一种基于神经网络的犯罪行为识别方法与流程
本发明涉及一种犯罪行为识别方法,尤其涉及一种基于神经网络的犯罪行为识别方法,属于自然语言处理和机器学习技术领域。
背景技术:
大数据和人工智能的信息科技迅速发展,为司法数据信息化建设提供了强有力的支撑。近些年来,“智慧法院”也成为了引人关注的重点计划。然而,面对海量的司法文本数据,如何高速有效利用信息抽取技术,从而准确抽取出文本中的犯罪行为,构建出完整的犯罪行为链,有效地提高司法质效,仍是一个亟待解决的问题。而在本发明中,即对于中文裁判文书的案情部分的“犯罪行为”进行深度挖掘分析。
现有的中文法律文本挖掘,主要涉及的是案件文本的分类和案件信息的抽取,大多更关注于对裁判文书进行关键词(主题词)的抽取,进而对裁判文书进行分类,其更多地属于针对文本的浅层分析和应用,未能充分考虑案件文本中以“犯罪行为”为核心的案情特征要素,并不能有效支撑法条推荐、类案推送、辅助量刑等辅助审判工作。在具体的司法实践中,我们还需要研究能够有效分析案件案情特征的方法。
由于中文信息处理缺少句子分词信息和词的形态变化,加上中文动词使用灵活、形式多变、结构复杂,识别犯罪行为是一项具有挑战性的任务。目前,信息抽取的研究更多地关注于人名、地名、组织、时间、日期等命名实体的抽取,以及实体间关系的抽取,涉及到犯罪行为词的抽取的研究还比较少,没有形成系统化、深入化的研究。在中文信息处理领域,也缺少针对犯罪行为的标注规范和标注数据集。与“犯罪行为”抽取最为贴近的是实体抽取、词性标注和语义角色标注。
技术实现要素:
本发明要解决的技术问题是:提供一种基于神经网络的犯罪行为识别方法,该方法通过介绍犯罪行为的概念,制定犯罪行为识别规范,并构建了犯罪行为数据集。此外,我们面向法律裁判文书,研究针对案情要素的行为关键词提取方法,围绕“犯罪行为词”提取关键案情要素特征。提出基于attentional-bilstm-crf神经网络结构的犯罪行为识别方法,该方法可以有效地提高犯罪行为识别的性能,有效的解决了上述存在的问题。
本发明的技术方案为:一种基于神经网络的犯罪行为识别方法,所述方法包括以下步骤:一、定义犯罪行为概念并制定犯罪行为标注规范,并构建犯罪行为数据集;二、面向步骤一中所得的数据集,以attentional-bilstm-crf神经网络结构模型为依托,进行犯罪行为识别。
所述步骤一中,犯罪行为指的是在案情文本中,句子中可以单独作谓语的动词,犯罪行为包括五种模式:单犯罪行为、复合结构犯罪行为、同义并列犯罪行为、带修饰或带补语的犯罪行为和其他特殊犯罪行为。
所述单犯罪行为为仅包含单个动词的犯罪行为;复合结构犯罪行为为使用重复的表达式来生成复合词的犯罪行为;同义并列犯罪行为为同时使用同义动词作为动词表达式的犯罪行为;带修饰或带补语的犯罪行为为动词带有时态标记、补语或修饰符的犯罪行为,其它特殊犯罪行为表达为使用名词化、形容词化、谚语、成语或典故的犯罪行为。
所述步骤二中,识别步骤为:给定一个输入序列句子,通过双向递归神经网络获取句子内部的依赖关系;然后,用注意力机制建模句子的焦点角色;最后通过crf层返回一条最大化的标注路径。
