数据重分布方式的确定方法、装置、服务器及存储介质与流程
本发明实施例涉及数据库技术领域,尤其涉及一种数据重分布方式的确定方法、装置、服务器及存储介质。
背景技术:
mpp(massivelyparallelprocessing)即大规模并行处理,在非共享数据库集群中,每个节点都有独立磁盘存储系统和内存系统,节点间数据通过网络相互连接,彼此协调计算。简单来说,mpp是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的执行结果。
在mpp环境下,数据库表以合适的分布列进行数据分布,存储在各节点上。常见的分布方式有哈希分布(hash)、随机分布(rand)和复制分布(full)等。在进行多表连接操作时,总是两两连接的,即两表进行连接的结果再与另一表或另一两表连接结果进行连接,类似于树状层次分布。当连接操作涉及非分布列时,需要对数据进行重分布。
传统方式在对某节点的数据进行重分布时,虽然考虑了下层节点数据分布的影响,但系统执行效率仍然较低。
技术实现要素:
本发明实施例提供一种数据重分布方式的确定方法、装置、服务器及存储介质,以提高系统的执行效率。
第一方面,本发明实施例提供一种数据重分布方式的确定方法,包括:
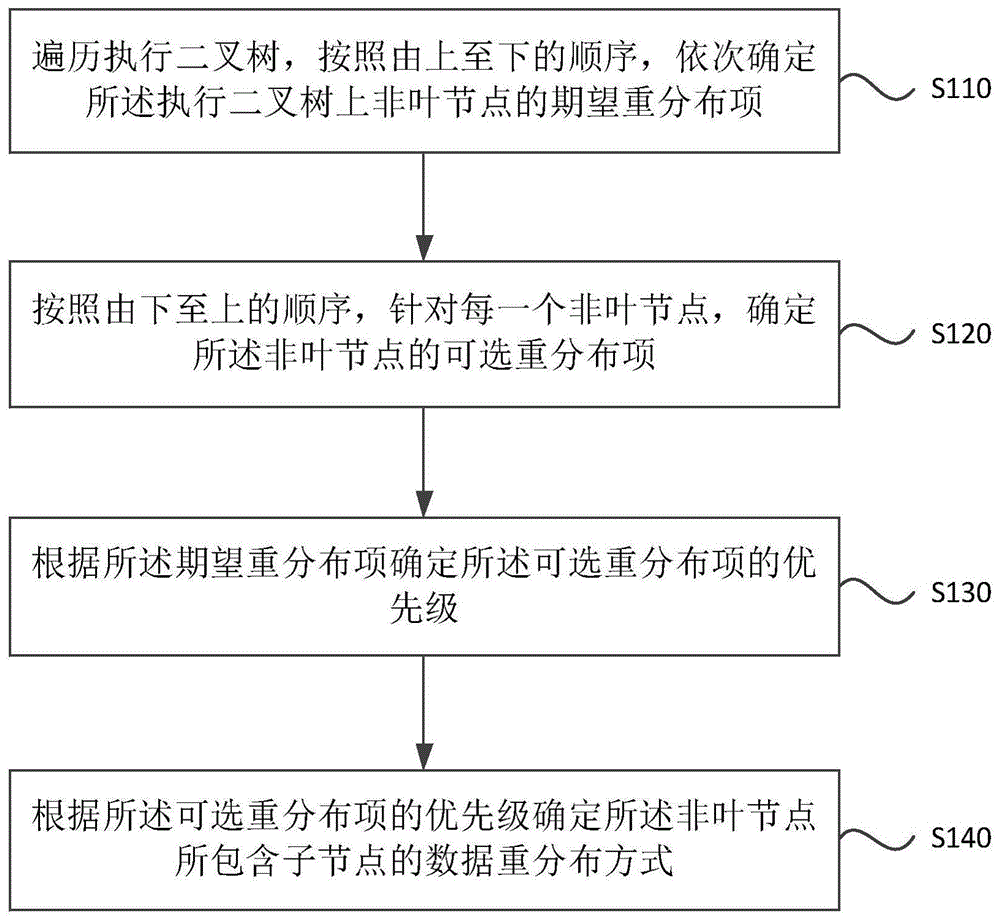
遍历执行二叉树,按照由上至下的顺序,依次确定所述执行二叉树上非叶节点的期望重分布项,所述执行二叉树通过对用户所输入结构化查询语句的解析生成;
按照由下至上的顺序,针对每一个非叶节点,确定所述非叶节点的可选重分布项;
根据所述期望重分布项确定所述可选重分布项的优先级;
根据所述可选重分布项的优先级确定所述非叶节点所包含子节点的数据重分布方式。
第二方面,本发明实施例还提供一种数据重分布方式的确定装置,该装置包括:
期望重分布项确定模块,用于遍历执行二叉树,按照由上至下的顺序,依次确定所述执行二叉树上非叶节点的期望重分布项,所述执行二叉树通过对用户所输入结构化查询语句的解析生成;
可选重分布项确定模块,用于按照由下至上的顺序,针对每一个非叶节点,确定所述非叶节点的可选重分布项;
优先级确定模块,用于根据所述期望重分布项确定所述可选重分布项的优先级;
数据重分布方式确定模块,用于根据所述可选重分布项的优先级确定所述非叶节点所包含子节点的数据重分布方式。
第三方面,本发明实施例还提供一种服务器,包括:
一个或多个处理器;
存储器,用于存储一个或多个程序;
当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现如第一方面所述的数据重分布方式的确定方法。
第四方面,本发明实施例还提供一种存储介质,其上存储有计算机程序,该程序被处理器执行时实现如第一方面所述的数据重分布方式的确定方法。
本发明实施例提供一种数据重分布方式的确定方法、装置、服务器及存储介质,通过遍历执行二叉树,按照由上至下的顺序,依次确定所述执行二叉树上非叶节点的期望重分布项,所述执行二叉树通过对用户所输入结构化查询语句的解析生成,按照由下至上的顺序,针对每一个非叶节点,确定所述非叶节点的可选重分布项,根据所述期望重分布项确定所述可选重分布项的优先级,根据所述可选重分布项的优先级确定所述非叶节点所包含子节点的数据重分布方式。与现有技术相比,本发明实施例为非叶节点的可选重分布项设置了优先级,同时考虑了上层节点和下层节点对当前非叶节点的可选重分布项的影响,提高了系统执行效率。
