一种基于融合认知计算的知识跟踪方法与流程
本发明属于知识跟踪领域,具体涉及一种基于融合认知计算的知识跟踪方法。
背景技术:
知识跟踪的目标是预测学习者的知识学习状态,这是学习者建模领域的核心问题,过往研究为解决这一问题主要提供了三类模型。第一类是静态知识跟踪模型,以项目反应理论(itemresponsetheory,irs)为代表,先建模学习者及知识的各项特征,再计算学习者对某知识的学习状态,其优点是模型简单清晰,缺点是模型为静态,不能反映学习者在学习过程中知识学习状态的变化。第二类是动态知识跟踪模型,以贝叶斯知识跟踪(bayesianknowledgetracing,bkt)模型为代表,先建模学习状态,再与学习者问题回答正确与否相关联。其优点是各状态语义清晰且状态的转移和映射模拟了学习过程,缺点是学习状态的二分建模未能反映真实的学习状态。第三类是基于深度学习的知识跟踪模型,以深度知识跟踪(deepknowledgetracing,dkt)为代表。其优点是在某些条件下预测效果较好,缺点是无法提供模型的语义解释。上述三类模型在各自的适用领域取得了较好的效果,为知识跟踪领域的后续研究提供了坚实的基础。
然而,知识学习的过程本质上是人类的一种复杂认知过程,这是认知心理学和认知神经科学领域的共识,而且认知领域已在知识学习认知机理方面通过大量实验总结出多种学习理论,对知识学习相关的认知要素和认知过程进行了深入的分析。但现有的知识跟踪模型研究并未与认知领域的研究成果紧密融合,现有的知识跟踪模型也没有如实地反映知识学习的认知过程,失去了取得更好知识跟踪效果的认知基础。随着对知识跟踪模型的结果的要求不断提高,传统的知识跟踪模型与已有的认知领域的研究成果之间的矛盾日益突出,如何利用认知领域的研究成果构建符合知识学习认知过程的知识跟踪模型,正在成为亟待解决的重要课题。
技术实现要素:
针对现有技术的以上缺陷或改进需求,本发明提供了一种基于融合认知计算的知识跟踪方法,通过统计的知识组件样本数据建立认知者的记忆系统m、学习系统l和表现状态o,并进行迭代计算待测知识组件的后验概率p(m,l|o),利用后验概率计算认知模型的参数值,进而利用认知模型推导出认知者对待测知识组件的认知表现数据。
为实现上述目的,按照本发明的一个方面,提供了一种基于融合认知计算的知识跟踪方法,具体步骤为:
获取统计的认知者对知识组件样本所处的各个记忆状态数据,对所述记忆状态数据进行处理,建立记忆状态之间的转移关系,即记忆系统模型m;
获取统计的认知者对知识组件样本所处的各个学习状态数据,对所述学习状态数据进行处理,建立学习状态之间的转移关系,即学习系统模型l;
获取统计的认知者对知识组件样本的认知表现数据,对所述认知表现数据进行处理,建立表现状态模型o;
对所述记忆系统模型m、学习系统模型l和表现状态模型o中的获取数据进行处理,获取待测知识组件的后验概率p(m,l|o)数据信息,对该数据信息进行迭代处理,获得预设的认知模型的参数值数据,进一步利用预设的认知模型获取并输出认知者对待测知识组件的认知表现信息。
作为本发明的进一步改进,记忆状态数据包括瞬时记忆状态s、工作记忆状态w、长时记忆状态g和遗忘状态f,记忆系统模型m可表示为:
m={m1,m2,…,mt},mi∈{s,w,g,f},1≤i≤t
其中,mi为认知者的第i个知识组件样本的记忆状态,t为知识组件样本的总个数。
作为本发明的进一步改进,瞬时记忆状态s∈{0,1},将知识组件样本处于瞬时记忆状态的概率记为:p(s=1),知识组件样本从瞬时记忆状态到遗忘状态的转移概率记为psf,知识组件样本从瞬时记忆阶段到工作记忆阶段的转移概率记为psw,则有psf+psw=p(s=1);
