基于交叉验证的标签补全方法、终端、装置及存储介质与流程
本发明涉及机器学习技术领域,尤其涉及一种基于交叉验证的标签补全方法、终端、装置及存储介质。
背景技术:
基于监督学习的机器学习算法需要充足的有标签的样本来训练模型,才能达到理想的效果。在现实的应用场景中,部分(甚至大部分)训练样本的标签是缺失的,没有标签的样本将不能用于模型训练,我们通常只能放弃这些样本,这样在造成样本数据浪费的同时,也造成了用来训练机器学习模型的样本数据的不充足,从而降低了训练模型的泛化能力。
目前,现有的技术方案是收集更多的有标签样本或对无标签样本进行标注。然而,人工的有标签样本的收集或样本标注往往需要专业的技术人员来完成,成本高昂。自动标注样本是降低标签成本的一个有效方法。现有的自动样本标注技术是利用迁移学习从拥有大量标签样本的数据集上训练一个判别模型,然后,用该判别模型来确定无标签样本的标签。该种方法的缺点有:从时间成本和人力成本上看,收集大量标签样本的数据集是昂贵的;现成的成本低的标签样本,能够用于迁移学习的大数据集通常只存在于专业度低的领域,比如动物的识别,在专业度高的领域,比如医疗、金融、异常检验等。
在专业度高的领域,优质的样本数据往往分散于不同的企业机构中。可以通过分布式计算的方式利用各个企业机构拥有的数据或模型来进行标签补全。然而,企业机构通常将自己拥有的数据和模型视为商业秘密,这使得非加密的分布式计算方案在现实中是不可行的。
上述内容仅用于辅助理解本发明的技术方案,并不代表承认上述内容是现有技术。
技术实现要素:
本发明的主要目的在于提供一种基于交叉验证的标签补全方法、系统、装置及存储介质,旨在解决现有标签补全中通过本地判别模型补上的标签对本地判别模型有较强的偏执和标签不准确的技术问题。
为实现上述目的,本发明提供一种基于交叉验证的标签补全方法,所述的基于交叉验证的标签补全方法包括以下步骤:
第一终端基于第一样本、所述第一样本对应的第一标签以及第二样本生成所述第二样本对应的待校对标签;
所述第一终端基于所述第二样本、所述待校对标签以及交叉验证算法确定所述第二样本对应的目标标签。
进一步地,在一实施方式中,所述第一终端基于第一样本、所述第一样本对应的第一标签以及第二样本生成所述第二样本对应的待校对标签的步骤包括:
基于所述第一样本以及所述第一标签训练得到第一预测模型;
基于所述第一预测模型以及所述第二样本生成所述待校对标签。
进一步地,在一实施方式中,所述第一终端基于所述第二样本、所述待校对标签以及交叉验证算法确定所述第二样本对应的目标标签的步骤包括:
基于所述第一样本、所述第一样本对应的第一标签、所述第二样本以及所述第二样本对应的待校对标签训练得到第二预测模型;
基于预设加密算法对所述第二预测模型进行加密,并分别发送加密后的第二预测模型至通信系统中的第二终端;
在接收到所述第二终端对应的加密预测模型时,基于所述第二样本以及所述加密预测模型生成预设数量的加密预测标签;
基于所述加密预测标签确定所述第二样本对应的目标标签。
进一步地,在一实施方式中,所述基于所述加密预测标签确定所述第二样本对应的目标标签的步骤包括:
对所述加密预测标签进行随机混淆,并将随机混淆后的加密预测标签分别发送至与所述加密预测标签对应的终端进行解密,以得到解密后的预测标签;
在接收到预设数量的解密后的预测标签时,基于各个解密后的预测标签确定所述第二样本对应的目标标签。
进一步地,在一实施方式中,所述在接收到预设数量的解密后的预测标签时,基于各个解密后的预测标签确定所述第二样本对应的目标标签的步骤包括:
累计所述解密后的预测标签中标签值等于第一预设值的第一数量,以及标签值等于第二预设值的第二数量;
基于所述第一数量及所述第二数量确定所述第二样本对应的目标标签。
进一步地,在一实施方式中,所述基于交叉验证的标签补全装置包括:
预测模块,第一终端基于第一样本、所述第一样本对应的第一标签以及第二样本生成所述第二样本对应的待校对标签;
处理模块,所述第一终端基于所述第二样本、所述待校对标签以及交叉验证算法确定所述第二样本对应的目标标签。
