一种基于深度学习的高光谱图像分类方法与流程
本发明涉及高光谱图像分类方法,特别是涉及一种基于深度学习的高光谱图像分类方法。
背景技术:
高光谱图像同时包含了空间信息和光谱信息,光谱信息的分辨率很高,一般都达到了纳米级别,空间分辨率相对较低,具体而言分类工作就是对图像中的每一个像素进行分类确认像素的类别。高光谱图像分类大体上可以分为无监督分类和有监督分类(包含半监督分类)两种。无监督分类指的是在没有预先标注数据标签的情况下对高光谱图像进行分类(聚类),主要思想是依照能代表像素点的特征信息(空间信息、谱信息及特征等)将相似的像素归为一类。有监督的分类指的是在有预先标注数据作为监督信号的情况下对高光谱图像进行分类,主要思想是利用有标注的数据学习像素特征信息与像素类别之间的内在关系,然后利用这种关系对没有标注的数据进行分类,确定像素类别。
目前基于深度学习的高光谱图像分类主要属于有监督分类,在高光谱领域应用的深度学习模型有卷积神经网络(cnn)、基于自编码网络的栈式自编码网络(sae)、基于受限玻尔兹曼机的深度置信网络(dbn)等。深度学习的相关模型为高光谱图像分类中存在的问题提供了一些解决思路,同时也面临以下一些困难:其中一个主要的困难就是有标注的样本量有限的问题,深度学习中的模型通常需要包含大量参数,这些参数需要通过训练从而确定具体的值,而训练的过程依赖大量有标注的样本数据。
在深度卷积网络的有监督训练中,需要大量的有标签样本进行充分训练,网络才能取得优秀的分类效果。但在高光谱分类任务中,获取大量有标签样本的成本很高,而标签样本不足将会导致过拟合现象发生,最终降低模型在测试数据集中分类效果。
技术实现要素:
发明目的:本发明的目的是提供一种能够在标签样本尽可能少的情况下提高分类效果的基于深度学习的高光谱图像分类方法。
技术方案:本发明所述的基于深度学习的高光谱图像分类方法,包括以下步骤:
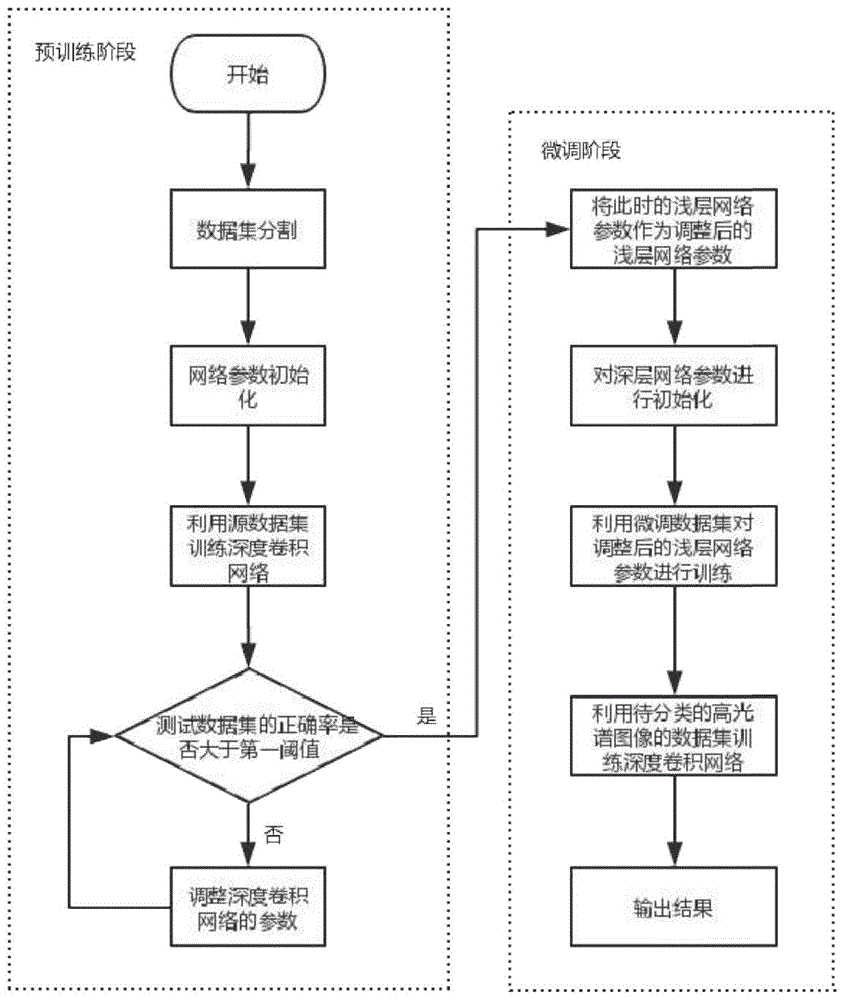
s1:对一个已有的高光谱图像的数据集进行分割,得到源数据集、微调数据集和测试数据集;
s2:对深度卷积网络的参数进行初始化;
s3:利用源数据集训练深度卷积网络,将测试数据集输入到训练好的深度卷积网络中,得到测试数据集的正确率;
s4:判断测试数据集的正确率是否大于第一阈值:如果是,则进行步骤s6;否则,则进行步骤s5;
s5:调整深度卷积网络的参数,然后返回步骤s4;
s6:将此时的浅层网络参数作为调整后的浅层网络参数;所述浅层是指深度卷积网络中用于提取所述已有的高光谱图像的数据集边缘和轮廓的卷积层;
s7:对深层网络参数进行初始化;所述深层是指深度卷积网络中除浅层以外的其他卷积层;
s8:利用微调数据集对步骤s6得到的调整后的浅层网络参数进行训练;
s9:利用待分类的高光谱图像的数据集训练深度卷积网络;