工作记忆状态w∈{0,1},知识组件样本处于工作记忆状态的概率记为:p(w=1);知识组件样本从工作记忆状态转移到遗忘状态的概率记为pwf;知识组件样本从工作记忆状态到工作记忆状态的被复述的概率记为pww;知识组件样本从工作记忆状态进入长时记忆状态的概率记为pwg;则有pwf+pww+pwg=p(w=1);
长时记忆状态g∈{0,1},知识组件样本处于长时记忆状态的概率记为:p(g=1);知识组件样本从长时记忆状态转移到遗忘状态的概率记为pgf;知识组件样本从长时记忆阶段提取进入工作记忆阶段的概率记为pgw;则有pgf+pgw=p(g=1);
遗忘状态f∈{0,1},所述知识组件样本处于遗忘状态的概率为p(f=1)。
作为本发明的进一步改进,学习状态数据包括知识获得状态a、知识保持状态r和知识应用状态u,学习系统模型l可以表示为:
l={l1,l2,…,lt},li∈{a,r,u},1≤i≤t
其中,li为认知者的第i个知识组件样本的学习状态,t为知识组件样本的总个数。
作为本发明的进一步改进,知识获得状态a∈{0,1},知识组件样本处于知识获得状态的概率记为:p(a=1);知识组件样本从知识获得状态进入知识保持状态和知识应用状态的概率分别记为par,pau;则有par+pau=p(a=1);
知识保持状态r∈{0,1},知识组件样本处于知识保持状态的概率记为:p(r=1);知识组件样本从知识保持状态进入知识获得状态和知识应用状态的概率分别记为pra,pru;则有pra+pru=p(r=1);
知识应用状态u∈{0,1},知识组件样本处于知识应用状态的概率记为:p(u=1);知识组件样本从知识应用状态进入知识获得状态和知识保持状态的概率分别记为pua,pur;则有pua+pur=p(u=1)。
作为本发明的进一步改进,认知表现数据包括正确状态c、错误状态e,表现状态模型o可以表示为:
{o1,o2,…,ot},oi∈{c,e},1≤i≤t
其中,oi为认知者对第i个知识组件样本的认知表现数据,t为知识组件样本的总个数。
作为本发明的进一步改进,利用变分inference算法计算待测知识组件的后验概率p(m,l|o),具体为:将变分inference算法中的变量q(z),z表示为m和l的联合概率分布,利用变分inference算法进行迭代计算后的输出值即为所求待测知识组件的后验概率p(m,l|o)。
作为本发明的进一步改进,将后验概率p(m,l|o)作为emlearning算法的输入,继而得到对应输出的最大化观测变量的对数似然函数logp(o;θ),计算得到bkt认知模型的参数θ,进而推导出认知者对待测知识组件的认知表现数据。
总体而言,通过本发明所构思的以上技术方案与现有技术相比,具有以下有益效果:
本发明的一种基于融合认知计算的知识跟踪方法,通过统计的知识组件样本数据建立认知者的记忆系统m、学习系统l和表现状态o,并进行迭代计算待测知识组件的后验概率p(m,l|o),利用后验概率计算认知模型的参数值,进而利用认知模型推导出认知者对待测知识组件的认知表现数据,通过研究知识学习的认知机理,描述知识学习的认知要素,模拟知识学习的认知过程,才能建立客观准确的知识跟踪模型,从而更好地预测学习者的知识学习状态,更好地辅助具体的教学实践。
本发明的一种基于融合认知计算的知识跟踪方法,根据当前三类主要知识跟踪模型的特点,结合认知过程中各种状态的语义解释、状态转移和映射关系的建模,表征记忆系统模型m、学习系统模型l和表现状态模型o,从而通过融合认知计算的ckt认知模型能够有效解决知识学习过程中的认知要素表示问题,有助于更加准确地建模知识学习的认知过程、形成知识跟踪模型、预测学习者的知识学习状态,促进学习者建模和个性化学习领域发展;有助于掌握知识学习的认知规律,提升知识跟踪结果在具体教学实践中的可用性,增强教与学的效果。
附图说明
