一种基于BPANN与ε-SVR混合模型的PM2.5浓度预测方法与流程
本发明涉及一种pm2.5浓度预测方法,属于细颗粒物污染的预测
技术领域:
。
背景技术:
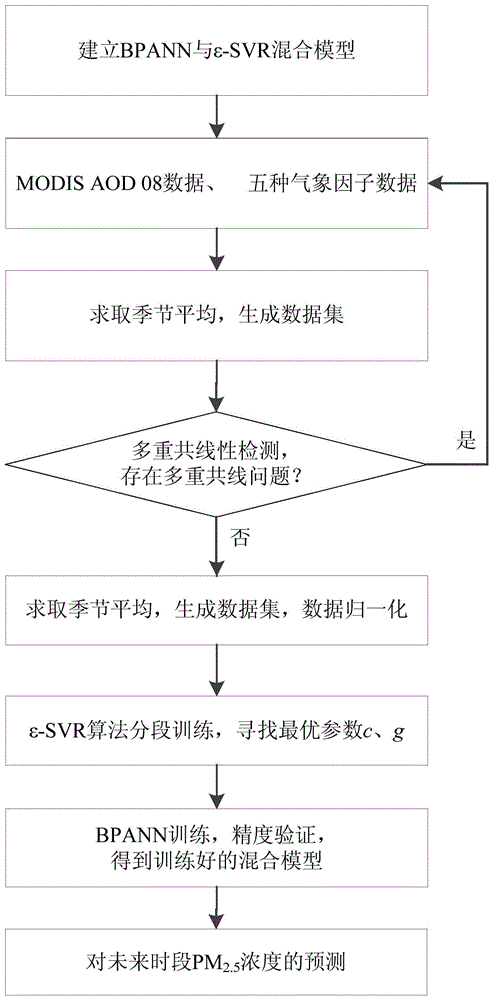
:细颗粒物(pm2.5)引发空气霾污染频发的主要原因,同时也是导致肺癌发病率和死亡率升高的重要因素。pm2.5易附带有毒的重金属离子,且在大气中的停留时间长、输送距离远,极难消散。现代社会pm2.5污染越来越受到广泛的关注,传统的监测手段无法有效和准确的预测出区域内pm2.5浓度,从而不能及时有效的给出警示。bpann是人工神经网络中的一种,其原理按误差反向传播训练的多层前馈型网络,其算法称为bp算法,基本的思想是梯度下降法,利用梯度搜索技术,以期使网络的实际输出值和期望输出值的误差最小。bp人工神经网络(bpann)包含输入层、隐含层和输出层,内部结构如图2所示。输入层有多个节点,每个节点表示一种输入参数;隐含层有多个神经元,算法主要实现在隐含层中;输出层的功能为输出隐含层算法实现的结果。每两个相邻的层级之间单向传播,训练和学习的规则使用梯度下降法,通过阈值的判断反相传播而不断的调整网络的权值,使得整个网络的误差平方和最小。由于bp人工神经网络具有很强的非线性映射能力和柔性的网络结构,且收敛速度快,结构简单,但是学习过程多以经验最小化原则,依赖经验成分较多,容易出现过拟合现象。支持向量回归基于统计学基础,以实现结构风险最优化为原则,把复杂的结构化问题转化为核函数选择问题。svr把原有的二次凸化问题转换成约束更简单的对偶问题且二者等价,使用核函数展开定理,不仅几乎不增加计算的复杂性,而且在某种程度上避免了“维数灾难”。ε-svr是在svr的基础上给定了一个参数范围ε,原始的svr模型中只有当学习得到的f(x)完全等于y值时,模型损失才为零;假使模型的损失容忍度最多有ε范围的偏差,以f(x)为中心构建出一个宽度为2ε的偏差域,训练样本处于此区域内也被算作正确预测,则模型学习能力将会更加优秀。ε-svr大大减轻了对样本集的依赖,且学习泛化能力强,可以避免“维数灾难”,但模型训练时需要把样本集映射到一个高维的空间中,当样本集较大时,计算的复杂度会大大增加,耗费较多的时间和资源。技术实现要素:本发明为解决现有监测手段无法简便而准确的预测出区域内pm2.5浓度的问题,提供了一种基于bpann与ε-svr混合模型的pm2.5浓度预测方法。本发明所述一种基于bpann与ε-svr混合模型的pm2.5浓度预测方法,通过以下技术方案实现:步骤a、分别建立bpann模型与ε-svr模型;然后将ε-svr模型的输出作为bpann模型的输入,得到bpann与ε-svr混合模型;步骤b、对所述bpann与ε-svr混合模型进行训练:b1、获取与pm2.5浓度相关的数据,提取一段时间的modisaod08中每个栅格里的数据;获取五种气象因子数据包括风向、风速、相对湿度、行星边界层高度以及温度;所述modisaod表示利用中分辨率率成像光谱仪modis测得的大气气溶胶光学厚度aod;b2、把步骤b1中获取的modisaod数据与五种气象因子数据进行时空上的匹配,并获取对应时间内站点实测的pm2.5浓度数据,剔除异常值后求取月均值,通过月均值求取季节平均,并按照时间先后顺序生成数据集;b3、对b2所生成的数据集进行归一化处理;b4、把b3归一化处理后的数据作为所述混合模型的输入参数,使用ε-svr算法进行分段训练,寻找二维数组中最优的参数值c、g,将输出的pm2.5浓度与实测pm2.5浓度对比,选择误差范围内的数据值作为结果集s;b5、把结果集s作为所述混合模型bpann部分的输入,抽取结果集s中的80%作为bpann训练集,20%作为bpann测试集,并将得出的预测结果与实测pm2.5浓度进行精度验证;经过多次迭代训练,得到训练好的混合模型;步骤c、对未来时段pm2.5浓度的预测:c1、将当前的modisaod08数据和五种气象因子数据进行与步骤b3中一致的归一化处理;将归一化处理处理后的数据输入步骤b5得到的训练好的混合模型中进行预测;c2、对c1所得到的输出结果进行反归一化处理,得到预测的pm2.5浓度值。