此外,为实现上述目的,本发明还提供一种终端,所述终端包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的基于交叉验证的标签补全程序,所述基于交叉验证的标签补全程序被所述处理器执行时实现上述任一项所述的基于交叉验证的标签补全方法的步骤。
此外,为实现上述目的,本发明还提供一种存储介质,所述存储介质上存储有基于交叉验证的标签补全程序,所述基于交叉验证的标签补全程序被处理器执行时实现上述任一项所述的基于交叉验证的标签补全方法的步骤。
本发明通过第一终端基于第一样本、所述第一样本对应的第一标签以及第二样本生成所述第二样本对应的待校对标签,而后所述第一终端基于所述第二样本、所述待校对标签以及交叉验证算法确定所述第二样本对应的目标标签,进而解决了标签对本地判别模型的偏执,提升了机器模型的性能和标签补全的准确性,同时保证了各终端数据的安全性。
附图说明
图1是本发明实施例方案涉及的硬件运行环境中终端的结构示意图;
图2为本发明基于交叉验证的标签补全方法第一实施例的流程示意图;
图3为本发明一实施例中标签补全流程示意图;
图4为本发明基于交叉验证的标签补全方法第二实施例的流程示意图;
图5为本发明一实施例中终端之间的加密模型迁移的示意图;
图6为本发明一实施例中生成加密预测标签的示意图;
图7为本发明一实施例中终端t通过其它终端对样本的加密预测标签进行解密的示意图;
图8为本发明基于交叉验证的标签补全装置实施例的功能模块示意图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
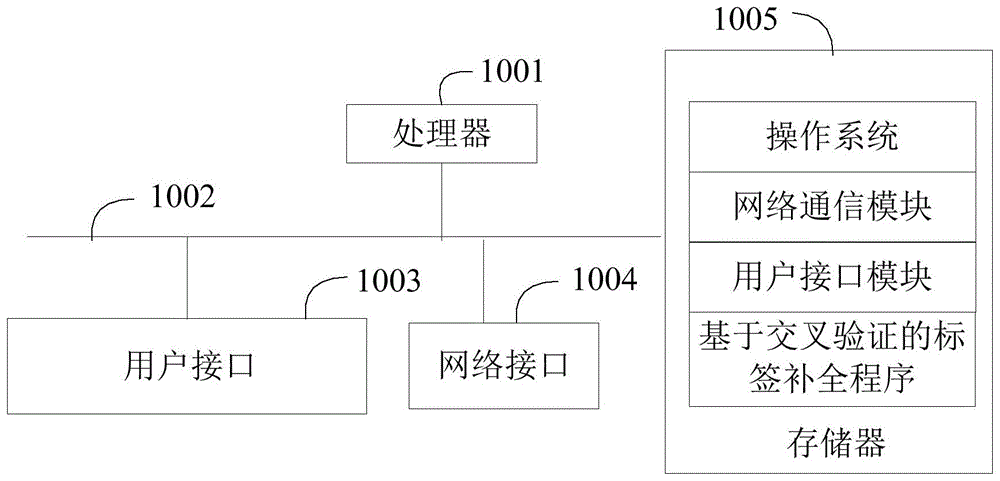
如图1所示,图1是本发明实施例方案涉及的硬件运行环境中终端的结构示意图。
如图1所示,该终端可以包括:处理器1001,例如cpu,网络接口1004,客户接口1003,存储器1005,通信总线1002。其中,通信总线1002用于实现这些组件之间的连接通信。客户接口1003可以包括显示屏(display)、输入单元比如键盘(keyboard),可选客户接口1003还可以包括标准的有线接口、无线接口。网络接口1004可选的可以包括标准的有线接口、无线接口(如wi-fi接口)。存储器1005可以是高速ram存储器,也可以是稳定的存储器(non-volatilememory),例如磁盘存储器。存储器1005可选的还可以是独立于前述处理器1001的存储装置。
可选地,终端还可以包括摄像头、rf(radiofrequency,射频)电路,传感器、音频电路、wifi模块等等。其中,传感器比如光传感器、运动传感器以及其他传感器等,在此不再赘述。
本领域技术人员可以理解,图1中示出的系统结构并不构成对终端的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。
如图1所示,作为一种存储介质的存储器1005中可以包括操作系统、网络通信模块、客户接口模块以及基于交叉验证的标签补全程序。
在图1所示的系统中,网络接口1004主要用于连接后台服务器,与后台服务器进行数据通信;客户接口1003主要用于连接客户端(客户端),与客户端进行数据通信;而处理器1001可以用于调用存储器1005中存储的基于交叉验证的标签补全程序。
在本实施例中,终端包括:存储器1005、处理器1001及存储在所述存储器1005上并可在所述处理器1001上运行的基于交叉验证的标签补全程序,其中,处理器1001调用存储器1005中存储的基于交叉验证的标签补全程序时,执行本申请各个实施例提供的基于交叉验证的标签补全方法的步骤。
本发明还提供一种基于交叉验证的标签补全方法,参照图2,图2为本发明基于交叉验证的标签补全方法第一实施例的流程示意图。
本发明实施例提供了基于交叉验证的标签补全方法的实施例,需要说明的是,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