图1是本发明实施例的一种基于融合认知计算的知识跟踪方法的示意图;
图2是本发明实施例的记忆系统的示意图;
图3是本发明实施例的瞬时记忆状态的示意图;
图4是本发明实施例的工作记忆状态的示意图;
图5是本发明实施例的长时记忆状态的示意图;
图6是本发明实施例的学习系统的示意图;
图7是本发明实施例的知识获得状态的示意图;
图8是本发明实施例的知识保持状态的示意图;
图9是本发明实施例的知识应用状态的示意图;
图10是本发明实施例的2004-2005年间认知者的认知状态预测结果的示意图;
图11是本发明实施例的2005-2006年间认知者的认知状态预测结果的示意图;
图12是本发明实施例的2006-2007年间认知者的认知状态预测结果的示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。下面结合具体实施方式对本发明进一步详细说明。
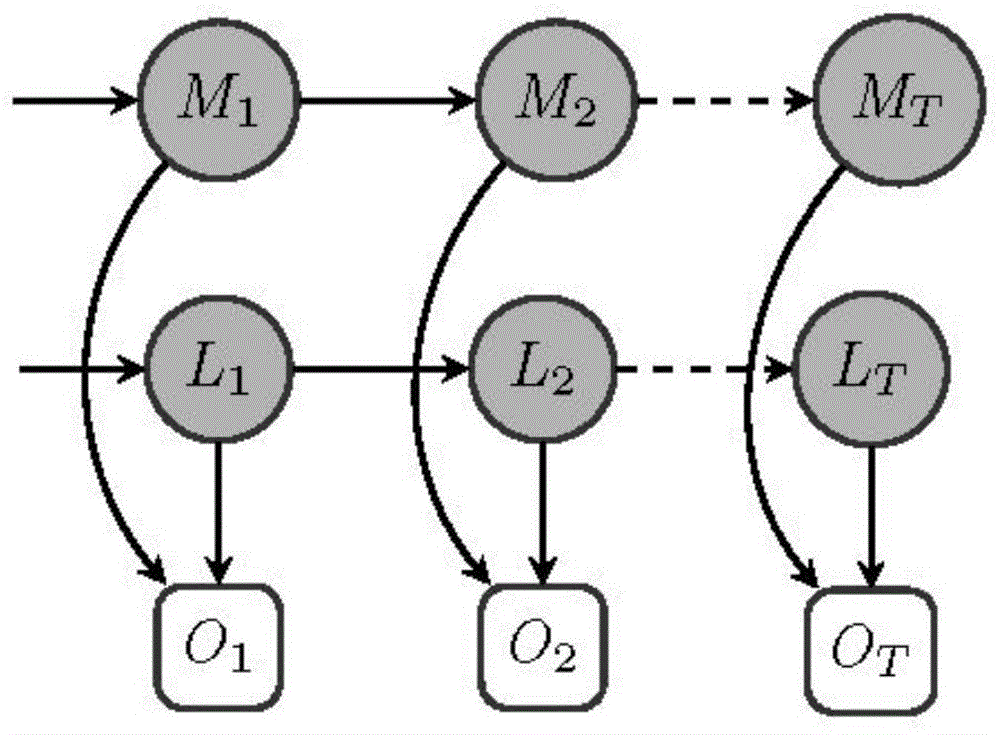
图1是本发明实施例的一种基于融合认知计算的知识跟踪方法的示意图。如图1所示,该方法包括以下步骤:
s1.获取统计的认知者对知识组件样本所处的各个记忆状态数据,对所述记忆状态数据进行处理,建立记忆状态之间的转移关系,即记忆系统模型m;
具体地,以马尔科夫链(markovchain,mc)建模记忆系统,包括知识组件所处的各个记忆状态,以及记忆状态之间的转移关系。具体地,记忆状态包括:瞬时记忆状态(s)、工作记忆状态(w)、长时记忆状态(g)和遗忘状态(f);记忆状态之间的转移关系指某一记忆状态到其他记忆状态之间的转移概率。记忆系统m是整个fhmm模型的最上层隐藏状态模型,m={m1,m2,…,mt},mi∈{s,w,g,f},1≤i≤t,其中,mi为认知者的第i个知识组件的记忆状态,t为知识组件的总个数。
图2是本发明实施例的记忆系统的示意图。如图2所示,建立记忆系统模型m的具体过程为:
根据学习者记忆系统中各记忆阶段之间相互转移的认知过程特征,基于贝叶斯理论建模各个记忆阶段内部以及各个记忆阶段之间的转移概率(transitionprobability)依赖关系,事实上,这些状态转移关系已分别在记忆系统的表示部分建模完成,将各记忆阶段的表示进行关联最终建模学习者的记忆系统。
图3是本发明实施例的瞬时记忆状态的示意图。如图3,瞬时记忆状态即为知识组件处于瞬时记忆状态与否的情况视为随机变量s∈{0,1},则将知识组件样本处于瞬时记忆状态的概率记为:p(s=1),知识组件样本从瞬时记忆状态到遗忘状态的转移概率记为psf,知识组件样本从瞬时记忆阶段到工作记忆阶段的转移概率记为psw,在瞬时记忆阶段知识组件样本或者被遗忘,或者进入工作记忆,即有psf+psw=p(s=1);
图4是本发明实施例的工作记忆状态的示意图。如图4,工作记忆状态即为知识组件处于工作记忆状态与否的情况视为随机变量w∈{0,1},知识组件处于工作记忆状态的概率记为:p(w=1);知识组件样本从工作记忆状态转移到遗忘状态的概率记为pwf,知识组件样本从记忆状态到记忆状态的被复述的概率记为pww;知识组件样本从工作记忆阶段进入长时记忆阶段的概率记为pwg;在工作记忆阶段,知识组件样本或者被遗忘,或者被复述,或者进入长时记忆阶段,即有pwf+pww+pwg=p(w=1);
图5是本发明实施例的长时记忆状态的示意图。如图5,长时记忆状态即为知识组件处于长时记忆状态与否的情况视为随机变量g∈{0,1},知识组件样本处于长时记忆状态的概率记为:p(g=1);知识组件样本从长时记忆状态转移到遗忘状态的概率记为pgf;知识组件样本从长时记忆阶段提取进入工作记忆阶段的概率记为pgw。在长时记忆阶段,知识组件样本或者被遗忘,或者被提取进入工作记忆阶段,即有pgf+pgw=p(g=1);