本发明最为突出的特点和显著的有益效果是:本发明所涉及的一种基于bpann与ε-svr混合模型的pm2.5浓度预测方法,本发明使用与pm2.5浓度值有较高相关性的modisaod数据与欧洲气象中心获取的五种气象因子数据,将ε-svr算法的输出作为bpann的输入,结合了bpann与ε-svr两种算法模型的优点;本发明方法简便,稳定性好,对pm2.5浓度的预测精度高;仿真实验中预测精确度达到95%以上;适于对区域内pm2.5浓度长时间的预测,具有较好的预测效果,能够为有关部门治理空气污染提供理论依据和技术支持。附图说明图1为本发明方法流程图;图2为bp神经网络结构示意图;图3为ε-svr原理示意图;图4为本发明实施例中bpann与ε-svr混合模型预测的长三角地区(2016年春季)pm2.5浓度的精度验证图;图5为本发明实施例中bpann与ε-svr混合模型预测的长三角地区(2016年夏季)pm2.5浓度的精度验证图;图6为本发明实施例中bpann与ε-svr混合模型预测的长三角地区(2016年秋季)pm2.5浓度的精度验证图;图7为本发明实施例中不同预测方法的预测值对比曲线图;图8为本发明实施例中不同预测方法的预测误差对比曲线图。具体实施方式具体实施方式一:结合图1对本实施方式进行说明,本实施方式给出的一种基于bpann与ε-svr混合模型的pm2.5浓度预测方法,具体包括以下步骤:步骤a、分别建立bpann模型与ε-svr模型;然后将ε-svr模型的输出作为bpann模型的输入,得到bpann与ε-svr混合模型;步骤b、对所述bpann与ε-svr混合模型进行训练:b1、获取与pm2.5浓度相关的数据,提取一段时间的modisaod08中每个栅格里的数据,精度为1°×1°、每月;从欧洲气象中心获取五种气象因子数据包括风向、风速、相对湿度、行星边界层高度以及温度;所述modisaod表示利用中分辨率率成像光谱仪modis(moderateresolutionimagingspectrora-diometer)测得的大气气溶胶光学厚度aod(aerosolopticaldepth);b2、把步骤b1中获取的两种类型的数据(modisaod数据、五种气象因子数据)进行时空上的匹配,并获取对应时间内站点实测的pm2.5浓度数据,剔除异常值后求取月均值,通过月均值按照3、4、5月为春季,6、7、8月为夏季,9、10、11月为秋季,12月、第二年1、2月为冬季的规则求取季节平均,并按照时间先后顺序生成数据集;b3、对b2所生成的数据集进行归一化处理;b4、把b3归一化处理后的数据作为所述混合模型的输入参数,使用ε-svr算法进行分段训练(以一年为一个时间段,将第一年的数据作为模型的输入,得到下一年的预测数据,并把预测数据与下一年的实测数据进行对比;依次类推),寻找二维数组中最优的参数值c、g,将输出的pm2.5浓度与实测pm2.5浓度对比,选择误差范围内的数据值作为结果集s;b5、把结果集s作为所述混合模型bpann部分的输入,抽取结果集s中的80%作为bpann训练集,20%作为bpann测试集,并将得出的预测结果与实测pm2.5浓度进行精度验证;经过多次迭代训练,得到训练好的混合模型;步骤c、对未来时段pm2.5浓度的预测:c1、将当前的modisaod08数据和五种气象因子数据进行与步骤b3中一致的归一化处理;将归一化处理处理后的数据输入步骤b5得到的训练好的混合模型中进行预测,预测模型能够预测输入数据时间跨度后一年时间的pm2.5浓度,使用历史数据训练模型,当前数据去预测未来的pm2.5浓度;通常当前数据包含在历史数据内,当不包含在内的时候也可以预测。