一种基于聚类和K2-tree的大规模图数据表示方法与流程
本发明涉及图数据技术领域,具体涉及一种基于聚类和k2-tree的大规模图数据表示方法。
背景技术:
图作为表示数据之间关系的基本结构,在web网络分析,生物数据分析,社会团体分析等领域有着广泛应用。传统的图数据表示方法主要分为邻接矩阵和邻接表。根据gloabalweb统计,2019年facebook的用户量已经超过300亿,平均每个人的好友超过300位,若采用邻接表来存储,需要接近4tb的空间。根据cnnic统计,2019年中国网页的数量已经达到2816亿个,超链接的数量估计超过1016,若采用邻接表来存储,需要1*106tb的空间。为了支持快速的查询,通常将整个邻接表加载到内存中,但是在实际情况下,这会面临存储空间过大的问题,同时随着用户量的快速增长,图数据的存储问题也只会变得越来越严峻。可见,随着图数据的不断产生和累积,传统的图数据表示方法已经不能支持上百万个节点和边的图的存储和操作。
为了解决大规模图数据的表示问题,研究者提出了k2-tree和k2-bdc大规模图数据表示方法。然而,这两种大规模图数据表示方法,分别存在以下缺陷:
k2-tree机械式的划分邻接矩阵,不考虑邻接矩阵的内部结构,这将导致邻接矩阵中的稠密区域被分割,额外增加存储开销。此外,k2-tree的节点邻居查询时间跟图顶点的数目成正比,针对于上百万个节点和边的图数据,查询时间需要进一步的改善。
k2-bdc仅仅考虑沿着主对角线划分邻接矩阵,远离对角线外的稠密区域不能很好的捕获。此外,k2-bdc采用dac编码技术来进一步压缩k2-tree对应的t向量和l向量,这可能会增加节点邻居查询时间。再者,k2-bdc不能方便的压缩其他类型的图数据,其方法仅仅考虑主对角线上的分布,没有实现真正的聚类。
技术实现要素:
本发明所要解决的是现有k2-tree和k2-bdc在表示大规模图数据的不足,提供一种基于聚类和k2-tree的大规模图数据表示方法。
为解决上述问题,本发明是通过以下技术方案实现的:
一种基于聚类和k2-tree的大规模图数据表示方法,具体包括如下步骤:
步骤1、先将图数据转化为邻接矩阵表示,再将邻接矩阵划分成n2/k2个网格;
步骤2、统计每个网格的密度,并将密度大于预设网格密度阈值的网格纳入到网格记录表中;
步骤3、对于网格记录表中的每一个网格,计算当前网格和其它网格之间的距离:将与当前网格的距离大于预设距离阈值的网格,直接放入到簇记录表中;将与当前网格的距离小于等于预设距离阈值的所有网格,与当前网格进行合并形成新的网格后,放入到簇记录表中;
步骤4、对于簇记录表的每一个网格,计算当前网格和其它网格之间的距离,并将与当前网格的距离小于等于预设距离阈值的所有网格,与当前网格进行合并形成新的网格,以此更新簇记录表;
步骤5、递归重复步骤4的网格合并过程,直至簇记录表中的网格无法再合并;此时,将簇记录表中每个网格的位置即起始行、终止行、起始列和终止列形成一条记录,保存在边界表中;
步骤6、将簇记录表中的每个网格转化为k2-tree表示,由此完成图数据的表示;
上述n为图节点的个数,k为设定的划分参数。
上述步骤6的具体过程如下:
步骤6.1、对于簇记录表中的每个网格,计算当前网格的边长s:
