基于特征选择的季节型非平稳并发量能耗分析方法与流程
本发明涉及云计算
技术领域:
,尤其涉及一种基于特征选择的季节型非平稳并发量能耗分析方法。
背景技术:
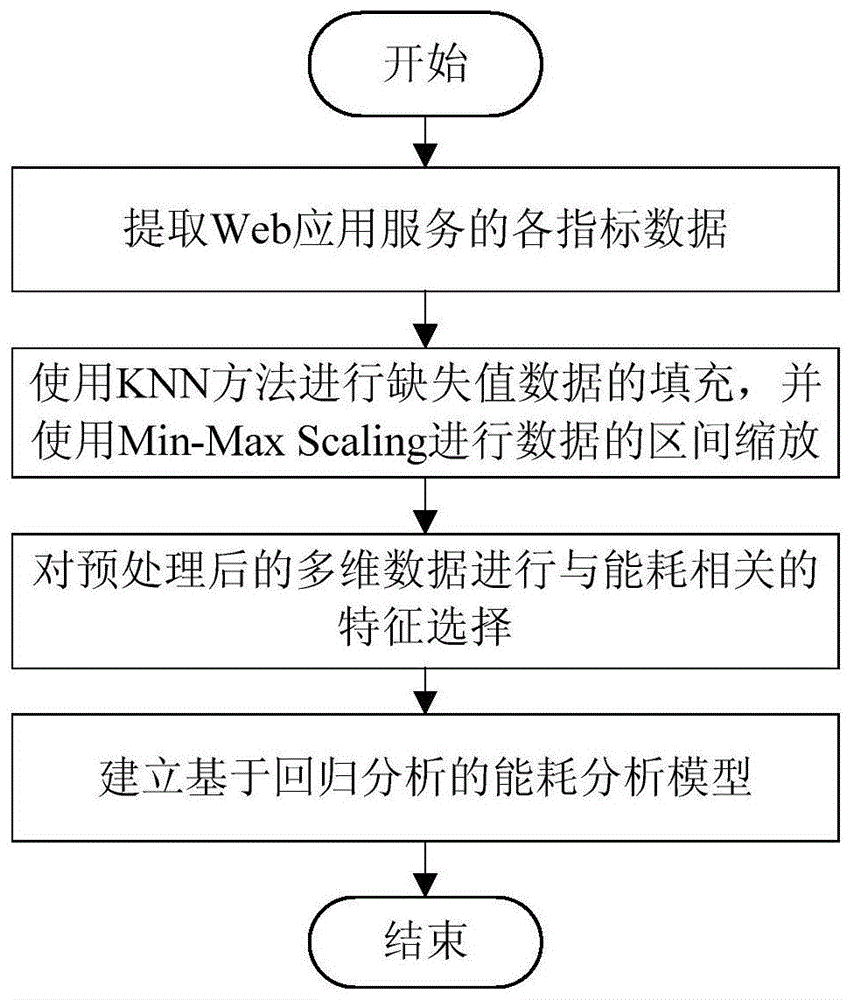
:云计算使用户通过互联网按需自助服务,可以自动扩展和按照需求使用付费模式提供大量的共享计算资源,虽然云计算提供了许多好处,但是云服务中心的高能耗是一个严重的问题。云服务中心的高能耗近年来受到了广泛关注,主要包括三方面的原因:对性能产生重大影响;对环境造成不利的影响;过高的运营成本。因此,合理降低能耗的产生已经成为全社会亟待解决的问题,精确的能耗分析系统必不可少。现有的方法主要将重点放在cpu能耗上,而忽略了其它各方面的能源消耗,例如内存、磁盘等。若要制定相对精确的能耗分析方法,需要同时考虑很多对云服务中心整体能耗有贡献的资源。此外,现有的方法在能耗分析时并没有考虑应用特性,不同的应用特性对资源的需求有所不同,只考虑单一组件,这样得出的能耗数据是不太准确,参考价值不高的。技术实现要素:本发明要解决的技术问题是针对上述现有技术的不足,提供一种基于特征选择的季节型非平稳并发量能耗分析方法,针对web应用特性建立能耗模型,实现对web应用服务的能耗进行分析计算,为合理降低能耗,提高云服务中心的性能提供依据。为解决上述技术问题,本发明所采取的技术方案是:基于特征选择的季节型非平稳并发量能耗分析方法,包括以下步骤:步骤1、提取web应用服务的各指标数据并进行数据预处理;步骤1.1、在数据提取的过程中,使用负载测试工具提取web应用服务的特征参数,标记为{x1,x2,...xn},每一行代表一个元组,并提取能耗数据为y;所述特征参数包括处理器时间、已使用的内存大小、页面错误/秒、磁盘时间、磁盘字节数/秒、字节总数/秒和当前带宽;步骤1.2、在数据预处理的过程中,使用knn方法进行缺失值数据的填充,并使用min-maxscaling进行数据的区间缩放;knn算法对缺失值数据进行填充时,首先计算并记录包含某维缺失数据值的数据元组的目标数据与所有不含任何缺失数据值的数据元组的完全数据元组的欧几里得距离,然后在所有完全数据元组中选择与目标数据的欧几里得距离最小的前k个数据元组作为目标数据的最近邻,最后对前k个近邻项数据相应位置的加权平均作为目标数据的记录缺失值的估计值;步骤1.2.1、初始化数据,将提取出的特征参数构建整个数据矩阵(x1,x2,...,xn);步骤1.2.2:将整个数据矩阵分离构建完全数据矩阵(x1,x2,...,xn)与目标数据矩阵(x1″,x2″,...,xn″);所述完全数据为不含任何缺失数据值的数据,所述目标数据为包含某维缺失数据值的数据;步骤1.2.3:计算目标数据矩阵中每一个元组与完全数据矩阵中所有数据元组的欧几里得距离,如下公式所示:其中,di为x″i与x′j之间的欧几里得距离,x″i表示目标数据矩阵中第i个元组,i=1,2,…,n,x′j表示完全数据矩阵中第j个元组,j=1,2,…,n,;步骤1.2.4:针对每一个目标数据元组选择出欧几里得距离最小的前k个数据元组作为目标数据元组的k最近邻;步骤1.2.5:计算出目标数据元组的前k个最近邻权值,如下公式所示:其中,wi表示第i个目标数据元组的前k个最近邻权值;步骤1.2.6:计算目标数据矩阵中每个元组的缺失数据值,并在整个数据元组中的相应位置进行填