基于图补全和自适应视角权重分配的不完备多视角聚类方法、装置、系统及存储介质与流程
本发明涉及机器学习技术领域,尤其涉及基于图补全和自适应视角权重分配的不完备多视角聚类方法、装置、系统及存储介质。
背景技术:
在机器学习领域,多视角聚类能够利用目标的多个视角特征将海量无标签数据自动地划分成若干类别,该技术已经广泛应用于图像聚类、医学诊断等场景。多种单视角聚类方法被扩展到多视角情形,例如多视角期望最大化算法(multi-viewexpectationmaximumclustering,mvem)、多视角k-means方法(multi-viewk-meansclustering,mvkm)、基于谱聚类的多视角聚类方法(multi-viewspectralclustering,mvsc)、基于非负矩阵分解的多视角聚类方法(multi-viewnonnegativematrixfactorization,multinmf)、基于典型相关分析的多视角数据低维映射(multi-viewcanonicalcorrelationanalysis,mcca)等。其中,基于谱聚类和基于非负矩阵分解的多视角聚类方法的核心都是从不同视角中学习一致的子空间,然后在该子空间上实施传统的单视角聚类方法(如k-means)得到最终的聚类结果。由于每一个视角从不同的方面揭示了目标的特征,不同视角在含有一致的类别归属信息的同时,也包含了互为补充的鉴别有益信息,因此利用多个视角进行聚类性能可以超过单视角或者对多视角的简单拼接。
由于特征收集过程中的一些不可控因素,视角缺失情况时有发生。例如,将不同报社对同一新闻的报道看作该新闻的不同视角,由于不同报社报道的新闻覆盖面不完全相同,在对新闻主题进行聚类时,视角缺失是常见的情形。同样地,将不同设备或者不同光照下对物体采集的照片视作该物体的不同视角,由于部分设备损坏或者光照条件不达标,也可能出现视角缺失的情形。近年来,学者们越来越多地关注不完备多视角情形下的聚类方法。着眼于视角缺失的挑战,学者们提出了很多方法来降低缺失视角的负面影响。一些方法(partialmulti-viewclustering,pvc,incompletemulti-modalitygrouping,img)利用完备样本(样本在各视角中的实例都存在)指导一致子空间的学习,由于这些方法要求完备样本的存在,其应用范围受到较大限制;一些方法(multi-incomplete-viewclustering,mic,doublyalignedincompletemulti-viewclustering,daimc)采用非负矩阵分解(nonnegativematrixfactorization,nmf)的框架,对视角中缺失样例的重构误差项赋予较低甚至为零的权重,这类方法往往不能捕获数据的本质结构,同时对噪声较为敏感。一些方法考虑了数据本质结构,如利用完备视角的仿射图对缺失视角的样例相似关系进行估计(multiviewclusteringwithincompleteviews,mcic),但实际的多视角数据集中常常不存在完备的视角。一些方法为了克服这个问题,直接对所有的缺失样例的相似关系进行估计(incompletemulti-viewclustering,ivc,incompletemultiviewspectralclusteringwithadaptivegraphlearning,imsc_agl),然而不恰当的估计往往会在缺失率较大时造成大幅偏离真实结果的情况。
虽然学者们提出了大量的不完备多视角聚类框架,可以在一定程度上降低视角缺失所带来的负面影响,但是这些方法普遍存在如下的问题:第一种缺陷,现有方法不能很好地捕捉数据的本质结构。只针对视角完备的样本对齐低维表征或者对缺失样例及其相似关系进行不合理的填充,都会造成数据本质结构的偏离,从而影响聚类性能。第二种缺陷,现有方法没有考虑各视角在聚类鉴别信息方面的不均衡性。由于各视角所代表的特征本身所蕴含的鉴别信息的差异性、视角受噪声干扰程度的不同、不同的缺失率导致鉴别性能下降的差异等,各视角对聚类学习的指导作用是不同的。现有方法普遍均衡地利用各视角的鉴别信息来指导聚类,导致了聚类性能的下降。
