一种基于关联性分析和数据挖掘的台区线损计算方法与流程
本发明涉及电力线损计算技术领域,尤其涉及一种基于关联性分析和数据挖掘的台区线损计算方法。
背景技术:
电力系统的低压电网会在电力的传输过程中存在线损现象,电能从电厂发电厂运送出来,通过一定方式的传送途径传送到用电的客户。在这一过程中,由于存在很多的传输环节,例如:输电环节、变电环节、配电环节等,这些环节在一定程度上让电能出现了传输损耗,作为电网系统的规划设计或者是生产的运行管理的一个非常重要的指标。
在现有低压配网台区线损的分析测算方法中,台区线损指标数据往往便于收集且数据充足,但由于缺少有针对性的线损指标分析与灵活高效的线损计算方法,不能准确有效的挖掘台区线损影响因素的关联,无法充分拟合台区数据与线损的复杂映射关系,导致低压配网台区线损分析指标数据的实用性低,并且线损率的计算工作十分繁杂,计算耗时长的同时精确率较低。
技术实现要素:
本发明为解决现有的台区线损计算方法不能准确有效的挖掘台区线损影响因素的关联,计算工作效率以及准确率低等问题,提供了一种基于关联性分析和数据挖掘的台区线损计算方法。
为实现以上发明目的,而采用的技术手段是:
一种基于关联性分析和数据挖掘的台区线损计算方法,包括以下步骤:
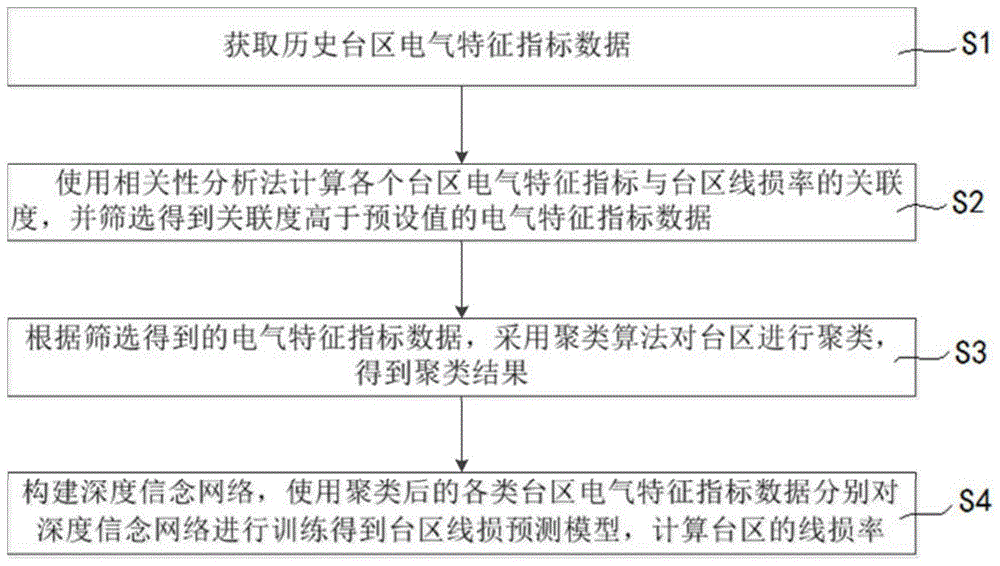
s1.获取历史台区电气特征指标数据;
s2.使用相关性分析法计算各个台区电气特征指标与台区线损率的关联度,并筛选得到关联度高于预设值的电气特征指标数据;
s3.根据筛选得到的电气特征指标数据,采用聚类算法对台区进行聚类,得到聚类结果;
s4.构建深度信念网络,使用聚类后的各类台区电气特征指标数据分别对深度信念网络进行训练得到台区线损预测模型,用于计算台区的线损率。
上述方案中,通过对比分析不同台区电气特征指标对台区线损率的影响大小,选取影响更大的特征指标数据作为深度信念网络的输入,利用聚类算法对不同类型台区进行区分来分别进行训练,以挖掘输入参数与台区线损率之间复杂的关联关系,最终生成计算迅速高效、结果准确性较高的台区线损预测模型,从而利用该模型对台区线损进行计算分析。
优选的,所述步骤s1具体为:获取历史t年共n种台区电气特征指标数据,所述电气特征指标包括台区属性、配变容量、台区供电半径、线缆类型、低压线路总长度、电力用户数、总功率因数、负载率、年平均线损率、用电性质及比例;其中t和n均为正整数。在本优选方案中,主要考虑与台区网架结构和负荷特性相关的电气特征指标。
优选的,所述步骤s1还包括:
s11.根据获取得到的历史台区电气特征指标数据,构建台区线损率的影响因素矩阵x=[xi,j],j∈[1,t],其中xi,j为第i个影响因素的第j年的数据,即第i个电气特征指标的第j年的数据;由台区年平均线损率构成影响对象序列行向量y=[yj],j∈[1,2,…,t],其中yj为第j年台区年平均线损率;
s12.对影响因素矩阵x=[xi,j],j∈[1,t]以及影响对象序列行向量y=[yj],j∈[1,2,…,t]中的各个数据进行标准化处理,表示为:xi,j=xi,j/xi,1,yj=yj/y1。在本优选方案中,由于不同序列的数值取值范围和单位都不相同,可能干扰到分析结果,为避免受量纲影响进行计算,在本优选方案中对原始数据进行标准化处理。
优选的,所述步骤s2使用的相关性分析法为灰色关联度分析法。在本优选方案中,灰色关联度分析法基于影响因素与影响对象序列曲线几何形状的相似程度来判断其关系的紧密程度,是确定因子间影响程度或因子对主行为的贡献程度而进行的一种分析方法,其尤其适合数据有限、没有原型、复杂而且具有不确定性问题的分析和评价。
优选的,所述步骤s2具体包括以下步骤:
s21.根据标准化处理后的数据,计算影响对象序列行向量中数据yj与影响因素矩阵中数据xi,j的差序矩阵δj,i,并计算差序矩阵δj,i中不同年份对应元素的最大值mj,i和最小值mj,i,其中差序矩阵δj,i中第t年的元素计算为:δj,i=|yj-xi,j|,j=t;