若当前网格的边长s不等于k的幂,则先增加当前网格的行和列使得当前网格的边长s等于k的幂,其中增加的行和列的元素用0进行填充,再将网格划分成s2/k2个大小相同的子矩阵;
若当前网格的边长s等于k的幂,则直接将当前网格划分成s2/k2个大小相同的子矩阵;
步骤6.2、先将元素中至少有一个为1的子矩阵标记为1,将元素中全为0的子矩阵标记为0;再按照子矩阵自上而下,自左而右的顺序排列上述标记值,以形成k2-tree的第一层节点;
步骤6.3、对标记为1的子矩阵,先进一步划分成s2/k2个大小相同的子矩阵;再将元素中至少有一个为1的子矩阵标记为1,将元素中全为0的子矩阵标记为0;后按照子矩阵自上而下,自左而右的顺序排列上述标记值,以形成k2-tree的下一层节点;
步骤6.4、递归重复步骤6.3的子矩阵划分,并形成k2-tree各层节点的过程,直到子矩阵全为0或者已经划分到单个元素为止,由此而得到当前网格的k2-tree表示;
上述k为设定的划分参数。
上述步骤6之后,还进一步包括查询给定节点的直接邻居的过程:对于行编号为number-line的给定节点,首先查询边界表中的每一条记录的起始行start-line和终止行end-line,并找出所有start-line≤number-line并且end-line≥number-line的所有记录;接着在簇记录表中,选出上述所找出的记录所对应的网格的k2-tree;最后对每个k2-tree均调用k2-tree的查询算法,由此得到行编号为number-line的给定节点的所有直接邻居。
上述步骤6之后,还进一步包括查询给定节点的反向邻居的过程:对于列编号为number-column的给定节点,首先查询边界表中的每一条记录的起始列start-column和终止列end-column,并找出所有start-column≤number-column并且end-column≥number-column的所有记录;接着在簇记录表中,选出上述所找出的记录所对应的网格的k2-tree;最后对每个k2-tree均调用k2-tree的查询算法,由此得到列编号为number-column的给定节点的所有反向邻居。
与现有技术相比,本发明提出了一种基于聚类和k2-tree的大规模图数据表示办法,其先采用了网格聚类算法充分的邻接矩阵中的稠密区域,从而使得大量的1值被包含在稠密区域中。相比于原始邻接矩阵,每个稠密区域的边长大大降低,减少了k2-tree查询操作中从顶层到叶子节点需要的递归次数,增加了存储空间利用率。在处理上百万个节点和边的图数据时,本方法能够对其高效紧凑准确的表示,并且还能支持节点邻居查询操作。
附图说明
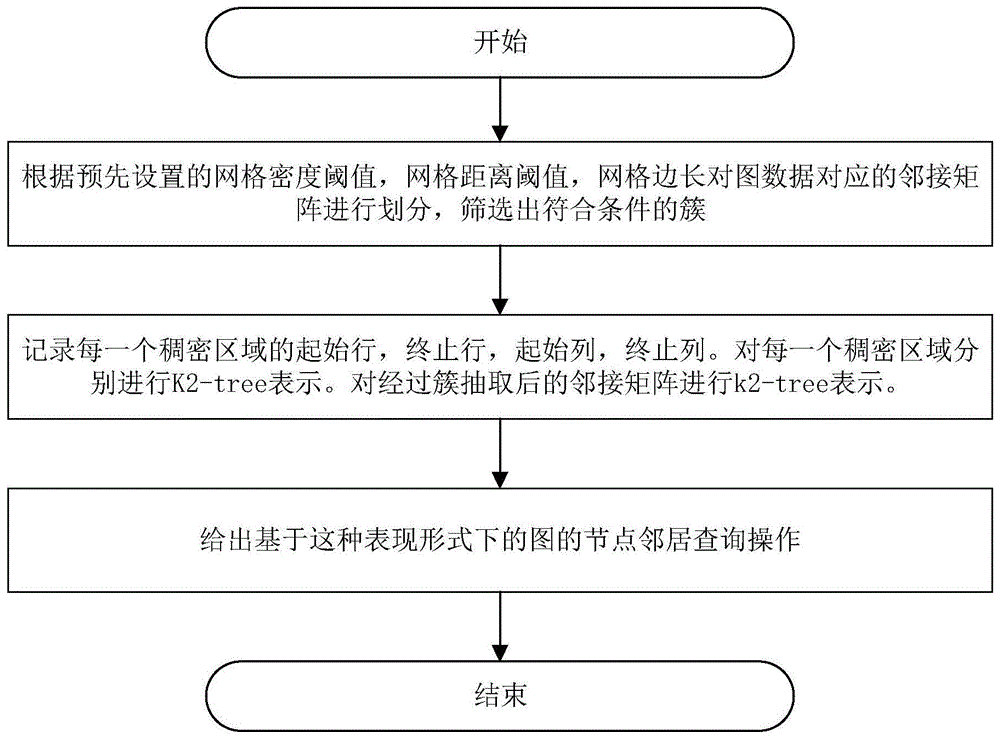
图1是一种大规模图数据表示方法的流程图。
图2是图g1对应的邻接矩阵。
图3是经过网格聚类处理后的图g1邻接矩阵,其中灰色的部分为稠密区域。
图4是对经过网格聚类处理后的邻接矩阵的k2-tree表示,其中(a)为cluster[0]的k2-tree表示,(b)为cluster[1]的k2-tree表示,(c)为cluster[2]的k2-tree表示,(d)为cluster[3]的k2-tree表示,(e)为cluster[4]的k2-tree表示。
