作站或基于用户自研发工作站的数据库中的至少一种。
优选地,数据库格式包括文本、excel、oracle、mysql、splite或microsoftsqlserver中的至少一种。
本发明的另一方面提供了一种应用合欢皮识别平台识别合欢皮的方法,该方法至少包括以下步骤:
1)使用色谱和质谱获取已知样本和未知样本的原始色谱-质谱数据;
2)生成已知样本和未知样本的色谱-质谱高维数据,色谱-质谱高维数据表达各数据点间的空间信息;
3)生成已知样本和未知样本的色谱-质谱高维数据图像,使高维数据中的每个离子与构成图像中的点一一对应,每个点拥有自己的坐标信息,每个点的强度由点的大小或/和亮度的强弱表示,高维数据图像中的点与高维数据一一对应;
4)利用图像分割工具或聚类工具将未知样本的色谱-质谱高维图像中的点分割为n个点簇(n为≥1的整数),将提取点簇后的未知样本的色谱-质谱高维图像与已知样本质谱-色谱的高维图像逐一进行分别扫描和匹配;
5)将与未知样本匹配的已知样本按匹配度进行排名,在未知样本的原始色谱-质谱数据信息和/或高维数据信息中按所述匹配度排名依次检索,对应已知样本的标志性化合物,所述标志性化合物数目≥1,未知样本中检索到标志性化合物时即接受未知样本是该已知样本,停止检索;若第一排名已知样本在未知样本中未搜索到,接下来在未知样本中检索第二排名已知样本标志性化合物,以此类推,一直到检索到标志性化合物为止;若所有匹配到的已知样本中的标志性化合物在未知样本中都没有检索到,即认为已建立的数据库中没有包含该未知样本;
在优选的实施方式中,坐标信息包括数据点间的距离信息、数据点间的角度关系信息、数据点的坐标位置信息、数据点的密度信息、数据点集合的边缘范围信息和数据点的强度信息中的至少一种。
在优选的实施方式中,点簇是在空间上距离接近的数据点的集合,点簇内数据点的个数n≥3。
优选地,所述每个点簇有自己的中心点。
优选地,所述点簇的形状为任意形状。
在优选的实施方式中,已知样本和未知样本的原始色谱-质谱数据通过以下步骤获取:
使用色谱仪和离子迁移谱仪器,通过选择性作用将已知和未知样本中混合的分子进行分离,获得不同的色谱保留时间信息t;
利用质谱仪的电磁场作用,根据分子的质荷比不同进行样本中各化合物的分离和检测,获得不同的质荷比信息m/z;
将样本提取物利用色谱-质谱仪器进行分析,即得原始色谱-质谱数据;
在优选的实施方式中,色谱分离所用的时间t的范围是1-10000s,离子的m/z扫描的范围50-10000da。
在优选的实施方式中,上述方法还可以包括将所获取的原始色谱-质谱数据经过保留时间校正、过滤和归一化中的至少一种数据处理。
在优选的实施方式中,该方法还可以包括使用质量控制样本和混合标准品内标物的步骤。
优选地,质量控制样本包括已知样本或其混合物、未知样本或其混合物以及两种以上标准品的混合物中的至少一种,该质量控制样本用于评价数据质量。
优选地,在采用混合标准品时可以使用混合标准品内标物,以提高测定的重复性和进行保留时间校正。
在优选的实施方式中,未知样本是中药原药材、饮片、粉末、制剂、中药的不同部位以及它们的加工品中的至少一种。
优选地,制剂包括中药颗粒或制备质中药注射液。
本申请能产生的有益效果包括:
1)本发明建立的合欢皮识别平台包括中药色谱-质谱高维图像数据库,该数据库以中药整体为主体,既包括中药整体信息,也包括中药化合物的单点信息。因此本发明的中药识别平台能够很好地揭示中药各复杂成分之间的关联,能够对中药样本中大量化合物间的空间信息实现全面表征。
2)本发明的合欢皮色谱-质谱高维图像数据库可用于中药的识别、分类、质量控制、数据的深度挖掘等多方面的研究使用。
3)本发明的合欢皮识别方法适用于样本分析条件相近或相似获得的数据,使得该方法的适用性大大提高。
4)本发明的合欢皮识别方法利用样本的空间信息实现已知样本与未知样本的匹配与识别,具有快速、高通量、高精度和高可靠性等优势。
附图说明
图1为示出本发明构思的示意图。
具体实施方式
下面结合实施例详述本申请,但本申请并不局限于这些实施例。
以下对相关术语的统一解释如下:
在本申请中“高维”是指二维及二维以上的维度。“低维”为一维。
所述“共同离子”是指相同或者不同样本高维图像中的同一成分(保留时间和m/z相同)。