c2、对c1所得到的输出结果进行反归一化处理,其方法和步骤与b3中的归一化方式相对应,得到预测的pm2.5浓度值,预测单位为季均值。由于bp人工神经网络具有很强的非线性映射能力和柔性的网络结构,且收敛速度快,结构简单,但是学习过程多以经验最小化原则,依赖经验成分较多,容易出现过拟合现象,为了保证模型的精度与稳定,需要与支持向量回归结合;ε-svr模型大大减轻了对样本集的依赖,且学习泛化能力强,可以避免“维数灾难”,但模型训练时需要把样本集映射到一个高维的空间中,当样本集较大时,计算的复杂度会大大增加,耗费较多的时间和资源。综合两种算法的优缺点,本发明构建了bpann与ε-svr混合模型。具体实施方式二:本实施方式与具体实施方式一不同的是,步骤a中建立bpann模型时设置参数如下:设置bpann的激活函数选用sigmoid函数;设置bpann的学习效率0.01;设置bpann隐含层层数为3,节点数为10。bp人工神经网络(bpann)是一种按误差反向传播训练的多层前馈型网络,其算法称为bp算法,基本的思想是梯度下降法,利用梯度搜索技术,以期使网络的实际输出值和期望输出值的误差最小。bp人工神经网络包含输入层、隐含层和输出层,结构如图2所示。输入层有多个节点,每个节点表示一种输入参数;隐含层有多个神经元,算法主要实现在隐含层中;输出层的功能为输出隐含层算法实现的结果。每两个相邻的层级之间单向传播,训练和学习的规则使用梯度下降法,通过阈值的判断反相传播而不断的调整网络的权值,使得整个网络的误差平方和最小。本实施方式中,bpann模型的激活函数(核心函数)选用sigmoid函数,其形式为:其中,x为函数自变量,e自然常数;其他步骤及参数与具体实施方式一相同。具体实施方式三:本实施方式与具体实施方式一或二不同的是,步骤a中ε-svr模型建立过程具体如下:设已知ε-svr训练集t={(x1,y1),(x2,y2),…,(xi,yi)}∈(x×y),其中,xi∈rn,yi∈rn;xi为ε-svr模型的输入,yi为ε-svr模型的输出;rn为实数集,n为训练集中数据的数目;i=1,2,...,n;采用的核函数为线性核函数k(x,y)=x·y、多项式核函数k(x,y)=[(x·y)+c]d(d=1,2,…,n)、径向基核函数k(x,y)=exp(-|x-y|2/d2)、sigmoid核函数k(x,y)=tanhε(xy)+k中任意一种;式中d、k为待定系数;ε为偏差范围;ε-svr是在svr的基础上给定了一个参数偏差范围ε,如图3所示。传统的svr模型中只有当学习得到的f(x)完全等于y值时,模型损失才为零;假使模型的损失容忍度最多有ε范围的偏差,以f(x)为中心构建出一个宽度为2ε的偏差域,训练样本处于此区域内也被算作正确预测,则模型学习能力将会更加优秀。偏差范围ε的最优化问题可以通过下式求得:其中,ai均为最优化时选择的系数,且c为恰当的正数。其他步骤及参数与具体实施方式一或二相同。具体实施方式四:本实施方式与具体实施方式三不同的是,步骤b5中经过迭代训练次数为1000次。1000次的迭代训练能够保证得到训练好的混合模型能够得到相对准确的预测结果,并且训练耗费的时间也在可接受的范围。