附图说明
图1为本发明实施例一提供的一种数据重分布方式的确定方法的流程图;
图2为本发明实施例一提供的一种执行二叉树的示意图;
图3为本发明实施例二提供的一种数据重分布方式的确定方法的流程图;
图4为本发明实施例三提供的一种数据重分布方式的确定装置的结构图;
图5为本发明实施例四提供的一种服务器的结构图。
具体实施方式
下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部结构。此外,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
实施例一
图1为本发明实施例一提供的一种数据重分布方式的确定方法的流程图,本实施例可适用于在大规模并行处理环境中,确定节点的数据重分布方式,以使该节点基于确定的数据重分布方式执行数据重分布的情况,该方法可以由数据重分布方式的确定装置来执行,该装置可以由软件和/或硬件的方式来实现,该装置集成在服务器中,具体的,该方法包括如下步骤:
s110、遍历执行二叉树,按照由上至下的顺序,依次确定所述执行二叉树上非叶节点的期望重分布项。
所述执行二叉树通过对用户所输入结构化查询语句的解析生成。结构化查询语句(structuredquerylanguage,简称sql语句)是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统等。二叉树是每个节点最多有两个子树的树结构。解析sql语句可以得到对应的执行二叉树。示例性的,用户输入的sql语句为:selectaa.cc1,b.d2froma,b,aa,bbwherea.c1=b.d1anda.c2=b.d2andaa.cc1=bb.dd1andaa.cc2=bb.dd2andb.d2=1groupbyaa.cc1,b,d2,解析该sql语句,得到的执行二叉树如图2所示,图2为本发明实施例一提供的一种执行二叉树的示意图。
其中,hagr为执行二叉树的根节点,hi1、hi2和hi3为执行二叉树的中间节点,表示哈希内连接,以hi3为例,hi3表示数据表aa和数据表bb执行哈希内连接,数据表a、数据表b、数据表aa以及数据表bb为执行二叉树的叶节点,select为执行二叉树的过滤节点,实施例将根节点和中间节统称为非叶节点。重分布项是当某节点选择分发重分布方式时,该节点对应的一元或二元元组,元组中包含了该节点所包含子节点的分布属性,所述分布属性包括哈希分布、复制分布和随机分布等,一元元组表示该节点包含一个子节点,二元元组表示该节点包含两个子节点。期望重分布项是根据节点的特征确定的重分布项,需要说明的是,只有非叶节点具有期望重分布项,即图2中只有根节点和中间节点具有期望重分布项,叶节点和过滤节点不具有期望重分布项。
如图2所示,遍历执行二叉树,按照先根遍历的顺序,由上至下,由左至右分别确定hagr节点、hi1节点、hi2节点以及hi3节点的期望重分布项。在确定某非叶节点的期望重分布项时,可以根据该非叶节点的特征确定,该特征包括连接或分组等,比如,确定hagr节点的期望重分布项时,根据前面所述的sql语句可知,hagr节点按照分组项aa.cc1和b.d2进行group分组,根据分组项可以确定hagr节点的期望重分布项为:cc1/d2/(cc1,d2)。再如,确定hi1节点的期望重分布项,根据sql语句可知,hi1节点对应的连接条件为:a.c1=bb.dd1andaa.cc2=b.d2,该连接条件对应的连接项为a.c1、bb.dd1、aa.cc2和b.d2,根据该连接项可以确定hi1节点的期望重分布项为:c1,dd1/cc2,d2/(c1,d2),(dd1,cc2)。由此即可确定执行二叉树上各个非叶节点的期望重分布项。