遗忘状态即为知识组件样本处于遗忘状态的情况视为随机变量f∈{0,1},知识组件样本处于遗忘状态的概率为p(f=1)。
s2.获取统计的认知者对知识组件样本所处的各个学习状态数据,对所述学习状态数据进行处理,建立学习状态之间的转移关系,即学习系统模型l;
具体地,以马尔科夫链建模学习系统,包括知识组件样本所处的各个学习状态,以及学习状态之间的转移关系。具体地,学习状态包括:知识获得状态(a)、知识保持状态(r)和知识应用状态(u);学习状态之间的转移关系指某一学习状态到其他学习状态之间的转移概率。学习系统mc是整个fhmm模型的最第二层隐藏状态模型,l={l1,l2,…,lt},li∈{a,r,u},1≤i≤t,其中,li为认知者的第i个知识组件样本的学习状态,t为知识组件样本的总个数。
图6是本发明实施例的学习系统的示意图。如图6所示,学习系统模型l的具体实现过程为:
当前的知识跟踪研究较少涉及知识学习状态的认知表示,绝大多数研究仅对知识组件的学习状态做出“未学会”和“已学会”的表示,尚未把认知学习理论中的知识学习阶段的成果应用起来。根据认知学习理论,知识学习分为三个阶段。第一阶段是知识的获得,即新知识从瞬时记忆进入工作记忆,与长时记忆中被激活的相关知识建立联系,从而出现新的意义的建构;第二阶段是知识的保持,即新建构的意义储存于长时记忆中;第三阶段是知识的应用,即从长时记忆中提取知识后再工作记忆中参与应用。
图7是本发明实施例的知识获得状态的示意图。如图7所示,知识获得状态为知识组件样本处于知识获得状态与否的情况视为随机变量a∈{0,1},知识组件样本处于知识获得状态的概率为p(a=1);知识组件样本从知识获得状态进入知识保持状态和知识应用状态的概率分别记为par,pau,则有par+pau=p(a=1);
图8是本发明实施例的知识保持状态的示意图。如图8所示,知识保持状态的表即为知识组件样本处于保持状态与否的情况视为随机变量r∈{0,1},知识组件样本处于知识保持状态的概率为p(r=1);知识组件样本从知识保持状态进入知识获得状态和知识应用状态的概率分别记为pra,pru,则有pra+pru=p(r=1);
图9是本发明实施例的知识应用状态的示意图。如图9所示,知识应用状态即为知识组件样本处于知识应用状态与否的情况视为随机变量u∈{0,1},则知识组件样本处于知识应用状态的概率为p(u=1);知识组件样本从知识应用状态进入知识获得状态和知识保持状态的概率分别记为pua,pur,则有pua+pur=p(u=1)。
s3.获取统计的认知者对知识组件样本的认知表现数据,对所述认知表现数据进行处理,建立表现状态模型o;
表现状态o指学习者在关于某一知识组件的题目上的表现。具体地,表现状态模型包括:正确状态(c)、错误状态(e)。表现状态之间的转移关系指某一表现状态到其他表现状态之间的转移概率。学习系统是整个fhmm模型的观测状态模型,o={o1,o2,…,ot},oi∈{c,e},1≤i≤t,oi为认知者的第i个知识组件相关习题上的表现状态,t为知识组件的总个数。
学习者在某一题目上正确的表现视为随机变量c∈{0,1},则学习者在某一题目上正确表现的概率为p(c=1)。
错误状态的表示。学习者在某一题目上错误的表现视为随机变量e∈{0,1},则学习者在某一题目上正确表现的概率为p(e=1)。
s4.对所述记忆系统模型m、学习系统模型l和表现状态模型o中的获取数据进行处理,获取待测知识组件的后验概率p(m,l|o)数据信息,对该数据信息进行迭代处理,获得预设的认知模型的参数值数据,进一步利用预设的认知模型获取并输出认知者对待测知识组件的认知表现信息。