其他步骤及参数与具体实施方式三相同。具体实施方式五:本实施方式与具体实施方式四不同的是,步骤b3中使用min-max函数对b2所生成的数据集进行归一化处理,其公式为:其中,max为样本最大值,min为样本最小值,x为步骤b2所生成的数据集,x*为映射后的样本集。其他步骤及参数与具体实施方式四相同。具体实施方式六:本实施方式与具体实施方式五不同的是,步骤b还包括对步骤b2所生成的数据集进行多重共线性检测,数据之间常会出现多重共线性的问题,检验是为了避免因数据之间存在高度相关关系而导致模型失真,当检测的结果为存在多重共线性问题,则需要返回步骤b1重新提取数据。其他步骤及参数与具体实施方式五相同。具体实施方式七:本实施方式与具体实施方式六不同的是,通过容忍度tv(tolerancevalue)和方差膨胀因子vif(varianceinflationfactor)步判定骤b2所生成的数据集变量之间是否存在多重共线性问题;当vif<10且0.1<tv<1时,表明变量之间没有共线性关系。其他步骤及参数与具体实施方式六相同。实施例采用以下实施例验证本发明的有益效果:预测区域为长三角地区,该地区是中国的第一大经济区,更是通往亚太地区的国际门户,pm2.5污染时常发生,研究此地区的pm2.5浓度,具有代表意义。获取modisaod08、欧洲气象中心五种气象因子数据、pm2.5历史实测数据,时间范围为2013-04~2016-12,因研究区的空间地理位置占据了多个栅格,需进行时空匹配,得出331组季均数据,按时间先后顺序排列,如表1所示。表1长三角地区2013-04~2016-12实测站点pm2.5浓度季均值由于长三角地区在空间位置上占据多个栅格,导致时间序列上出现多个相同年份季节的不同的pm2.5浓度数据。把pm2.5浓度季均值作为bpann与ε-svr混合模型的输出,modisaod及五种气象因子数据作为混合模型的输入,随机抽取80%的数据作为训练集,20%的数据作为测试集;使用min-max函数对输入数据进行归一化处理,结果保留两位小数,结果如表2所示。表2331组数据中随机抽取80%,264组数据均归一化于[-1,1]之间。使用单一的bpann模型以上述六种数据作为输入预测pm2.5的浓度,得到单一bpann模型对长三角地区pm2.5浓度的预测值和其与站点实测值的误差绝对值(结果保留两位小数),如表3所示。由表3可以看出,单一的bpann模型对pm2.5的浓度值有一定的预测能力,预测均在可接受范围内,时间列为122的预测误差只有0.01。表3时间列bpann预测值(μg/m3)站点实测值(μg/m3)误差(绝对值)151.9854.212.23253.8250.523.3362.9459.913.03451.1851.730.55556.8767.2810.41653.3150.992.32731.3247.6316.31…………12057.3666.298.9312157.970.6212.7212243.4843.490.01…………33061.4864.683.233173.2678.064.8使用单一的ε-svr模型以上述六种数据作为输入预测pm2.5的浓度,得到单一的ε-svr模型对长三角地区pm2.5浓度的预测值和其与站点实测值的误差绝对值(结果保留两位小数),如表4所示。