s120、按照由下至上的顺序,针对每一个非叶节点,确定所述非叶节点的可选重分布项。
可选重分布项是该非叶节点对应的至少一个重分布项,实施例将该叶节点对应的所有重分布项称为可选重分布项,比如hi2节点对应的重分布项为d1:c1,d1,d2:c2,d2,d3:(c1,c2),(d1,d2),则d1、d2和d3称为hi2节点的可选重分布项。确定可选重分布项是为了后续对可选重分布项进行优化,确定可选重分布项的优先级。需要说明的是,执行二叉树中的叶节点和过滤节点对应的重分布项无需优化,即不需要确定可选重分布项,如图2所示,只需要由下至上依次确定hi2节点、hi3节点、hi1节点以及hagr节点的可选重分布项。可选重分布项的具体过程与期望重分布项的确定过程类似,此处不再赘述。
s130、根据所述期望重分布项确定所述可选重分布项的优先级。
同一个非叶节点对应的期望重分布项和可选重分布项不一定相同,当前非叶节点对应的可选重分布项与其祖先节点的期望重分布项可能相同,也可能不同,根据当前非叶节点对应的期望重分布项以及其祖先节点对应的期望重分布项可以确定当前非叶节点对应的可选重分布项的优先级。示例性的,参考图2,实施例将hi1节点和hagr节点称为hi2节点的祖先节点。具体的,若某可选重分布项不在本节点的期望重分布项中,则该可选重分布项对应的优先级降低,若在本节点的期望重分布项,但不在其祖先节点的期望重分布项中,则该可选重分布项的优先级不变,若既在本节点的期望重分布项中,也在某个祖先节点的期望重分布项中,则该可选重分布项的优先级升高。实施例设定可选重分布项的初始优先级为0。由此即可确定每一个非叶节点各个可选重分布项的优先级。
其中,可选重分布项在期望重分布项中是指当可选重分布项或期望重分布项为二元元组,即可选重分布项或期望重分布项包含左重分布项和右重分布项,若可选重分布项的左重分布项或右重分布项与期望重分布项的左重分布项或右重分布项相同,则认为可选重分布项在期望重分布项中。例如,期望重分布项为c1,dd1,可选重分布项为c1,d1,可选重分布项的左重分布项c1与期望重分布项的左重分布项c1相同,则称该可选重分布项在该期望重分布项中。
s140、根据所述可选重分布项的优先级确定所述非叶节点所包含子节点的数据重分布方式。
数据重分布方式是某节点进行重分布的依据,根据该数据重分布方式可以执行相应的数据重分布。数据重分布方式可以是分发重分布或收集重分布等。本实施例对分发重分布和收集重分布不进行具体介绍。优先级可以为数据重分布方式的确定提供依据。
具体的,在确定非叶节点所包含子节点的数据重分布方式时,通常利用代价计算算法计算该非叶节点在分发重分布方式或收集重分布方式下的代价值,将代价值最小时子节点对应的数据重分布方式作为该子节点的数据重分布方式。本实施例在该非叶节点选择分发重分方式时,为该非叶节点的可选重分布项设置了优先级,使得在利用代价计算方法计算分发重分布方式下不同可选重分布项对应的代价值时,考虑了祖先节点的重分布项对本节点重分布项的影响,从而使得代价计算的结果能更准确的体现可选重分布项在执行二叉树中的代价而非孤立的节点中的代价,既利用了下层节点的分布属性,又为上层节点所需的分布属性提供了依据,可以进一步减少数据重分布的次数和数据量,提高系统的执行效率。