具体地,利用变分inference算法计算认知者的记忆系统m、学习系统l和表现状态o对应的后验概率p(m,l|o),具体为:将变分inference算法中的变量q(z),z表示为m和l的联合概率分布,利用变分inference算法进行迭代计算后的输出值即为所求后验概率p(m,l|o);
由于该后验概率很难直接求解,故引入变量q(z)对p(m,l|o)进行近似,具体如下:
令利用变量z=m×l,表示m和l的联合概率分布,根据条件概率公式,有
即有
对上式左右两边取自然对数,有
在此,引入变量q(z):
对上式左右两边取关于q(z)的期望:
其中(1)式左边
inp(o)为常数。
(1)式右边分为如下两部分:
kl(q(z)||p(z|o))为相对熵指标,表征两个随机变量的相似程度,相似程度越高kl指标越低,两个相同的随机变量的kl指标为0,因此,需要q(z)和p(z|o)尽可能的相似,kl指标越低越好,l(q)越高越好,l(q)与kl指标的和为常数inp(o)。
至此,寻找p(z|o)的近似概率q(z)的问题,转化为求l(q)的最大值。对于q(z),令q(z)=q1(z(1))q2(z(2))...qn(z(n))的分布。
其中
根据kl指标的特性可知,当且仅当
上述inq1(z(1)),inq2(z(2)),…,inqn(z(n))迭代求精,最终可得q(z)=q1(z(1))q2(z(2))qn(z(n));
利用求得的q(z)就可以得到后验概率p(m,l|o),以上迭代方法为现有的变分inference算法的常用步骤,对于参数定义、初值如何获取以及具体迭代过程在此不做累述。
将后验概率p(m,l|o)作为emlearning算法的输入,继而得到对应输出的最大化观测变量的对数似然函数logp(o;θ),计算得到bkt认知模型的参数θ,进而推导出认知者对待测知识组件的认知表现数据;
一般地,使用期望最大算法(expectationmaximization,em)即emlearning算法进行ckt认知模型的参数学习,该算法包括迭代进行的e步和m步。其中,e步是先固定当前参数,然后计算出隐藏变量(m,l)的后验概率p(m,l|o);m步是以p(m,l|o)为输入,最大化观测变量的对数似然函数logp(o;θ)。
e步即为上述inference算法的内容;对应的m步的过程如下:
根据jensen不等式,要想让等式成立,需要让随机变量变成常数值,即
进一步可以得到:
learning算法的流程如下:
e步:计算
p(z(i)|o(i);θ)
m步:计算
以上迭代方法为emlearning算法的常用步骤,对于参数定义、初值如何获取以及具体迭代过程在此不做累述。
图10-12分别为本发明实施例的2004-2005、2005-2006和2006-2007年间认知者的认知状态预测结果的示意图。如图10-12所示,以wpi-assistments数据集所包括的三个子数据集即:2004-2005年间912名学生认知状态的统计数据、2005-2006年间3136名学生认知状态的统计数据和2006-2007年间5046名学生认知状态的统计数据为数据原型,涉及五个知识组件即:d-data-analysis-statistics-probability(d-kc),g-geometry(g-kc),m-measurement(m-kc),n-number-sense-operations(n-kc)和p-patterns-relations-algebra(p-kc)的认知状态,其中,实线表示本发明实施例的技术方案ckt的预测精度,虚线表示现有技术方案的预测精度,从图示中可以看到,本发明实施例的技术方案的预测精度明显优于现有技术方案的预测精度。
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!