s22.分别计算影响对象序列行向量中数据yj与影响因素矩阵中数据xi,j的关联度矩阵λ=[λji],影响对象序列行向量中数据yj与影响因素矩阵中数据xi,j之间的综合关联度ri,得到关联度向量r;
其中关联度矩阵λ=[λji]中向量λji的计算为:
其中ρ为分辨系数,ρ∈[0,1],mj,i和mj,i分别为差序矩阵δj,i中不同年份对应元素的最大值和最小值;
其中综合关联度ri的计算为:
其中,ωj为第j年的权重,ri表示第i个影响因素与线损率的相关程度;ri越大则关联程度越大;
关联度向量r为:r=[r1r2...ri...rn],其中n指共n种影响因素;
s23.从步骤s22计算得到的关联度向量r中筛选出前m个综合关联度ri对应影响因素的电气特征指标数据,得到m维的电气特征指标数据集,其中m∈[4,5,6]。
优选的,所述步骤s3具体包括:
s31.初始化聚类中心:
计算评价指标
其中n为共有n个m维的电气特征指标数据,xjmin为第j个电气特征指标的n个电气特征指标数据中的最小值,ωj第j个电气特征指标的权重;
将所有电气特征指标数据根据计算得到的pe值进行升序排序后,等分成k类,并选取每类的中心电气特征指标数据作为该类的初始聚类中心;k值通过初始化得到;
s32.确定最优分类数k:采用综合轮廓系数st评价聚类效果,通过对比不同聚类情况下的s(i)选取最大轮廓系数所对应的最优分类数k;对于任意一个样本点i,计算方法为:
轮廓系数
综合轮廓系数
其中q(i)为样本点i到所属类中其它点的平均距离;p(i)为样本点i到非所属类中所有点平均距离的最小值,聚类结果的综合轮廓系数st是所有样本点轮廓系数s(i)的平均值;
s33.计算各个电气特征指标数据与k个初始聚类中心的距离lij,按照距离大小将所有电气特征指标数据对应分配给最近的初始聚类中心,形成k个台区聚类;
其中
lij为样本点i与第j个聚类中心的距离,xik为样本点i的第k个电气特征指标,xjk为第j个聚类中心的第k个元素;
s34.对于形成的k个台区聚类,求取每个台区聚类中所有数据的平均值,并用该平均值更新对应台区聚类的聚类中心;
s35.判断台区聚类过程是否结束,计算公式为:
其中mi为ci类的聚类中心;xq为ci类中的样本,若计算得到的e达到收敛条件,则完成台区聚类;否则返回步骤s32。
优选的,所述步骤s4构建的深度信念网络由若干个玻尔兹曼机堆叠而成,其中深度信念网络的输入层节点个数等于电气特征指标的维数m,输出层对应线损率预测值,节点个数为1;初始化深度信念网络的结构参数为2层隐层,隐层节点个数为s=2m+1,隐层激活函数为relu函数,深度信念网络的学习效率为0.01,迭代次数为1000。在本优选方案中,采用relu函数作为隐层激活函数,由于其具有非饱和性,收敛速度更快,能够提高深度信念网络的训练速度。
优选的,步骤s4中所述的使用聚类后的各类台区电气特征指标数据分别对深度信念网络进行训练得到台区线损计算模型具体包括以下步骤:
s41.样本集划分:将筛选得到的电气特征指标数据按8:2的比例划分为训练样本集和测试样本集;
s42.模型无监督逐层预训练:获取所述深度信念网络的初始结构参数,输入所述训练样本集并采用贪婪学习算法对所述深度信念网络进行前向训练,通过采用对比散度算法更新各个rbm的层间连接权值、可见层的偏置以及隐藏层的偏置;
s43.模型有监督整体精调:
采用梯度下降算法对预训练后的深度信念网络进行后向训练,通过bp算法对预训练后的深度信念网络进行自顶向下的回调;
s44.模型训练:
输入训练样本集对步骤s43得到的深度信念网络进行充分训练,得到待验证的台区线损预测模型;
s45.模型测试:将测试样本集输入待验证的台区线损预测模型,检验预测线损值与实际线损值之间的误差值是否在预设误差范围内,若是则得到台区线损预测模型,用于计算台区的线损率;若否则返回步骤s42。
