一种基于语义相似度的APIFramework服务发现方法与流程
本发明涉及5g网络能力开放应用程序框架(apiframework)的服务发现问题,特别涉及一种基于语义相似度的apiframework服务发现方法。
背景技术:
工业互联网已成为产业升级发展的必然趋势,5g网络依靠多接入、广覆盖、高性能以及丰富的网络控制和组网方案等优势功能,正在逐渐成为工业企业优先考虑的部署选择。与此同时,5g移动通信系统标准化成为一个亟待解决的问题。在标准化组织第三代合作伙伴计划(3gpp)中,存在多个北向应用程序接口(api)相关规范(例如,用于3gpp技术规范(ts)23.682中定义的服务能力暴露功能(scef)功能的api,用于mbts服务提供商和3gpptr26.981中定义的bm-sc之间的接口的api)。为避免不同api规范之间的方法重复和不一致,3gpp考虑开发通用api框架(capif),其中包括适用于任何北向服务api的常见方面。
参照r15能力开放标准规范,研发出api网关(gw)系统,提供基于restful的网络能力开放api,为第三方提供调用获得相关网络能力(如用户位置、基于业务要求的数据传输qos保障等)的服务;设计能力开放apiframework,实现api的注册,发现及授权机制,进行标准化操作从而弥补现有技术中不能为apiframework的管理提供一套完整解决方案的问题。
基于5g通信技术和网络的不断发展和演进,在apiframework中构造restful形式的服务集,为用户提供更加高效、便捷的服务。然而在服务大规模增长的场景下,apiframework如何在保证服务集完备性和健壮性的前提下,通过服务之间相似度的衡量,从而发现新的服务类别来扩展该apiframework的服务范围。其中,服务发现依赖于服务之间的相似度,而服务之间的相似度最终转化为对于api中的概念语义相似度的计算,传统的语义相似度计算方法分为四类,分别为基于距离的方法、基于信息量的方法、基于属性的方法以及混合式方法。这四种语义相似度计算方法特点如下:
(1)基于距离的方法
基于距离计算语义相似度的思想:在本体概念结构树中通过向量化概念词来计算两个概念之间的路径长度,通过两个概念在路径维度上的结果得出相似度关系,规定两个概念词在本体层次树中的路径长度越大,相似度越小。传统基于距离的计算方法主要利用了语义字典(wordnet)中的上下位结构信息来计算相似度,方法简单易实施,但是由于只利用距离、深度、宽度等语义信息进行计算,在计算的准确性方面表现较差,从而影响了服务发现的效率。
(2)基于信息量的方法
基于信息量计算语义相似度的方法是将概念的信息量与本体知识相结合,即认为概念对之间共享信息量越高,其概念的差异信息量越少,相似度则越高。其中,共享信息量根据共享的父节点信息量计算,而差异信息量根据各个概念与共享父节点的差量来计算。在本体的概念结构树中,每个概念子节点可以认为是根节点的实例化以及概念的扩展,因此根据其父节点之间的信息量的关系可以计算其概念之间的相似度。基于信息量的语义计算方法能够客观的反应概念节点在语义、语法等方面的相似度和差异性,但其最大的问题是,信息量的计算依赖于语料库,不同的语料库存在较大的差异,使用不同的语料库计算也会产生很大的差异,从而导致其语义相似度的计算很难形成统一的结果,从而影响其服务发现的可信度。
(3)基于属性的方法
