一种面向小语种语言的神经机器翻译方法与流程
本发明涉及神经机器翻译技术领域,特别涉及仅拥有小规模平行语料库的小语种语言的神经机器翻译方法。
背景技术:
机器翻译是自然语言处理的分支,是人工智能的目标之一。随着神经网络相关理论与技术的发展,机器翻译的相关研究从传统的基于统计的机器翻译逐渐转变到基于神经网络的机器翻译。神经机器翻译成为当下各学者研究的重点之一,在推动理论和技术发展的同时,对促进世界经济文化交流起到了重要作用。
神经机器翻译具有神经网络的部分特点,如:数据需求量大、计算性能需求高等特点,同时又具有自己独特的特点,如:平行语料准确性需求高、oov(outofvocabulary)问题、平行语料成本高、标注难等问题。
目前大量神经机器翻译的研究主要集中在有监督学习任务上,即利用由源语言和目标语言对构成的平行语料库来学习翻译模型,从而得到能够完成翻译任务的模型。但是,由于神经网络的特性,该学习过程需要大量的平行语料来完成,同时,需要大规模的神经网络模型来完成该任务,这也就意味着对硬件设备有着极高的要求。然而,这些特点对仅拥有小规模平行语料库的小语种语言之间的翻译是不适用的,大规模神经网络模型和小规模平行语料库会造成严重的欠拟合问题,同时由于小规模平行语料库与神经网络数据量的需求之间的矛盾,难以发挥神经网络在这种情况下的优势。
技术实现要素:
本发明所要解决的技术问题是:提供一种面向小语种语言的神经机器翻译方法,解决平行语料匮乏的情况下神经机器翻译的问题。
本发明解决上述技术问题采用的技术方案是:
一种面向小语种语言的神经机器翻译方法,包括通过以下步骤构建神经机器翻译模型以及进行训练:
步骤1、获取单语语料并进行预处理;
步骤2、利用单语语料分别训练源语言和目标语言的语言模型;
步骤3、利用小语种语言的平行语料库中的双语平行语料在源语言和目标语言的语言模型中的编码结果,分别训练用于将其中一种语言的编码结果映射到另一种语言空间中的映射器;
步骤4、利用单语语料训练鉴别器模型;
步骤5、利用语言模型、映射器、鉴别器模型、双语平行语料、单语语料训练翻译模型。
作为进一步优化,步骤1具体包括:
步骤1.1、利用爬虫工具爬取源语言和目标语言句子,并进行筛选,剔除长度超过阈值的句子,获得源语言和目标语言的单语语料;
步骤1.2、利用分词工具对源语言和目标语言的单语语料进行分词,并且使用bpe(双字节编码)技术结合word2vec技术学习词向量,然后利用词向量将源语言和目标语言的单语语料以及小语种语言的平行语料库中的双语平行语料的句子进行向量化。
作为进一步优化,步骤1.2中所述使用bpe技术结合word2vec技术学习词向量,包括:
首先利用bpe技术对分词后的单语语料进行处理,包括学习子词、创建训练集词表、应用训练集词表到验证集和测试集;然后利用word2vec中的skip-gram模式学习词向量。
作为进一步优化,步骤2具体包括:
步骤2.1、为源语言和目标语言句子添加噪声;
步骤2.2、利用transformer模型分别搭建源语言的语言模型和目标语言的语言模型;
步骤2.3、利用添加噪声后的源语言句子和未添加噪声的源语言句子构成源序列和目标序列,用于训练源语言的语言模型;利用添加噪声后的目标语言句子和未添加噪声的目标语言句子构成的源序列和目标语言序列,用于训练目标语言的语言模型;
步骤2.4、将小语种语言的平行语料库中的双语平行语料分别同步输入到源语言的语言模型和目标语言的语言模型中进行编码,两个语言模型的编码结果分别构成h1,h2两个序列,对(h1,h2)和(h2,h1)的集合进行保存。