其中,分布属性反映了节点的一种数据分布情况,可以是哈希分布、随机分布和复制分布等。例如对数据表a和数据表b进行哈希内连接,连接条件为hi(a.c1=b.d1anda.c2=b.d2),此时,可以确定数据表a的分布属性为哈希分布c1/c2/(c1,c2)、随机分布和复制分布五种情况之一,数据表b的分布属性为哈希分布d1/d2/(d1,d2)、随机分布和复制分布五种情况之一。实施例对分布属性的内容不具体描述。
本发明实施例一提供一种数据重分布方式的确定方法,通过遍历执行二叉树,按照由上至下的顺序,依次确定所述执行二叉树上非叶节点的期望重分布项,所述执行二叉树通过对用户所输入结构化查询语句的解析生成,按照由下至上的顺序,针对每一个非叶节点,确定所述非叶节点的可选重分布项,根据所述期望重分布项确定所述可选重分布项的优先级,根据所述可选重分布项的优先级确定所述非叶节点所包含子节点的数据重分布方式。与现有技术相比,本发明实施例为非叶节点的可选重分布项设置了优先级,同时考虑了上层节点和下层节点对当前非叶节点的可选重分布项的影响,提高了系统执行效率。
实施例二
图3为本发明实施例二提供的一种数据重分布方式的确定方法的流程图,在上述实施例的基础上具体化,具体的,该方法包括如下步骤:
s210、解析所述结构化查询语句,确定所述非叶节点对应的特征项。
不同的操作对应的特征项不同,比如连接操作对应的特征项为连接项,分组操作对应的特征项为分组项,解析用户输入的sql语句,可以确定某节点对应的具体操作,进而确定特征项,为期望重分布项和可选重分布项的确定提供基础。示例性的,参考图2,解析用户输入的sql语句,可以确定hagr节点对应分组操作,分组项为aa.cc1和b.d2,hi1节点、hi2节点和hi3节点对应连接操作,其中,hi1节点对应的连接条件为:a.c1=bb.dd1andaa.cc2=b.d2,相应的连接项为:a.c1、bb.dd1、aa.cc2和b.d2,hi2节点对应的连接条件为:a.c1=b.d1anda.c2=b.d2,相应的连接项为:a.c1、b.d1、a.c2和b.d2,hi3节点对应的连接条件为:aa.cc1=bb.dd1andaa.cc2=bb.dd2,相应的连接项为:aa.cc1、bb.dd1、aa.cc2和bb.dd2。
s220、根据所述特征项确定所述非叶节点的初始期望重分布项。
重分布项是节点特征项的组合,例如哈希连接的连接项的组合、分组操作的分组项的组合等。初始期望重分布项是直接根据特征项的组合确定的重分布项。仍以图2为例,hagr节点的初始期望重分布项为:cc1/d2/(cc1,d2),hi1节点的初始期望重分布项为:c1,dd1/cc2,d2/(c1,d2),(dd1,cc2),hi2节点的初始期望重分布项为:c1,d1/c2,d2/(c1,c2),(d1,d2),hi3节点的初始期望重分布项为:cc1,dd1/cc2,dd2/(cc1,cc2),(dd1,dd2)。
s230、遍历过程中,当前节点是否为过滤节点,且所述过滤节点对应的过滤条件满足设定形式,若是,执行s240,否则,执行s250。
若重分布项为常量,当将全部常量均分布至mpp中的一个站点时,容易导致数据分布不均匀,为此,需要避免常量作为重分布项的情况。具体的,如果当前节点为过滤节点,且过滤节点对应的过滤条件满足设定形式,则执行s240,否则,两个条件只要有一个不满足,则执行s250。其中,设定形式为:exp=常量,exp为表达式,实施例对表达式的具体形式不进行限定,例如可以是b.d2或b.d2+1等形式。