优选的,步骤s42中还包括将所述训练样本集划分为若干组样本子集,分别通过各组样本子集并采用贪婪学习算法对所述深度信念网络进行前向训练;对于各组样本子集依次采用对比散度算法更新各个受限玻尔兹曼机的层间连接权值ωij,g、可见层的偏置ai,g以及隐藏层的偏置bj,g,对于包含k个样本的第g组数据集,计算公式具体为:
其中对比散度算法的采样步数为1,vi,k为第k个样本中可视层的第i个神经元的值,v′i,k为vi,k反向回代的值;hj,k为第j个样本中隐藏层的第i个神经元的值,h′j,k为hj,k的第二次迭代的计算值;εcd为对比散度算法的学习率。
在本优选方案中,由于存在训练样本数据量巨大的情况,因此采用小批量梯度下降算法,将训练样本划分为若干组小批量的样本子集依次进行训练,以提高计算效率。
与现有技术相比,本发明技术方案的有益效果是:
本发明的台区线损计算方法通过对比分析不同台区电气特征指标对台区线损率的影响大小,选取影响更大的特征指标数据作为深度信念网络的输入,利用聚类算法对不同类型台区进行区分来分别进行训练,以挖掘输入参数与台区线损率之间复杂的关联关系,最终生成计算迅速高效、结果准确性较高的台区线损预测模型,从而利用该模型对台区线损进行计算分析。本发明的台区线损计算方法可以快速对种类繁多、数量庞大的台区线损计算数据进行分析、筛选、归类,提高计算的效率及精准度。
附图说明
图1为本发明方法的总流程图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
下面结合附图和实施例对本发明的技术方案做进一步的说明。
实施例1
一种基于关联性分析和数据挖掘的台区线损计算方法,如图1所示,包括以下步骤:
s1.获取历史台区电气特征指标数据;
s2.使用相关性分析法计算各个台区电气特征指标与台区线损率的关联度,并筛选得到关联度高于预设值的电气特征指标数据;
s3.根据筛选得到的电气特征指标数据,采用聚类算法对台区进行聚类,得到聚类结果;
s4.构建深度信念网络,使用聚类后的各类台区电气特征指标数据分别对深度信念网络进行训练得到台区线损预测模型,用于计算台区的线损率。
实施例2
一种基于关联性分析和数据挖掘的台区线损计算方法,包括以下步骤:
s1.获取历史t年共n种台区电气特征指标数据,所述电气特征指标包括台区属性、配变容量、台区供电半径、线缆类型、低压线路总长度、电力用户数、总功率因数、负载率、年平均线损率、用电性质及比例;其中t和n均为正整数;
然后:
s11.根据获取得到的历史台区电气特征指标数据,构建台区线损率的影响因素矩阵x=[xi,j],j∈[1,t],其中xi,j为第i个影响因素的第j年的数据,即第i个电气特征指标的第j年的数据;由台区年平均线损率构成影响对象序列行向量y=[yj],j∈[1,2,…,t],其中yj为第j年台区年平均线损率;
s12.对影响因素矩阵x=[xi,j],j∈[1,t]以及影响对象序列行向量y=[yj],j∈[1,2,…,t]中的各个数据进行标准化处理,表示为:xi,j=xi,j/xi,1,yj=yj/y1。
s2.使用灰色关联度分析法计算各个台区电气特征指标与台区线损率的关联度,并筛选得到关联度高于预设值的电气特征指标数据;
s21.根据标准化处理后的数据,计算影响对象序列行向量中数据yj与影响因素矩阵中数据xi,j的差序矩阵δj,i,并计算差序矩阵δj,i中不同年份对应元素的最大值mj,i和最小值mj,i,其中差序矩阵δj,i中第t年的元素计算为:δj,i=|yj-xi,j|,j=t;
s22.分别计算影响对象序列行向量中数据yj与影响因素矩阵中数据xi,j的关联度矩阵λ=[λji],影响对象序列行向量中数据yj与影响因素矩阵中数据xi,j之间的综合关联度ri,得到关联度向量r;
其中关联度矩阵λ=[λji]中向量λji的计算为:
其中ρ为分辨系数,ρ∈[0,1],mj,i和mj,i分别为差序矩阵δj,i中不同年份对应元素的最大值和最小值;
其中综合关联度ri的计算为:
其中,ωj为第j年的权重,ri表示第i个影响因素与线损率的相关程度;