补,如下公式所示:其中,xi表示第i个最近邻前k个完全数据元组相应位置的值,xi表示第i个原始数据元组的值;步骤1.2.7:使用min-maxscaling方法,对缺失值填充完成的数据进行区间缩放,即将数据的取值区间转换到[0,1]范围内,归一化公式如下所示:其中,x表示缺失值填充完成的数据,min表示并发量数据中的最小值,max表示并发量数据中的最大值,y表示处理完的数据;步骤2、采用过滤型特征选择算法与装箱式特征选择算法相结合的方式,对预处理后的多维数据进行与能耗相关的特征选择;将提取出的各维数据定义为x=[x1,x2,...,xn],xi=[xi1,xi2,...,xim],并将监测出的能耗数据定义为y,y=[y1,y2,...,ym],同时初始化线性相关系数α与特征排序集r=[],使用knn算法对x与y进行数据预处理,分别计算xi在pearson度量下的相关性分数sip以及在随机森林的相关性度量下的相关性分数sir,得到各个特征的分数s=α·sip+(1-α)·sir,并进行排名,得到筛选后的特征集合x′=[x1,x2,...,xn′],然后使用装箱式特征选择算法对x′进行特征排序,最后,训练一个线性支持向量机,将筛选出的特征作为输入,计算特征权重wi′,i′=1,2,…,n′,得到特征集合x′中特征的排名分数:ci′=(wi′)2;步骤3、根据步骤2得到的与能耗相关的特征集合x′建立基于回归分析的能耗分析模型,得到web应用服务的实际能耗;采用幂回归、指数回归与多项式回归三种建模方法分别建立最终的能耗分析模型;采用幂回归建模方法建立的最终能耗分析模型为:幂回归公式如下所示:其中,y是web应用服务的实际能耗,b0,b1,b2,...,bn′是回归系数,ε表示随机误差;所述采用指数回归建模方法建立的最终能耗分析模型为:指数回归公式如下所示:其中,y是web应用服务的实际能耗,β0,β1,β2,...,βn′是回归系数,ε表示随机误差;所述采用多项式回归建模方法建立的最终能耗分析模型为:多项式回归公式如下所示:y=β0+β1x1+β2x2+...+βn′xn′+ε(7)其中,y是web应用服务的实际能耗,β0,β1,β2,...,βn′是回归系数,ε表示随机误差。采用上述技术方案所产生的有益效果在于:本发明提供的基于特征选择的季节型非平稳并发量能耗分析方法,建立了基于特征选择与回归分析的云服务中心能耗模型,与现有模型只考虑单一组件的方式不同,本发明方法提出的能耗建模方法建立在web应用特性的基础上,涉及了存储器、处理单元与磁盘等的能量消耗,主要提取的参数包括processortime,memoryused,pagefault/sec,disktime,diskbytes/sec等特征。将提取的特征作为改进特征选择算法的输入数据,选择出合理有效的特征,在缩减数据维度的基础上提高了数据质量,提升了特征选择的效率;最后,将选择出来的有效特征进行回归分析建模,得到最终的能耗模型,使模型泛化能力较强从而减少过拟合,使建立的能耗模型所得到的数据更接近于真实值。附图说明图1为本发明实施例提供的基于特征选择的季节型非平稳并发量能耗分析方法的流程图;图2为本发明实施例提供的两种特征选择方法下的能耗回归模型对比图;图3为本发明实施例提供的五种能耗模型对比图;图4为本发明实施例提供的五种模型相对误差对比图。