基于轻量级卷积神经网络的织物缺陷识别系统的搭建方法与流程
本发明涉及纺织品图像识别
技术领域:
,特别是指一种基于轻量级卷积神经网络的织物缺陷识别系统的搭建方法。
背景技术:
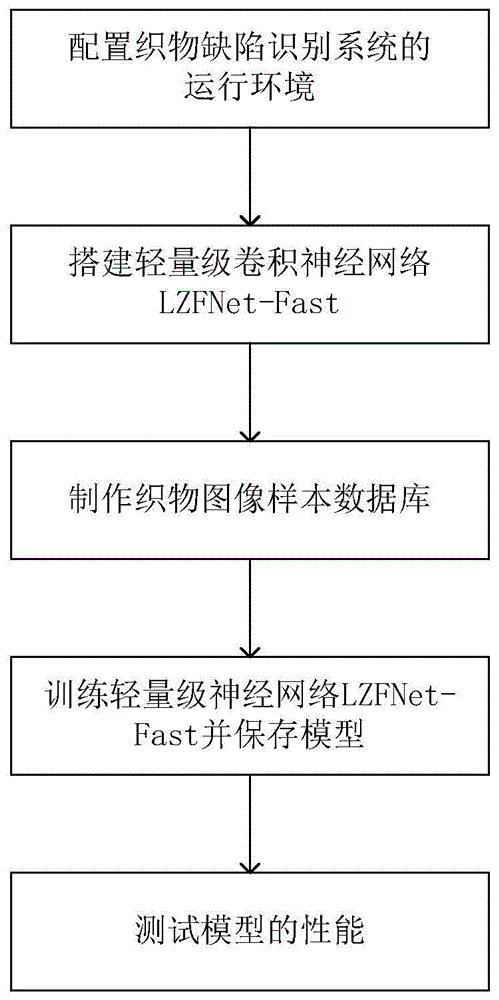
:目前纺织成品的生产成本往往会受到原始坯布的影响,服装行业中大部分质量问题都与织物缺陷有关,这是纺织业面临的主要问题之一。织物缺陷,常称为织物疵点,指在布匹织造过程中,由各种不利因素导致的产品外观上的缺陷。从纤维原料到成品织物,一般需经过纺纱、织造、印染等多道工序,在各加工环节中均有可能产生缺陷。而人工检测织物缺陷成本过高,且容易产生漏检。因此纺织品生产企业需要采用自动缺陷识别系统来保证织物的质量。目前国内外现有的织物缺陷检测方法主要有直方图特性分析、局部对比度增强、傅里叶变换、小波变换、字典学习和方向梯度直方图等。然而,随着整个社会纺织工业的不断发展和消费者欣赏水平的提高,现有的织物大多具有复杂的纹理和图案,而这些传统视觉识别算法往往自适应性较差,难以提取出有利于分类器识别疵点的视觉特征。所以传统织物缺陷识别方法只适用于单色坯布或纹理较规则的织物,而对于纹理和印染较复杂织物的缺陷识别,目前最适合利用深度学习技术来完成。卷积神经网络作为一种重要的识别模型,近年来得到了迅速的发展,并在某些领域取得了显著的成果。然而,卷积神经网络应用于织物缺陷识别目前还存在一些问题。卷积神经模型既具有计算密集型的又具有内存密集型的结构特点,这使得卷积神经模型很难部署在硬件资源有限的现场可编程门阵列和嵌入式系统上。目前的深度卷积神经网络为了提取目标图像的高级语义特征,往往具有非常复杂的结构,这极大地增加了计算开销,不利于织物缺陷实时识别。其次,近年来卷积神经网络发展的趋势是搭建更深更复杂的网络结构,以达到更高的识别精度。然而,这些提高模型识别准确率的新技术并不一定使得系统在运行速度和内存占用方面更加有效。技术实现要素:针对传统深度卷积神经网络存在结构复杂、计算量大的技术问题,本发明提出了一种基于轻量级卷积神经网络的织物缺陷识别方法,构造了一个织物识别领域专用的卷积模块,该模块融合了先进的可因式分解卷积结构,首先将织物图像通过三维卷积操作扩展到32维后作为卷积模块的输入,然后利用可因式分解卷积层进行空间滤波,随后特征图被网络顶部的全局平均池化层压缩到低维空间。本发明可在tensorflow框架中使用人工神经网络库keras和张量流型机器学习库tfslim快速实现,适用于计算资源受限条件下的织物缺陷识别。本发明的技术方案是这样实现的:一种基于轻量级卷积神经网络的织物缺陷识别系统的搭建方法,其步骤如下:s1、配置织物缺陷识别系统的运行环境;s2、设计可因式分解卷积结构,并利用可因式分解卷积结构构建轻量级卷积神经网络lzfnet-fast;s3、采集织物图像样本数据,并对织物图像样本数据进行标准化,标准化后的织物图像样本数据分为训练图像集和测试图像集;s4、利用异步梯度下降的训练策略将训练图像集输入轻量级卷积神经网络lzfnet-fast中进行训练,得到lzfnet-fast模型;s5、将测试图像集输入步骤s4中得到的lzfnet-fast模型进行测试,验证lzfnet-fast模型的性能。所述步骤s1中的织物缺陷识别系统的运行环境包括硬件系统和软件系统,硬件系统的处理器包括两个cpu和两个gpu,cpu的型号均为英特尔xeon(r)e5-2650-v4,gpu的型号均为英伟达quadrom5000;软件系统包括操作系统和卷积库,其中,操作系统为windows10,卷积库为卷积神经网络加速库cudnn7.0。