基于属性的语义相似度计算方法主是通过两个概念之间属性集的相似程度来衡量语义的相似度关系。基于属性的语义相似度基于本体属性的重叠程度来计算语义相似度,从而更好地解决跨本体的语义相似度问题,从而很好的弥补了基于距离计算语义相似度时无法跨本体的问题。基于属性的方法依赖概念节点具有完备的属性集,对于wordnet等大型本体字典才会拥有丰富的语义知识,而其他的特定领域词典不会含有足够的语义内容,从而造成属性的相似度无法有效的计算,影响最终语义相似度的准确率,导致其服务发现的效率比较低。
(4)混合式方法
不同于基于距离、基于信息量以及基于属性的计算方法,混合式的计算方法充分利用多种语义信息,对于各种计算因素加以不同的权重,得到最终的相似度计算结构。由于使用语义信息更加充分,该方法能够极大的挖掘语义信息来提高准确度。然而,由于其需要根据领域本体设置权值,从而权重设置的不确定性影响了这种方法的普适性,通用的语义词典很难满足特定的业务需求,导致在设定的应用场景下服务发现效率比较低。
考虑到传统方法严重影响服务发现效率的情况,因而,计算方法并不能直接应用于apiframework服务发现中,必须根据其所属领域对其相似度计算方法进行改进。
技术实现要素:
本发明的目的在于解决apiframework系统中服务发现问题,提供一种基于语义相似度的apiframework服务发现方法,该方法在构建基于计算机领域知识网络的基础上,通过计算服务之间各个属性的相似度,从而对服务之间的总体相似度进行准确的分析,根据分析的结果做出决策,可以有效的解决由于语义相似度计算准确性不够而引起无法准确发现服务的情况。
为了达到上述目的,本发明采用了以下技术方案:
一种基于语义相似度apiframework服务发现方法,包括以下步骤:
1)基于apiframework中服务收集模块不断收集服务信息,如果没有获得服务信息则继续服务收集工作,否则将服务信息描述为wsdl标准化文档形式;同时抽取对应的信息内容构造服务属性信息;
2)将语义词典内所有的术语和概念都以同义词集合的形式表示,将同义词集进行组织,得到知识网络;
3)对步骤2)的知识网络,使用word2vec模型训练分好词的语料,得到训练好的词向量文件,基于训练好的的词向量文件和步骤1)得到的服务属性信息,得到两个概念或者两个句子直接的语义相似度;
4)针对属性相似度,分别求解服务之间的相似度,最后使用线性加权的方式获得服务相似度;
5)针对步骤4)得到的服务相似度,判别该服务是否属于新的服务类别,从而做出是否将其加入到apiframework服务集中的决策。
本发明进一步的改进在于:步骤2)中,语义词典通过以下过程构造:选择计算机领域本体的概念及概念关系来源,获取概念及其属性间的关系,生成本体概念层次,并将其映射到owl语言,采用相关性分析方法对构建的本体网络结构信息进行分析,通过挖掘上下位结构发现不同类目间的关联关系以及进行本体映射研究,并且建立概念的层级,挖掘本体的语义信息,发现本体中的隐含知识,从而构造语义词典。
本发明进一步的改进在于:步骤3)中,两个概念或者两个句子直接的语义相似度sims(t1,t2)采用以下公式计算得到;
其中s1·s2表示两个句子的向量点乘;||si||表示句子si向量的长度。
本发明进一步的改进在于:步骤4)中,属性相似度通过以下过程得到:针对服务属性信息中的概念,计算概念之间的平均语义相似度;根据概念之间的平均语义相似度得到属性wsname与wsdesp的相似度;属性oprset中的oprname属性使用字符串匹配算法计算相似度,相等为1,不相等为0;根据两个概念或者两个句子直接的语义相似度、基于距离的语义相似度以及基于信息量的语义相似度,构造带权二分图模型,在该带权二分图模型上计算输入、输出之间的相似度,进而得到属性oprset中inset与outset属性相似度。