作为进一步优化,步骤2.1中,为源语言和目标语言句子添加噪声的方式为:
按照一定概率删除或随机替换句子中的词,或者按照一定规则进行乱序。
作为进一步优化,步骤3具体包括:
步骤3.1、利用lstm(长短时记忆网络)搭建源->目标语言映射器和目标->源语言映射器,分别对应将源语言的语言模型的编码结果映射到目标语言空间及将目标语言的语言模型的编码结果映射到源语言空间;
步骤3.2、利用(h1,h2)和(h2,h1)分别对搭建的两个映射器进行训练,完成两个映射器的初始化。
作为进一步优化,步骤4具体包括:
步骤4.1、利用源语言的单语语料和目标语言的单语语料构建训练数据,其中,源语言的单语语料和目标语言的单语语料均包含未添加噪声和已添加噪声的句子;
步骤4.2、利用lstm搭建一个n:1型网络模型作为鉴别器模型;
步骤4.3、利用步骤4.1中的训练数据对鉴别器模型进行训练。
作为进一步优化,步骤5具体包括:
步骤5.1、搭建源->目标和目标->源两个翻译模型:
其中,源->目标翻译模型的编码器、解码器分别由源语言的语言模型的编码器和目标语言的语言模型的解码器来构建,源->目标语言映射器添加在源->目标语言翻译模型的编码器、解码器中间;
目标->源翻译模型的编码器、解码器分别由目标语言的语言模型的编码器和源语言的语言模型的解码器来构建,目标->源语言映射器添加在目标->源语言翻译模型的编码器、解码器中间;
步骤5.2、利用源->目标平行语料训练源->目标翻译模型,利用目标->源平行语料训练目标->源翻译模型,完成两个翻译模型的初始化;
步骤5.3、分别利用源语言和目标语言的单语语料,通过输入相应的翻译模型得到相应的输出,并且利用鉴别器为翻译模型添加相似度损失;
步骤5.4、利用步骤5.3中两个翻译模型中的其中一个模型的输入和输出构成语料对,作为另一个翻译模型的输入,利用另一个翻译模型进行回译。
本发明的有益效果是:
基于爬取获得的单语语料经过预处理后在语言模型的构建、鉴别器的构建以及翻译模型的回译过程中的应用,弥补了小语种语言的小规模平行语料库中语料不足的问题,并通过鉴别器和映射器学习不同语言的潜在语义空间,从而提升翻译效果。
附图说明
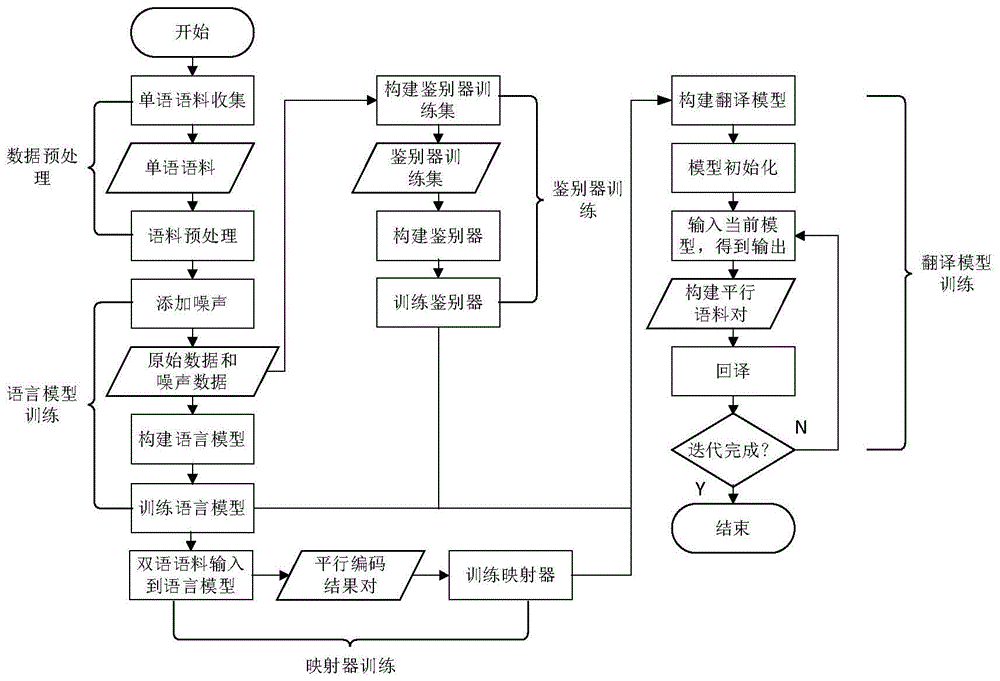
图1为实施例中的面向小语种语言的神经机器翻译方法流程图;
图2为实施例中的神经机器翻译模型的结构图。
具体实施方式
本发明旨在提供一种面向小语种语言的神经机器翻译方法,通过结合使用单语语料和平行语料,构建神经机器翻译模型,构造对应的训练算法来解决小语种语言神经机器翻译任务中的语料不足,翻译效果不佳的问题。
本发明中的面向小语种语言的神经机器翻译模型由语言模型(languagemodel),鉴别器(discriminator),翻译模型(translationmodel),映射器(mapper)组成,简称ldtm模型。实现方案主要包括数据预处理以及ldtm模型的训练。数据预处理主要是将数据进行数字化以及添加噪声。ldtm模型的训练包括了模型各个组成部分的训练。语言模型预训练则是通过构建降噪自编码器学习单语语言特征,鉴别器则是学习识别语种,在翻译模型的训练过程中通过提供损失函数来提升翻译质量,翻译模型的训练包括了初始化阶段和训练阶段,初始化利用小规模平行语料进行模型训练,训练阶段利用单语语料构建平行语料对训练翻译模型,映射器则主要用于将两种语言分别映射到另一种语言的语言空间中,用于提升翻译效果。
在具体实现上,本发明中的神经机器翻译方法,包括以下步骤:
步骤1、获取单语语料并进行预处理,包括步骤1.1-1.2:
步骤1.1、利用爬虫工具爬取源语言和目标语言句子,并进行筛选,剔除长度超过阈值的句子,获得源语言和目标语言的单语语料;
步骤1.2、利用分词工具对源语言和目标语言的单语语料进行分词,并且使用bpe(双字节编码)技术结合word2vec技术学习词向量,然后利用词向量将源语言和目标语言的单语语料以及小语种语言的平行语料库中的双语平行语料的句子进行向量化;
步骤2、利用单语语料分别训练源语言和目标语言的语言模型,
包括步骤2.1-2.4:
步骤2.1、为源语言和目标语言句子添加噪声;
步骤2.2、利用transformer模型分别搭建源语言的语言模型和目标语言的语言模型;
步骤2.3、利用添加噪声后的源语言句子和未添加噪声的源语言句子构成源序列和目标序列,用于训练源语言的语言模型;利用添加噪声后的目标语言句子和未添加噪声的目标语言句子构成的源序列和目标语言序列,用于训练目标语言的语言模型;
步骤2.4、将小语种语言的平行语料库中的双语平行语料分别同步输入到源语言的语言模型和目标语言的语言模型中进行编码,两个语言模型的编码结果分别构成h1,h2两个序列,对(h1,h2)和(h2,h1)的集合进行保存;
步骤3、利用小语种语言的平行语料库中的双语平行语料在源语言和目标语言的语言模型中的编码结果,分别训练用于将其中一种语言的编码结果映射到另一种语言空间中的映射器,包括步骤3.1-3.2:
步骤3.1、利用lstm(长短时记忆网络)搭建源->目标语言映射器和目标->源语言映射器,分别对应将源语言的语言模型的编码结果映射到目标语言空间及将目标语言的语言模型的编码结果映射到源语言空间;
步骤3.2、利用(h1,h2)和(h2,h1)分别对搭建的两个映射器进行训练,完成两个映射器的初始化;
步骤4、利用单语语料训练鉴别器模型,包括步骤4.1-4.3:
步骤4.1、利用源语言的单语语料和目标语言的单语语料构建训练数据,其中,源语言的单语语料和目标语言的单语语料均包含未添加噪声和已添加噪声的句子;
步骤4.2、利用lstm搭建一个n:1型网络模型作为鉴别器模型;
步骤4.3、利用步骤4.1中的训练数据对鉴别器模型进行训练;
步骤5、利用语言模型、映射器、鉴别器模型、双语平行语料、单语语料训练翻译模型:
步骤5.1、搭建源->目标和目标->源两个翻译模型,包括步骤5.1-5.4:
其中,源->目标翻译模型的编码器、解码器分别由源语言的语言模型的编码器和目标语言的语言模型的解码器来构建,源->目标语言映射器添加在源->目标语言翻译模型的编码器、解码器中间;
目标->源翻译模型的编码器、解码器分别由目标语言的语言模型的编码器和源语言的语言模型的解码器来构建,目标->源语言映射器添加在目标->源语言翻译模型的编码器、解码器中间;
步骤5.2、利用源->目标平行语料训练源->目标翻译模型,利用目标->源平行语料训练目标->源翻译模型,完成两个翻译模型的初始化;
步骤5.3、分别利用源语言和目标语言的单语语料,通过输入相应的翻译模型得到相应的输出,并且利用鉴别器为翻译模型添加相似度损失;
步骤5.4、利用步骤5.3中两个翻译模型中的其中一个模型的输入和输出构成语料对,作为另一个翻译模型的输入,利用另一个翻译模型进行回译。
实施例:
本实施例中的神经机器翻译模型的整体结构包括了语言模型、映射器、鉴别器、翻译模型四个部分,如图2所示。模型的实现流程如图1所示,主要包括了5个部分,分别是数据预处理、语言模型训练、映射器初始化、鉴别器训练、翻译模型训练。