在本实施例中,该基于交叉验证的标签补全方法包括:
步骤s100,第一终端基于第一样本、所述第一样本对应的第一标签以及第二样本生成所述第二样本对应的待校对标签;
在本实施例中,每个终端的现有样本数据分两类,一类是有标签的样本数据,另一类是无标签的样本数据,终端根据有标签的样本可以进一步确定无标签的样本数据的标签,标签是用于标注数据正常或异常。
具体地,步骤s100包括:
步骤s110,基于所述第一样本以及所述第一标签训练得到第一预测模型;
步骤s120,基于所述第一预测模型以及所述第二样本生成所述待校对标签。
在本实施例中,每个终端有预设数量的样本,样本的具体数量根据通信系统的实际情况确定,预设数量的样本中包括有标签的样本和无标签的样本数据,其中,有标签的样本为第一样本,无标签的样本为第二样本。
具体地,参照图3,确定无标签的样本数据的标签的过程分两步:
第一步,每个终端利用各自的第一样本集根据预设的“机器学习”算法训练得到第一预测模型ft,假设系统中有n个终端,每个终端t(t=1,2,3......n)拥有有标签的样本即第一样本
第二步,每个终端t通过模型ft对无标签样本
步骤s200,所述第一终端基于所述第二样本、所述待校对标签以及交叉验证算法确定所述第二样本对应的目标标签;
在本实施例中,由于通过第一预测模型确定的标签仅仅是根据本地有限的有标签的样本确定,因此准确度不够高,而且容易对本地预测模型有较强的偏执,因此该标签有待于进一步校对。
具体地,根据第一样本和第二样本训练得到第二预测模型,对第二预测模型进行加密,并分别发送加密后的第二预测模型至系统中的其他终端。假设系统中有n个终端,则每个终端将接收到其它n-1个终端对应的第二预测模型,利用n-1个第二预测模型获取加密预测标签,则对于第二样本中的每一个样本就有n-1个加密预测标签,接下来按照预设的算法对n-1个加密预测标签进行随机混淆、解密等操作,得到解密后的n-1个预测标签,此时,样本有n个标签,包括n-1个预测标签和1个待校对标签,再根据预设的判定规则,确定无标签样本
本实施例提出的基于交叉验证的标签补全方法,通过第一终端基于第一样本、所述第一样本对应的第一标签以及第二样本生成所述第二样本对应的待校对标签,而后所述第一终端基于所述第二样本、所述待校对标签以及交叉验证算法确定所述第二样本对应的目标标签,通过交叉验证算法解决了标签对本地判别模型的偏执,提升了机器模型的性能和标签补全的准确性,同时保证了各终端数据的安全性。
基于第一实施例,参照图4,提出本发明基于交叉验证的标签补全方法的第二实施例,在本实施例中,步骤s200包括:
步骤s210,基于所述第一样本、所述第一样本对应的第一标签、所述第二样本以及所述第二样本对应的待校对标签训练得到第二预测模型;
在本实施例中,每个终端利用各自的第一样本、第一样本对应的第一标签、第二样本以及第二样本对应的待校对标签,根据预设的“机器学习”算法训练得到第二预测模型。具体地,假设系统中有n个终端,每个终端每个终端t(t=1,2,3......n)通过其全部样本
步骤s220,基于预设加密算法对所述第二预测模型进行加密,并分别发送加密后的第二预测模型至通信系统中的第二终端;
在本实施例中,每个终端t生成一对公钥和私钥,然后利用公钥对第二预测模型gt进行加密,得到加密后的第二预测模型
步骤s230,在接收到所述第二终端对应的加密预测模型时,基于所述第二样本以及所述加密预测模型生成预设数量的加密预测标签;
在本实施例中,如图6所示,终端t接收到其它n-1个终端对应的加密后的第二预测模型
步骤s240,基于所述加密预测标签确定所述第二样本对应的目标标签。
在本实施例中,终端t的第二样本中的每个样本
具体地,步骤s240包括:
步骤s241,对所述加密预测标签进行随机混淆,并将随机混淆后的加密预测标签分别发送至与所述加密预测标签对应的终端进行解密,以得到解密后的预测标签;
在本实施例中,如图7所示,为了保证数据在传输过程中的安全性,对加密预测标签进行随机混淆,具体做法如下:在每个加密预测标签