s240、将所述过滤条件中的表达式从所述过滤节点的祖先节点的初始期望重分布项中移除,获得期望重分布项。
参考图2,select节点为过滤节点,对应的过滤条件为:b.d2=1,满足exp=常量这一设定形式,为此,需要从当前层开始向上查找祖先节点的初始期望重分布项,若d2在祖先节点的初始期望重分布项中,则将d2从祖先节点的初始期望重分布项中移除,其中,select节点的祖先节点为hi2节点、hi1节点和hagr节点。例如,hi2节点的初始期望重分布项为:c1,d1/c2,d2/(c1,c2),(d1,d2),d2在初始重分布项c2,d2中,则将初始重分布项c2,d2移除,即hi2节点的期望重分布项为:c1,d1/(c1,c2),(d1,d2),继续向上查找hi1节点和hagr节点,过程类似。最终确定的hagr节点的期望重分布项为:cc1/(cc1,d2),hi1节点的期望重分布项为:c1,dd1/(c1,d2),(dd1,cc2),hi2节点的期望重分布项为:c1,d1/(c1,c2),(d1,d2)。
s250、将所述初始期望重分布项作为期望重分布项。
若遍历过程中没有遇到过滤节点,或者过滤节点对应的过滤条件不满足设定形式,则将初始期望重分布项作为期望重分布项。继续参考图2,select节点的操作处理结束后,由于数据表b为叶节点,不需要设置期望重分布项,则向上返回,最终转入hi3节点,hi3节点的初始期望重分布项为:cc1,dd1/cc2,dd2/(cc1,cc2),(dd1,dd2),继续遍历,没有遇到过滤节点,则hi3节点的期望重分布项即为初始期望重分布项为:cc1,dd1/cc2,dd2/(cc1,cc2),(dd1,dd2)。由此,各个非叶节点的期望重分布项全部设置完毕。
s260、按照由下至上的顺序,针对每一个非叶节点,确定所述非叶节点的可选重分布项。
可选重分布项的确定过程与初始期望重分布项的确定过程类似,具体的,所述确定所述非叶节点的可选重分布项,包括:
解析所述结构化查询语句,确定所述非叶节点对应的特征项;
根据所述特征项确定所述非叶节点的可选重分布项。
参考图2,hi2节点的可选重分布项为:d1:c1,d1/d2:c2,d2/d3:(c1,c2),(d1,d2),hi3节点的可选重分布项为:d1:cc1,dd1/d2:cc2,dd2/d3:(cc1,cc2),(dd1,dd2),hi1节点的可选重分布项为:d1:c1,dd1/d2:cc2,d2/d3:(c1,d2),(dd1,cc2),hagr节点的可选重分布项为:d1:cc1/d2:d2/d3:(cc1,d2)。具体细节可以参考初始期望重分布项,此处不再赘述。
s270、根据所述期望重分布项确定所述可选重分布项的优先级。
具体的,所述根据所述期望重分布项确定所述可选重分布项的优先级,包括:
按照由下至上的顺序,针对每一个非叶节点,获取所述非叶节点的至少一个可选重分布项;
将各所述可选重分布项分别与所述非叶节点的期望重分布项以及所述非叶节点的上层节点的期望重分布项匹配;
根据匹配结果确定各所述可选重分布项的优先级。