“样本轮廓”是指样本产生的高维图像的轮廓。
本发明构思的示意图如图1所示。
1、中药色谱-质谱高维图像数据库的建立:
1)在已知样本信息数据库模块20中获取与处理已知中药样本的原始色谱-质谱(x-ms)数据:使用色谱和质谱获取已知中药样本的原始x-ms数据,将已知中药样本原始x-ms数据导入诸如progenesisqi等的峰提取软件中,对色谱-质谱联用原始x-ms数据进行数据处理;
2)生成已知中药样本的高维数据200并在已知样本色谱-质谱图像模块22中生成高维数据图像:获取样本中每个化合物的m/z、t、i、m、z值,产生高维数据矩阵(如m/z-t-i矩阵、m-z-t-i矩阵或m-t-i矩阵),生成已知中药样本色谱-质谱联用高维数据200;将高维数据200导入诸如matlab等的图像生成软件来生成第一数据图像220。使高维数据中的每个离子与构成图像中的点一一对应,每个点拥有自己的坐标信息(例如t,m/z或m或m与z),每个点的强度由点的大小或/和亮度的强弱表示,高维数据图像中的点与高维数据一一对应;
3)建立已知中药样本的色谱-质谱高维图像数据库:将获得的1类或2类以上已知中药样本高维数据图像作为中药色谱-质谱高维图像数据库,每类已知中药样本中的样本数为1个或2个以上;中药色谱-质谱高维图像数据库,包括已知中药样本的样本信息、原始x-ms数据信息、高维数据信息、高维图像数据信息;
2、合欢皮的快速识别:
1)未知样本高维图像数据400的获取:采用与步骤1相同或相似的操作参数和条件,按步骤1中1)~2)操作,针对待分析的未知样本进行分析,获取未知样本原始x-ms数据和高维数据;利用图像生成软件将x-ms数据得到未知样本的x-ms第二数据图像420;
2)在未知样品识别模块60中识别未知样本;
a、利用机器学习中的诸如matlab2016b自带的分割程序的图像分割工具,或诸如k-means,dbscan或fanny等的聚类工具,将未知样本x-ms高维图像中的点分割为n个点簇(n≥1整数);
点簇指的是在空间上距离接近的点的集合,点簇内点的个数n≥3;
每个点簇可以有自己的中心点,点簇的形状可以为任意形状;
b、将提取点簇后的未知样本x-ms第二数据图像420与中药x-ms高维图像数据库中的已知中药样本x-ms第一数据图像220逐一进行分别扫描和匹配;
扫描时,将两个x-ms高维图像的原点、t轴和m/z(m)轴对齐;
扫描时,将点簇作为一个整体,移动的范围为0-tk,其中tk为已知中药样本对应的最大分析时间;
扫描时,未知样本的每个点簇保留其m/z(或m)轴的位置和几何形状,沿时间轴(t)进行扫描;
通过扫描,寻找未知样本点簇与已知中药样本x-ms高维图像中能够在t和m/z(或m)能够准确匹配的共同点;扫描过程中,在未知样本中的一个点簇中的点与已知中药样本x-ms高维图像中的点进行匹配时,每个点允许的t绝对偏移值(ttolerance)为≥t,t等于未知样本x-ms数据采集时色谱仪允许的保留时间平均偏移值(绝对值,可用1个或1个以上标准品,或某样本中的1个或1个以上化合物的多次重复测定计算)与已知中药样本x-ms数据采集时色谱仪允许的保留时间平均偏移值(绝对值,可用1个或1个以上标准物质,或某样本中的1个或1个以上化合物的多次重复测定计算)之和;
扫描过程中,在未知样本中的一个点簇中的点与已知中药样本x-ms高维图像中的点进行匹配时,每个点允许的m/z(或m)绝对测定误差[m/z(或m)tolerance]≥a,a等于未知和已知中药样本x-ms数据采集时质谱仪扫描时允许的质量平均偏差(绝对值,可由仪器所用的校正液多次重复测定)之和;
当未知样本点簇内一个点与已知中药样本的某个点满足t偏差和m/z(或m)偏差时,认为该点符合匹配要求;
扫描时,点簇沿时间轴(t)扫描的步长≤t,通常情况下,0s<t<10000s;
c、当一个点簇移动到已知中药样本x-ms高维图像的t轴的每一个位置时,记录匹配点的个数、每个匹配点的坐标和点簇几何中心点的坐标;
