用于CT影像设备的加速图像处理系统的制作方法
本发明涉及一种用于ct影像设备的加速图像处理系统。
背景技术:
在医疗ct影像设备中,ct处理的一个瓶颈在于处理实时图像的速度。当前图像的前处理是在嵌入式系统中,但是在大部分嵌入式系统没有专用的图像计算模块,且大部分系统均是使用arm架构的嵌入式模块,arm属于risc指令架构的cpu,指令集相对比较少,编写嵌入式程序相对精简,需要的存储规模比较小,占用内存小,因此系统功耗会比较低,移植性也比较好。但是针对图像的计算主要是矩阵和向量的计算,arm处理器性能远远落后于同样主频的x86系列(cisc处理器,硬件汇编指令丰富,流水线丰富,但功耗很大,程序库比较大),ati/nvidia的gpu模块(核心数非常多,适合矩阵处理,同样功耗问题比较大)以及专用的图像处理dsp(流水线比arm丰富,内部集成dsp常用模块,比如矩阵计算,高性能乘/除法器),但这三种器件价格都非常昂贵。因此目前ct影像设备大部分图像的后处理以及合成算法均在计算性能更为强大的pc端处理,而此时ct影像设备图像数据的网络通信速度将决定整个系统的瓶颈。
当前的ct影像设备要么采用x86,gpu等高端处理器的嵌入式平台来进行图像的实时处理,价格昂贵。要么将图像数据通过网络发出来在pc上处理,但速度会受限于网络通信的速度。
技术实现要素:
为了解决上述问题,本发明提供了一种可应用于ct影像设备的加速图像处理系统,可用于基于arm平台的ct影像设备,解决网络通信的速度受限问题,以加速图像传输速度。本发明提供的用于ct影像设备的加速图像处理系统主要包括:
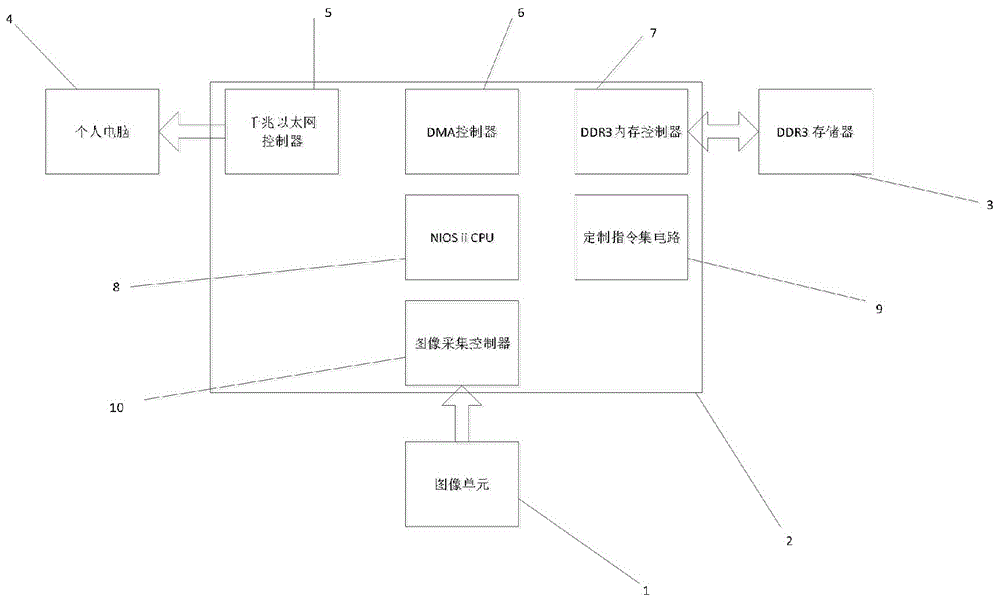
提供所述ct影像设备成像过程中产生的图像数据的图像单元,用以实现加速图像处理的fpga,为fpga提供内存缓存并临时存储图像数据的ddr3存储器,和接收fpga传出的图像数据并将收到的图像数据进行显示的个人电脑。
其中,所述的图像单元的输出端连接fpga的输入端;
所述的fpga的输出端连接个人电脑的输入端;
所述的ddr3存储器和fpga之间有数据输入输出的交互。
其中所述fpga具备:
驱动所述图像单元的图像采集控制器,驱动千兆以太网的千兆以太网控制器,用以进行fpga内部数据传输的dma控制器,驱动ddr3存储器的ddr3内存控制器,用以协调图像数据加载成网络通信的数据的niosiicpu,和定制指令集电路。
根据本发明,fpga能快速地将图像数据转换成网络通信相应的格式,以加速图像传输。
本发明提供的用于ct影像设备的加速图像处理系统借助于上述构成的fpga可以快速提高网络通信速度,大大提高系统处理实时图像的速度,而且价格实惠,功耗低。本发明在ct影像设备实时图像处理中有着非常好的性价比,既没有gpu,dsp以及x86芯片这样价格昂贵、功耗大,又能保证ct影像设备中不受限于网络通信,另个人电脑能实时地处理图像数据。在保证性能的基础上节省了大量成本。
优选地,所述dma控制器将所述图像采集控制器采集到的图像数据写入到所述ddr3内存控制器,同时将所述ddr3内存控制器中的数据传输到千兆以太网控制器。
优选地,所述定制指令集电路包括反码求和电路和swizzle电路以实现反码求和功能和swizzle功能。
根据下述具体实施方式并参考附图,将更好地理解本发明的上述内容及其它目的、特征和优点。
附图说明
