新词发现方法与流程
本发明涉及智能交互领域,尤其涉及一种基于社会化媒体的新词发现方法及装置。
背景技术:
在中文信息处理的众多领域,均需要基于词典完成对应的功能。例如,在智能检索系统或智能对话系统中,通过分词、问题检索、相似度匹配、确定检索结果或智能对话的答案等,其中每个过程都是通过词语为最小单位进行计算,计算的基础为词语词典,所以词语词典对于智能系统的性能有着很大的影响。
随着互联网的蓬勃发展,微博、微信等社会化媒体平台的出现改变了人们以往的传统交流互动方式,网民在多种网络平台发表自己的观点,网友倾向于使用网络新词,多数内容及评论往往是偏口语化的表达,因此有很多新词被网友们创造出来并能以很快的速度在网络上传播。而是否能在新词出现后及时更新词语词典,对词语词典所在的智能对话系统的系统效率有着决定性的影响。
目前新词发现的方法可以分为两类:基于分类的方法和基于标注的方法。基于分类的方法是先从语料中抽取候选字符串,然后依据规则或统计信息再判断候选字符串是不是新词。基于标注的方法则是新词发现与中文分词相结合,在分词的基础上发现新词。但目前的新词发现方法,如专利201510706254.x、201810409087.6、201810409083.8等,存在以下缺点:分词单元中限制字长会导致一部分新词不能被召回;计算单元中特征参数不够全面会导致新词准确率降低。
为提高新词的召回率及准确率,本发明提出一种新词发现方法,糅合以上两种方法,在中文分词的基础上,依据规则与统计信息进行新词发现。
技术实现要素:
本发明解决的技术问题是如何提升新词发现的准确度。
为解决上述技术问题,本发明提供一种新词发现方法,包括以下步骤:
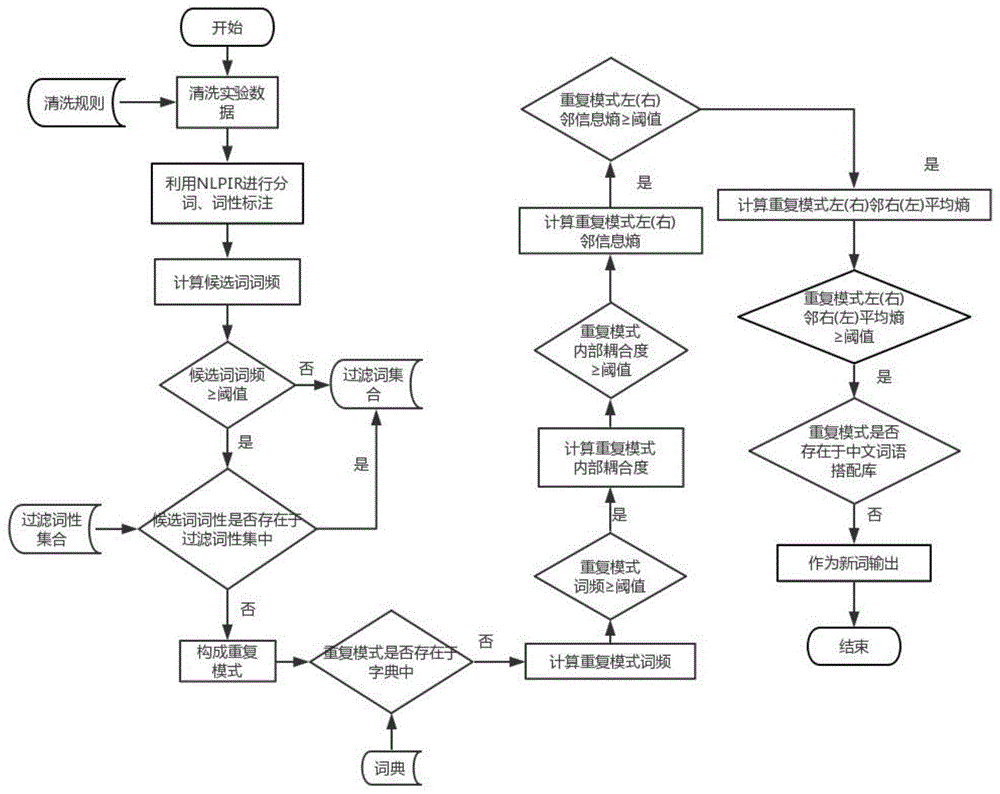
s1:语料清洗并保存;
s2:切分语料并标注词性;
s3:词频过滤和词性过滤;
s4:构建重复模式集合;
s5:重复模式过滤删除;
s6:剩余重复模式即为新词。
进一步地,所述语料清洗并保存包括:按照语料清洗规则对实验语料进行清洗,并把语料库中的语料以条为单位按行进行保存。
进一步地,所述切分语料并标注词性包括:使用nlpir工具及用户词典对微博语料进行分词并标注词性,获取词性标注后的语料。进一步地,所述词频过滤和词性过滤包括以下步骤:
s31:统计词性标注后的语料中每个词出现的频率,根据预先设置的词频阈值,把低频词放入过滤词表中,高频词加入到初始候选列表中;
s32:构建过滤词性集合,判断词性标注后的语料中词语词性是否存在于过滤词性集合中,若存在,将其加入到过滤词表中,否则将其加入初始候选列表中。
进一步地,所述构建重复模式集合包括:循环遍历初始候选列表l0,取到某个初始候选词,在初始候选词上叠加其右侧词语,如果右侧词语不存在于过滤词表中则叠加,得到重复串1后将其加入重复模式列表r中,继续在重复串1的基础上叠加其右侧的词语,如果右侧词语不存在于过滤词表中则叠加,得到重复串2后将其加入重复模式列表r中;上述叠加过程直到右侧词语遇到标点符号或过滤词表中的词时即停止,进而得到重复模式列表。
进一步地,所述重复模式过滤删除包括以下步骤:
s51:使用整合的基础词典对获得的重复模式列表进行过滤,若重复模式存在于基础词典中则过滤删除;
s52:计算重复模式的词频,根据预先设置的词频阈值,对重复模式词频进行过滤,把低于阈值的重复模式删除。
进一步地,所述重复模式过滤删除进一步包括以下步骤:
s53:计算重复模式的内部耦合度,根据预先设置的阈值,对重复模式进行过滤,把低于阈值的重复模式删除;
s54:统计重复模式的左邻接字符集和右邻接字符集,根据预先设置的左(右)邻接熵阈值,对于低于左(右)邻接熵阈值的重复模式过滤删除。
s55:统计重复模式的每一个左邻接字符的右邻接字符集和每一个右邻接字符的左邻接字符集,根据预先设置的左(右)邻右(左)平均邻接熵阈值,对于低于平均邻接熵阈值的重复模式过滤删除。
s56:使用中文词语搭配库对上一步获得的重复模式进行过滤,若重复模式存在于中文词语搭配库中则过滤删除。
本发明的新词发现方法,采用的系统包括语料预处理单元、分词单元、筛选过滤单元、重复模式构建单元、统计信息计算单元;其中语料预处理单元对语料清洗并保存;分词单元切分语料并标注词性;筛选过滤单元对候选词进行词频过滤和词性过滤;重复模式构建单元对候选词构建重复模式集合;统计信息计算单元计算重复模式的内部耦合度等参数,并进行过滤删除。
与现有技术相比,本发明采用基于规则与统计相结合的方法进行新词发现,具有以下有益效果:
其一,分词单元中,本发明采用中文分词工具对实验语料进行分词,加入了整合的用户词典,最大限度保证了词语切分的准确度,进而保证了新词的准确率。
其二,在筛选过滤单元中,本发明不仅构建了停用词性集合,也整合了多个词典作为后台基础词典。
其三,本发明中的过滤筛选中包含了词频、内部耦合度、左(右)邻接信息熵、左邻右邻接熵、右邻左邻接熵、左邻右平均邻接熵及右邻左平均信息熵等判断标准,大大提高了新词的准确率。
附图说明
图1是本发明的新词发现方法的流程图。
具体实施方式
为使本发明的上述目的、特征和有益效果能够更为明显易懂,下面结合附图1对本发明的具体实施例做详细的说明。
首先,按照语料清洗规则对实验语料进行清洗,并把语料库中的语料以条为单位按行进行保存。
其次,顺序读取每一行,使用nlpir工具及用户词典切分微博语料并标注词性,获取词性标注后的语料。
然后,统计词性标注后的语料中每个词出现的频率,根据预先设置的词频阈值,把低频词放入过滤词表中,高频词加入到初始候选列表中。
接下来,构建过滤词性集合,判断词性标注后的语料中词语词性是否存在于过滤词性集合中,若存在,将其加入到过滤词表中;若不存在,将其加入初始候选列表中,进入下一步骤。
实例:在原始微博语料中,选取某条微博“吃土一词源于双十一购物狂欢节,网友们在购物的过程中因花销超预算自嘲下个月吃土,来形容过对网络购物的一种疯狂程度。”第一次分词后的语料切分和词性标注结果为:吃/v土/n一/m词/n源于/v双十一/nz购物/vn狂欢节/n,/wd网友/n们/m在/p购物/vi的/ude1过程/n中/n因/p花销/n超预算/n自嘲/vi下个月/nz吃/v土/n,/wd来/vf形容/v过/vf对/p网络/n购物/vi的/ude1一/m种/v疯狂/a程度/n。/wj。根据词频,将切分语料中的低频词——“过程”、“花销”、“下个月”、“形容”、“疯狂”、“程度”加入到过滤词表中。根据词性,将切分语料中的“一”、“,”、“们”、“在”、“的”、“因”、“来”、“过”、“对”添加到过滤词表中。