所述步骤s2中的轻量级卷积神经网络lzfnet-fast的构建方法为:定义一个局部感受野为3×3的二维面卷积层和一个1×1×n的三维信息融合层,然后将二维面卷积层和三维信息融合层编译为一个可因式分解卷积结构,并利用可因式分解卷积结构搭建轻量级卷积神经网络lzfnet-fast。所述轻量级卷积神经网络lzfnet-fast包含一个标准卷积层、九个可因式分解卷积结构、十九个批量正则化层、一个全局平均池化层、一个全连接层和一个softmax分类器;一个可因式分解卷积结构包括一个二维面卷积层和一个三维信息融合层,一个标准卷积层、九个二维面卷积层和九个三维信息融合层共十九个卷积层,卷积层和批量正则化层一一对应,最后一个批量正则化层与全局平均池化层相连接,全局平均池化层与全连接层相连接,全连接层与softmax分类器相连接。对于大小为f×f的输入特征图,标准卷积层的计算量cs为:cs=f×f×k×k×m×n,其中,m为输入通道的数量,n为输出通道的数量,k×k为标准卷积层的卷积核尺寸;可因式分解卷积结构是将卷积层分为面卷积层和信息融合层两部分,面卷积层的卷积核大小为k×k,信息融合层的卷积核大小为1×1,则可因式分解卷积结构的计算量cf为:cf=f×f×k×k×m+f×f×m×n;可因式分解卷积结构与标准卷积层的计算量之比为:所述标准卷积层和四个二维面卷积层均采用步幅为2的卷积替代最大池化,所有卷积层的标准化均采用批量标准化,激活函数采用值域为0~6的修正线性单元,终端采用softmax分类器作为织物缺陷判决器。织物图像样本数据分为两类,分别为正常织物图像和缺陷织物图像,正常织物图像的数量和缺陷织物图像的数量相近;所述训练图像集的数量占总数量的4/5,测试图像集的数量占总数量的1/5。所述步骤s4中利用异步梯度下降的训练策略将训练图像集输入轻量级卷积神经网络lzfnet-fast中进行训练,得到lzfnet-fast模型的方法为:s41、激活卷积神经网络加速库cudnn7.0,激活人工神经网络库keras和张量流型机器学习库tfslim;s42、将训练图像集中的正常织物图像和缺陷织物图像分别转化为tfrecord格式文件,并分别保存为两个单独的文件;s43、初始化初始学习率θ、迭代动量参数vi,初始迭代次数i=0,设置最大迭代次数imax;s44、利用异步梯度下降的训练策略将训练图像集输入轻量级卷积神经网络lzfnet-fast中进行训练:其中,α为权重衰减,l为损失函数,di为第i次迭代时的训练图像的数量,wi为待训练的lzfnet-fast模型参数;更新lzfnet-fast模型参数:wi+1=wi+vi+1;s45、迭代次数增加1,循环执行步骤s44直至达到最大迭代次数imax,结束循环,生成lzfnet-fast模型。本技术方案能产生的有益效果:本发明利用可因式分解卷积结构建立lzfnet-fast模型,可与现场可编程门阵列或嵌入式系统的设计要求相匹配,能够识别纹理复杂的有色织物,并且在保证识别精度的前提下,比原始神经网络vgg16减少98.4%的模型参数数量和97.6%的计算量,极大地减少了对硬件计算能力和内存容量的依赖,使得深度神经网络更容易在工业现场运行。附图说明为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。图1为本发明的系统框图。