技术实现要素:
本发明提供了一种基于图补全和自适应视角权重分配的不完备多视角聚类方法,包括如下步骤:
步骤1,多视角仿射图的构建及补全步骤:归一化各视角中的样本实例,构建并补全各视角的仿射图;
步骤2,学习各视角间一致的低维表征步骤:迭代求取各视角间一致的低维表征;
步骤3,聚类步骤:归一化全局低维表征并使用传统的单视角聚类方法得到聚类类别。
作为本发明的进一步改进,步骤1,多视角仿射图的构建及补全步骤包括:
特征抽取和归一化步骤:提取目标事物的多种特征,并将每种特征视为一个视角:用
各视角仿射图的构建及填补校正步骤:
首先,在各视角x(v)中利用式
其次,利用式
最后,对上一步骤得到的各视角拉伸后的仿射图中关于缺失样例的相似信息进行校正:若第v个视角中缺失了总样本序列中第i个样本的样例,则根据式
作为本发明的进一步改进,步骤2,学习各视角间一致的低维表征步骤包括:
变量初始化步骤:对各个视角在指导子空间学习中的权重ω(v)(v=1,...,l)作均等初始化,即ω(v)=1/l(v=1,...,l);通过求解式
迭代第一步:更新全局低维表征y*。具体来说,首先求解矩阵
迭代第二步:更新各视角的低维表征y(v)(v=1,...,l)。具体来说,针对第v个视角,首先求解矩阵(λy*y*t-l(v))的特征值和特征向量,然后取其中最大c个特征值对应的特征向量
迭代第三步:更新各视角的权重鉴别因子ω(v)(v=1,...,l)。具体来说,针对第v个视角,利用式
判断收敛条件步骤:计算当前第t次迭代目标函数值
作为本发明的进一步改进,在步骤3,聚类步骤中,低维表征y*的第i行
本发明还提供了一种基于图补全和自适应视角权重分配的不完备多视角聚类装置,包括:
多视角仿射图的构建及补全单元:用于归一化各视角中的样本实例,构建并补全各视角的仿射图;
学习各视角间一致的低维表征单元:用于迭代求取各视角间一致的低维表征;
聚类单元:用于归一化全局低维表征并使用传统的单视角聚类方法得到聚类类别。
作为本发明的进一步改进,多视角仿射图的构建及补全单元包括:
特征抽取和归一化模块:提取目标事物的多种特征,并将每种特征视为一个视角:用
各视角仿射图的构建及填补校正模块:
首先,在各视角x(v)中利用式
其次,利用式
最后,对上一步骤得到的各视角拉伸后的仿射图中关于缺失样例的相似信息进行校正:若第v个视角中缺失了总样本序列中第i个样本的样例,则根据式
作为本发明的进一步改进,学习各视角间一致的低维表征模块包括:
变量初始化模块:对各个视角在指导子空间学习中的权重ω(v)(v=1,...,l)作均等初始化,即ω(v)=1/l(v=1,...,l);通过求解式
迭代第一步:更新全局低维表征y*。具体来说,首先求解矩阵
迭代第二步:更新各视角的低维表征y(v)(v=1,...,l)。具体来说,针对第v个视角,首先求解矩阵(λy*y*t-l(v))的特征值和特征向量,然后取其中最大c个特征值对应的特征向量
迭代第三步:更新各视角的权重鉴别因子ω(v)(v=1,...,l)。具体来说,针对第v个视角,利用式
判断收敛条件模块:用于计算当前第t次迭代目标函数值
作为本发明的进一步改进,在聚类单元中,低维表征y*的第i行
本发明还提供了一种基于图补全和自适应视角权重分配的不完备多视角聚类系统,包括:存储器、处理器以及存储在所述存储器上的计算机程序,所述计算机程序配置为由所述处理器调用时实现本发明所述的方法的步骤。
本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序配置为由处理器调用时实现本发明所述的方法的步骤。
本发明的有益效果是:本发明通过相似图补全技术和视角权重鉴别因子的引入,有效地捕捉了数据的本质结构,提高了聚类性能。
附图说明
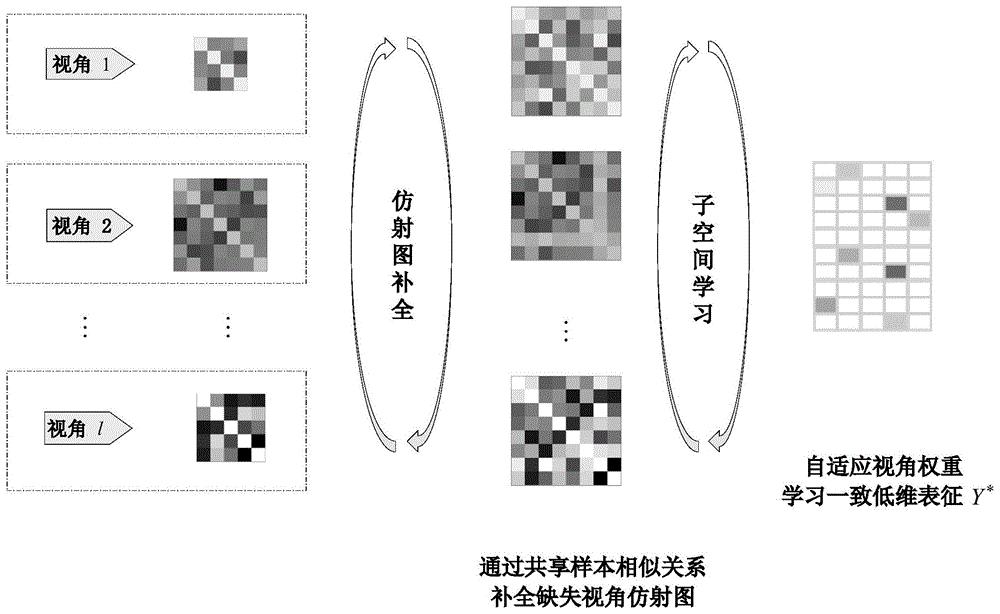
图1是本发明的原理示意图。
图2是本发明的方法流程图。
具体实施方式
