一种出租车智能寻客方法与流程
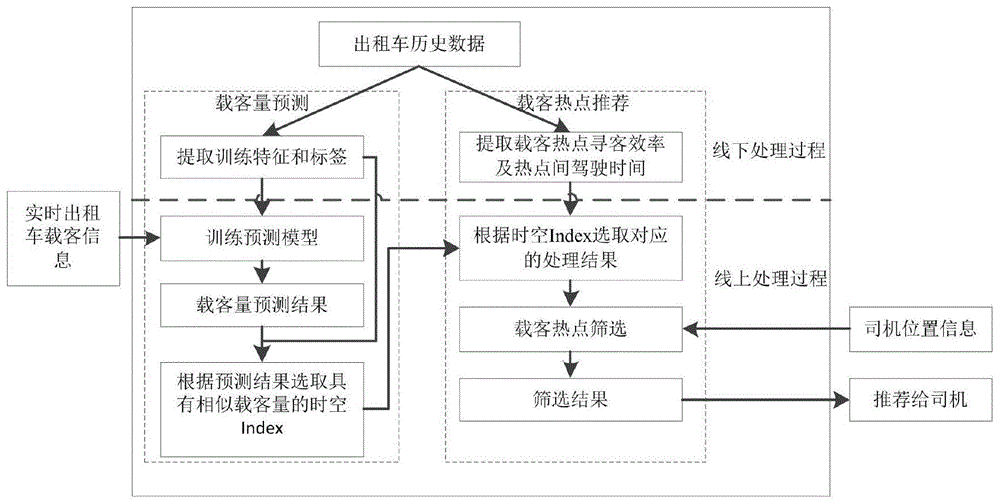
本发明结合出租车历史轨迹数据和实时的交通信息,提出了一种出租车智能寻客方法。
背景技术:
近年来,随着通信技术和计算机技术的快速发展,智能交通系统(intelligenttransportationsystem,its)受到了很多研究学者的青睐,智能出租车技术作为智能交通系统的重要组成部分,受到了研究人员的广泛关注。同时,乘客对出租车的需求也不仅仅停留在等待出租车上,更多的智能化匹配服务相继被提出,如:出租车预约服务、拼车服务、最优驾驶路线服务等,这些服务的提供都离不开对出租车历史轨迹数据的分析。由于每天都会产生大量的出租车历史轨迹数据,因此为了满足每项服务的实时性,快速的数据分析成为当务之急。虽然大数据平台是增加分析效率的重要手段,但对出租车历史轨迹数据的分析策略更为关键,很多研究人员采用线下的历史轨迹处理方式和线上的服务推荐方式满足推荐的实时性。
针对出租车与乘客智能匹配这一问题,研究的方向主要有两种,第一种是从乘客的角度为乘客推荐最佳的寻客位置,为提高乘客寻客效率,并提供出租车预期到达时间及其到达概率。第二种是从司机的角度为司机推荐最佳寻客路线,为了节约司机的寻客成本,对出租车附近的载客热点区域进行分析,分析出租车前往不同热点的预期寻客时间及其寻客概率,根据上述两种因素筛选载客热点并推荐。由于每天产生的出租车历史数据都有所不同,导致选择不同的出租车历史数据对推荐服务的准确性有很大的影响,目前在该领域采用比较多的方式是将出租车历史数据分为工作日数据和非工作日数据,然而这种分割方法并不够细致。影响人们出行的方式有很多种,比如天气、假期、时间等因素,为了合理的选取历史数据实现推荐服务,应该综合考虑这些因素,实时、动态的选取合理的历史数据,而不是单一的考虑某一种因素。
由于出租车在寻找乘客的过程中,驾驶经验丰富的司机能够有效的寻找到火车站、电影院等载客热点区域,而这些区域内的乘客数量是随着时间变化的,而不能单一的将载客热点区域推荐给司机。而载客热点内乘客数量的变化以及出租车司机不明显的寻客方案都隐藏在出租车历史轨迹数据内。因此,我们综合出租车历史轨迹数据的线下处理过程和实时交通信息线上处理过程,提出了tcsfp寻客策略。
技术实现要素:
本发明的目的是提出一种出租车智能寻客方法,以解决解决城市中出租车与乘客匹配“难”这一问题,结合出租车历史轨迹数据和实时的交通信息,提出了一种基于载客量预测的出租车寻客策略(taxicruisingstrategybasedonforecastingpassengervolume,tcsfp)。
本发明通过以下技术方案实现:一种出租车智能寻客方法,所述出租车智能寻客方法包括以下步骤:
步骤一:载客量预测:基于出租车历史轨迹数据对城市中的载客热点区域的载客量作预测,根据预测结果筛选出历史数据中与当天载客量相似的日期,将筛选出的日期生成时空index;
步骤二:构建寻客指标数据库:基于出租车历史轨迹数据建立载客热点区域的寻客效率数据库和热点间驾驶时间数据库,所述寻客效率数据库包括热点的寻客时间、载客概率和载客收入;
步骤三:载客热点筛选:根据步骤一生成的时空index从步骤二中筛选出对应日期的寻客效率数据库和热点间驾驶时间数据库,并对出租车前往不同热点的寻客效率进行均衡,筛选出最佳的热点区域,筛选原则如公式(1)所示:
其中i表示出租车当前所在区域编号,j表示第j个热点区域编号,m表示每天的第m个时间段,
进一步的,步骤一中包括以下步骤:
步骤一一:从历史数据中提取所有的乘客上车点,并对不同时间段发生的载客次数进行统计,如公式(2)所示:
其中,hi表示第i个热点区域,dj表示出租车历史数据中的第j天,l表示将一天分为l个时间段,