具体的,针对每一个可选重分布项,如果该可选重分布项不在本节点的期望重分布项中,则优先级降低,如果既在本节点的期望重分布项中,也在祖先节点的期望重分布项中,则优先级升高。实施例设定如果可选重分布项不在本节点的期望重分布项中,优先级-1,如果既在本节点的期望重分布项中,也在某祖先节点的期望重分布项中,优先级+1。示例性的,以hi2节点为例,hi2节点的可选重分布项为:d1:c1,d1/d2:c2,d2/d3:(c1,c2),(d1,d2),期望重分布项为:c1,d1/(c1,c2),(d1,d2),d1:c1,d1和d3:(c1,c2),(d1,d2)在期望重分布项中,优先级不变,d2:c2,d2不在期望重分布项中,优先级-1,初始优先级均为0,则此时hi2节点各可选重分布项的优先级分别为:d1=0,d2=-1,d3=0。向上查找有期望重分布项的祖先节点。hi1节点的期望重分布项为:c1,dd1/(c1,d2),(dd1,cc2),d1:c1,d1在期望重分布项中,则d1的优先级+1,d2和d3均不在hi1节点的期望重分布项中,此时优先级d1=1,d2=-1,d3=0。继续向上查找,hagr节点的期望重分布项为:cc1/(cc1,d2),d1、d2和d3均不在hagr节点的期望重分布项中,优先级维持不变。到达顶层之后,hi2节点的可选重分布项的优先级确定完毕。最终hi2节点各可选重分布项的优先级分别为:d1=1,d2=-1,d3=0。
hi3节点、hi1节点和hagr节点的可选重分布项的优先级的确定过程与hi1节点类似,此处不再赘述。最终,hi3节点各可选重分布项的优先级分别为:d1=2,d2=0,d3=0。hi1节点各可选重分布项的优先级分别为:d1=0,d2=-1,d3=0。hagr节点各可选重分布项的优先级分别为:d1=0,d2=-1,d3=0。为防止遗漏有期望重分布项的节点,实际应用中可以为每一个有期望重分布项的节点设置层数标记,以level表示,比如图2中的hi2节点和hi3节点位于第三层,level=3,hi1节点位于第二层,level=2,hagr节点位于第一层,level=1,当确定hi2节点各可选重分布项的优先级时,hi2节点对应的level=3,此时需要向上查找level=2和level=1中相应祖先节点的期望重分布项。
s280、根据所述可选重分布项的优先级确定所述非叶节点所包含子节点的数据重分布方式。
具体的,所述根据所述可选重分布项的优先级确定所述非叶节点所包含子节点的数据重分布方式,包括:
根据所述可选重分布项的优先级确定对应所述可选重分布项的权重;
根据所述权重确定所述非叶节点在所述权重对应的可选重分布项下的代价值;
根据所述代价值确定所述非叶节点所包含子节点的数据重分布方式。
具体的,可选重分布项的优先级设置完毕后,可以根据优先级为每一个可选重分布项设置相应的权重,比如,优先级越高,对应的权重越大,实施例对权重的具体设置方式不进行限定。同一个节点的各可选重分布项对应的权重之和为1。当计算各可选重分布项对应的代价值时,即可考虑各可选重分布项对应的权重,以此优化代价值的计算结果,进而减少数据重分布的次数。例如,代价计算算法选择了hi2节点的d1:c1,d1,hi3节点的d1:cc1,dd1,当hi1节点选择c1,dd1为重分布项时,由于hi2节点的d1和hi3节点的d1均在hi1节点选择的重分布c1,dd1中,则hi2节点和hi3节点可以省略数据重分布的过程了。需要说明的是,虽然为各可选重分布项设置了优先级,但并不保证最终一定会选择优先级高的可选重分布项。