表4时间列ε-svr预测值(μg/m3)站点实测值(μg/m3)误差(绝对值)150.954.213.31246.8150.523.71360.259.910.29456.0451.734.31564.9967.282.29658.6950.997.7740.5647.637.07…………12061.0166.295.2812176.3270.625.712247.7843.494.29…………33066.0564.681.3733176.6778.061.39比较表3、表4发现,单一的ε-svr模型对pm2.5浓度的预测的效果相比于单一bpann模型更好,稳定性更强,具有较强的预测功能。综合两种算法的优缺点,构建bpann与ε-svr混合模型;把modisaod与五种气象因子数据作为模型的输入、pm2.5实测数据作为输出参数,随机抽取数据的80%作为训练集,20%为测试集。运用ε-svr模型分别对长三角地区按时间序列分段训练(如,使用2013-04~2014-04的输入数据训练输出2014-04~2015-04的pm2.5浓度值;然后依次类推),寻找最佳c、g参数,得到每个地区的结果集s,再把结果集s作为bpann模型的输入参数,预测出长三角地区的pm2.5浓度值。使用bpann与ε-svr混合模型,以上述六种数据作为输入预测pm2.5的浓度,得到混合模型对长三角地区pm2.5浓度的预测值和其与站点实测值的误差绝对值(结果保留两位小数),如表5所示。如图4、图5、图6为bpann与ε-svr混合模型预测的长三角地区(2016年)pm2.5浓度的精度验证图,可以看出,本发明方法预测16年春、夏、秋季pm2.5浓度的平均误差均低于3.91,即,本发明方法预测精确度达到95%以上。由图7的三种预测方法(bpann模型、ε-svr模型、bpann与ε-svr混合模型)的预测值对比图可知,bpann与ε-svr混合模型的结果相比两种单一的模型预测结果更准确、稳定性更高等优点。表5时间列混合模型预测值(μg/m3)站点实测值(μg/m3)误差(绝对值)153.2754.210.94251.850.521.28361.159.911.19451.7651.730.03563.6867.283.6651.5550.990.56746.5347.631.1…………12062.8666.293.4312165.7970.624.8312243.6743.490.18…………33063.9564.680.7333176.3278.061.74本实施例对三种预测方法(bpann模型、ε-svr模型、bpann与ε-svr混合模型)在长三角地区的预测值与pm2.5实测值采用了拟合度(r2)、均方根误差(rmse)和平均绝对百分比误差(mape)三个指标来衡量,具体结果如表6所示。表6模型r2rmsemapebpann与ε-svr0.816.047.49%bpann0.669.8815.06%ε-svr0.727.9310.01%从表6、以及图8可以看出,bpann与ε-svr混合预测模型(本发明方法)的r2为三种方法中最高,rmse和mape在三种方法中最低,由此可以得出bpann与ε-svr混合模型预测结果的精度要高于单一bpann模型或单一ε-svr模型,拥有更小的误差,具有误差小、预测精确、稳定性高等特点。本实施例选用长三角地区的pm2.5站点实测数据以及modisaod08栅格数据,欧洲气象中心获得的五种气象因子数据的季节均值作为模型的输入,得到了较好的效果,但本发明应用的地区和时间单位并不局限与此,其他的地区以及输入数据的时间单位都可以使用bpann与ε-svr混合模型进行pm2.5浓度的预测。本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,本领域技术人员当可根据本发明做出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1