本发明进一步的改进在于:基于距离的语义相似度sim通过以下过程得到:
其中,depth(ci)表示概念ci在语义词典中is_a关系树中的深度,len(c1,c2)指的是在语义词典中两个概念(c1,c2)最短的路径长度,msc(c1,c2)表示概念c1和概念c2处于语义词典中is_a关系树中最深层的公共父节点。
本发明进一步的改进在于:基于信息量的语义相似度通过以下过程得到:
首先计算属于概念节点c中所有单词在语料库中出现的次数freq(c):
freq(c)=∑n∈words(c)count(n)(3)
其中words(c)表示概念节点c中所包含的所有单词的集合;
概念节点c在语义词典中出现的概率p(c):
其中nodemax表示在语义词典中概念节点的总数;
信息量ic(c):
ic(c)=-log(p(c))(5)
基于信息量计算语义相似度sim(c1,c2):
其中,ic(ci)表示概念节点ci的信息量,msc(c1,c2)表示概念c1和概念c2处于语义词典is_a树中最深层的公共父节点。
本发明进一步的改进在于:步骤5)的具体过程如下:
针对步骤4)得到的服务相似度,根据相似度的判定阈值,如果当前服务相似度大于判定阈值,认为该服务属于系统已有服务,不予加入apiframework服务集中;若当前服务相似度小于判定阈值,则判定其为新的服务类型,将其加入到apiframework服务集中,增加服务的覆盖范围。
本发明进一步的改进在于:判定阈值为0.8。
与现有技术相比,本发明具有以下有益效果:本发明引入基于计算机领域知识网络的语料信息,对所发现的服务与系统中服务集合中的服务进行相似度计算,可以有效的提高服务的发现能力,维护apiframework的服务集完备性。本发明考虑到基于wordnet的词汇语义相似度计算方法中隔离抽象词汇和具象词汇,以及片面依赖上下文关系的不足,提出了基于计算机领域知识网络的概念语义相似度计算方法。同时,考虑到传统中基于wordnet语义词典计算语义相似度存在准确性不够、严重依赖语料库等缺点,提出将基于word2vec的语义计算方法、基于距离的语义计算方法以及基于信息量的计算方法进行集成的方法,从而保证其在准确性方面的优势。通过改进语料词典和相似度的计算方法,可以很好的弥补传统方法中存在的不足(如服务发现效率比较低、不能适应多种应用场景等),同时针对其特定的应用场景,保证服务发现的高效性。
附图说明
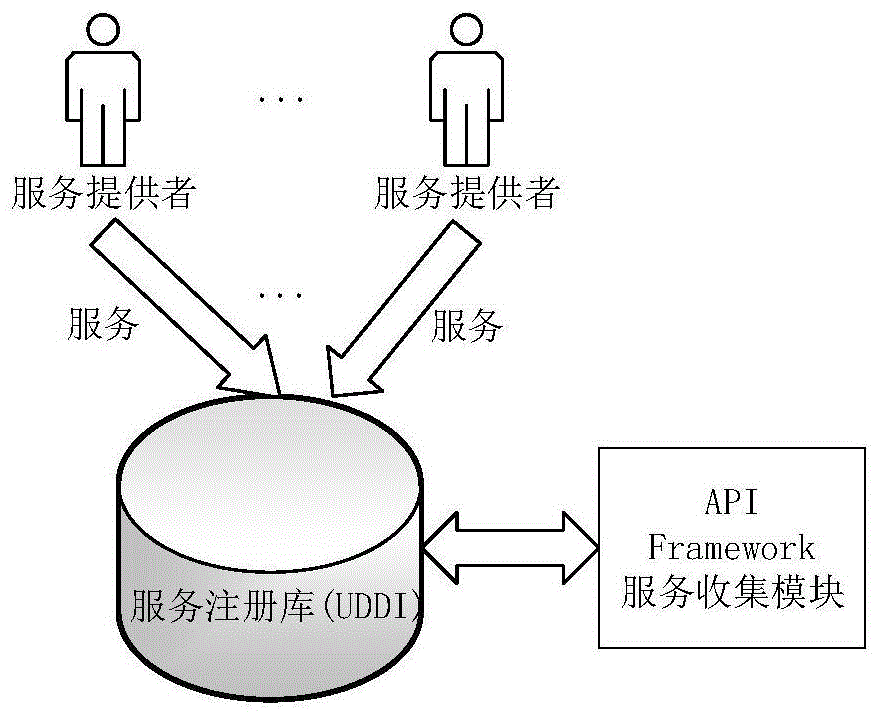
图1为基于能力开放apiframework中服务发现模块图。
图2为基于服务信息的数据预处理流程图。
图3为基于带权二分图模型计算接口相似度流程图。
图4为基于语义相似度在服务发现中决策流程图。
具体实施方式
为了使本发明的内容、效果以及优点更加清楚明白,下面结合附图和实施例对本发明进行详细描述。
本发明是应用构造基于计算机领域的语料知识,基于集成的语义相似度策略计算服务之间的相似度,通过对apiframework中服务收集模块收集的服务信息进行服务判定,在保证语义相似度的计算准确性的前提下,可以有效的避免传统语义计算方法中准确率不高、严重依赖领域词典的缺点,可以有效的提高系统中服务发现的能力,从而提高系统服务集合的服务覆盖能力。参见图1,图1中展示了基于能力开放apiframework中服务发现模块,本发明中服务来源于apiframework中服务发现模块,通过对于发现的服务与系统服务集合中服务之间的相似度进行计算,判别该服务是否作为新的服务类型加入到服务集合,在避免大量人工参与的情况下,保证提高服务的支持能力,致力于为用户提供高效的服务体验。