针对背景技术的第一种缺陷,本发明通过图补全技术共享多个视角间样本的相似关系,挖掘数据的本质结构,同时利用谱聚类进一步捕获数据的非线性流形结构。针对背景技术的第二种缺陷,本发明引入视角权重鉴别因子,自适应地平衡每个视角在聚类学习中的重要性,从而获得更好的聚类性能。
本发明公开了一种基于图补全和自适应视角权重分配的不完备多视角聚类方法,可以合理地填充从缺失视角中学习到的仿射图,并降低各视角鉴别信息差异所带来的负面影响。为了便于从多个视角中学习到尽量一致的子空间,我们利用各视角中样本的相似信息补全从缺失视角中学习到的仿射图。与已有方法不同的是,该图填充策略填补对象是仿射图,不需要对缺失样例数据直接评估,而且该策略可以共享多个视角间的互补信息,从而大幅降低缺失样例带来的负面影响。此外,考虑到多个不同视角代表的特征鉴别能力不同、样本缺失率的差异、噪声干扰程度不同,本发明引入自适应学习的视角权重鉴别因子,来平衡鉴别信息不同的视角在聚类学习中的作用,从而大幅提高聚类的性能。
首先给定不完备多视角数据集
在本发明中,首先在各视角x(v)中使用高斯核函数(gaussiankernel)构建相似矩阵,即利用式
仿射图校正过程中,若样本总序列中第i个样本在视角x(v)中缺失了对应的实例,则利用式
传统的多视角谱聚类框架设计了如下的优化问题:
其中
传统的谱聚类框架在指导子空间的学习过程中等同看待各个视角,这使得被噪声污染严重或特征鉴别信息弱的视角与鉴别信息丰富的视角对子空间学习的贡献等同,从而导致了聚类性能的下降。为了自适应地平衡鉴别信息不同的视角在子空间学习中的作用,基于前面得到的各视角补全的仿射图,本发明提出以下的子空间学习模型来学习各视角间一致的低维表征y*:
其中ω(v)为自适应学习的视角权重鉴别因子,用来平衡各视角在子空间学习中的作用,权重幂次r起平滑作用。λ是平衡因子。通过视角权重鉴别因子ω(v)的引入,本发明能够有效降低各视角鉴别信息的差异性所带来的负面影响,从而指导模型学习到更优的子空间表示。
模型(2)中含有多个未知变量,难以求其最优解。我们使用迭代更新方法逼近模型(2)的最优解,即求解某变量时,固定其他未知变量,通过该策略对模型中的未知变量y(v),y*,ω(v)逐一进行求解。
1)求解一致的低维表征y*:
固定变量y(v),ω(v),针对一致的低维表征y*,模型(2)退化为如下优化问题:
该优化问题是特征值分解问题,故y*的最优解为矩阵
2)求解各视角的低维表征y(v)
观察模型(2)可以发现,不同视角的低维表征可以单独优化,固定变量y*,ω(v),关于y(v),优化问题(2)退化为如下的优化问题:
该问题亦为典型的特征值分解问题,即y(v)的最优解为矩阵(λy*y*t-l(v))最大的c个特征值对应的特征向量构成的矩阵。
3)求解视角鉴别因子ω(v)
同样地,固定y(v),y*,模型(2)退化为下式:
其中γ(v)=tr(y(v)tl(v)y(v))+λ(c-tr(y(v)y(v)ty*y*t))。在变量y(v),y*固定的情形下,γ(v)为固定值,该优化问题的解为
通过迭代地对以上变量进行求解,我们得到模型(2)的逼近解,迭代过程总结为算法1:
综上,本发明的具体实施步骤:
对于任意的多视角聚类问题,包括样本完全对应的完备多视角数据和任意缺失情形的不完备多视角数据,首先归一化各视角中的样本实例,构建并补全各视角的仿射图,然后学习各视角间一致的低维表征,最后归一化全局低维表征并使用传统的单视角聚类方法得到聚类类别。下面具体描述该发明实施过程的步骤细节:
步骤1,多视角仿射图的构建及补全步骤:归一化各视角中的样本实例,构建并补全各视角的仿射图;
步骤2,学习各视角间一致的低维表征步骤:迭代求取各视角间一致的低维表征;
步骤3,聚类步骤:归一化全局低维表征并使用传统的单视角聚类方法得到聚类类别。
步骤1,多视角仿射图的构建及补全步骤包括:
(1)特征抽取和归一化步骤:针对包含多个视角的聚类任务,首先灵活地提取目标事物的多种特征,并将每种特征视为一个视角。例如针对网页数据,可以提取其内容和其超链接信息视为该聚类任务的两个视角,亦可提取其文字内容和图片内容视为其两个视角。对于图像数据的聚类,可以将原始图像的元素作为特征,同时提取其hog特征等作为该任务的其他视角。用