图2为本发明的可因式分解卷积运算图;(a)为标准三维卷积层,(b)为二维面卷积层,(c)为信息融合层。图3为本发明具体实例中采用的织物缺陷图;(a)为经纬线缺失,(b)为划痕缺陷,(c)为斜纹缺陷,(d)为印染疵点。具体实施方式下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有付出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。如图1所示,一种基于轻量级卷积神经网络的织物缺陷识别系统的搭建方法,其步骤如下:s1、配置织物缺陷识别系统的运行环境;织物缺陷识别系统的运行环境包括硬件系统和软件系统,硬件系统的处理器包括两个cpu和两个gpu,cpu的型号均为英特尔xeon(r)e5-2650-v4,gpu的型号均为英伟达quadrom5000,软件系统包括操作系统和卷积库,其中,操作系统为windows10,卷积库为卷积神经网络加速库cudnn7.0。s2、设计可因式分解卷积结构,并利用可因式分解卷积结构构建轻量级卷积神经网络lzfnet-fast;定义一个局部感受野为3×3的二维面卷积层和一个1×1×n的三维特征图信息融合层,然后将二维面卷积层和三维信息融合层编译为一个可因式分解卷积结构,并利用可因式分解卷积结构搭建轻量级卷积神经网络lzfnet-fast。所述轻量级卷积神经网络lzfnet-fast包含一个标准卷积层、九个可因式分解卷积结构、十九个批量正则化层、一个全局平均池化层、一个全连接层和一个softmax分类器;一个可因式分解卷积结构包括一个二维面卷积层和一个三维信息融合层,一个标准卷积层、九个二维面卷积层和九个三维信息融合层共十九个卷积层,卷积层和批量正则化层一一对应(织物图像首先经过一个标准卷积层,接着经过一个批量正则化层,然后经过一个二维面卷积层,之后再经过一个批量正则化层,然后经过一个三维信息融合层,再经过一个批量正则化层,二维面卷积层、批量正则化层和三维信息融合层交替分布),最后一个批量正则化层与全局平均池化层相连接,全局平均池化层与全连接层相连接,全连接层与softmax分类器相连接。所述轻量级卷积神经网络lzfnet-fast是基于标准卷积结构的,如图2(a)所示,标准卷积结构的卷积层是直接利用尺度为k×k×m×n的卷积核对输入特征矩阵进行空间卷积滤波,标准卷积层的计算量cs为:cs=f×f×k×k×m×n,其中,m为输入通道的数量,n为输出通道的数量,k×k为标准卷积层的卷积核尺寸,f×f为输入特征图的维度;如图2(b)和图2(c)所示,轻量级卷积神经网络lzfnet-fast是通过因式分解卷积结构将卷积层分为面卷积层和信息融合层两部分,面卷积层使用单个相互独立的卷积滤波器分别卷积每个输入特征图矩阵,然后信息融合层通过使用简单的1×1卷积核对卷积层输出的多维特征图进行线性组合,可因式分解卷积结构的计算量cf为:cf=f×f×k×k×m+f×f×m×n;由此可以看出可因式分解卷积结构的计算量是面卷积层的计算量和信息融合层的计算量之和,信息融合层的三维1×1卷积占了较大的计算复杂度。假设计算设备中的ram容量足够大,足以存储功能映射和参数,则内存访问成本或内存操作数目mac为:mac=(m+n)×f2+m×n。所述内存访问成本或内存操作分别对应于输入/输出特征图的内存访问和内核权重,内存访问操作数存在由触发器给出的下限,当输入和输出通道的数目相等时,内存访问操作数到达下限。但实际上,许多嵌入式设备上的ram不够大。