图1是本发明一实施形态的用于ct影像设备的加速图像处理系统的结构框图。
图2是本发明一实施形态的加速图像处理方法的流程图。
图3和图4是本发明一实施形态的可应用于ct影像设备的加速图像处理系统中定制指令集电路--swizzle32bit字节序交换电路的rtl图。
图5是本发明一实施形态的可应用于ct影像设备的加速图像处理系统中定制指令集电路--反码求和电路的rtl图。
具体实施方式
以下结合附图和下述实施方式进一步说明本发明,应理解,附图及下述实施方式仅用于说明本发明,而非限制本发明。
为了克服现有技术无法在价格较低的arm平台上获得实时图像处理数据,本发明提供了一种用于ct影像设备的加速图像处理系统。以下,结合图示进行进一步详细说明。
图1是本发明一实施形态的用于ct影像设备的加速图像处理系统的结构框图。图2是本发明一实施形态的加速图像处理方法的流程图。
如图1所示,其中示出了图像单元,个人电脑,ddr3存储器以及位于fpga上的千兆以太网控制器,dma控制器,ddr3内存控制器,niosiicpu,定制指令集电路和图像采集控制器。
如图1所示,以下详细描述了用于ct影像设备的加速图像处理系统内各个模块的相互连接关系。
用于ct影像设备的加速图像处理系统由图像单元1,fpga2,ddr3存储器3,个人电脑4组成。
所述的图像单元1的输出端是fpga的输入端。所述的fpga的输出端是个人电脑4的输入端。所述的ddr3存储器用来起缓存作用。
图像采集控制器10,千兆以太网控制器5,dma控制器6,ddr3内存控制器7,niosiicpu8,定制指令集电路9位于fpga上。
根据本发明,fpga能快速的将图像数据转换成网络通信相应的格式,以加速图像传输。
具体而言,图像单元1提供ct影像设备成像过程中产生的图像数据,fpga2上提供了实现千兆以太网控制器5,dma控制器6,ddr3内存控制器7,niosiicpu8,定制指令集电路9和图像采集控制器10的载体。ddr3存储器3用来给fpga2提供内存缓存,用来临时存储图像数据。个人电脑4用来接受fpga2传出来的数据,将收到的图像数据显示出来。千兆以太网控制5主要用来发送图像数据,dma控制器6主要负责将图像采集控制器10采集到的图像数据写入到ddr3内存控制器7,同时还负责将ddr3内存控制器7中的数据传输到千兆以太网控制器5,ddr3内存控制器7用来从ddr3存储器3进行数据的读和写。niosiicpu8不仅调用定制指令集电路9,而且是整个传输过程中的大脑。定制指令集电路9是用来实现反码求和电路和swizzle电路。图像采集控制器10用来读取图像单元1中的数据。
图2是本发明一实施形态的加速图像处理方法的流程图。如图所示,当ct影像设备的图像单元产生图像数据后,会传递到图像采集控制器10,dma控制器6会将图像数据送到ddr3内存控制器7中,ddr3内存控制器7会将图像数据进一步存到ddr3存储器3中。niosiicpu8会发出命令,dma控制器6会将图像数据从ddr3内存控制器7中读出,此时,ddr3内存控制器7就会去读取ddr3存储器3中的数据,通过ddr3内存控制器7送到dma控制器6中。dma控制器6将需要进行反码求和和swizzle的数据送给到niosiicpu8,niosiicpu8将需要处理的数据送到定制指令集电路9进行处理,定制指令集电路9有反码求和电路和swizzle电路,从而快速的完成了反码求和功能和swizzle功能,将相应的数据返回给niosiicpu8,niosiicpu8将这个处理后的数据和其他数据组合后重新返回给dma控制器6,dma控制器6将转化后的数据发送到千兆以太网控制器5,千兆以太网控制器5最后发送到个人电脑4进行处理。
