一种面向语义敏感词句的分析方法与流程
本发明属于文本分类领域,具体涉及一种面向语义敏感词句的分析方法。
背景技术:
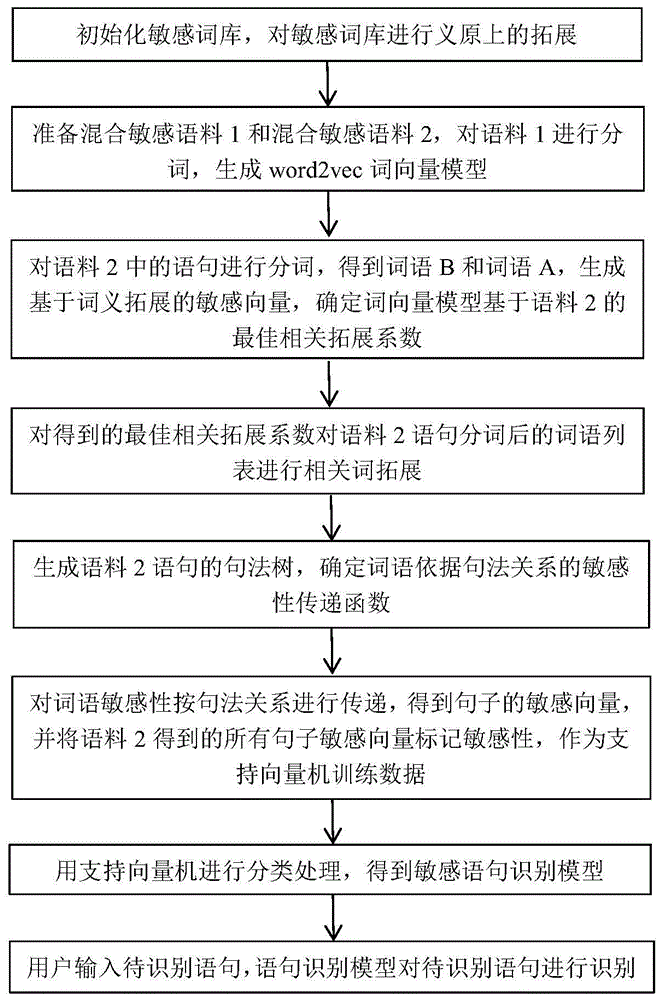
:随着网络的迅速发展,网络信息成了人们生活中必不可少的一部分,不论是在什么地方,都有人在上网,通过网络获取人们需要的信息,比如新闻、娱乐资讯、视频、评论等,互联网成了人们信息交换的媒介。与此同时,生活中常见的麻烦,也会在这个过程当中被带到互联网上,敏感语句(包括色情、暴力、反动等言论)就是其中的一部分。敏感语句在互联网上的传播会对广大网民尤其是青少年带来一系列的负面影响,不利于良好社会风气的构建。因此,如何从海量的文本信息中识别出语义敏感的词句就是一个重要的课题,面向语义敏感词句的分析方法是一个重要的研究内容。敏感文本的分析方法多种多样,已经有很多学者和机构对敏感文本的分析方法进行了各方面的研究。2005年,吴偶等人通过构建cnn-like词网,将语义和统计结合,对敏感文本进行识别;同年,李荣陆等人使用最大熵的模型方法对中文文本进行了分类;2013年,刘巍提出了基于特征簇的向量模型和双层过滤的分类器架构,在对文本进行了预处理、特征选择、特征加权、分类计算后对文本进行分类;2013年,jianpingzeng等研究出基于自适应主题建模的敏感信息文本内容检测框架,使用加权图挖掘敏感信息并发现敏感话题;2018年,卢刚结合语义分析和计算技术,设计并实现了基于语义依存关系的文本敏感性计算方法。技术实现要素:发明目的:本发明提供一种面向语义敏感词句的分析方法,可快速有效地从海量文本信息中识别出语义敏感的词句,维护网络社区环境的纯净。技术实现要素:本发明所述的一种面向语义敏感词句的分析方法,包括以下步骤:(1)初始化敏感词库,对敏感词库进行义原上的拓展;(2)准备混合敏感语料1和混合敏感语料2,对语料1进行分词,生成word2vec词向量模型;(3)对语料2中的语句进行分词,得到词语b和词语a,生成基于词义拓展的敏感向量,确定词向量模型基于语料2的最佳相关拓展系数;(4)利用步骤(2)得到的词向量模型和步骤(3)得到的最佳相关拓展系数对语料2语句分词后的词语列表进行相关词拓展;(5)生成语料2语句的句法树,确定词语依据句法关系的敏感性传递函数;(6)对词语敏感性按句法关系进行传递,得到句子的敏感向量,并将语料2得到的所有句子敏感向量标记敏感性,作为支持向量机训练数据;(7)对步骤(6)得到的训练数据,用支持向量机进行分类处理,得到敏感语句识别模型;(8)用户输入待识别语句,语句识别模型对待识别语句进行识别。所述步骤(1)包括以下步骤:(11)初始敏感词敏感级别标记为3级;(12)对初始敏感词进行全匹配,拓展词语敏感级别标记为2级;(13)对初始敏感词进行模糊匹配,拓展词语敏感级别标记为1级。所述步骤(4)通过以下方式实现:对词语b进行词语相关性拓展后,得到的词语敏感级别senb为:senb:=max(senb,senrelateda)其中,senrelateda是词语b由相关词语a关联得到的敏感级别,定义如下:其中sena∈{0,1,2,3},词语a和词语b的相关系数为κ,κ∈(0,1),整体做四舍五入处理,以符合我们对于敏感级别的定义。步骤(5)所述敏感性传递函数为:sena:=f(sena,...senchildren)其中,child是词语a在句法树上的孩子节点,...senchildren是所有孩子节点敏感性的展开。其中敏感性传递函数基于不同的句法关系定义如下:句法关系为并列关系的两个词语,其敏感性传递函数为:f(senparent,senchild)=max(senparent,senchild)句法关系为左附加关系或者右附加关系的两个词语,其敏感性传递函数为:f(senparent,senchild)=senparent+senchild主谓关系、动宾关系、间宾关系、前置宾语、兼语、定中关系、状中关系、动补结构等句法结构的敏感性传递函数的为系数相加的形式,即f(senparent,senchild)=senparent+λsenchild。