一种基于自适应权重点卷积的因果方向判别方法与流程
本发明涉及深度学习,涉及因果学习。
背景技术:
大多数统计学习方法都依赖于利用所研究事物之间的相关关系,然而这些相关关系都是由事物之间潜在的因果关系所引起的,因果关系相比于相关关系更能反映事物的本质联系,因果关系不仅有利于预测任务,更能够帮助人们对事物进行干预。传统的因果关系识别依赖严格的控制实验来进行,然而这类方法往往由于代价高昂或受限于道德约束而不可行。幸运的是,大数据时代的来临使得各种类型的观测数据以指数级的速度不断积累,推动了基于数据驱动的学习算法的发展,利用机器学习、深度学习算法在观测数据上进行因果关系挖掘具有重大的研究意义。
因果关系方向识别任务的内容为给定两个确定具有因果关系的变量的若干样本,以此判断两个变量之间因果关系的方向,即判断哪个变量是因,哪个变量是果。传统的方法利用统计假设检验的方法利用两种因果方向之间的差异来进行判断,但是这类方法需要预先对数据的分布类型以及因果机制的类型做出强假设才能实施,往往不能应用到实际应用场景中。近年来也有利用诸如神经网络等强大分类器,将因果方向的判别问题看做二分类问题,在模拟因果数据上进行训练,在真实因果数据上进行测试的方法,但是这类方法提取变量特征的方式为首先单独提取每个样本的个体特征,然后再提取全局特征,缺少了对局部特征的提取,限制了分类精度。
技术实现要素:
本发明的目的是提供一种能够充分提取变量样本局部特征的因果方向判别方法。
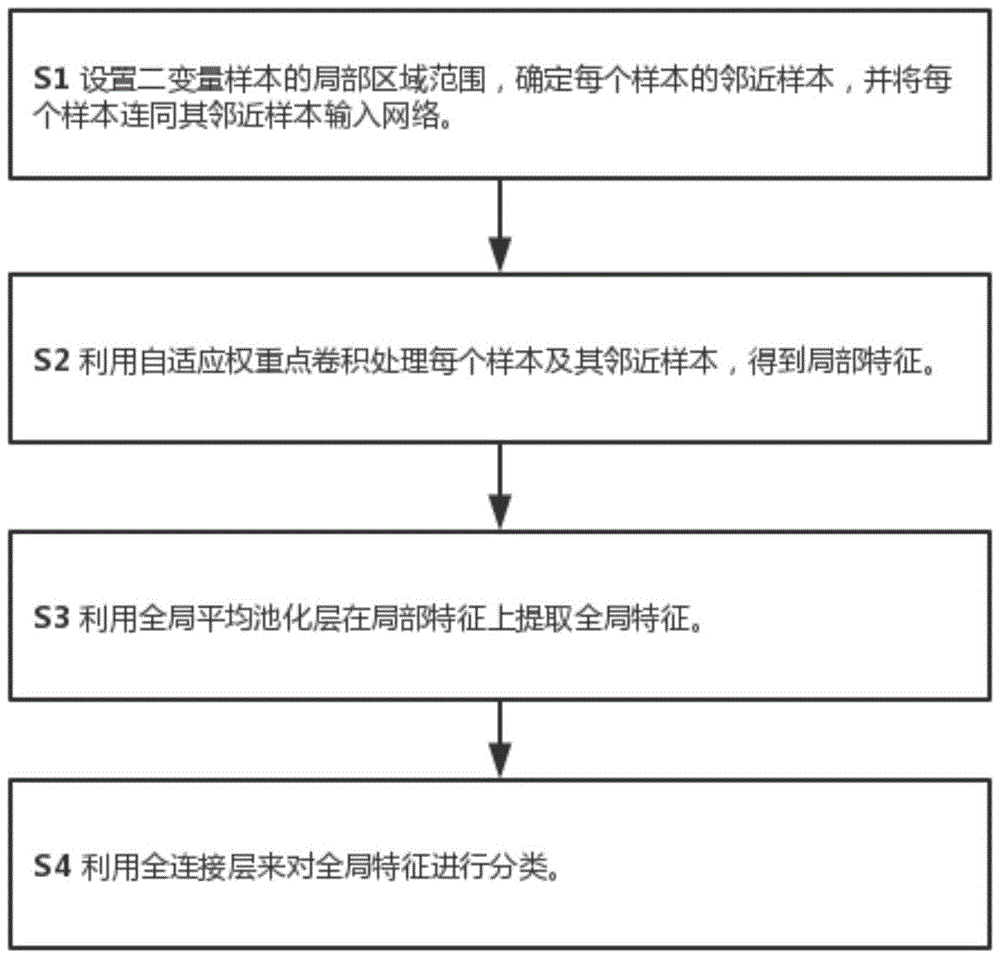
为解决上述技术问题,本发明提供了一种基于自适应权重点卷积的因果方向判别方法,包括如下步骤:
步骤s1,设置二变量样本的局部区域范围,确定每个样本的邻近样本,并将每个样本连同其邻近样本输入网络;
步骤s2,利用自适应权重点卷积来提取每个样本及其邻近样本的局部特征;
步骤s3,利用全局平均池化层在局部特征上提取全局特征;
步骤s4,利用全连接层来对全局特征进行分类。
进一步,步骤s1中,令二变量x,y的数据集为
进一步,步骤s2中,使用自适应权重点卷积同时提取中心样本特征及与邻近样本集的关系特征并进行融合,这样就提取到了局部特征。对于中心样本si,定义其由自适应权重点卷积操作计算得到的局部特征
其中idi为中心样本si的局部区域的逆密度系数,当局部区域样本密度大时该区域带来的信息冗余量就大,局部区域的样本密度越小,其局部特征的重要性也就越大,因此这里选择逆密度系数来作为局部特征的权重,其计算方式如下式所示,其中nd为中心样本的个数,
σ为非线性映射;sij指中心样本si的第j个相邻样本,其中
进一步,步骤s3中,自适应权重点卷积提取到了每个中心样本的特征
进一步,步骤s4中,由全局平均池化操作得到的全局特征,充分融合了所有样本的个体特征及局部特征,最后使用全连接层对该全局特征进行分类。
附图说明
图1是本发明流程图。
具体实施方式
现在结合附图对本发明作进一步详细的说明。这些附图均为简化示意图,仅以示意方式说明本发明的基本结构,因此其仅显示与本发明有关的构成。
实施例1
如图1所示,本实例提供了一种基于自适应权重点卷积的因果方向判别方法,包括如下步骤:
步骤s1,设置二变量样本的局部区域范围,确定每个样本的邻近样本,并将每个样本连同其邻近样本输入网络;
步骤s2,利用自适应权重点卷积来提取每个样本及其邻近样本的局部特征;
步骤s3,利用全局平均池化层在局部特征上提取全局特征;
步骤s4,利用全连接层来对全局特征进行分类。
所述步骤s1中,令二变量x,y的数据集为
所述步骤s2中,使用自适应权重点卷积同时提取中心样本特征及与邻近样本集的关系特征并进行融合得到局部特征。对于样本si,利用下式计算得到其局部特征
所述步骤s3中,自适应权重点卷积提取到了每个中心样本的特征
所述步骤s4中,由全局平均池化操作得到的全局特征,充分融合了所有样本的个体特征及局部特征,最后使用含有三层的全连接层对该全局特征进行分类,输出分类结果,即因果方向为为x→y还是x←y。
- 还没有人留言评论。精彩留言会获得点赞!