本发明的具体过程如下:
(一)服务相关定义
定义1:网络能力开放服务是一种可以通过网络通信的应用程序,通过标准的网络协议提供服务,目的保证不同平台的应用服务可以互操作,通常表现为一个向外界暴露出能够通过internet进行调用的api。
定义2:wsdl是能力开放服务的描述语言,以一种基于xml语言描述服务的文件形式,描述了调用服务所需要的详细信息,它描述说明三个基本属性:
服务做些什么:服务所提供的操作方法
如何访问服务:数据格式详情以及访问服务操作的必要协议
服务位于何处:有特定的协议决定的网络地址
能力开放服务的描述信息是服务相似度计算的基础,服务的语义描述可以抽象定义为如下:
定义3:能力开放服务:能力开放服务的描述表示为一个五元组ws={wsid,wsname,wsdesp,oprset,wsaddr},其中:
(1)wsid是服务的编号,每个服务在服务集合中的唯一标识符;
(2)wsname是服务的名称信息;
(3)wsdesp是服务功能的详细文本描述;
(4)oprset是服务操作集合,oprset={opr1,opr2,..oprn},其中opri表示一个服务操作;
(5)wsaddr是服务请求访问的地址;
每个服务操作对应一组服务操作方法、使用该方法的服务的输入接口信息以及调用该方法获得的输出接口信息,结合参数之间的关联关系,服务操作定义如下:
定义4:服务操作:服务操作表示为一个三元组opr={oprname,inset,outset},其中:
(1)oprname是服务操作的名称;
(2)inset={inp1,inp2,...inpn}是输入接口信息集合,其中inpi为第i个输入接口信息,i取值为1~n;
(3)outset={outp1,outp2,...outpn}是输出接口信息集合,其中outpi为第i个输出接口信息,i取值为1~n;
(二)基于能力开放apiframework服务发现
参照r15能力开放标准规范,设计基于restful的网络能力开放apiframework,其提供了各种模块来应用api,其中包括api发现、api注册、api授权、api安全等模块,本发明基于语义相似度来完成服务的发现功能,从网络中获得5g相关服务的过程主要包括以下步骤:
1)服务提供商开发出新的服务,将服务注册请求提交到uddi(universaldescription,discoveryandintegration,即通用描述、发现与集成服务),uddi对webservice(服务注册请求)进行审核,当审核通过时,同意将新服务注册到uddi服务目录中;
2)apiframework中提供的服务收集模块定期从uddi服务目录中搜索服务,服务收集模块维护一个服务标记文件,标记每一个服务是否被访问过,当服务收集模块从uddi中收集服务且该服务没有被访问过时,获取关于该服务的所有描述信息;
3)服务收集模块将获取的描述信息转化为标准的wsdl服务描述文件,应用本发明所设计的apiframework服务发现方法,进而维护服务之间的关系。
(三)数据预处理与语义词典构造
1)数据预处理
wsdl是一个描述服务信息的xml文档,包含7个重要元素,分别types,import,message,porttype,operation,binding,service。根据wsdl文档特点,对于步骤(二)中服务发现模块发现的服务信息,构造其对应的信息内容,实现服务信息的规范化处理,同时为了完成服务的相似度计算,需要将每一个服务的详细描述文本信息转化为上文中服务定义的格式,从而支撑下文中的相似度计算。