关联度向量r为:r=[r1r2...ri...rn],其中n指共n种影响因素;
s23.从步骤s22计算得到的关联度向量r中筛选出前m个综合关联度ri对应影响因素的电气特征指标数据,得到m维的电气特征指标数据集,其中m∈[4,5,6]。
s3.根据筛选得到的电气特征指标数据,采用聚类算法对台区进行聚类,得到聚类结果:
s31.初始化聚类中心:
计算评价指标
其中n为共有n个m维的电气特征指标数据,xjmin为第j个电气特征指标的n个电气特征指标数据中的最小值,ωj第j个电气特征指标的权重;
将所有电气特征指标数据根据计算得到的pe值进行升序排序后,等分成k类,并选取每类的中心电气特征指标数据作为该类的初始聚类中心;k值通过初始化得到;
s32.确定最优分类数k:采用综合轮廓系数st评价聚类效果,通过对比不同聚类情况下的s(i)选取最大轮廓系数所对应的最优分类数k;对于任意一个样本点i,计算方法为:
轮廓系数
综合轮廓系数
其中q(i)为样本点i到所属类中其它点的平均距离;p(i)为样本点i到非所属类中所有点平均距离的最小值,聚类结果的综合轮廓系数st是所有样本点轮廓系数s(i)的平均值;
s33.计算各个电气特征指标数据与k个初始聚类中心的距离lij,按照距离大小将所有电气特征指标数据对应分配给最近的初始聚类中心,形成k个台区聚类;
其中
lij为样本点i与第j个聚类中心的距离,xik为样本点i的第k个电气特征指标,xjk为第j个聚类中心的第k个元素;
s34.对于形成的k个台区聚类,求取每个台区聚类中所有数据的平均值,并用该平均值更新对应台区聚类的聚类中心;
s35.判断台区聚类过程是否结束,计算公式为:
其中mi为ci类的聚类中心;xq为ci类中的样本,若计算得到的e达到收敛条件,则完成台区聚类;否则返回步骤s32。
s4.构建深度信念网络,使用聚类后的各类台区电气特征指标数据分别对深度信念网络进行训练得到台区线损预测模型,用于计算台区的线损率:
其中构建的深度信念网络由若干个玻尔兹曼机堆叠而成,其中深度信念网络的输入层节点个数等于电气特征指标的维数m,输出层对应线损率预测值,节点个数为1;初始化深度信念网络的结构参数为2层隐层,隐层节点个数为s=2m+1,隐层激活函数为relu函数,深度信念网络的学习效率为0.01,迭代次数为1000;
使用聚类后的各类台区电气特征指标数据分别对深度信念网络进行训练得到台区线损计算模型具体包括以下步骤:
s41.样本集划分:将筛选得到的电气特征指标数据按8:2的比例划分为训练样本集和测试样本集;
s42.模型无监督逐层预训练:获取所述深度信念网络的初始结构参数,将所述训练样本集划分为若干组样本子集,分别通过各组样本子集并采用贪婪学习算法对所述深度信念网络进行前向训练;对于各组样本子集依次采用对比散度算法更新各个受限玻尔兹曼机的层间连接权值ωij,g、可见层的偏置ai,g以及隐藏层的偏置bj,g,对于包含k个样本的第g组数据集,计算公式具体为:
其中对比散度算法的采样步数为1,vi,k为第k个样本中可视层的第i个神经元的值,v′i,k为vi,k反向回代的值;hj,k为第j个样本中隐藏层的第i个神经元的值,h′j,k为hj,k的第二次迭代的计算值;εcd为对比散度算法的学习率。
s43.模型有监督整体精调:
采用梯度下降算法对预训练后的深度信念网络进行后向训练,通过bp算法对预训练后的深度信念网络进行自顶向下的回调;
s44.模型训练:
输入训练样本集对步骤s43得到的深度信念网络进行充分训练,得到待验证的台区线损预测模型;
s45.模型测试:将测试样本集输入待验证的台区线损预测模型,检验预测线损值与实际线损值之间的误差值是否在预设误差范围内,若是则得到台区线损预测模型,用于计算台区的线损率;若否则返回步骤s42。
附图中描述位置关系的用语仅用于示例性说明,不能理解为对本专利的限制;
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!