具体而言,本发明一实施形态中,可采用altera公司提供的fpga以及niosiicpu,并且实现定制的指令集电路,以进一步加速图像数据的网络通信,从而进一步提高个人电脑上实时图像数据处理。
系统中fpga主要负责以下3部分工作:
1,采集图像单元的图像数据;
2,把采集到的图像数据写入ddr3存储器;
3,把ddr3缓存的图像数据发送到个人电脑上,在个人电脑上重建图像。由于在发送过程中需要把字节序从主机序换成网络序,并对发送数据进行ip层的首部校验,此时niosiicpu会调用定制指令集电路中的swizzle电路快速完成主机序转网络序,和定制指令集中的反码求和电路完成ip层首部检验工作。
优选地,定制指令集电路通过反码求和电路和swizzle电路来实现反码求功能和swizzle功能。现说明具体的反码求和和swizzle这两个功能的定制指令实现:
图3和图4是本发明一实施形态的可应用于ct影像设备的加速图像处理系统中定制指令集电路--swizzle32bit字节序交换电路的rtl图。图5是本发明一实施形态的可应用于ct影像设备的加速图像处理系统中定制指令集电路--反码求和电路的rtl图。
为了克服现有的niosiicpu中没有反码求和和swizzle功能,本发明新增了反码求和电路,加速ip数据包首部字节校验。反码求和电路用于ip包发送前的数据校验,ip包最后的校验字节会是ip数据包首部字节的反码求和。整个电路可以从原来的五个指令周期内完成反码求和功能提高到一个指令周期内完成反码求和功能。
这样可以大大加速发送图像数据到服务器端的速度(相当于每次发送ip包时数据首部自检每两个字从5个指令变成1条指令,节省时间=(5-1)*(ip报文头字节长度/4),ip报文首部长度最小有20个字节,即4*5=20个指令周期,相当于发送一次ip包即可省下20个系统clk,对于图像这种大数据,可以省下的指令执行周期非常可观。每发送一个ip包,可以节约80%的时间。
本发明中的swizzle电路,用于交换字节序,用于tcp协议中交换主机字节序(littleendian)到网络字节序(bigendian)。整个电路可以从原来的九个指令周期完成的swizzle功能提高到一个指令周期内完成swizzle功能。
对于网络通讯而言,每次发送端发送32bit数据时可以节约8个clk周期,带来的时间开销的节约是非常可观的。图像数据从主机序转网络序的过程中节省了88%的时间。
本发明的电路设计在使用软核时,利用了定制化指令集电路完成了反码求和功能和swizzle功能,大大提高了图像数据网络通信的速度,每发送一个图像ip包至少可以节约80%,并且每发送32bit图像数据可以节约88%,对于降低整个系统的开销是非常可观的。
在不脱离本发明的基本特征的宗旨下,本发明可体现为多种形式,因此本发明中的实施形态是用于说明而非限制,由于本发明的范围由权利要求限定而非由说明书限定,而且落在权利要求界定的范围,或其界定的范围的等价范围内的所有变化都应理解为包括在权利要求书中。
- 还没有人留言评论。精彩留言会获得点赞!