步骤s242,在接收到预设数量的解密后的预测标签时,基于各个解密后的预测标签确定所述第二样本对应的目标标签。
在本实施例中,其他终端对加密预测标签进行解密后,将解密后的预测标签
具体地,步骤s242包括:
步骤a,累计所述解密后的预测标签中标签值等于第一预设值的第一数量,以及标签值等于第二预设值的第二数量;
步骤b,基于所述第一数量及所述第二数量确定所述第二样本对应的目标标签。
在本实施例中,标签是用来标注样本数据是异常还是正常,终端t拥有的每一个样本
本实施例提出的基于交叉验证的标签补全方法,通过基于所述第一样本、所述第一样本对应的第一标签、所述第二样本以及所述第二样本对应的待校对标签训练得到第二预测模型,而后基于预设加密算法对所述第二预测模型进行加密,并分别发送加密后的第二预测模型至通信系统中的第二终端,接下来在接收到所述第二终端对应的加密预测模型时,基于所述第二样本以及所述加密预测模型生成预设数量的加密预测标签,最后基于所述加密预测标签确定所述第二样本对应的目标标签。通过所有终端之间将第二样本对应的待校对标签进行交叉验证,实现对待校对标签的校准,同时减少待校对标签对本地预测模型的偏执,从而提高标签的准确性。
本发明进一步提供一种基于交叉验证的标签补全装置,参照图8,图8为本发明基于交叉验证的标签补全装置实施例的功能模块示意图。
预测模块10,第一终端基于第一样本、所述第一样本对应的第一标签以及第二样本生成所述第二样本对应的待校对标签;
处理模块20,所述第一终端基于所述第二样本、所述待校对标签以及交叉验证算法确定所述第二样本对应的目标标签。
进一步地,所述预测模块10还用于:
基于所述第一样本以及所述第一标签训练得到第一预测模型;
基于所述第一预测模型以及所述第二样本生成所述待校对标签。
进一步地,所述处理模块20还用于:
基于所述第一样本、所述第一样本对应的第一标签、所述第二样本以及所述第二样本对应的待校对标签训练得到第二预测模型;
基于预设加密算法对所述第二预测模型进行加密,并分别发送加密后的第二预测模型至通信系统中的第二终端;
在接收到所述第二终端对应的加密预测模型时,基于所述第二样本以及所述加密预测模型生成预设数量的加密预测标签;
基于所述加密预测标签确定所述第二样本对应的目标标签。
进一步地,所述基于交叉验证的标签补全装置包括:
发送模块,对所述加密预测标签进行随机混淆,并将随机混淆后的加密预测标签分别发送至与所述加密预测标签对应的终端进行解密,以得到解密后的预测标签;
确定模块,在接收到预设数量的解密后的预测标签时,基于各个解密后的预测标签确定所述第二样本对应的目标标签。
进一步地,所述确定模块还用于:
累计所述解密后的预测标签中标签值等于第一预设值的第一数量,以及标签值等于第二预设值的第二数量;
基于所述第一数量及所述第二数量确定所述第二样本对应的目标标签。
此外,本发明实施例还提出一种存储介质,所述存储介质上存储有基于交叉验证的标签补全程序,所述基于交叉验证的标签补全程序被处理器执行时实现上述各个实施例中基于交叉验证的标签补全方法的步骤。
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者系统不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者系统所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、方法、物品或者系统中还存在另外的相同要素。
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在如上所述的一个存储介质(如rom/ram、磁碟、光盘)中,包括若干指令用以使得一台系统设备(可以是手机,计算机,服务器,空调器,或者网络设备等)执行本发明各个实施例所述的方法。
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!