具体实施方式下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。本实施例以某虚拟的飞机订票系统为例,使用本发明的基于特征选择的季节型非平稳并发量能耗分析方法对web应用服务的实际能耗进行分析。基于特征选择的季节型非平稳并发量能耗分析方法,如图1所示,包括以下步骤:步骤1、提取web应用服务的各指标数据并进行数据预处理;步骤1.1、在数据提取的过程中,使用负载测试工具提取web应用服务的特征参数,标记为{x1,x2,...xn},每一行代表一个元组,并提取能耗(energyconsumption)数据为y;所述特征参数包括处理器时间(processortime)、已使用的内存大小(memoryused)、页面错误/秒(pagefault/sec)、磁盘时间(disktime)、磁盘字节数/秒(diskbytes/sec)、字节总数/秒(bytestotal/sec)和当前带宽(currentbandwidth);步骤1.2、在数据预处理的过程中,使用knn方法进行缺失值数据的填充,并使用min-maxscaling进行数据的区间缩放;knn算法对缺失值数据进行填充时,首先计算并记录包含某维缺失数据值的数据元组的目标数据与所有不含任何缺失数据值的数据元组的完全数据元组的欧几里得距离,然后在所有完全数据元组中选择与目标数据的欧几里得距离最小的前k个数据元组作为目标数据的最近邻,最后对前k个近邻项数据相应位置的加权平均作为目标数据的记录缺失值的估计值;步骤1.2.1、初始化数据,将提取出的特征参数构建整个数据矩阵(x1,x2,...,xn);步骤1.2.2:将整个数据矩阵分离构建完全数据矩阵(x1,x2,...,xn)与目标数据矩阵(x1″,x2″,...,xn″);所述完全数据为不含任何缺失数据值的数据,所述目标数据为包含某维缺失数据值的数据;步骤1.2.3:计算目标数据矩阵中每一个元组与完全数据矩阵中所有数据元组的欧几里得距离,如下公式所示:其中,di为x″i与x′j之间的欧几里得距离,x″i表示目标数据矩阵中第i个元组,i=1,2,…,n,x′j表示完全数据矩阵中第j个元组,j=1,2,…,n,;步骤1.2.4:针对每一个目标数据元组选择出欧几里得距离最小的前k个数据元组作为目标数据元组的k最近邻;步骤1.2.5:计算出目标数据元组的前k个最近邻权值,如下公式所示:其中,wi表示第i个目标数据元组的前k个最近邻权值;步骤1.2.6:计算目标数据矩阵中每个元组的缺失数据值,并在整个数据元组中的相应位置进行填补,如下公式所示:其中,xi表示第i个最近邻前k个完全数据元组相应位置的值,xi表示第i个原始数据元组的值;步骤1.2.7:使用min-maxscaling方法,对缺失值填充完成的数据进行区间缩放,即将数据的取值区间转换到[0,1]范围内,归一化公式如下所示:其中,x表示缺失值填充完成的数据,min表示并发量数据中的最小值,max表示并发量数据中的最大值,y表示处理完的数据;步骤2、采用过滤型特征选择算法与装箱式特征选择算法相结合的方式,对预处理后的多维数据进行与能耗相关的特征选择;将提取出的各维数据定义为x=[x1,x2,...,xn],xi=[xi1,xi2,...,xim],并将监测出的能耗数据定义为y,y=[y1,y2,...,ym],同时初始化线性相关系数α与特征排序集r=[],使用knn算法对x与y进行数据预处理,分别计算xi在pearson度量下的相关性分数sip以及在随机森林的相关性度量下的相关性分数sir,得到各个特征的分数s=α·sip+(1-α)·sir,并进行排名,得到筛选后的特征集合x′=[x1,x2,...,xn′],然后使用装箱式特征选择算法对x′进行特征排序,最后,训练一个线性支持向量机,将筛选出的特征作为输入,计算特征权重wi′,i′=1,2,…,n′,得到特征集合x′中特征的排名分数:ci′=(wi′)2;步骤3、根据步骤2得到的与能耗相关的特征集合x′建立基于回归分析的能耗分析模型,得到web应用服务的实际能耗;采用幂回归、指数回归与多项式回归三种建模方法分别建立最终的能耗分析模型;(1)基于幂回归的能耗分析建模幂回归公式如下所示:其中,y是web应用服务的实际能耗,b0,b1,b2,...,bn′是回归系数,ε表示随机误差;(2)基于指数回归的能耗分析建模指数回归公式如下所示:其中,y是web应用服务的实际能耗,β0,β1,β2,...,βn′是回归系数,ε表示随机误差;(3)基于多项式回归的能耗分析建模多项式回归公式如下所示:y=β0+β1x1+β2x2+...+βn′xn′+ε(7)其中,y是web应用服务的实际能耗,β0,β1,β2,...,βn′是回归系数,ε表示随机误差。本实施例中,测试环境建立在虚拟环境中的飞机订票系统以及提供web服务的负载测试工具hploadrounner之上。在hploadrunner上搭建完成测试环境之后,即可运行负载测试场景。在测试运行的过程中,通过loadrunner的一套集成监控器实时了解web应用程序的各指标数据。另外,可以通过controller的联机图查看并提取监控器收集的各项指标数据。运行完场景之后,通过hploadrunneranalysis对场景运行中生成的性能数据进行分析,也可以使用它把性能相关的数据进行总结,得到详细的报告和图例表格。环境搭建完成之后,针对web应用服务,基于虚拟环境中的飞机订票系统对hploadrunner进行加压,并在controller中提取对应数据,同时,得到能耗相关数据。表1显示了web应用服务下部分参数的数据值。由表1可知,对于事务web应用,当“cpu利用率,,,,processortime”=6.89%,“已使用的内存大小memoryused”=4.29%,“处理器每秒钟处理的错误页pagefault/sec”=28192.04,“磁盘系统的吞吐率disktime”=2.86,“磁盘忙于读写活动所用时间的百分比diskbytes/sec”=689229.22,“服务器发送和接收数据的速率bytestotal/sec”=64.13,“当前带宽currentbandwidth”=9.22×1018时,“能耗energycompution”=107.00,以此类推。本实施例中,各个特征得分排名如表2所示,由表可知,前三个特征(即处理器时间,使用的内存和页面错误/秒)显着贡献,而磁盘时间和磁盘字节数/秒贡献很少,“字节总数/秒”和“当前带宽“基本没有任何贡献。这是因为web应用服务需要大量的处理能力。因此,我们选择非零特征(即处理器时间,使用内存,页面错误次数,磁盘字节数/秒,和磁盘时间)来构建能耗模型。并使用y,x1,x2,x3,x4,x5,x6分别表示energyconsumption,processortime,diskbytes/sec,disktime,pagefault/sec,memoryused以及bytestotal/sec。