参见图2,根据自然语言处理的主要流程,对wsdl格式服务文件进行信息提取,得到web信息,然后进行分词,加载停用词表,去停用词、去标点后大写还原,词干化,在进行词性标注,最后输出标准化服务信息。服务信息的数据预处理主要分为以下步骤:
1.1)分词:基于宾夕法尼亚大学计算机和信息科学使用python语言实现的自然语言工具包nltk,对于一个服务中各个属性的描述信息,调用其分词的方法实现分词的效果;
1.2)去停用词:加载维基百科提供的停用词表,实现对于停用词的过滤作用。
1.3)词干化:对于词干化处理,同样适用nltk工具包中提供的词干化功能实现。
1.4)词性标注:使用nltk中的词性标注模块进行处理,给出每个词不同的词性。
2)语义词典构造
针对传统基于wordnet的词语语义相似度计算方法中隔离抽象词汇和具象词汇以及片面依赖上下文关系的缺点,针对本发明研究的apiframework中服务发现的背景,提出基于计算机领域知识网络的词汇语义相似度计算方法。同时基于上下文、工具-工具对象、部件-整体等概念关系准则构建计算机词汇的知识网络,提出集成多种语义相似度的计算方法来弥补单个方法中存在的不足,得到更高的语义一致性结果,提高服务发现的能力。
本发明选择计算机领域本体的概念及概念关系来源,获取概念及其属性间的关系,生成本体概念层次,并将其映射到owl语言,采用相关性分析方法对构建的本体网络结构信息进行分析,可以通过挖掘上下位结构发现不同类目间的关联关系以及进行本体映射研究,并且可以利用这种形式框架辅助建立概念的层级,以期充分挖掘本体的语义信息,发现本体中的隐含知识,从而构造语义词典。
(四)基于word2vec计算语义相似度
word2vec模型是一款将词汇向量化的高效工具,其思想是经过训练将每个词汇映射成k维实数向量(k为模型中的超参数),通过计算词汇之间的距离(如欧式距离等)来判断它们的相似程度。word2vec中包含两个模型分别为cbow模型和skip-gram模型,其中cbow为连续词袋模型,即利用词汇的上下文来预测该词汇,而skip-gram将当前中心词作为输入,预测上下文信息。
基于下载的计算机领域的语料,对语料进行基本的预处理操作,word2vec模型在给定的语料库上训练cbow和skip-gram两种模型,应用服务定义得到服务的概念描述信息,在已经训练好的word2vec模型上计算得到所有概念在语料库上的词向量表示。
针对所有概念在语料库上的词向量表示,使用余弦距离计算两个概念或者两个句子直接的语义相似度,依照公式(1)计算语义相似度。
其中s1·s2表示两个句子的向量点乘;||si||表示句子si向量的长度;
(五)基于距离计算语义相似度
对于定义3中的能力开放服务属性描述信息,采用步骤(三)中的数据预处理方法进行处理,获得需要判断服务的属性概念信息。通过路径距离的语义相似度算法以语义词典中的“is_a”关系分类树为基础,通过两个概念在关系树中的最短路径来表示它们之间的语义相似度,该类方法认为距离越近的概念间语义相似度越高。
为了充分利用概念的语义中的各种信息,在考虑两个概念在关系树中的路径长度时,也考虑最小父节点在关系树中的深度。当两个节点长度相同时,它们的父节点越深,则相似度越大,而父节点相同的节点,长度越大,相似度越低。依据公式(2)计算基于距离的语义相似度sim。
其中,depth(ci)表示概念ci在语义词典中“is_a”关系树中的深度。len(c1,c2)指的是在语义词典中两个概念(c1,c2)最短的路径长度,msc(c1,c2)表示概念c1和概念c2处于语义词典中“is_a”关系树中最深层的公共父节点。
(六)基于信息量计算语义相似度