d、计算每一个位置时,未知样本一个点簇(i,i≥1整数)与该已知中药样本x-ms高维图像之间的匹配度(si),匹配度的大小可利用诸如matlab的统计工具来计算点簇(i)与已知中药样本x-ms高维图像所匹配的点数、或相似度(如图像相似度计算中的欧氏距离法)、或相关度(如matlab中的2d-correlationcoefficient)中的一种或二种以上进行计算;
由上述三种方法得到的匹配度分别由点数(或点数的函数)、相似度或相关度表示;
点簇匹配度大小,与点簇匹配的点数、坐标位置(t,m/z)和强度这四个变量呈线性或非线性相关;计算点数(或点数的函数)、相似度或相关度的基础是基于四个变量的关系变换;
可选用不同的匹配度计算方法分别计算点簇和已知中药样本x-ms高维图像的整体匹配度;
匹配点的个数指的是点簇符合匹配条件点的个数;基于上述步骤,对未知样本x-ms高维图像中每一个点簇的最大匹配度(si)进行数学加权处理(如加和、平均或取对数),得到未知样本x-ms高维图像与已知中药样本x-ms高维图像的整体匹配度(sc);
e、重复上述步骤,逐一分析未知样本x-ms高维图像与其它已知中药样本x-ms高维图像之间的匹配度,得到其与每一个已知中药样本的整体匹配度(sc);
f、未知样本的所属类别可不借助阈值或借助阈值进行判定;
当不借助阈值时,利用上述步骤,将未知样本与已知中药样本进行匹配,对匹配度从大到小进行排序,若未知样本与某一已知中药样本的匹配度排名越靠前,表明未知样本为与该样本的可能性越大,反之越小;
当借助阈值时,设定阈值γ,用于判断不同来源未知样本与同类已知中药样本匹配的可信范围;
阈值可以根据统计学的方法设定:按步骤1中1)~2)操作,采用相同或相近的操作参数和条件,选取2个以上同类别的已知中药样本作为某一类样本的训练样本,进行分析,获取x-ms原始数据;利用图像生成软件(如matlab2016b)将x-ms原始数据或多维信息文本转化为x-ms高维图像,得到该类样本的训练x-ms高维图像集;利用训练x-ms高维图像集,与同类已知中药样本x-ms高维图像进行匹配,通过统计学的方法(如概率,比率等)发现匹配度分布区间,选定分布区间中匹配度的下限作为该类样本的阈值γ;
此外,阈值可以利用文献报道或实验观察得到某类样本(n≥2)与已知中药样本匹配度分布区间(按步骤1中1)~2)操作采用相同或相近的操作参数和条件所得到的分析结果),选定分布区间中匹配度的下限作为该类样本的阈值γ;
将未知样本与已知中药样本进行匹配,匹配度按照从大到小进行排序,若未知样本与某类已知中药样本的匹配度排名越靠前,且sc大于由该类已知中药样本测定所得的阈值γ,表明未知样本为该类样本的可能性越大,反之越小;
3)未知样本识别结果的验证
将步骤2中与未知样本匹配的已知中药样本按匹配度排名排列,在未知样本的原始x-ms数据信息和/或高维数据信息中按上述匹配度排名依次检索对应已知中药样本的标志性化合物(标志性化合物数目≥1),未知样本中检索到标志性化合物时即接受未知样本是该已知中药样本,停止检索;若第一排名已知中药样本在未知样本中未搜索到,接下来在未知样本中检索第二排名已知中药样本标志性化合物,以此类推,一直到检索到标志性化合物为止;若所有匹配到的已知中药样本中的标志性化合物在未知样本中都没有检索到,即认为已建立的数据库中没有包含该未知样本。
在步骤2中,在已知样本数据库中是否具有标准品时,稍有不同:
具有标准品的标志性化合物的检索:采用步骤1中的方法,获得标准品样本的高维数据。将标志性化合物高维数据与未知样本高维数据匹配,寻找未知样本中与标志性化合物保留时间t和m/z均满足阈值窗口的离子;
不具有标准品的标志性化合物的检索:搜索未知样本中标志性化合物的m/z值,寻找未知样本中与已知中药样本中标志性化合物保留时间t和m/z均满足阈值窗口的离子。
步骤1中,为使未知样本与已知中药样本具有可比性,在进行未知样本制备、原始数据获取、数据处理时,各样本的均应采取相同或相似的可重复的样本处理、原始数据获取和数据处理方法。
步骤1中,色谱仪的保留时间平均偏差(绝对值)指的是色谱仪器在同样条件下重复测定同一样本时各个化合物的时间偏差的均值(绝对值),可用混合标准品进行测定。
步骤1中,原始色谱-质谱数据通过以下方法获得:
1)色谱仪和离子迁移谱仪器通过选择性作用,将中药样本中混合的分子进行分离,获得不同的保留时间信息t;
