一种基于生成对抗网络的中文语法错误更正方法与流程
本发明涉及信息处理领域,特别涉及一种基于神经网络的中文语法错误更正方法。
背景技术:
中文语法错误更正是中文自然语言处理中的比较新的任务,目的是判断对非中文母语的人所写的语句是否包含语法错误,对包含错误的地方提出更正方案。
目前最普遍的中文语法错误更正方法有两种。一种是利用中文语法错误检测模型先检测错误,再利用n-gram字典计算词语共同出现的频率,得到更正的语句。另一种是利用序列到序列的模型建立端到端的中文语法错误更正模型。这种模型将语法错误更正任务视为一个翻译任务,将包含语法错误的句子翻译为正确的句子。但是这些网络都有一定的缺点,前者依赖于大型的词典,后者依赖于质量较高的训练数据集。最近,大量的训练数据被开发,因此也有越来越多的人运用序列到序列的模型到中文语法错误更正的任务中。但是大部分的工作仅仅是利用了语料库,没有很好的解决模型更正后的语句不太符合中文习惯的问题。而本发明为了解决上述的问题,采用了生成对抗网络,得到比较好的生成模型,得到了较好的语法错误更正效果。
技术实现要素:
为了解决现有的技术问题,本发明提供了一种基于生成对抗网络的中文语法错误更正方法。方案如下:
步骤一,我们将输入的包含语法错误的句子进行处理,使用生成网络捕获句子中的词语信息及上下文信息,生成语法错误被更正后的语句。
步骤二,我们将包含语法错误的语句及生成网络更正后的语句送入判别网络,利用损失函数,优化生成网络。
步骤三,我们将包含语法错误的语句,人工标注更正后的语句及生成网络更正后的语句送入判别网络,计算更正语句来源于人工标注或是更正网络的概率。
步骤四,利用更正语句来源于人工标注或是更正网络的概率,计算损失函数,优化判别网络。
步骤五,返回步骤一,不断优化生成网络及更正网络。
附图说明
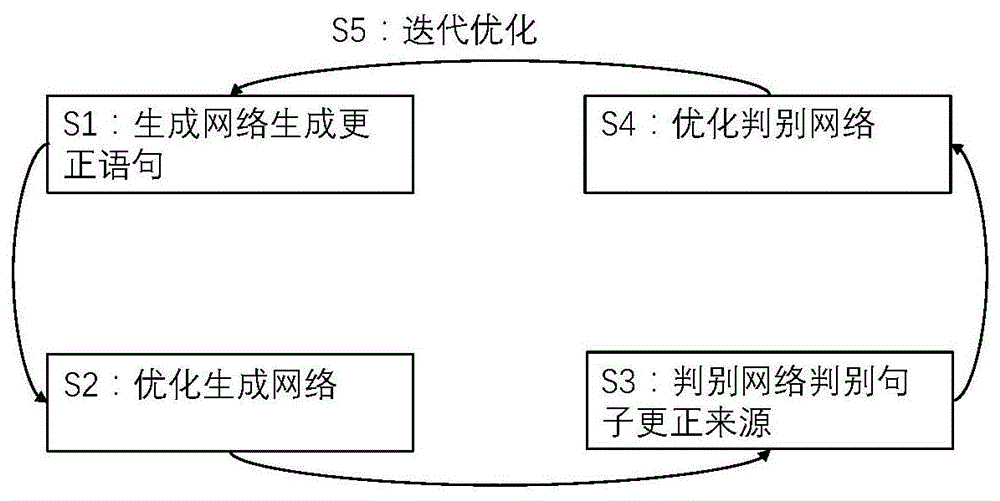
图1是本发明提供的基于生成对抗网络的中文语法错误更正方法的步骤流程示意图
图2为基于卷积神经网络的序列到序列的文本生成网络结构图
具体实施方式
接下来将对本发明的实施方案作更详细的描述。
图1是本发明提供的基于生成对抗网络的中文语法错误更正方法的步骤流程示意图,其中包括:
步骤s1:生成网络生成更正语句;
步骤s2:优化生成网络;
步骤s3:判别网络判别句子更正来源;
步骤s4:优化判别网络;
步骤s5:迭代优化;
下面将对每个步骤进行具体的说明:
步骤s1:生成网络生成更正语句。本发明首先建立生成网络编码层及解码层的词语到词向量编号的映射字典,将文本中各个词语映射为相应的词语编号。建立生成网络编码层及解码层的词向量表,每一行行号对应相应的词语编号,每一行代表一个词向量。通过词向量表将词语编号映射为相应的原词向量。各原词向量与对应的位置向量相加,形成输入词向量。连接文本中各词的输入词向量分别形成编码层输入的文本矩阵及解码层的输入的文本矩阵。假设中文词语共有n个,那么词向量矩阵可以表示为一个n*d的矩阵,其中d表示词向量的维度。输入词向量可以表示为x。
x=v+p
其中,v表示文本中词语的原词向量,p表示词语v对应的位置向量。
将得到的编码层文本矩阵输入生成网络的编码层。生成网络编码层由多层卷积神经网络组成。每一层卷积神经网络由一个一维卷积和一个非线性组成。通过残差连接,连接各层的卷积神经网络。一层的卷积神经网络的计算可以表示为:
[ab]=conv(x)
其中x表示文本向量,a和b表示卷积运算后被分为两部分的结果,σ表示非线性函数,
解码层的计算方式与编码层一样,由多层卷积神经网络组成。每一层卷积神经网络由一个一维卷积和一个非线性组成。通过残差连接,连接各层的卷积神经网络。
编码器的隐藏层的输出向量与解码器的隐藏层输出向量进行运算,得到注意力机制权重,计算得到文本向量。第l层第i个时间截点的文本向量