对于定义3中的能力开放服务属性描述信息,采用步骤(三)中的数据预处理方法进行处理。在语义词典的树形结构中,每个概念节点的子节点都是对其祖先节点所表达概念的一次细分和具体化,因此,可以通过被比较概念节点对其祖先节点所包含的信息量来衡量它们直接的相似度,所以在比较概念节点的相似度之前,需要计算语义词典中各个节点的信息量。
首先计算属于概念节点c中所有单词在语料库中出现的次数,次数freq(c)统计公式如式(3)所示。
freq(c)=∑n∈words(c)count(n)(3)
其中words(c)表示概念节点c中所包含的所有单词的集合;
概念节点c在语义词典中出现的概率,概率p(c)计算如式(4)所示。
其中nodemax表示在语义词典中概念节点的总数;
信息量(ic)的计算如公式(5)所示。
ic(c)=-log(p(c))(5)
任意一对概念的相似度和它们的共性相关,共性越大,相似度越高。基于信息理论的定义和信息量,给出基于信息量计算语义相似度的计算如公式(6)所示。
其中,ic(ci)表示概念节点ci的信息量,msc(c1,c2)表示概念c1和概念c2处于语义词典“is_a”树中最深层的公共父节点。
(七)基于带权二分图模型计算接口相似度
计算出概念之间的语义相似度后,就可以构建不同服务输入接口间带权二分图和输出接口间带权二分图,概念节点间的语义相似度作为权重。这样,服务间的功能性语义信息的匹配,即服务的输入和输出接口的匹配转化为计算带权二分图中的相似程度(图3给出基于带权二分图模型计算接口相似度流程图)。参见图3,基于带权二分图模型计算接口相似度的具体过程如下:
1)功能性信息语义相似度
语义服务的功能是通过输入和输出属性体现的,接口相似度定义为:
sim(wsi,wsj)=α·simin(wsi,wsj)+β·simout(wsi,wsj)
其中,simin(wsi,wsj)和simout(wsi,wsj)分别是服务wsi和wsj的输入相似度和输出相似度,α和β是调整因子,且α+β=1;
2)输入相似度
根据定义4可知,服务的输入是由若干个本体概念组成的,可将每个本体概念刻画成一个输入参数,那么就可以通过一组参数来表示服务的输入。计算2个服务之间的输入相似度就是对这2组参数进行匹配。为了解决这类参数的匹配问题,可以把2组输入参数建模成一个二分图g=(inputi,inputj,e),其中inputi和inputj是服务wsi和wsj的输入本体概念集合;边集e的构造规则如下:对于
其中emin是输入最优匹配min的边集;e是min中的某一边;we是该边的权重;
3)输出相似度
与输入相似度类似,输出相似度计算如公式(8)所示。
其中,emout是输出最优匹配mout的边集,e是mout中的某一边;we是该边的权重。
(八)计算服务之间的相似度
参见图4,服务之间的相似度计算流程(图4给出基于语义相似度在服务发现中决策流程图)如下:
1)基于apiframework中服务收集模块不断收集服务信息,如果没有获得服务信息则继续服务收集工作,否则进行服务信息描述相关步骤,即将其服务信息描述为wsdl标准化文档形式;同时根据服务的定义3的能力开放服务和定义4的服务操作,抽取对应的信息内容构造服务属性信息;
2)利用步骤(三)构造的语义词典进行知识网络的构建,即将语义词典内所有的术语和概念都以同义词集合的形式表示,针对每一个同义词集都有一个简单的定义描述以及该同义词集存在的语义关系记录;将同义词集按照上下位、整体、部分、同义、反义、因果等关系组织起来,得到知识网络,为每一个术语提供严格的语义层次结构;