2)质谱仪通过电场或磁场作用,根据分子的质荷比不同进行分离和检测,获得不同的质荷比信息m/z;
3)中药样本提取物利用色谱-质谱仪器进行分析,色谱分离所用的时间(t)范围为1-10000s.离子(m/z)扫描的范围50-10000da;得到色谱-质谱(x-ms)数据。
步骤1中,所获取的原始数据可以经过保留时间校正、过滤和归一化等中的一种或二种以上数据处理;其中保留时间校正可以采用待分析样本中的若干(≥2)化合物保留时间校正、混合标准品内标物保留时间校正或者其它保留时间校正方式。
高维数据可以包括高维数据矩阵中所有离子,或也可以选择性保留高维数据矩阵中的离子。
高维数据图像的斑点位置由该化合物的性质决定:纵轴代表色谱保留时间,化合物按极性由大到小延纵轴方向分布;横轴代表m/z值,化合物按m/z值由小到大延横轴方向分布;同一化合物在质谱中可以存在准分子离子、加和离子、碎片离子等多种形式,每个化合物可以存在相同纵轴位置不同横轴位置的斑点;性质相近的化合物(斑点)会形成区域性的点簇,代表某一类型物质。
色谱-质谱数据中包含的离子数量越多,构建出来的色谱-质谱高维图像信息越丰富越有利于识别。
噪音会引起识别偏差,利用原始色谱-质谱数据中每个离子的信噪比或同位素分布形态进行早期除噪,越有利于提高识别的准确度。
步骤1不需要强制的时间校正。
数据库中的色谱-质谱信息或离子迁移谱-质谱信息可拓展为二维、三维或更高维度。
实施例1中药色谱-质谱高维图像数据库的建立
一、已知中药样本的制备
中药样本的制备方法包括但不局限于溶剂提取,包括适用于一切中药样本制备的方法。本发明数据库中的已知中药样本采用来自于中国食品药品研究院的547个品种的对照药材(参见表1)。取每种对照药材粉末各100mg,分别加入体积浓度50%甲醇0.5ml,超声提取10min,15000转/分钟高速离心10min取上清液,滤渣再次加入0.5ml体积浓度50%甲醇超声提取10min,15000转/分钟高速离心10min取上清液。合并两次得到上清的提取液。
二、已知中药样本色谱-质谱原始数据获取与数据处理
本发明基于色谱-质谱联用技术获取已知中药样本原始数据。已知中药样本原始数据需在同一条件下分析,以获得具有可比性的色谱-质谱高维图像。采用agilent1290超高效液相色谱系统(agilent,waldbronn,germany)串联6520q-tof-ms(agilentcorp,usa)。
1.色谱方法
采用agilent公司zorbaxeclipseplusc18色谱柱(3.0×150mm,1.8μm),流动相a相为水(0.5%乙酸),b相为乙腈,梯度洗脱:0至15分钟,b相5%-100%,15至20分钟,b相保持100%,20至21分钟,b相100%-5%,21至25分钟,b相保持5%,流速为0.3ml/分钟。柱温为60℃,进样量为2μl。
2.质谱方法
质谱采用esi离子源,负离子模式采集数据。数据采集范围m/z100-3200。温度为350℃,干燥器流速8l/分钟,雾化气压力40psi,毛细管电压3500v,fragmentor电压200v,skimmer电压65v。
3.已知中药样本色谱-质谱原始数据的数据处理
本发明原始数据包括样本提取物中每一个化合物的色谱信息,如色谱保留时间和峰强度,和质谱信息如质荷比。原始数据处理包括数据的校正、过滤和归一化。将原始数据导入峰提取软件progenesisqi,设置阈值为基峰强度为0.005%去除噪音信号,获取样本中每个化合物的m/z,t和i值,产生m/z-t-i数据矩阵,以excel表格.csv文件格式存储。
三、已知中药样本高维数据和色谱-质谱高维图像的获取
1.高维数据的获取
将“原始数据的处理”步骤文件导入matlab软件,保留离子强度排名前2000名的离子。
2.高维数据图像的建立
本发明色谱-质谱高维图像中的点与高维数据一一对应。将上述高维数据导入matlab软件,以m/z和t为坐标,绘制出样本的m/z-t-i图,每个可测化合物具有特定的质量和时间坐标,化合物的质谱信号强度(峰值)i值以点的面积或以点的色度值表示。
3.色谱-质谱高维图像的转化
本发明高维数据图像可采用上述步骤建立的原始图像,对图像进行转化处理,包括图像模糊化处理,图像不同分辨率处理等处理方式。