步骤一二:收集hotspoti在历史数据中的所有载客量数据,如公式(3)所示:
m(hi)={p(hi,d1),p(hi,d2),...,p(hi,dn)}
(3)
假设预测第i个热点第m个时间段的载客量,并使用前k个时间段的载客量作为预测特征,可以构建如公式(4)和公式(5)所示的机器学习特征和标签,
步骤一三:根据公式(4)和公式(5)所提供的特征和标签训练机器学习分类模型。并从公式(5)中寻找出与预测结果接近的载客量
进一步的,在步骤二中,具体的,对
其中
使用
将选择目标更改为寻找
进一步的,步骤三中包括以下步骤:
步骤三一:为每个热点设置权重,热点的权重为载客热点的寻客时间、寻客概率和载客收入之和:
步骤三二:将载客热点的权重按照由大到小进行排序,并将排序的结果记录为:
s(hi,m)=(weight1,weight2,...,weightl)(9)
筛选出边缘热点,并将筛选出的边缘热点推荐给出租车司机。
本发明的有益效果在于:本发明从为空驶的出租车推荐最佳寻找乘客策略的角度入手,结合出租车历史轨迹数据和线上的载客量信息,提出了一种基于载客量预测的出租车寻客策略(taxicruisingstrategybasedonforecastingpassengervolume,tcsfp),该策略分为两个阶段:载客量预测阶段和出租车载客热点筛选阶段。在载客量预测阶段能够生成时空index,动态的选取历史轨迹数据,在载客热点推荐阶段能够为出租车推荐寻客热点。同时该策略包含线上和线下两种处理过程,能够极大的缩短推荐服务的计算时间。
附图说明
图1为本发明的一种出租车智能寻客方法的方法流程图;
图2为载客热点筛选示意图。
具体实施方式
下面将结合本发明实施例中的附图对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
参照图1所示,本发明通过以下技术方案实现:一种出租车智能寻客方法,所述出租车智能寻客方法包括以下步骤:
步骤一:载客量预测:基于出租车历史轨迹数据对城市中的载客热点区域的载客量作预测,根据预测结果筛选出历史数据中与当天载客量相似的日期,将筛选出的日期生成时空index;
步骤二:构建寻客指标数据库:基于出租车历史轨迹数据建立载客热点区域的寻客效率数据库和热点间驾驶时间数据库,所述寻客效率数据库包括热点的寻客时间、载客概率和载客收入;
步骤三:载客热点筛选:根据步骤一生成的时空index从步骤二中筛选出对应日期的寻客效率数据库和热点间驾驶时间数据库,并对出租车前往不同热点的寻客效率进行均衡,筛选出最佳的热点区域,筛选原则如公式(1)所示:
其中i表示出租车当前所在区域编号,j表示第j个热点区域编号,m表示每天的第m个时间段,
具体的,步骤一中,通过对载客量的预测实现动态的从数据库中选取历史数据的处理结果;而步骤二中,通过构建数据库,提供每个热点的寻客效率和驾驶时间,加快了步骤三的推荐效率。本发明综合出租车历史轨迹数据的线下处理过程和实时交通信息线上处理过程,提出了tcsfp寻客策略,如图1所示。tcsfp寻客策略分为线上和线下两种处理过程,图1中虚线以上的处理过程为出租车历史数据线下处理过程,虚线以下的处理过程为线上推荐过程。对历史数据的处理共分为两个方面,左侧虚线框代表载客量预测阶段,右侧代表载客热点推荐阶段。出租车寻客时间、载客概率和载客收入是筛选载客热点非常关键的因素,对寻客性能的影响十分巨大,而且这些因素均是实时变化的,因此需要对这些因素的快速获取及综合评价。
参照图1所示,在本部分优选实施例中,步骤一中包括以下步骤:
步骤一一:从历史数据中提取所有的乘客上车点,并对不同时间段发生的载客次数进行统计,如公式(2)所示:
其中,hi表示第i个热点区域,dj表示出租车历史数据中的第j天,l表示将一天分为l个时间段,
步骤一二:收集hotspoti在历史数据中的所有载客量数据,如公式(3)所示:
m(hi)={p(hi,d1),p(hi,d2),...,p(hi,dn)}
(3)
假设预测第i个热点第m个时间段的载客量,并使用前k个时间段的载客量作为预测特征,可以构建如公式(4)和公式(5)所示的机器学习特征和标签,
步骤一三:根据公式(4)和公式(5)所提供的特征和标签训练机器学习分类模型。并从公式(5)中寻找出与预测结果接近的载客量
具体的,由于人们的出行受很多因素的影响,比如天气、节假日等,因此在为出租车寻找最佳寻客热点过程中,选择适当的历史数据进行分析极为关键,本发明采取的历史数据筛选方法是基于历史轨迹数据提取每天不同时间段载客量的信息,并构建预测模型,并将实时的交通信息获取的载客量数据作为预测数据,得到载客量的预测结果。从历史数据中筛选出与预测的载客量结果相似的日期,那么有理由说明该日期的乘客出行与今日相似,跟据筛选出的日期生成时空index,并输入给步骤三,作为步骤三选取历史数据的依据。
参照图1所示,在本部分优选实施例中,在步骤二中,具体的,由于出租车从起始位置hi前往载客热点hj的寻客时间、寻客概率和载客收入分别为不同类型指标,因此需要对
其中
由于寻客时间应尽可能的小,而寻客概率和载客收入应尽量的高,因此使用
如图2所示,应尽量选找出距离三条坐标轴均较远的“边缘热点”,删除距离远点较近的“内部热点”,因此删除热点h2。
具体的,由于出租车寻客方案的推荐需要满足实时性,因此对历史轨迹数据的处理应在线下完成。出租车的载客概率和载客收入可以直接对应到每个热点的载客概率和载客收入,相对容易从历史数据中提取,而出租车的寻客时间由司机前往不同热点所需时间和每个热点的平均寻客时间组成,因此本发明将热点的属性分为:热点的寻客时间、载客概率和载客收入。出租车前往热点所需的时间可从热点间的驾驶时间数据库中获取,出租车的寻客时间为出租车前往热点所需时间和热点的平均寻客时间之和。本步骤属于线下处理过程。
参照图1所示,在本部分优选实施例中,步骤三中包括以下步骤:
步骤三一:为每个热点设置权重,热点的权重为载客热点的寻客时间、寻客概率和载客收入之和:
步骤三二:将载客热点的权重按照由大到小进行排序,并将排序的结果记录为:
s(hi,m)=(weight1,weight2,...,weightl)(9)
步骤三三:对排序的结果s(hi,m)内的每一个元素判断是否为边缘热点:
1.由于weight1为最大权重,可以得出其所属热点为边缘热点。证明如下:
若热点ha具有最大权重,且ha属于“内部”热点,那么一定存在热点hb的寻客时间、寻客概率和载客收入均大于热点ha,因此热点hb的权重weight(hi,hb,k)大于ha的权重weight(hi,ha,k),这与ha具有最大权重矛盾,因此ha为边缘热点,证毕。
2.若weight2所在热点的寻客时间、寻客概率和载客收入均小于weight1所在热点,那么weight2所在热点为内部热点;反之weight2所在热点为边缘热点,证明如下:
若weight2所在热点为内部热点,那么存在热点hb的寻客时间、寻客概率和载客收入均大于weight2所在热点,因此hb的权重大于weight2。而大于weight2的权重只有weight1,这与假设矛盾,证毕。
依次类推,对s(hi,k)中的每个元素,与已选出的边缘热点进行比较,逐一判断,筛选出边缘热点,并将筛选出的边缘热点推荐给出租车司机。
具体的,从图1中可以看出出租车的寻客请求只经历一步,其他处理过程均在线下或提前完成,能够极大的缩短出租车寻客请求所花费的时间。
- 还没有人留言评论。精彩留言会获得点赞!