3)针对服务中描述的属性信息分别进行一系列的预处理操作,包括分词、去停用词、词干化、词性标注等基本数据处理逻辑,从而得到针对每个属性的一组描述信息;即采用步骤(三)中的数据预处理过程进行处理。
4)对步骤2)构建的知识网络,使用word2vec模型训练分好词的语料,得到训练好的词向量文件,基于训练好的的词向量文件和步骤1)得到的服务属性信息,根据步骤(四)中的方法,得到两个概念或者两个句子直接的语义相似度;
5)基于步骤2)中构造的语义词典,应用步骤(五)中的方法,得到基于距离的语义相似度;
6)基于步骤2)中构造的语义词典,应用步骤(六)中的方法,得到基于信息量的语义相似度;
7)根据定义3中的服务属性之间的特征,分别制定不同的策略来计算对应的相似度,其中属性wsname,wsdesp由简单的描述信息构成,针对服务属性中的概念,计算概念之间的平均语义相似度;根据概念之间的平均语义相似度得到属性wsname,wsdesp的相似度;由于restful风格服务中的方法主要为get、put、post、delete四种方法,所以属性oprset中的oprname属性使用字符串匹配算法计算相似度,相等为1,不相等为0;根据步骤4),步骤5)以及步骤6)中求解概念相似度的方法,构造带权二分图模型,在该带权二分图模型上计算输入、输出之间的相似度,进而得到属性oprset中inset,outset属性相似度;针对步骤3)的属性描述信息,应用步骤4),步骤5)以及步骤6)提供的三种不同求解概念相似度的方法,从而得到每个属性的不同相似度;
8)针对步骤7)中得到的每个属性的不同相似度,分别求解服务之间的相似度,最后使用线性加权的方式获得服务相似度。
(九)决策
针对步骤(八)得到的服务相似度,判别该服务是否属于新的服务类别,从而做出是否将其加入到apiframework服务集中的决策。主要判别步骤如下:
对于计算得到的服务相似度,根据相似度的判定阈值(在本发明设定判定阈值为0.8),如果当前服务相似度大于判定阈值,认为该服务属于系统已有服务,不予加入apiframework服务集中;若当前服务相似度小于判定阈值,则判定其为新的服务类型,将其加入到apiframework服务集中,增加服务的覆盖范围。
本发明设计了一种基于语义相似度的网络服务发现机制,以提升服务发现的有效性和实时性。本发明在apiframework的服务发现问题上,应用自然语言处理的基础手段,对获取的服务详细信息解析以获得服务信息的标准化描述,应用基本的语言处理逻辑,加强语义相似度计算的容错性;同时本发明通过引入基于计算机领域的知识网络,发现传统语义计算方法存在的问题,提出基于word2vec的语义计算方法、基于距离的语义计算方法以及基于信息量的语义计算方法的集成,使得基于语义计算两个服务之间的相似度拥有很高的准确率,提升了服务发现的效率。
本发明通过引入语义相似度计算模型,对apiframework服务信息进行发现,可以准确的判别服务与现有apiframework服务集的关系,从而有效扩展服务集,提高系统的服务能力。通过构造基于计算机领域的语义词典,可以准确的描述概念的语义,避免由于词典语义信息不足而导致概念相似度无法衡量的问题;通过基于word2vec的概念计算方法、基于距离的概念计算方法以及基于信息量的概念计算方法的集成,保证在充分应用语义信息的同时,有效提高服务之间相似度计算的准确性,避免由于单一方法引起的语义信息描述不准确的问题。本发明通过引入计算机领域的语义词典,通过多种语义相似度计算方法的集成,可以有效的辅助服务信息的发现,增强系统的服务范围。
- 还没有人留言评论。精彩留言会获得点赞!