一种结合用户评论与评分信息的推荐算法的制作方法
本发明涉及推荐算法领域,具体为一种结合用户评论与评分信息的推荐算法。
背景技术:
推荐系统广泛的应用在各类网络平台中,它已经改变了用户在网上发现和评估产品的方式。现有的推荐方法可以分为两大类:协同过滤方法和基于内容的推荐方法。协同过滤方法是基于显性评分等信息进行建模,虽然可以获得较理想的推荐效果,但是存在评分数据的稀疏性问题。基于内容的推荐方法是通过挖掘具有相同或相似属性的商品进行推荐,这种方法产生的推荐具有推荐结果单一化的问题。关于评分建模的研究很多,然而评分数据所具有的稀疏性、推荐的冷启动和用户喜好的转移始终是个问题,不能很好的得以解决。与此同时,评论网站上的另一种反馈方式,即评论本身,往往被忽略。因此,近年来研究者通过尝试挖掘用户的关系、用户的评论和商品的标签等信息来进一步提高推荐方法的质量。虽然也很多研究工作都是在研究评分和用户评论文本,但是他们都是将这两点孤立地研究,很少有研究试图将这两种信息来源相结合进行推荐算法研究。
技术实现要素:
本发明的目的是针对现有技术的缺陷,提供一种结合用户评论与评分信息的推荐算法,以解决上述背景技术提出的问题。
为实现上述目的,本发明提供如下技术方案:一种结合用户评论与评分信息的推荐算法,包括以下步骤:
步骤(1):构建用于发现用户评论文本中潜在主题维度的概率生成模型,计算公式如下:
式中,nd表示文件d的字数;
式中,θi表示针对项目i的k维主题分布;
式中,zu,i,j表示用户u关于项目i的第j个词的主题;
式中,wu,i,j表示用户u对项目i评论的第j个词;
步骤(2):构建基于用户评分矩阵分解模型与主题发现模型相结合的推荐函数,其计算公式如下:
式中,θ表示评分,即基于评分矩阵分解模型的参数;
式中,φ={θ,φ}表示主题参数,即基于评论lda主题发现模型的参数集合;
式中,k表示控制转换函数的权重;
式中,z是语料库t中每个单词的主题参数;
式中,rec(u,i)为用户u对项目i的预测评分;
式中,ru,i表示用户u对i的评级;
式中,λ是一个超参数,用于控制这两部分的权重;
式中,logl(t|θ,φ,z)表示用户评论集lda对数似然函数;
步骤(3):通过对目标函数的迭代计算实现基于用户评论文本和评分数据的产品推荐预测,其最小化目标函数为:
作为本发明的一种优选技术方案,所述步骤(1)构建的用于发现用户评论文本中潜在主题维度的概率生成模型具体实施流程为:
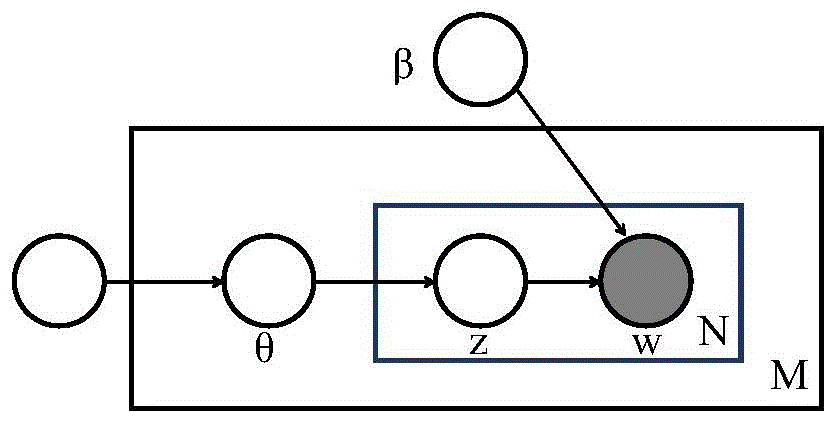
步骤(1a):将每一篇文档可看作是由n个单词组成的序列,m为文档集包中含篇文档的数目,z表示单词的主题分布,α和β分别是文本中主题的分布θ和词分布φ的超参数,服从先验狄利克雷分布;
步骤(1b):将每个文档d∈d与一个具有k维主题分布的主题θd相关联,即文档d中讨论主题k的文字部分,文本d中的文字以θd,k的概率在讨论主题k;
步骤(1c):假设主题分布θd自身服从dirichlet分布,最后的模型包括了每个主题的词分布φk,每个文档的主题分布θd,以及每一个单词zd,j的主题分配;
步骤(1d):参数φ={θ,φ}和主题分布z通过抽样被更新;
步骤(1e):给定词分布φk和每个单词的主题分布后,可以构成属于特定文本语料库,其计算公式如下:
式中,nd表示文件d的字数。
作为本发明的一种优选技术方案,所述步骤(2)构建的基于用户评分矩阵分解模型与主题发现模型相结合的推荐函数具体实施流程为:
步骤(2a):对本模型中的“文档”进行定义,定义方法如下:
从评论文本中导出文档,是将特定项目i的所有评论集合定义为文档di;
步骤(2b):将学习评分参数γi和用户评论参数θi两者联系起来,在此隐含地假设评分矩阵分解的潜在因子的数目k和评论文本的潜在主题数目k相同,且潜在因子具有相同的权重,构建潜在因子和潜在主题间的转换关系如下:
式中,θi,k表示项目i在潜在特征k上的主题,此处使用了指数形式确保了数θi,k都为正值,并且满足∑kθi,k=1,γi,k表示项目i的潜在因子向量在特征k上的值,引入参数k来控制变换的“峰值”,换言之,k表示控制转换的权重,当κ→∞时,θi将接近单位向量,该单位向量仅对于γi的最大指数取值1;当κ→0时,θi接近均匀分布,直观地,大κ表示用户只讨论最重要的主题,而小κ则表示用户均匀地讨论所有主题;
步骤(2c):定义基于用户评分和用户评论的语料库目标函数t:
式中,θ和φ={θ,φ}分别表示评分和主题参数,即基于评分矩阵分解模型的参数和基于评论lda主题发现模型的参数集合,k表示控制转换函数的权重,z是语料库t中每个单词的主题参数,logl(t|θ,φ,z)表示用户评论集lda对数似然函数,此等式的第一部分是预测评级分的误差,第二部分是评论文本主题模型的对数似然函数,λ是一个超参数,用于控制这两部分的权重,rec(u,i)为用户u对项目i的预测评分,可以通过下式获得:
rec(u,i)=α+βu+βi+γu·γi
其中,α表示全局偏置,即全部评分数据的平均值,反映不同数据集对用户评分的影响,βu和βi分别是用户和项目偏置,两个偏置反映不同用户和不同项目对评分的影响,γu和γi分别表示用户u和项目i的k维潜在主题向量,γi可以直观地被认为是产品i的“属性”,而γu是用户对这些属性的“偏好”,同时,给定一个评分为t的训练语料库,参数θ={α,βu,βi,γu,γi}的选择通常是最小化均方误差(mse),即:
其中,ω(θ)是惩罚“复杂”模型的正则化器。
作为本发明的一种优选技术方案,所述步骤(3)通过对目标函数的迭代计算实现基于用户评论文本和评分数据的产品推荐预测的具体实施流程为:
步骤(3a):将步骤(1e)中的公式代入步骤(2c)中的公式,构建最小化目标函数,其计算公式如下:
步骤(3b):固定词的主题zd,j后,可采用梯度下降法对参数tmf模型矩阵分解参数集合参数θ和主题发现参数集合φ、和潜在维度/主题的数量k进行求解,其计算公式如下:
其中,对以上公式求解目标函数的推导过程,计算公式如下:
式中,nd,k表示文档d中出现主题k的次数;
步骤(3c):通过步骤(3b)以及吉布斯采样方法不断迭代直到到输出的参数不再变化或者达到一定的阈值,算法达到收敛,其中,吉布斯采样算法计算公式如下:
本发明的有益效果:本发明的算法充分考虑了用户的评论信息,利用评论文本中的潜在主题分布,将用户评分数据与用户评论文本相结合,有效解决了推荐系统中的冷启动问题;同时比单独考虑两种数据来源的方法更能准确地进行评分预测,特别适用于对新产品和新用户的评分预测,因为这些新用户可能拥有的历史评分数据太少,以至于无法对其潜在因素进行建模。
附图说明:
图1是本发明概率生产模型lda的图形表示;
图2是本发明各种正则化参数λ值对均方误差mse值的影响对比图;
图3是本发明算法与各种传统推荐算法在mse指标值上的对比图;
图4是本发明算法与各种传统推荐算法在acc指标值上的对比图。
具体实施方式:
下面结合附图对本发明的较佳实施例进行详细阐述,以使本发明的优点和特征能更易被本领域人员理解,从而对本发明的保护范围做出更为清楚明确的界定。
本发明提供一种技术方案:一种结合用户评论与评分信息的推荐算法:
包括以下步骤:
步骤(1):构建用于发现用户评论文本中潜在主题维度的概率生成模型,计算公式如下:
式中,nd表示文件d的字数;
式中,θi表示针对项目i的k维主题分布;
式中,zu,i,j表示用户u关于项目i的第j个词的主题;
式中,wu,i,j表示用户u对项目i评论的第j个词;
步骤(2):构建基于用户评分矩阵分解模型与主题发现模型相结合的推荐函数,其计算公式如下:
式中,θ表示评分,即基于评分矩阵分解模型的参数;
式中,φ={θ,φ}表示主题参数,即基于评论lda主题发现模型的参数集合;
式中,k表示控制转换函数的权重;
式中,z是语料库t中每个单词的主题参数;
式中,rec(u,i)为用户u对项目i的预测评分;
式中,ru,i表示用户u对i的评级;
式中,λ是一个超参数,用于控制这两部分的权重;
式中,logl(t|θ,φ,z)表示用户评论集lda对数似然函数;