有益效果:与现有技术相比,本发明的有益效果:依据句法结构,充分结合词语上下文信息,放大敏感语句中的词语敏感性,使敏感语句识别更快速、准确。经第一阶段敏感词典拓展、敏感语句分析、敏感语句分析策略对比分析以及第二阶段获取词语敏感性传递参数的最优值方法,生成面向语义敏感词句的识别模型,达到识别敏感词句的目的。附图说明图1是本发明流程图;图2是基于词语相关性的敏感语句分析策略结果图。具体实施方式下面结合附图对本发明作进一步详细说明,如图1所示,本发明包括以下步骤:1、初始化敏感词库,对敏感词库进行义原上的拓展有限的敏感词典对于敏感语句的分析是不充分的,因此选择了知网开源的hownet词典进行拓展。hownet词典由223767个以中英文词和词组所代表的概念构成,为每个概念标注了基于义原的定义以及词性、情感倾向、例句等信息,其中,中文词、英文词、义原定义能充分表示该词汇的词义,是敏感词典拓展的关键项。拓展方法有两种,一种为词语全匹配,一种为词语模糊匹配。敏感词拓展的具体步骤为:(1)从原生敏感词典中取出一个敏感词汇,记为sensitiveword;如果是完全匹配转到(2),如果是模糊匹配转到(3)。(2)在hownet词典中寻找出中文词或者英文词与sensitiveword完全一样的词汇,并且其情感为负面情感,将其加入到sensitivewordexpendlist中,转到(5)。(3)在hownet词典中寻找出中文词或者英文词与sensitiveword部分匹配的负面情感词汇,将其加入到敏感词典中,敏感级别标记为1级,转到(4)。(4)在hownet词典中寻找出sensitiveword是其义原定义中的一部分的负面情感词汇,将其加入到sensitivewordexpendlist中,转到(5)。(5)遍历sensitivewordexpendlist中的词汇,将其义原定义中的词汇取出,加入到sensitivewordexpendatomlist中,转到(6)。(6)遍历sensitivewordexpendatomlist中的义原,在hownet词典中寻找词汇x,x的中文词或者英文词或者义原中的某个词和该义原完全匹配,如果词汇x的情感为负面情感,则将其加入到敏感词典中,如果是完全匹配,则敏感级别标记为2级,如果是模糊匹配,则敏感级别标记为1级。利用openhownet-api的核心数据hownet.txt对包含9597条词汇的敏感词典进行拓展后,得到689条二级词汇,12192条一级词汇,拓展比例约134%,极大地丰富了敏感词库的内容。2、准备混合敏感语料1和混合敏感语料语料2,并对语料1进行分词,生成word2vec词向量模型;对语料2中的语句进行分词,生成基于词义拓展的敏感向量,确定词向量模型基于语料2的最佳相关拓展系数;词向量模型和最佳相关拓展系数对语料2语句分词后的词语列表进行相关词拓展基于感知机的分词模型的训练数据来自2014年人民日报切分语料,增加了少量98年人民日报中独有的词语,并加入了拓展后的敏感词典中的词语;基于神经网络的依存句法分析器的模型训练自哈工大信息检索研究中心汉语依存树库;word2vec的词向量模型训练自混合敏感语料1来自sighan05分词语料,并混入了一些敏感语句的分词语料。混合敏感语料2集合了5000多句敏感语句和15000多句非敏感语句,其中,敏感语句筛选自网络上共享的资源,非敏感语句来自微博评论和搜狗文本分类中情感倾向为正面的语句。训练数据与测试数据按照4:1的比例分布,训练数据中敏感语句4084句,非敏感语句12000句,测试数据中敏感语句1021句,非敏感语句3000句。利用词语的词向量,将词语映射到多维空间中,通过词语a和词语b之间的几何距离来衡量这两个词语之间的相关程度。如果词语a的敏感级别为sena,词语b的敏感级别为senb,词语a和词语b的相关系数为κ,那么词语b由词语a关联得到的敏感级别senrelateda为其中sena∈{0,1,2,3},κ∈(0,1),做四舍五入处理以符合我们对于敏感级别的定义。那么词语b的敏感级别的表达式为senb:=max(senb,senrelateda)(2)对于词语的相似程度进行分级,分别以[0.55,1],[0.65,1],[0.75,1],[0.85,1],[0.95,1]作为相似程度认可区间,对语料2分别进行句子敏感向量计算,对不同相似程度认可区间的训练数据进行训练。