1、数据预处理主要包括了单语语料的收集和数据预处理。具体来讲:
1.1从互联网上收集大量源语言和目标语言两种语言的单语语料,可以采用爬虫爬取相关网站获得;
1.2对小规模平行语料库以及单语语料库进行预处理,具体来讲包括:
1.2.1分词:对源语言和目标语言句子进行分词处理;
1.2.2利用bpe技术处理训练语料库,包括了两种语言的单语语料库以及平行语料,处理包括学习子词、创建训练集词表、应用训练集词表到验证集和测试集等步骤;
1.2.3利用word2vec中的skip-gram模式学习词向量;
1.2.4将词向量运用到语料上,得到句子的向量化表示。
2、在数据收集与预处理完成后,将利用预处理后的语料训练两种语言的语言模型:
2.1双语语料和单语语料添加噪声,具体添加噪声的方式分为三种:
(1)以下式的概率删除一个词:
pwd=0.1
(2)按照下式规则进行乱序:
|σ(i)-i|≤k
其中,σ(i)是指第i个单词偏移后的位置。所以,上式指的是一个单词最多偏离原来位置k个单词的距离,k设为3;
(3)按照0.1的概率将单词替换为词表中的其他任意单词。
2.2利用transformer分别搭建源语言和目标语言的语言模型,构成降噪自编码器,结构如图2语言模型所示;
2.3利用添加噪声的语料和未添加噪声的语料训练语言模型,利用下文中语言模型的训练算法进行训练,损失函数定义如下:
llm=ex~s[-logps->s(x|c(x))]+ey~t[-logpt->t(y|c(y))]
s和t分别代表源语言和目标语言;
优化算法选用adam算法,学习率从集合{0.1,0.01,0.001,0.0001}中选择,过大会造成学习过程中损失函数出现震荡情况,难以收敛,过小则会增加学习时间,最后选择学习率为0.001,β1=0.9,β2=0.999,ε=1e-8,batch大小设置为32,pdropout=0.1。
3、语言模型训练完成后,进行映射器的初始化,该过程主要利用两个语言模型编码器结果构建数据,这个阶段包括:
3.1将小规模平行语料分别输入到两个语言模型中,得到对应的编码结果,假设源语言和目标语言的一组平行语句对分别编码结果为h1和h2,那么分别构建(h1,h2),(h2,h1)的数据集合;
3.2利用lstm搭建两个映射器,映射器的本质是一个seq2seq模型,也分为了编码器与解码器两个部分,这里将其看作一个整体,目的是将一种语言的编码结果序列映射为另一种语言编码结果序列;
3.3利用(h1,h2)训练源->目标映射器,利用(h2,h1)训练目标->源映射器,完成映射器的初始化,损失函数定义如下:
初始化采用梯度下降算法,两个映射器同时训练,同样的,为了防止训练速度过慢或者损失震荡的结果,学习率选取0.01,batch大小设置为32。
4、鉴别器模型的训练与映射器的训练可以同步进行,具体包括:
4.1利用未添加噪声的语料和添加了噪声的语料构成训练集,源语言句子标签为0,目标语言句子标签为1;
4.2利用bilstm搭建鉴别器,其本质是一个处理序列的分类器,结构如图2中鉴别器所示;
4.3训练鉴别器,损失函数利用交叉熵:
训练采用adam算法进行优化。
5、在完成语言模型和鉴别器的训练以后,我们将按照图2中翻译模型的结构搭建翻译模型,具体来讲:
5.1搭建翻译模型:
编码器由语言模型的编码器组成,由于同时需要搭建两个翻译模型用于回译,所以将两个语言模型的编码器和解码器拆分并重组,两个翻译模型的编码器即为语言模型的编码器,以源到目标语言的翻译模型为例,翻译模型中编码器编码得到的隐层状态h1的计算过程按照下式进行:
h1=encoderlm(x)
其中encoderlm是语言模型的编码器;
编码器后面接着一个映射器,用于将输入语言的编码结果映射到输出语言的编码结果空间中,如下式所示:
h2=mapper(h1)
解码器则是利用语言模型的解码器搭建,源->目标翻译模型的解码器是目标语言语言模型的解码器,目标->源翻译模型的解码器是源语言语言模型的解码器。在整个训练过程中解码器参数不变,这样是为了保存解码器解码成符合语言表达的句子的能力。由于transformer结构中解码器本身带有了注意力机制,所以解码器不需要再添加注意力机制。解码过程如下:
(1)获得编码器状态;
(2)利用映射器映射编码结果;
(3)计算注意力机制
其中st-1是解码器上个时刻的状态,h={h1,h2,...,hm},αt,i是t时刻hi隐层状态的系数,并且αt,i满足:
αt,j的计算过程如下,其中et,i是将st-1和hi通过神经网络求得的。
(4)解码:
st=f(st-1,yt-1,ct)
q=g(yt-1,ct,st)
最后一个式子中q就是最后的解码得到的张量。解码器最终的解码过程为:
p(yt|y<t,x)=softmax(q)
5.2初始化则是利用小规模语料库训练两个翻译模型,利用源->目标(目标->源)平行语料训练源->目标(目标->源)翻译模型,完成两个模型的初始化,损失函数如下,优化算法采用adam,在整个训练过程中,解码器参数不变。
linit=e[-logps->t(y|x)]+e[-logpt->s(x|y)]
其中e[-logps->t(y|x)]+e[-logpt->s(x|y)]是输入与输出的交叉熵损失。
5.3回译过程:利用单语语料迭代训练整个翻译模型。该过程中添加了鉴别器损失函数,用于提升翻译质量,鉴别器损失函数如下:
回译过程中模型损失函数如下:
lback=ey~t[-logps->t(y|u*(y))]+ex~s[-logpt->s(x|v*(x))]
利用单语语料训练翻译模型损失函数如下:
ltotal=λbacklback+λdisldis
其中λ为系数,两者都取0.5。训练优化算法同样采用adam算法。
本发明中的神经机器翻译模型的各个部分的训练算法如下:
语言模型:
(1)训练集添加噪声:
(2)利用
映射器:
(1)双语语料分别输入到ps->s,pt->t中,并得到编码结果h1,h2
(2)构建(h1,h2),(h2,h1)数据对训练映射器mapper1,mapper2,完成初始化
鉴别器:
(1)构建训练集
(2)利用
(3)固定参数
翻译模型:
(1)构建编码器-映射器-解码器结构的两个翻译模型ps->t,pt->s;
(2)利用语言模型ps->s,pt->t对翻译模型ps->t,pt->s的encoder,decoder赋初始参数,解码器参数在整个训练过程中保持不变:
θ(ps->t.encoder)=θ(ps->s.encoder),θ(ps->t.decoder)=θ(pt->t.decoder);
θ(pt->s.encoder)=θ(pt->t.encoder),θ(pt->s.decoder)=θ(ps->s.decoder);
(3)翻译模型初始化:利用小规模平行语料或者利用单语语料学习的双语词典学习
(4)fork=1tondo
(5)back-translation:
(6)利用当前翻译模型
(7)v*(x),u*(y)分别添加噪声
(8)利用(u*(y),y),(v*(x),x)分别训练得到
(9)end.
- 还没有人留言评论。精彩留言会获得点赞!