本发明的有益效果是:本发明针对案件裁判文书数据中文本结构规则性较强、专业术语多、关键词专业性强、主题词较为明确、逻辑关系严谨、人员间关联程度高、犯罪行为词时序关系明显等特点,致力于解决针对裁判文书的犯罪行为特征要素抽取,实现对案情信息的有效描述。如此,在后续工作中,我们可以借助犯罪行为,建立对应的“犯罪行为链”,以实现对于案情语义的深层分析,助力法院审判流程的信息化、智能化和服务化,继而提供更加优质的诉讼服务,提高审判工作的效率和严谨性。审判人员期望能够通过这些问题的解决,推动法院的智能化应用,提升司法辅助工作的智能化水平,继而推进案件审判工作的公平性和严谨性,取得了很好的使用效果。
附图说明
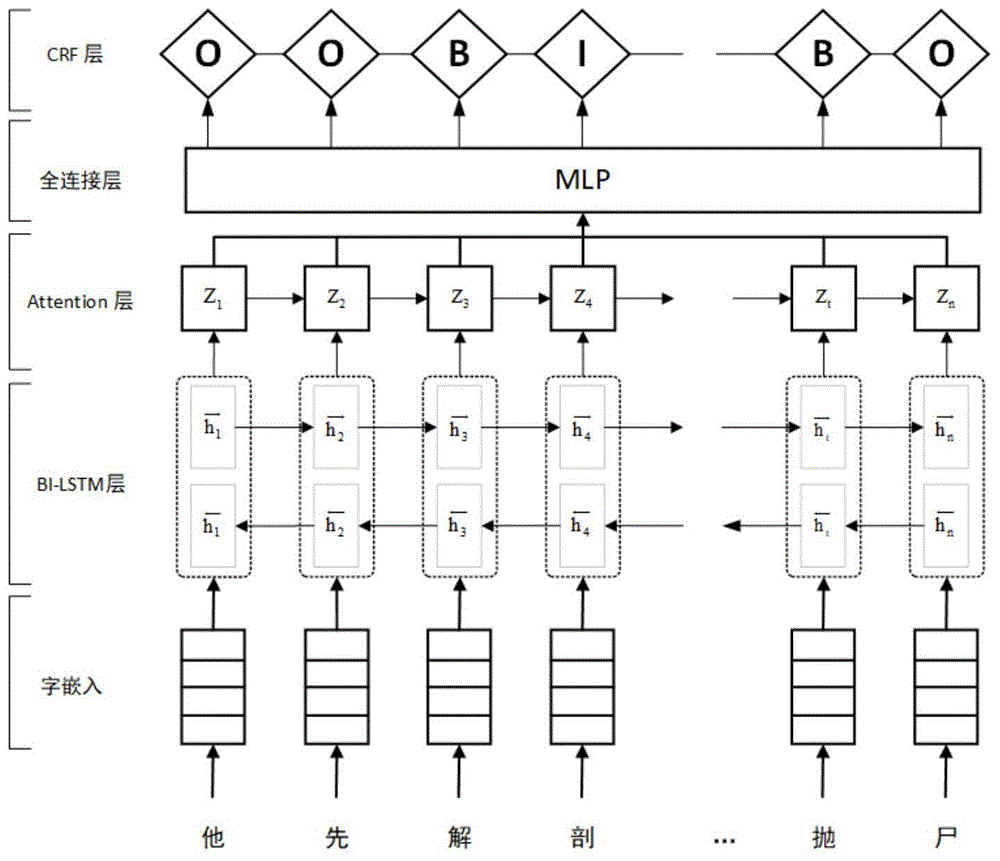
图1为本发明的犯罪行为识别模型。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将参照本说明书附图对本发明作进一步的详细描述。
实施例1:如附图1所示,一种基于神经网络的犯罪行为识别方法,所述方法包括以下步骤:一、介绍犯罪行为的概念,制定犯罪行为的标注规范,并构建犯罪行为数据集;二、面向步骤一中所得的数据集,以attentional-bilstm-crf神经网络结构模型为依托,进行犯罪行为识别。
所述步骤一中,犯罪行为包括五种模式:单犯罪行为、复合结构犯罪行为、同义并列犯罪行为、带修饰或带补语的犯罪行为和特殊犯罪行为。
犯罪行为指的是在案情文本中,句子中可以单独作谓语的动词。目前,犯罪行为还没有公开的标注数据集。由于犯罪行为使用灵活、形式多变、结构复杂,结合犯罪行为的表达方式、语法功能和统计特性,根据发明的需要,把犯罪行为分为五种模式:
模式1:单犯罪行为
仅包含单个动词的犯罪行为,如:不带修饰语、补语的及物动词和不及物动词。
由于中文单词之间没有分隔符,在词的划分上存在歧义。这里的单个动词,以词典的收录为准。因此,该模式涉及以下三个问题:1)许多登录动词里包含表示时态的字符。如,“王某取得一把尖刀”和“王某取出一把尖刀”,其中“得”和“出”可表示:刀已经“获得”或“取出”。“取得”在词典中能被查到,但“取出”不能。因此,只有“取得”属于该模式,被标记为单个犯罪行为。2)若某个由连续动词组成的复合动词已在词典中收录。则,该复合动词标记为单犯罪行为。如,“反叛者们正在打砸抢”,尽管“打砸抢”可以被分割为“打/砸/抢”,但它在词典中已收录。因此,标注为单犯罪行为。3)不及物动词。它们常由动词和名词组成。如,“下雨”和“下冰雹”,前者在词典中已收录,但后者没有。所以,“下雨”标记为单犯罪行为。在“下冰雹”中,只有“下”被标记为犯罪行为。
模式2:复合结构犯罪行为
中文语言中经常使用重复的表达式来生成复合词。如,aa,aab,abb,aabb,a里ab,a不ab,abab如,“走走”,“跑一跑”,“洗洗澡”,“勾勾搭搭”等。
模式3:同义并列犯罪行为