s5:构建重复模式集合,若当前候选词右侧存在字符串且不是标点符号,则进一步判断当前字符串是否存在于上述过滤词语集合及过滤词性集合中,若均不在,则对当前候选词及当前字符串进行组合得到重复模式,进而得到重复模式列表。
具体地,循环遍历初始候选列表l0,取到某个初始候选词,在初始候选词上叠加其右侧词语,如果右侧词语不存在于过滤词表中则叠加,得到重复串1后将其加入重复模式列表r中,继续在重复串1的基础上叠加其右侧的词语,如果右侧词语不存在于过滤词表中则叠加,得到重复串2后将其加入重复模式列表r中;上述叠加过程直到右侧词语遇到标点符号或过滤词表中的词时即停止。
实例:针对切分语料,构建重复模式的过程为:首先从“吃”开始构建“吃土”,由于“一”在过滤词表中则停止迭代;然后从“词”开始构建“词源于”、“词源于双十一”、“词源于双十一购物”、“词源于双十一购物狂欢节”、“源于双十一”、“源于双十一购物”、“源于双十一购物狂欢节”、“双十一购物”、“双十一购物狂欢节”、“购物狂欢节”,由于“,”在过滤词表中则停止迭代;由于“们”、“在”、“的”、“过程”、“中”、“因”、“花销”在过滤词表中,从“超预算”开始构建“超预算自嘲”,又因为“下个月”在过滤词表中停止迭代;从“吃”开始构建“吃土”,由于“,”、“来”、“形容”、“过”、“对”在过滤词表中停止迭代;从“网络”开始构建“网络购物”,由于“的”、“一”、“疯狂”、“程度”在过滤词表中停止迭代,重复模式构建过程结束。
s6:使用整合的基础词典对上一步获得的重复模式列表进行过滤,若重复模式存在于基础词典中则过滤删除。若不存在,进入s7。
实例:使用基础词典对重复模式的结果进行过滤,得到候选新词为:“吃土”、“词源于”、“词源于双十一”;“词源于双十一购物”、“词源于双十一购物狂欢节”、“源于双十一”、“源于双十一购物”、“源于双十一购物狂欢节”、“双十一购物”、“双十一购物狂欢节”、“购物狂欢节”、“超预算自嘲”、“网络购物”。
s7:计算重复模式的词频。根据预先设置的词频阈值,对重复模式词频进行过滤,把低于阈值的重复模式删除。
实例:通过计算词频过滤掉以下候选词:“词源于”、“词源于双十一”;“词源于双十一购物”、“词源于双十一购物狂欢节”、“源于双十一”、“源于双十一购物”、“源于双十一购物狂欢节”、“超预算自嘲”、“网络购物”。
s8:计算重复模式的内部耦合度。穷举重复模式的所有子串,并对子串进行内部耦合度计算,通过公式(1)求得该重复模式内部耦合度的值。根据预先设置的阈值,对重复模式进行过滤,把低于阈值的重复模式删除。
其中,通过内部耦合度(insidecoupling)来可以衡量词语内部紧密程度,定义如下:对字串w划分为两个分字串所有的可能组合{(w11,w12),(w21,w22)…(wi1,wi2)…(wn1,wn2)}(例“中国人”所有可能组合:{(“中国”,“人”),(“中”,“国人”)},得到的ic(w)称为字串w的内部耦合度。其中p(w)表示字串w在文本域d(原始语料)出现概率,通过公式:
计算,n(w)表示w字串在文本域d中出现的次数,nd表示文本域的总字数。ic值越大,说明字串间的相关程度越高,该词语的内聚性越高;反之,ic值越小,说明字串间的相关程度越低,该词语的内聚性越低。
实例:通过计算内部耦合度过滤掉以下候选词:“双十一购物”、“双十一购物狂欢节”、“购物狂欢节”。
s9:统计重复模式的左邻接字符集和右邻接字符集。通过公式(3)分别求出每个重复模式的左(右)邻接熵。根据预先设置的左(右)邻接熵阈值,对于低于左(右)邻接熵阈值的重复模式过滤删除。
字串w在文本域d中所有可能出现在w左(右)侧的单字的集合c={c1,c2,ci,…cn}称为w的左(右)邻字集。对c通过公式:
计算得到的ie(w)称为w的左(右)邻字集的信息熵。其中ni表示ci作为w的左(右)邻字出现的次数,n表示邻字集c中的所有字作为w的左(右)邻字出现的次数之和,lb表示以2为底的对数。
s10:统计重复模式的每一个左邻接字符的右邻接字符集和每一个右邻接字符的左邻接字符集。通过公式(4)、(5)计算每个词的左邻右邻接熵和右邻左邻接熵,通过公式(6)、(7)计算每个词的左邻右平均邻接熵和右邻左平均邻接熵。根据预先设置的左(右)邻右(左)平均邻接熵阈值,对于低于平均邻接熵阈值的重复模式过滤删除。
左邻右邻接熵:
其中xi表示候选词的左邻字,i表示候选词左邻字个数,gj表示候选词左邻字的右邻字,j为当前xi的右邻字个数;p表示在候选词的左邻字集中以xi作为候选词左邻字的概率。
右邻左邻接熵:
其中xi表示候选词的右邻字,i表示候选词右邻字个数,gj表示候选词右邻字的左邻字,j为当前xi的左邻字个数;p表示在候选词的右邻字集中以xi作为候选词右邻字的概率。
左邻右平均邻接熵:
其中lre(xi)表示候选词的左邻右邻接熵,m表示候选词左邻右邻字的个数。
右邻左平均邻接熵:
其中rle(xi)表示候选词的右邻左邻接熵,m表示候选词右邻左邻字的个数。
s11:使用中文词语搭配库对上一步获得的重复模式进行过滤,若重复模式存在于中文词语搭配库中则过滤删除。
s12:剩余的词就认为是新词。
实例:计算左邻信息熵、右邻信息熵、左邻右信息熵、右邻左信息熵、左邻右平均邻接熵、右邻左平均邻接熵,本条语料中没有被过滤的候选词。最终得到的新词为“吃土”。
本发明的新词发现方法,采用的系统包括语料预处理单元、分词单元、筛选过滤单元、重复模式构建单元、统计信息计算单元;其中语料预处理单元对语料清洗并保存;分词单元切分语料并标注词性;筛选过滤单元对候选词进行词频过滤和词性过滤;重复模式构建单元对候选词构建重复模式集合;统计信息计算单元计算重复模式的内部耦合度等参数,并进行过滤删除。
虽然本发明披露如上,但本发明并非限定于此。任何本领域技术人员,在不脱离本发明的精神和范围内,均可作各种更动与修改,因此本发明的保护范围应当以权利要求所限定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!