其中
将得到的预测词语作为下一时刻的输入,计算下一时刻的预测词语,直到预测完成,生成语法错误更正后的句子。图2给出了基于卷积神经网络的序列到序列的文本生成网络结构图。预测下一个词语计算可以表示为:
其中p表示下一个词预测的概率,wo,bo表示输出的权重及偏差,yi表示i个时刻的词语。
步骤s2:优化生成网络。首先利用判别网络的词语到词向量编号的映射字典,将文本中各个词语映射为相应的词语编号,再利用判别网络的词向量表将包含语法错误的句子及生成网络更正的句子中的各个词语映射为相应的词向量,将各数值化的词语分别连接成包含语法错误的文本矩阵及生成网络更正的文本矩阵。判别网络为一个二分类网络,判别更正语句的来源。先将包含语法错误的文本矩阵及生成网络更正的文本矩阵形成句子对[src,tgtp],其中src,tgtp分别是包含语法错误的文本矩阵及生成网络更正的文本矩阵,分别通过一个循环神经网络或卷积神经网络,分别生成文本表示向量,再对文本表示向量进行处理,得到判别网络将输入的更正语句判别为来自人工标注或更正网络的概率。概率计算过程可以表示为:
vs=ms(wssrc+bs)
vtp=mt(wttgtp+bt)
vd=[vs,vtp]
p(ltgt|src,tgtp)=softmax(wdvd+bd)
其中ms,mt分别表示包含语法错误的文本矩阵及生成网络更正的文本矩阵所经过的神经网络,ws,bs分别为计算包含语法错误文本表示向量的权重及偏差,wt,bt分别为计算更正的文本表示向量的权重及偏差,vs,vtp分别为包含语法错误文本的表示向量及更正文本的表示向量,p表示标签为ltgt的概率。
损失函数的计算可以表示为:
其中d,g分别表示判别网络及生成网络,z表示生成网络的输入。
步骤s3:首先利用判别网络的词语到词向量编号的映射字典,将文本中各个词语映射为相应的词语编号,再利用判别网络的词向量表将包含语法错误的句子,人工标注更正的句子及生成网络更正的句子中的各个词语映射为相应的词向量,将各数值化的词语分别连接成包含语法错误的文本矩阵,人工标注更正的文本矩阵及生成网络更正的文本矩阵。将包含语法错误的文本矩阵及人工标注更正的文本矩阵形成句子对[src,tgtg],将包含语法错误的文本矩阵及生成网络更正的文本矩阵形成句子对[src,tgtp],其中src,tgtg及tgtp分别是包含语法错误的文本矩阵,人工标注更正的文本矩阵及生成网络更正的文本矩阵。包含语法错误的文本矩阵及更正的文本矩阵分别通过一个循环神经网络或卷积神经网络,分别生成文本表示向量,再对文本表示向量进行处理,得到判别网络将输入的更正语句判别为来自人工标注或更正网络的概率。概率计算过程与步骤s2的概率计算过程相同。
步骤s4:优化判别网络。在步骤s3得到判别网络将输入的更正语句判别为来自人工标注或更正网络的概率,通过概率计算损失函数,优化判别网络。损失函数计算可以表示为:
其中d(x)表示对真实数据也就是人工标注更正语句进行判别,g(z)表示生成网络生成的更正语句。
步骤s5:迭代优化。返回步骤s1,继续迭代优化生成网络及更正网络,当损失函数不再下降,保持不变时停止优化,得到生成模型。
以上结合附图对所提出的一种基于生成对抗网络的中文语法错误更正方法及各模块的具体实施方式进行了阐述。通过以上实施方式的描述,所属领域的一般技术人员可以清楚的了解到本发明可借助软件加必需的通用硬件平台的方式来实现。
依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
以上所述的本发明实施方式,并不构成对发明保护范围的限定。任何在本发明的精神和原则之内所作的修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!