步骤(3):通过对目标函数的迭代计算实现基于用户评论文本和评分数据的产品推荐预测,其最小化目标函数为:
步骤(1)构建的用于发现用户评论文本中潜在主题维度的概率生成模型具体实施流程为:
步骤(1a):将每一篇文档可看作是由n个单词组成的序列,m为文档集包中含篇文档的数目,z表示单词的主题分布,α和β分别是文本中主题的分布θ和词分布φ的超参数,服从先验狄利克雷分布;
步骤(1b):将每个文档d∈d与一个具有k维主题分布的主题θd相关联,即文档d中讨论主题k的文字部分,文本d中的文字以θd,k的概率在讨论主题k;
步骤(1c):假设主题分布θd自身服从dirichlet分布,最后的模型包括了每个主题的词分布φk,每个文档的主题分布θd,以及每一个单词zd,j的主题分配,
步骤(1d):参数φ={θ,φ}和主题分布z通过抽样被更新;
步骤(1e):给定词分布φk和每个单词的主题分布后,可以构成属于特定文本语料库,其计算公式如下:
式中,nd表示文件d的字数。
步骤(2)构建的基于用户评分矩阵分解模型与主题发现模型相结合的推荐函数具体实施流程为:
步骤(2a):对本模型中的“文档”进行定义,定义方法如下:
从评论文本中导出文档,是将特定项目i的所有评论集合定义为文档di;
步骤(2b):将学习评分参数γi和用户评论参数θi两者联系起来,在此隐含地假设评分矩阵分解的潜在因子的数目k和评论文本的潜在主题数目k相同,且潜在因子具有相同的权重,构建潜在因子和潜在主题间的转换关系如下:
式中,θi,k表示项目i在潜在特征k上的主题,此处使用了指数形式确保了数θi,k都为正值,并且满足∑kθi,k=1,γi,k表示项目i的潜在因子向量在特征k上的值,引入参数k来控制变换的“峰值”,换言之,k表示控制转换的权重,当κ→∞时,θi将接近单位向量,该单位向量仅对于γi的最大指数取值1;当κ→0时,θi接近均匀分布,直观地,大κ表示用户只讨论最重要的主题,而小κ则表示用户均匀地讨论所有主题;
步骤(2c):定义基于用户评分和用户评论的语料库目标函数t:
式中,θ和φ={θ,φ}分别表示评分和主题参数,即基于评分矩阵分解模型的参数和基于评论lda主题发现模型的参数集合,k表示控制转换函数的权重,z是语料库t中每个单词的主题参数,logl(t|θ,φ,z)表示用户评论集lda对数似然函数,此等式的第一部分是预测评级分的误差,第二部分是评论文本主题模型的对数似然函数,λ是一个超参数,用于控制这两部分的权重,rec(u,i)为用户u对项目i的预测评分,可以通过下式获得:
rec(u,i)=α+βu+βi+γu·γi
其中,α表示全局偏置,即全部评分数据的平均值,反映不同数据集对用户评分的影响,βu和βi分别是用户和项目偏置,两个偏置反映不同用户和不同项目对评分的影响,γu和γi分别表示用户u和项目i的k维潜在主题向量,γi可以直观地被认为是产品i的“属性”,而γu是用户对这些属性的“偏好”,同时,给定一个评分为t的训练语料库,参数θ={α,βu,βi,γu,γi}的选择通常是最小化均方误差(mse),即:
其中,ω(θ)是惩罚“复杂”模型的正则化器。
步骤(3)通过对目标函数的迭代计算实现基于用户评论文本和评分数据的产品推荐预测的具体实施流程为:
步骤(3a):将步骤(1e)中的公式代入步骤(2c)中的公式,构建最小化目标函数,其计算公式如下:
步骤(3b):固定词的主题zd,j后,可采用梯度下降法对参数tmf模型矩阵分解参数集合参数θ和主题发现参数集合φ、和潜在维度/主题的数量k进行求解,其计算公式如下:
其中,对以上公式求解目标函数的推导过程,计算公式如下:
式中,nd,k表示文档d中出现主题k的次数;
步骤(3c):通过步骤(3b)以及吉布斯采样方法不断迭代直到到输出的参数不再变化或者达到一定的阈值,算法达到收敛,其中,吉布斯采样算法计算公式如下:
为了验证本发明包含优化算法性能,选取目前产品推荐的传统方法offset、lfm(latentfactormodel)、svd++模型、slopeone对比试验。