此外现代神经网络运行库通常采用复杂的阻塞策略来充分利用缓存机制,因此真正的内存访问操作数可能会偏离理论值。在googlenet的体系结构中,“多路径”结构在每个卷积模块中被广泛采用。许多碎片化操作符被使用,而不是几个大型操作符。虽然这种碎片化操作结构有助于提高精度,但由于对gpu等具有强大并行计算能力的设备不友好,它可能会降低计算效率。而且还引入了额外的开销,如ram的启动和同步。在轻量级卷积神经网络中,元素级操作占用了相当长的时间,特别是在gpu上,因此,按元素计算的运算符包括relu、张量加法、偏置相加等,特别是,面卷积也是一个元素级算子,因为它也有一个很高的内存访问操作数和每秒浮点运算率之比。通过将标准卷积层分解为面卷积层和信息融合层,从而可以轻易地构成轻量级卷积模块。可因式分解卷积结构与标准卷积层的计算量之比为:所述轻量级卷积神经网络lzfnet-fast是将lzfnet作为基准网络,把标准卷积层替换成可因式分解卷积结构,实现快速卷积操作,以达到压缩神经网络体积和减少织物缺陷识别系统计算消耗的目的,新的网络配置如表1所示。表1lzfnet-fast的网络配置表输入维度功能层步幅卷积核维度224×224×3三维卷积23×3×3×32112×112×32面卷积层13×3×32112×112×32融合层11×1×32×64112×112×64面卷积层23×3×6456×56×64融合层11×1×64×12856×56×128面卷积层13×3×12856×56×128融合层11×1×128×12856×56×128面卷积层23×3×12828×28×128融合层11×1×128×25628×28×256面卷积层13×3×25628×28×256融合层11×1×256×25628×28×256面卷积层23×3×25614×14×256融合层11×1×256×51214×14×512面卷积层13×3×51214×14×512融合层11×1×512×51214×14×512面卷积层23×3×5127×7×512融合层11×1×512×10247×7×1024面卷积层13×3×10247×7×1024融合层11×1×1024×10247×7×1024平均池化层-7×71×1×1024全连接层-1024×21×1×2分类器--所述标准卷积层和四个二维面卷积层均采用步幅为2的卷积替代最大池化实现下采样的功能,轻量级卷积神经网络lzfnet-fast中最后一个可因式分解卷积结构的输出特征图维度为7×7×1024,然后将所有特征图输入到平均池化层实现降维。且所有卷积层的标准化均采用批量标准化(batchnormalization),激活函数采用值域为0~6的修正线性单元(relu6),终端采用softmax分类器作为织物缺陷判决器。轻量级卷积神经网络lzfnet-fast的具体构建方法如下:1)激活tensorflow环境,并加载“tf.contrib.slim”、“tf.configproto”、“functools”、“namedtuple”高级封装库。2)定义可因式分解卷积操作,将二维面卷积层与信息融合层合并为一个函数,并根据表1对卷积核维度kernel、步幅stride、层数depth(表1的行数)进行赋值。3)根据表1提供的网络结构配置搭建轻量级卷积神经网络lzfnet-fast,并将超参数设置为以下值:织物图像的图像分辨率inputs=224,类别数量num_classes=2,网络深度乘子depth_multiplier=1.0,权重衰减weight_decay=0.00004。