如表3所示。表1web应用下各指标数据表表2各个特征得分排名参数得分processortime61.3memoryused17.5pagefault/sec14.2disktime4.6diskbytes/sec2.1bytestotal/sec0.3currentbandwidth0表3各个指标参数代表参数代表yenergyconsumptionx1processortimex2diskbytes/secx3disktimex4pagefault/secx5memoryusedx6bytestotal/sec根据建立的能耗模型,将各个参数代入分别得到幂回归、指数回归与多项式回归模型。其中,基于幂回归的回归模型为:y=e8.920533·x10.198811·x2-0.008926·x3-0.028378·x4-0.016527·x5-2.920025·x6-0.014455基于指数回归的回归模型为:基于多项式的回归模型为:y=-334.1569-0.115852x12-6.70×10-5x2+16.867x3-0.000406x4+102.1x5-0.0797x6为了评估能耗模型的准确性,定义如下度量:其中,pp表示能耗模型的预测值,pt是能耗的真实值,pe表示能耗的相对误差,pt所表示的数据值是通过powerbay-ssm工具测量的。将三种能耗回归模型与线性模型、立方模型进行对比分析,其中,线性模型以及立方模型在能耗建模方面更侧重于cpu所产生的贡献。本实施例首先验证本发明提出的特征选择算法的有效性。图2为通过两种特征选择算法,建立的能耗模型数据对比结果,一种特征选择算法为本发明提出的改进过滤型与装箱式特征选择算法,另一种为lvw算法。如图2所示,通过改进过滤型与装箱式特征选择算法选择特征之后建立的模型数据明显比较接近于能耗真实数据。图3与图4分别显示了web应用服务使用幂回归、指数回归、多项式回归、线性回归以及立方回归模型下的能耗和相对误差。由图3分析可知,三种建模方法(幂回归、指数回归与多项式回归)的性能明显优于线性回归以及立方回归模型。原因主要包括两个,其中一个是web应用服务的特点决定的。web应用服务本身在执行任务时频繁访问内存和网络,因此,若只考虑cpu或者内存因素不足以构建能耗模型。而本发明选择的特征不只包括cpu和内存因素,还考虑了磁盘以及网络接口卡等因素。另外一个原因是幂回归、指数回归与多项式回归利用改进过滤型与装箱式特征选择提高了基于特征的能耗模型的精度。图4为提取的50次能耗数据相对误差的对比,通过相对误差也可以得出三种建模方法(幂回归、指数回归与多项式回归)的性能相对来说较优的结论。通过对比结果的分析可知,针对web应用场景处理季节型非平稳并发量时,通过本发明提出来的改进过滤型与装箱式特征选择算法进行特征选择后,建立的能耗模型所得到的数据更接近于真实值。在此基础上,通过五种回归分析模型的对比发现,幂回归、指数回归以及多项式回归在web应用中生成的能耗模型,比线性回归以及立方回归的准确性要高。最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明权利要求所限定的范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1