本发明实施例二提供一种数据重分布方式的确定方法,在上述实施例的基础上,按照先根遍历的顺序,由上至下依次确定非叶节点的期望重分布项,然后按照由下至上的顺序确定各非叶节点的可选重分布项,并根据本节点的期望重分布项和祖先节点的期望重分布项为本节点的可选重分布项设置优先级,进而根据优先级设置对应的权重,优化了代价值的计算结果,减少了数据重分布的次数和数据量,提高了系统执行效率。
实施例三
图4为本发明实施例三提供的一种数据重分布方式的确定装置的结构图,该装置可以执行上述实施例所述的数据重分布方式的确定方法,具体的,该装置包括:
期望重分布项确定模块,用于遍历执行二叉树,按照由上至下的顺序,依次确定所述执行二叉树上非叶节点的期望重分布项,所述执行二叉树通过对用户所输入结构化查询语句的解析生成;
可选重分布项确定模块,用于按照由下至上的顺序,针对每一个非叶节点,确定所述非叶节点的可选重分布项;
优先级确定模块,用于根据所述期望重分布项确定所述可选重分布项的优先级;
数据重分布方式确定模块,用于根据所述可选重分布项的优先级确定所述非叶节点所包含子节点的数据重分布方式。
本发明实施例三提供一种数据重分布方式的确定装置,通过遍历执行二叉树,按照由上至下的顺序,依次确定所述执行二叉树上非叶节点的期望重分布项,所述执行二叉树通过对用户所输入结构化查询语句的解析生成,按照由下至上的顺序,针对每一个非叶节点,确定所述非叶节点的可选重分布项,根据所述期望重分布项确定所述可选重分布项的优先级,根据所述可选重分布项的优先级确定所述非叶节点所包含子节点的数据重分布方式。与现有技术相比,本发明实施例为非叶节点的可选重分布项设置了优先级,同时考虑了上层节点和下层节点对当前非叶节点的可选重分布项的影响,提高了系统执行效率。
在上述实施例的基础上,期望重分布项确定模块310,包括:
第一解析单元,用于解析所述结构化查询语句,确定所述非叶节点对应的特征项;
第一确定单元,用于根据所述特征项确定所述非叶节点的初始期望重分布项;
第二确定单元,用于遍历过程中,若当前节点为过滤节点,且所述过滤节点对应的过滤条件满足设定形式,则将所述过滤条件中的表达式从所述过滤节点的祖先节点的初始期望重分布项中移除,获得期望重分布项;
第三确定单元,用于否则,将所述初始期望重分布项作为期望重分布项。
在上述实施例的基础上,可选重分布项确定模块320,包括:
第二解析单元,用于解析所述结构化查询语句,确定所述非叶节点对应的特征项;
可选重分布项确定单元,用于根据所述特征项确定所述非叶节点的可选重分布项。
在上述实施例的基础上,优先级确定模块330,包括:
可选重分布项获取单元,用于按照由下至上的顺序,针对每一个非叶节点,获取所述非叶节点的至少一个可选重分布项;
匹配单元,用于将各所述可选重分布项分别与所述非叶节点的期望重分布项以及所述非叶节点的祖先节点的期望重分布项匹配;
优先级确定单元,用于根据匹配结果确定各所述可选重分布项的优先级。
在上述实施例的基础上,数据重分布方式确定模块340,包括:
权重确定单元,用于根据所述可选重分布项的优先级确定对应所述可选重分布项的权重;
代价值确定单元,用于根据所述权重确定所述非叶节点在所述权重对应的可选重分布项下的代价值;
数据重分布方式确定单元,用于根据所述代价值确定所述非叶节点所包含子节点的数据重分布方式。
本发明实施例三提供的数据重分布方式的确定装置可以执行上述任意实施例提供的数据重分布方式的确定方法,具备相应的功能和有益效果。
实施例四