四、色谱-质谱高维图像的空间信息
本发明x-ms高维图像中包括但不仅限于斑点和点簇。每个斑点由一个化合物产生,但每个化合物可以产生一个或一个以上的斑点。斑点位置由该化合物的性质决定:纵轴代表色谱保留时间,化合物按极性由大到小延纵轴方向分布;横轴代表m/z值,化合物按m/z值由小到大延横轴方向分布;同一化合物在质谱中可以存在准分子离子、加和离子、碎片离子等多种形式,因此每个化合物可以存在相同纵轴位置不同横轴位置的斑点。性质相近的化合物(斑点)会形成区域性的点簇,代表某一类型物质。
五、中药色谱-质谱高维图像的建立
本实施例建立的数据库包括但不仅限于文本、excel、oracle、mysql、splite或microsoftsqlserver等。得到547个品种的对照药材的中药色谱-质谱高维图像数据库,其中包括:1)excel格式的样本信息库,包括样本编号、名称、来源、规格、药材部位、目、科、属、种;2)文件夹格式的所有品种色谱-质谱原始数据数据库;3)文件夹格式的所有品种高维数据高维图像数据库。
实施例二:合欢皮样本的快速识别
一、未知样本的制备
本发明未知样本制备方法与已知中药样本的制备方法相同。本实施例采用来自于市场的3批合欢皮作为未知样本,分别命名为ss2-6520-007-0001(ss2-ltq-007-0001为同一样本不同采集仪器)、ss2-6520-225004-03、ss2-6520-225142-03。取每种未知样本粉末各100mg,分别加入体积浓度50%甲醇0.5ml,超声提取10min,15000转/分钟高速离心10min取上清液,滤渣再次加入0.5ml体积浓度50%甲醇超声提取10min,15000转/分钟高速离心10min取上清液。合并两次得到上清的提取液。
二、未知样本x-ms原始数据获取与数据处理
本发明基于色谱-质谱联用技术获取未知样本原始数据。未知样本原始数据需与已知中药样本在相同或相似条件下分析,以获得具有可比性的x-ms高维图像。本实施例中未知样本ss2-6520-007-0001、ss2-6520-225004-03、ss2-6520-225142-03采用agilent1290超高效液相色谱系统(agilent,waldbronn,germany)串联6520q-tof-ms(agilentcorp,usa)、未知样本ss2-ltq-007-0001采用watersacquityuplc串联thermofisherltqorbitrapelite获取未知样本原始数据。
1.色谱方法
本实施例中采用agilent公司zorbaxeclipseplusc18色谱柱(3.0*150mm,1.8um),流动相a相为水(0.5%乙酸),b相为乙腈,梯度洗脱:0-15min,b相5%-100%,15-20min,b相保持100%,20-21min,b相100%-5%,21-25min,b相保持5%,流速为0.3ml/min。柱温为60℃,进样量为2ul。
2.质谱方法
本实施例中agilent6520/6540q-tof-ms质谱采用esi离子源,负离子模式采集数据。数据采集范围m/z100-3200。温度为350℃,干燥器流速8l/min,雾化气压力40psi,毛细管电压3500v,fragmentor电压200v,skimmer电压65v。
thermofisherltqorbitrapelite采用esi离子源,ft负离子模式采集数据,分辨率60000,数据采集范围m/z100-2000。毛细管温度为300℃,干燥气流速10l/min,雾化气压力35psi,毛细管电压5kv,s-lensrf:60%。
3.未知样本色谱-质谱原始数据的数据处理
原始数据包括样本提取物中每一个化合物的色谱信息,如色谱保留时间和峰强度,和质谱信息如质荷比。原始数据处理包括数据的校正、过滤和归一化。将原始数据导入峰提取软件progenesisqi,设置阈值为基峰强度为0.005%去除噪音信号,获取样本中每个化合物的m/z,t和i值,产生m/z-t-i数据矩阵,以excel表格.csv文件格式存储。
三、未知样本高维数据和色谱-质谱高维图像的获取