同义动词通常同时使用作为动词表达式。如,“驱车/行驶”,“开发/建设”和“抓捕/归案”。我们将其标注为一个犯罪行为,如,[act-3驱车行驶](下标表示模式3)。除此以外,连续的动词表达相反的语义,但属于偏正关系的,如“进进出出”,也被标为一个犯罪行为。
如果两个连续的动词,代表一系列行动。如,“我去扭开水龙头”,“去扭开”可以被分割为“去/扭开”。在这种情况下,我们将最后一个动词被标记为犯罪行为。例如:“我去[act-3(扭)开]水龙头”,其中下标表示模式3,括号里的表示中心词。
模式4:带修饰或带补语的犯罪行为
当动词带有时态标记、补语或修饰符时,我们将犯罪行为作为中心词标注在括号里。例如,“王某取出一把尖刀”,标记为“王某[act-4(取)出]一把尖刀”。
模式5:其它特殊的犯罪行为表达
例如,名词化的动词,形容词化的动词,谚语,成语或典故等。
许多名词和形容词都可以用作动词,尤其是古典或文学风格的作品。如,“左右[act-5欲(刃)]相如”,“[act-5(红)透]半边天”。在例句“马某某[act-5心生不满]”中,成语“心生不满”如果切分,则会引起很多歧义,所以单独标注谓语犯罪行为。该定义还可用于处理主语-谓语从句,其形式为:名词(代词)+动词(形容词)。例如,“我[act-5开心]”,“我[act-5幸福]”等。
采用以上标注规范,可以标注实例。如:“被告人陈某某因家庭矛盾[act-1迁怒]岳父滕某某。2015年6月29日凌晨,陈某某[act-4谎(称)]购买房屋,将其[act-1骗]至其新房南侧桥上。”
所述步骤二中,识别步骤为:给定一个输入序列句子,通过双向递归神经网络获取句子内部的依赖关系;然后,用注意力机制建模句子的焦点角色;最后通过crf层返回一条最大化的标注路径。
犯罪行为识别建模成一个序列标注问题:给定一个输入序列(句子),返回一条最大化标注路径。本发明通过双向递归神经网络获取句子内部的依赖关系。然后,用注意力机制建模句子的焦点角色。最后通过crf层返回一条最大化的标注路径。具体步骤如下:
模型中的第一层是输入层,该层接受的输入数据shape的参数。模型中的embedding层设置了字典的长度,并会在该层上使用一个全连接层。embedding层通过使用随机初始化的embedding矩阵对预处理好的法院裁判文书案情文本中句子里的字通过one-hot向量映射成为低维稠密的字向量,然后再通过词向量来表示裁判文书中的文本内容。接下来是模型里能够进行自动提取句子特征的双向lstm层,在实际模型中,字序列经过词嵌入技术处理后,作为双向lstm的输入。对于包含n个单词的给定句子,将处理成前向lstm的输出隐藏状态序列
bilstm输出的数据为每一个标签的预测分值,该分值将作为attention层的输入。
本文中的attention机制思路是将上层lstm中的输出向量作为q、k、v(query,key,value)输入attention层中。首先计算一组query的attention函数,并将它们组合成一个矩阵q。key和value映射成矩阵k和v。我们计算输出矩阵表示为:
其中,
经过点积计算的query、key和value,再并行执行attention函数,产生dv维输出值。把这个过程重复做h次,最后把结果拼接在一起输入下一层,产生最终值,即完成multi-headattention。具体来说,可以用以下公式表达,
其中,
从上式中得到
模型中的最后一层是能够对句子级序列进行相应标注的crf层,最后把输入输出赋给模型并进行打印。
针对现有犯罪行为识别算法不足和识别困难的问题,本发明基于深度神经网络技术的最新进展,开展犯罪行为识别的研究。在本发明中,采用bilstm-crf模型与attention机制相结合的方法进行犯罪行为识别。在序列化标注过程中,重点考虑犯罪行为作为句子中心的问题。
基于神经网络的犯罪行为识别方法的实现可以包含两个部分。
第一部分是介绍犯罪行为的概念及规范,并构建犯罪行为数据集。
司法数据中的案情包含大量复杂的事件以及人物关系,多种行为的发生。而本发明的中心即介绍犯罪行为这一概念,犯罪行为指的是在案情文本中,句子中可以单独作谓语的动词。犯罪行为作为句子的核心,是关联全句中各个语言要素的重要语法单元,因此识别犯罪行为是理解句子的关键。通过犯罪行为识别可以解析句子结构,获取句子的语义信息。“犯罪行为”在整句中的重要性是可见的,它可以直接展现事件发展的态势。对于本发明来说,犯罪行为识别可以形成一系列的犯罪行为链,通过数据分析达到监控预测的效果。
根据司法数据案情的特征,制定一系列具有广泛应用性的标注规范。本标注规范将包括犯罪行为的类别定义,不同的行为类别将以不同的数字以区分,使得该标注规范即适用于所需标注数据,又能有效地消除中文语言之间的混乱与歧义。从而得到可供实验的数据集。
第二部分是提出基于attentional-bilstm-crf神经网络结构的犯罪行为识别方法。犯罪行为是句子中心,其识别存在高阶依赖,需要综合句子的整体结构和语义特征进行判断,还需要对输出标注路径的结构进行调整。本发明拟采用神经网络技术抽取句子的抽象语义特征和结构特征,并加入全局约束条件,优化训练过程。在本发明中面向已有的标注语料库,以attentional-bilstm-crf神经网络结构模型为依托,获得了较为优良的实验结果。
本发明提供了基于attentional-bilstm-crf神经网络结构的犯罪行为识别方法。犯罪行为是句子的中心,是关联句子各个语言要素的重要语法单元,把握句子之间的犯罪行为可以帮助理解案情事件的轮廓及全局。通过分析犯罪行为的表达方式和上下文特征,制定标注规范,有助于揭示中文的句法结构特点和语言表达规律,丰富中文自然语言处理的相关理论。
犯罪行为是句子的中心,其识别需要依赖句子的整体结构和语义。现有犯罪行为识别主要采用基于规则和统计机器学习的方法,难以建模犯罪行为识别中的高阶依赖信息。通过本发明,可以拓展中文信息处理的相关技术。
本发明未详述之处,均为本技术领域技术人员的公知技术。最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!