使用libsvm的java训练程序,得到的f1结果如图2所示。其中,起始相似程度为1的数据训练就是进行分词后,利用词典匹配法得到句子敏感向量进行的训练。当词语的起始相似程度大于0.75时,基于词语相关性的敏感语句分析策略效果提升明显,当词语相似程度认可区间为[0.95,1]时,基于词语相关性的敏感语句分析策略效果最佳,f1值为0.7354。3、生成语料2语句的句法树,确定词语依据句法关系的敏感性传递函数单个词语本身可能并没有敏感性,但是词语所处的上下文信息可能会赋予词语它原本所没有的敏感性,并通过句法和语义关系继续影响其他词汇,从而影响整个句子的敏感性。通过建立句法树,我们可以清晰地得到句子中各个词语之间的句法关系,这些关系在一定程度上可以代表词语之间的语义关系。如果在一个句子的句法树中,一个孩子节点所代表的词语是敏感词,那么它的所有祖先节点都会受到它的影响,从而具有一定的敏感性。当词语在句法树中为叶子节点时,其敏感性不受其他节点影响。孩子节点的敏感性senchild对于父节点的敏感性影响我们可以用敏感性传递函数f来描述sena:=f(sena,...senchildren)(3)其中,child是词语a在句法树上的孩子节点,...senchildren是所有孩子节点敏感性的展开。敏感性传递函数f,需要根据句法结构的具体情况确定,比如并列关系的敏感性传递函数定义为绝对值最大,左附加关系的敏感性传递函数定义为系数相加等等。在公式(3)中,我们用敏感性传递函数f来描述孩子节点的敏感性senchild对于父节点的敏感性影响,现在,我们来具体化敏感性传递函数f。在ltp描述的15种依存句法关系里,核心关系、标点符号没有语义体现,独立结构不影响句子中的其他结构,介宾关系在句子中的对于敏感性的语义没有明显体现,所以我们忽略核心关系、标点符号、独立结构、介宾关系这四种依存句法关系。并列关系结构,其子节点对父节点敏感性传递函数定义为两词中最大敏感值,即f(senparent,senchild)=max(senparent,senchild)(4)句法关系为左附加关系或者右附加关系的两个词语,其敏感性传递函数定义为父子节点敏感值的和,即f(senparent,senchild)=senparent+senchild(5)主谓关系、动宾关系、间宾关系、前置宾语、兼语、定中关系、状中关系、动补结构的敏感性传递函数的基本形式我们定义为系数相加,即f(senparent,senchild)=senparent+λsenchild(6)传递参数λ我们用如下算法确定。最后得到的八种依存句法关系的敏感性传递系数如表1所示:表1八种依存句法关系敏感性传递系数得到的准确率、精确率、召回率、f1值的结果如表2所示:表2依据句法关系的敏感语句分析策略结果准确率精确率召回率f1值0.91010.70910.85290.77444、敏感语句识别模型的比较下面是基于词语相关性的敏感语句分析策略、依据句法关系的敏感语句分析策略以及卢刚基于依存语义关系策略的实现结果,如表3所示:表3各种敏感语句分析策略的实现结果敏感语句分析策略准确率精确率召回率f1值词典匹配策略0.87520.60870.86340.7141词语相关策略0.88590.66870.81670.7354句法敏感传递策略0.91010.70910.85290.7744卢刚的策略0.89610.63920.80000.7106基于词语相关性的敏感语句分析策略相较于传统的词典匹配策略,f1值提升了两个百分点,有一定效果但是不是很明显,可能是因为在训练word2vec词向量模型时,所使用的敏感语料规模比较小,导致对弱敏感性的词汇无法做出有效的拓展,使得最后得到的句子的敏感特征不够明显。依据句法关系的敏感语句分析策略更充分地利用了词语在句子中的上下文语义信息,相较于基于词语相关性的敏感语句分析策略对敏感语句的辨别效率提升的更明显,比传统的词典匹配策略提高了六个百分点左右。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1