1.高维数据的获取
将“原始数据的处理”步骤文件导入matlab软件,保留离子强度排名前2000名的离子。
2.高维数据图像的建立
色谱-质谱高维图像中的点与高维数据一一对应。将上述高维数据导入matlab软件,以m/z和t为坐标,绘制出样本的m/z-t-i图,每个可测化合物具有特定的质量和时间坐标,化合物的质谱信号强度(峰值)i值以点的面积或以点的色度值表示。
3.色谱-质谱高维图像的转化
高维数据图像可采用上述步骤建立的原始图像,对图像进行转化处理,包括图像模糊化处理,图像不同分辨率处理等处理方式。本实施例中使用的是高维数据原始色谱-质谱高维图像。
四、未知样本的识别
1.利用机器学习中的聚类工具clusterdp,将首先将待检测样本ss2-6520-007-0001、ss2-ltq-007-0001、ss2-6520-225004-03、ss2-6520-225142-03的x-ms高维图像中的点分割为34个点簇;点簇内点的个数n≥10;
2.将提取点簇后的该待检测样本色谱-质谱高维图像与参照样本(m)的色谱-质谱高维图像进行分别扫描和匹配;
3.扫描时,将两个色谱-质谱高维图像的原点、t轴和m/z轴对齐,然后该待检测样本的每个点簇保留m/z轴的位置和几何形状,沿时间轴(t)进行连续扫描;通过扫描,寻找该待检测样本点簇与参照样本(m)色谱-质谱高维图像中能够在t和m/z能够准确匹配的共同点;
4.扫描过程中,点簇作为一个整体,移动的范围为0-tk,t为样本对应的有效分析时间,本实例取tk=1000s;
5.扫描时,点簇沿时间轴(t)扫描的步长为1s;
6.扫描过程中,在该待检测样本中的一个点簇与参照样本(m)色谱-质谱高维图像中的点进行匹配时,每个点允许的最小t偏差(ttolerance)为±30s;m/z(或m)允许的最小偏差[m/z(或m)tolerance]为±0.01da;
7.当一个点簇移动到参照样本(m)x-ms高维图像的t轴的每一个位置时,记录匹配点的个数、每个匹配点的坐标和点簇几何中心点的坐标;
8.利用matlab中的2dcorrelation函数计算该待检测样本一个点簇(i)与中药x-ms高维图像数据库中参照样本(m)之间的相关度;
9.计算该待检测样本每个点簇在t轴方向与参照样本色谱-质谱高维图像的最大相关度;
10.根据点簇在获得最大相关度的位置,利用计算点数的方法计算该待检测样本x-ms高维图像中每一个点簇与参照样本色谱-质谱高维图像的匹配度(si);
si代表第i个点簇对应的匹配度;k代表点簇中共有k个点符合匹配要求,
x,y,z指的是i,m/z,和t三个变量的指数,其中x≥0;y≥0;z≥0;
在本实施例中,取x=0;y=1/2;z=1/2;
11.根据上述步骤,计算该待检测样本x-ms高维图像与参照样本x-ms高维图像(m)的整体匹配度(sc);
n代表所有点簇在最大匹配度时对应的所有匹配点个数,
12.重复上述步骤,得到该待检测样本ss2-6520-007-0001与547类参照样本分别匹配,其中该待检测样本与合欢皮参照样本db-a2-2-0025的匹配度最高,为192.79%;
13.重复上述步骤,得到待检测样本ss2-ltq-007-0001、ss2-6520-225004-03、ss2-6520-225142-03与547类参照样本分别匹配,其中待检测样本均与合欢皮参照样本db-a2-2-0025的匹配度最高,分别为125.34%、194.56%和234.36%(所有参照样本的匹配度见附表2)。
五、未知样本识别结果的验证
按匹配度排序,未知样本ss2-6520-007-0001、ss2-ltq-007-0001、ss2-6520-225004-03、ss2-6520-225142-03对应匹配度最高的已知样本为合欢皮。参照未知样本的药材信息,合欢皮样本的识别正确。
以上所述,仅是本申请的几个实施例,并非对本申请做任何形式的限制,虽然本申请以较佳实施例揭示如上,然而并非用以限制本申请,任何熟悉本专业的技术人员,在不脱离本申请技术方案的范围内,利用上述揭示的技术内容做出些许的变动或修饰均等同于等效实施案例,均属于技术方案范围内。
表1
表2
- 还没有人留言评论。精彩留言会获得点赞!