offset方法:该方法是一种基于全局偏置的协同过滤模型,在模型构建中使用了商品的平均作为该商品的预测值,即将某商品所有打分的平均分作为用户对该商品的预测评分。
lfm(latentfactormodel),隐语义模型:该方法通过矩阵分解(svd)对未知商品进行预测评分。此模型仅考虑了用户的评分信息,并没有考虑到用户的评论文本信息。
svd++模型:该模型是在svd模型中添加邻域商品的信息,从而得到了svd++模型,将用户历史评论商品所具有的潜在因子的累加结果作为领域商品信息。
slopeone:该方法是目前应用较为广泛的基于商品的协同过滤方法,算法运行高效简洁,并可以通过开源工具获得。
为了量化性能,本发明使用评价推荐系统常用的均方误差mse作为评估指标,其定义公式如下:
其中m表示预测评分的总数量,
除了使用均方误差mse为评估指标以外,本实验还引入准确度(accuracy)作为衡量评论预测准确度的第二个指标,acc定义如下:
其中m表示系统预测评分与用户实际评分一致的发生次数。
在实验中我们对lda模型中超参数α和β的取值采用了经验值,即α=0.2和β=0.1。
本发明所用数据集的统计信息(表1)选择在各种公共资源收集用户评论数据。数据的主要来源是亚马逊,获得约3500万条用户评论。为了获得这些数据,首先列出了7500万个类似asin(亚马逊自己的商品编号)的字符串,这些字符串是从互联网档案馆获得的,其中约有250万个商品至少有一个用户评论。根据每种产品的顶级类别(例如书籍,电影)将此数据集进一步划分为26个部分。此数据集是现有公共可用的亚马逊数据集的超集。总计从1000万用户和300万项目中获得了4200万条用户评论。数据集涵盖了总共51亿字的用户评论。
参数k取值验证试验(表2)显示不同数目的主题下,该推荐算法的均方误差mse和准确度acc。通过比较表1中k取不同值时mse和acc的结果,可以看到当k的取值为10时主题划分最为清晰。当k的取值不断增大时,系统性能是不断提升的。但是注意到当k值从10增大到20时,系统性能增长的幅度较小,故实验最终将k=10设置为默认的主题数目。为了使lda模型能够在评论数据上实现快速收敛,实验将迭代次数设置为100。
各种正则化参数λ值对均方误差mse值的影响试验(图2)。正则化参数λ的作用是用来控制主题偏好的正则化权重,正则化项是机器学习算法中用于避免模型与实际结果过度拟合的有效手段之一。图2的实验结果给出了参数在不同取值下系统的性能情况,由图中数据可知,当λ=0.5附近取值时,系统的mse指标趋于平稳。因此本发明实验最终将正则化参数λ的值设置为0.5。
将本发明算法与各种传统推荐算法在mse指标值上的对比(图3),由实验结果可以看出潜在因子矩阵分解有效提升了推荐系统的推荐质量,lfm比基于全局偏置的offset方法性能要好,而svd++方法的性能又优于lfm。tmf方法由于考虑了用户评分与评论信息,因此获得了最优的推荐性能。
随机选取10个产品类别后,本发明算法与各种传统推荐算法在mse指标值上的对比(表3),为了验证主题发现的有效性,实验又随机选取了amazon28个子类数据中的10个类别,包含母婴、食品、音像、美妆等一级类目。综合所有数据子集来看tmf模型在10个子类上优于传统模型,在诸如“服装”和“鞋帽”几个类别中,tmf算法比其他算法提升的最为明显。因此可以看出tmf表现最好的这些类别都是较为主观的。因为这些类别用户在评论时总会提示出这个产品的众多方面,因此使用评论文本,tmf能更好地“分离”产品的客观品质和评论者对其主观意见。
本发明算法与各种传统推荐算法在acc指标值上的对比(图4),实际评分取值是1-5的整数,当算法得到的预测评分为小数时,为计算acc需将结果就近取整。从结果来看,tmf算法表现最好。测试集分别取随机分配和时序分配两种情况。从整体来看,评分预测的性能在随机分配的情况下要优于时序分配方法。
表1
表2
表3
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!