s10:输出结果;
所述步骤s1-s5为预训练阶段,步骤s6-s10为微调阶段。
进一步,所述步骤s4中的第一阈值为90%。
进一步,所述步骤s1具体包括以下步骤:
s11:选取indianpines数据集作为已有的高光谱图像的数据集,数据集中数据的维数为145*145*220,数据集中共有16类作物;
s12:去除数据集中20个水吸收严重的波段,将数据集中的数据进行维度转化;
s13:随机选取已有的高光谱图像的数据集中25%的数据作为源数据集对深度卷积网络进行预训练,再从indianpines中每个类别选取n个数据构成微调数据集,将余下所有数据作为测试数据集。
进一步,所述步骤s2中,初始化后各参数为:预训练阶段的学习率为0.008,微调阶段的学习率为0.0008,预训练阶段和微调阶段的训练总次数均为1000,卷积核的高度为4,卷积核的宽度为1,图像通道数为10,卷积核个数为16,步长为2,深度卷积网络的卷积层和池化层中的超参数padding为填充,最大池化层的核尺寸为2。
进一步,所述步骤s3具体包括以下步骤:
s31:将64个像素点的波段信息20*1*10输入深度卷积网络的卷积层,卷积层输出64个像素点的波段信息为40*1*16;
s32:将卷积层输出的64个像素点的波段信息40*1*16输入深度卷积网络的最大池化层,最大池化层输出向量(batch,20,1,16);
s33:将最大池化层输出的向量(batch,20,1,16)输入深度卷积网络的bn层,然后再将最大池化层输出的向量(batch,20,1,16)输入深度卷积网络的激励层;再利用tensorflow自带函数tf.reduce_mean()、tf.cast计算测试数据集的正确率。
进一步,所述步骤s7中,初始化后各参数为:卷积核的高度为4,卷积核的宽度为1,图像通道数为10,卷积核的个数为16,步长为2,深度卷积网络的卷积层和池化层中的超参数padding为填充,最大池化层的核尺寸为2。
有益效果:本发明公开了一种基于深度学习的高光谱图像分类方法,能够在尽可能少的标签样本的情况下避免过拟合现象,提高了深层网络在小样本情况下的分类效果,在采用同等数据量进行训练网络时有一定的优势。
附图说明
图1为本发明具体实施方式中方法的流程图;
图2为本发明具体实施方式中卷积核调整参数后的结果曲线;
图2(a)为第一个卷积核调整参数后的结果曲线;
图2(b)为第二个卷积核调整参数后的结果曲线;
图2(c)为第三个卷积核调整参数后的结果曲线;
图3为本发明具体实施方式中未调整卷积核参数的结果曲线。
具体实施方式
本具体实施方式公开了一种基于深度学习的高光谱图像分类方法,如图1所示,包括以下步骤:
s1:对一个已有的高光谱图像的数据集进行分割,得到源数据集、微调数据集和测试数据集;