图5为本发明实施例四提供的一种服务器的结构图,具体的,参考图5,该服务器包括:处理器410、存储器420、输入装置430和输出装置440,服务器中处理器410的数量可以是一个或多个,图5中以一个处理器410为例,服务器中的处理器410、存储器420、输入装置430和输出装置440可以通过总线或其他方式连接,图5中以通过总线连接为例。
存储器420作为一种计算机可读存储介质,可用于存储软件程序、计算机可执行程序以及模块,如本发明实施例中的数据重分布方式的确定方法对应的程序指令/模块。处理器410通过运行存储在存储器420中的软件程序、指令以及模块,从而执行服务器的各种功能应用以及数据处理,即实现上述实施例的数据重分布方式的确定方法。
存储器420主要包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需的应用程序;存储数据区可存储根据终端的使用所创建的数据等。此外,存储器420可以包括高速随机存取存储器,还可以包括非易失性存储器,例如至少一个磁盘存储器件、闪存器件、或其他非易失性固态存储器件。在一些实例中,存储器420可进一步包括相对于处理器410远程设置的存储器,这些远程存储器可以通过网络连接至服务器。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
输入装置430可用于接收输入的数字或字符信息,以及产生与服务器的用户设置以及功能控制有关的键信号输入。输出装置440可包括显示屏等显示设备、扬声器以及蜂鸣器等音频设备。
本发明实施例四提供的服务器与上述实施例提供的数据重分布方式的确定方法属于同一发明构思,未在本实施例中详尽描述的技术细节可参见上述实施例,并且本实施例具备执行数据重分布方式的确定方法相同的有益效果。
实施例五
本发明实施例五还提供一种存储介质,其上存储有计算机程序,该程序被处理器执行时实现如本发明上述实施例所述的数据重分布方式的确定方法。
当然,本发明实施例所提供的一种包含计算机可执行指令的存储介质,其计算机可执行指令不限于如上所述的数据重分布方式的确定方法中的操作,还可以执行本发明任意实施例所提供的数据重分布方式的确定方法中的相关操作,且具备相应的功能和有益效果。
通过以上关于实施方式的描述,所属领域的技术人员可以清楚地了解到,本发明可借助软件及必需的通用硬件来实现,当然也可以通过硬件实现,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在计算机可读存储介质中,如计算机的软盘、只读存储器(read-onlymemory,rom)、随机存取存储器(randomaccessmemory,ram)、闪存(flash)、硬盘或光盘等,包括若干指令用以使得一台计算机设备(可以是机器人,个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述的数据重分布方式的确定方法。
注意,上述仅为本发明的较佳实施例及所运用技术原理。本领域技术人员会理解,本发明不限于这里所述的特定实施例,对本领域技术人员来说能够进行各种明显的变化、重新调整和替代而不会脱离本发明的保护范围。因此,虽然通过以上实施例对本发明进行了较为详细的说明,但是本发明不仅仅限于以上实施例,在不脱离本发明构思的情况下,还可以包括更多其他等效实施例,而本发明的范围由所附的权利要求范围决定。
- 还没有人留言评论。精彩留言会获得点赞!