(2)各视角仿射图的构建及填补校正步骤:
首先,在各视角x(v)中利用式
其次,利用式
最后,对上一步骤得到的各视角拉伸后的仿射图中关于缺失样例的相似信息进行校正:若第v个视角中缺失了总样本序列中第i个样本的样例,则根据式
步骤2,学习各视角间一致的低维表征步骤包括:
变量初始化步骤:对各个视角在指导子空间学习中的权重ω(v)(v=1,...,l)作均等初始化,即ω(v)=1/l(v=1,...,l);通过求解式
迭代第一步:更新全局低维表征y*。具体来说,首先求解矩阵
迭代第二步:更新各视角的低维表征y(v)(v=1,...,l)。具体来说,针对第v个视角,首先求解矩阵(λy*y*t-l(v))的特征值和特征向量,然后取其中最大c个特征值对应的特征向量
迭代第三步:更新各视角的权重鉴别因子ω(v)(v=1,...,l)。具体来说,针对第v个视角,利用式
判断收敛条件步骤:计算当前第t次迭代目标函数值
在步骤3,聚类步骤中:将步骤2学习得到的低维表征y*的第i行
本发明还公开了一种基于图补全和自适应视角权重分配的不完备多视角聚类装置,包括:
多视角仿射图的构建及补全单元:用于归一化各视角中的样本实例,构建并补全各视角的仿射图;
学习各视角间一致的低维表征单元:用于迭代求取各视角间一致的低维表征;
聚类单元:用于归一化全局低维表征并使用传统的单视角聚类方法得到聚类类别。
多视角仿射图的构建及补全单元包括:
特征抽取和归一化模块:提取目标事物的多种特征,并将每种特征视为一个视角:用
各视角仿射图的构建及填补校正模块:
首先,在各视角x(v)中利用式
其次,利用式
最后,对上一步骤得到的各视角拉伸后的仿射图中关于缺失样例的相似信息进行校正:若第v个视角中缺失了总样本序列中第i个样本的样例,则根据式
学习各视角间一致的低维表征模块包括:
变量初始化模块:对各个视角在指导子空间学习中的权重ω(v)(v=1,...,l)作均等初始化,即ω(v)=1/l(v=1,...,l);通过求解式
迭代第一步:更新全局低维表征y*。具体来说,首先求解矩阵
迭代第二步:更新各视角的低维表征y(v)(v=1,...,l)。具体来说,针对第v个视角,首先求解矩阵(λy*y*t-l(v))的特征值和特征向量,然后取其中最大c个特征值对应的特征向量
迭代第三步:更新各视角的权重鉴别因子ω(v)(v=1,...,l)。具体来说,针对第v个视角,利用式
判断收敛条件模块:用于计算当前第t次迭代目标函数值
在聚类单元中,低维表征y*的第i行
本发明还公开了一种基于图补全和自适应视角权重分配的不完备多视角聚类系统,包括:存储器、处理器以及存储在所述存储器上的计算机程序,所述计算机程序配置为由所述处理器调用时实现本发明所述的方法的步骤。
本发明还公开了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序配置为由处理器调用时实现本发明所述的方法的步骤。
本发明属于机器学习领域,是一种针对视角不完备情形的多视角聚类新方法,具体为一种利用计算机技术、数字图像处理、文本信息处理等技术实现聚类的技术。本发明应用领域较为广泛,可用于各种具有多种特征维度的目标识别和聚类场景,如基于人脸、步态等多特征识别的安防系统、企业用户画像分析、搜索引擎二次聚类、文本主题聚类、蛋白质功能属性预测等。
本发明着重于捕捉数据的本质结构,并为每个视角自适应地分配不同权重,来平衡各视角在聚类学习中的作用。具体地,本发明通过共享视角的样本相似结构进行仿射图补全,然后在各视角补全的仿射图上实施联合谱聚类学习一致的子空间,以捕捉到数据的本质结构。同时,本发明提出自适应视角权重鉴别因子,来平衡各视角在子空间学习过程中的作用。总而言之,本发明通过相似图补全技术和视角权重鉴别因子的引入,有效地捕捉了数据的本质结构,提高了聚类性能。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!