s2:对深度卷积网络的参数进行初始化;
s3:利用源数据集训练深度卷积网络,将测试数据集输入到训练好的深度卷积网络中,得到测试数据集的正确率;
s4:判断测试数据集的正确率是否大于第一阈值:如果是,则进行步骤s6;否则,则进行步骤s5;
s5:调整深度卷积网络的参数,然后返回步骤s4;
s6:将此时的浅层网络参数作为调整后的浅层网络参数;所述浅层是指深度卷积网络中用于提取所述已有的高光谱图像的数据集边缘和轮廓的卷积层;
s7:对深层网络参数进行初始化;所述深层是指深度卷积网络中除浅层以外的其他卷积层;
s8:利用微调数据集对步骤s6得到的调整后的浅层网络参数进行训练;
s9:利用待分类的高光谱图像的数据集训练深度卷积网络;
s10:输出结果;
所述步骤s1-s5为预训练阶段,步骤s6-s10为微调阶段。
图2(a)—图2(c)是三个卷积核调整参数后的结果曲线。图3是未调整卷积核参数的结果曲线。
步骤s4中的第一阈值为90%。
步骤s1具体包括以下步骤:
s11:选取indianpines数据集作为已有的高光谱图像的数据集,数据集中数据的维数为145*145*220,数据集中共有16类作物;
s12:去除数据集中20个水吸收严重的波段,将数据集中的数据进行维度转化;
s13:随机选取已有的高光谱图像的数据集中25%的数据作为源数据集对深度卷积网络进行预训练,再从indianpines中每个类别选取n个数据构成微调数据集,将余下所有数据作为测试数据集。
步骤s2中,初始化后各参数为:预训练阶段的学习率为0.008,微调阶段的学习率为0.0008,预训练阶段和微调阶段的训练总次数均为1000,卷积核的高度为4,卷积核的宽度为1,图像通道数为10,卷积核个数为16,步长为2,深度卷积网络的卷积层和池化层中的超参数padding为填充,最大池化层的核尺寸为2。
步骤s3具体包括以下步骤:
s31:将64个像素点的波段信息20*1*10输入深度卷积网络的卷积层,卷积层输出64个像素点的波段信息为40*1*16;
s32:将卷积层输出的64个像素点的波段信息40*1*16输入深度卷积网络的最大池化层,最大池化层输出向量(batch,20,1,16);
s33:将最大池化层输出的向量(batch,20,1,16)输入深度卷积网络的bn层,然后再将最大池化层输出的向量(batch,20,1,16)输入深度卷积网络的激励层;再利用tensorflow自带函数tf.reduce_mean()、tf.cast计算测试数据集的正确率。
步骤s7中,初始化后各参数为:卷积核的高度为4,卷积核的宽度为1,图像通道数为10,卷积核的个数为16,步长为2,深度卷积网络的卷积层和池化层中的超参数padding为填充,最大池化层的核尺寸为2。
- 还没有人留言评论。精彩留言会获得点赞!