4)将轻量级卷积神经网络lzfnet-fast文件命名为“lzfnet-fast.py”。轻量级卷积神经网络lzfnet-fast中面卷积层共包含26208个参数,信息融合层共包含2091008个参数,整个模型仅含有2120128个权重参数。其中面卷积操作的计算量为13773312次,线卷积操作计算量为333971456次,模型总的计算量为358584832次,仅占标准卷积网络计算量的10.1%。s3、采集织物图像样本数据,并对织物图像样本数据进行标准化,标准化后的织物图像样本数据分为训练图像集和测试图像集;本发明使用的织物图像样本数据是具有复杂纹理背景的彩色纺织品,如图3所示。织物图像的标准化的方法为:利用张量流型机器学习库tfslim将.jpg格式的织物图像转换为.tfrecord格式,有利于处理大批量的织物图像,提高训练速度。所述织物图像样本数据分为两类,分别为正常织物图像和缺陷织物图像,正常织物图像的数量和缺陷织物图像的数量相近,织物图像样本数据的总数量为3800幅;所述训练图像集的数量占总数量的4/5,为3000幅,测试图像集的数量占总数量的1/5,为800幅。s4、利用异步梯度下降的训练策略将训练图像集输入轻量级卷积神经网络lzfnet-fast中进行训练,得到lzfnet-fast模型,步骤如下:s41、激活卷积神经网络加速库cudnn7.0,激活人工神经网络库keras和张量流型机器学习库tfslim;s42、将训练图像集中的正常织物图像和缺陷织物图像分别转化为tfrecord格式文件,图像大小固定为224×224的红绿蓝三通道彩色织物图像,并分别保存为两个单独的文件;s43、导入步骤4)的“lzfnet-fast.py”文件,初始化初始学习率θ=0.01,初始迭代动量参数vi=0.9,初始迭代次数i=0,设置最大迭代次数为imax=2000;s44、利用异步梯度下降的训练策略将训练图像集输入轻量级卷积神经网络lzfnet-fast中进行训练:其中,α为权重衰减,权重衰减α=0.00004,l为损失函数,di为第i次迭代时的训练图像的数量,训练图像的数量di=64,wi为待训练的lzfnet-fast模型参数;第i次迭代从第一个文件夹内取64幅图像用来训练,第i+1次迭代从第二个文件夹内取64幅图像用来训练,文件夹内的图像是有放回的取用;更新lzfnet-fast模型参数:wi+1=wi+vi+1;s45、循环执行步骤s44直至达到最大迭代次数imax,结束循环,生成lzfnet-fast模型。s5、将测试图像集输入步骤s4中得到的lzfnet-fast模型进行测试,验证lzfnet-fast模型的性能。为了评估模型的性能,将包含疵点的图像和正常图像分别输入到经过完全训练的lzfnet-fast模型中,并生成各自的准确率。在包含400张有缺陷织物图像的数据集中,共识别出378张缺陷图像和22张正常图像,漏检率为5.5%。在包含400幅正常织物图像的数据集中,共识别了383幅正常图像和17幅缺陷图像,误检率为4.2%。总体上,整个系统总的正确识别率为95.1%,平均每幅输入图像的平均识别时间为13.2毫秒。与大规模卷积神经网络的详细性能比较如表2所示。本发明使用的彩色织物图像库包含的图像数量有限,如果能够提供更多的彩色织物图像进行模型训练,将获得更理想的实验结果。表2lzfnet-fast与大规模卷积网络的性能对比以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1