图5是传统的k2-tree表示。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实例,对本发明进一步详细说明。需要说明的是,实例中提到的方向用语,例如“上”、“下”、“中”、“左”“右”、“前”、“后”等,仅是参考附图的方向。因此,使用的方向仅是用来说明并非用来限制本发明的保护范围。
一种基于聚类和k2-tree的大规模图数据表示方法,如图1所示,其具体包括如下步骤:
步骤1:以充分的挖掘邻接矩阵中的稠密区域(注:这里指的稠密区域是相对于整个整个邻接矩阵而言,是相对稠密的,实际上是比较稀疏的),将图对应的邻接矩阵划分成若干个满足密度阈值的网格(这统称为簇)。
步骤1.1:对于一个具有n个节点,m条边的图数据,将图转化为邻接矩阵表示。
步骤1.2:将邻接矩阵划分成n2/k2个网格,对于每一个网格,统计每个网格的密度。其中n为图节点的个数,k为设定的划分参数,在本实施例中,k一般取2。
步骤1.3:依次遍历每一个网格,若其对应的网格的密度density大于预先设置的网格密度阈值,则将其纳入到满足密度阈值的网格记录表list中。
步骤1.4:根据预先设置的距离阈值,遍历list中的每一个网格,计算出当前网格和其它网格之间的距离:
若距离小于等于距离阈值,则将这些满足距离阈值的网格合并,将当前网格和这些满足距离阈值的网格标记为已访问,统计合并后的大网格的密度;
若密度大于网格密度阈值,则将其纳入到簇记录表cluster中,重复步骤1.4,直到list中的每一个网格都已经被访问。
步骤1.5:根据簇记录表cluster中的划分结果,重复步骤1.4的网格合并过程,直到簇记录表cluster中的元素不再改变。此时簇记录表cluster记录了邻接矩阵中每一个稠密区间(大网格)的位置,聚类算法结束。
步骤2:对于cluster中的每一个大网格(即簇),用全局的边界表boundary记录下每一个簇的起始行,终止行,起始列和终止列,直到cluster中每一个稠密区间都已经被记录。
步骤3:将簇和经过簇抽取后的邻接矩阵用k2-tree紧凑表示,保存簇和经过簇抽取后的邻接矩阵所对应的t向量和l向量。
步骤3.1:对于cluster中的每一个大网格,计算该大网格的边长为s。
若s不等于k(这里k=2)的幂,增加该网格的行和列使得s=kn,其中增加的行和列的元素用“0”填充,再将网格划分成s2/k2个大小相同的子矩阵。
若s等于k的幂,将网格划分成s2/k2个大小相同的子矩阵。
步骤3.2:如果子矩阵中的元素至少有一个为1,那么把这种矩阵标记为1,否则标记为0,自上而下,自左而右排列这些值,它们将作为根节点的四个孩子,k2-tree的第一层节点构造完毕。
步骤3.3:将标记为1的矩阵再进行递归处理,先进一步划分成s2/k2个大小相同的子矩阵;再将元素中至少有一个为1的子矩阵标记为1,将元素中全为0的子矩阵标记为0;后按照子矩阵自上而下,自左而右的顺序排列上述标记值,它们的值将作为k2-tree的第二层节点;
步骤3.4:如此重复直步骤3.3,直到划分后的子矩阵全部为0或者已经划分到原始邻接矩阵中的某个元素,递归停止。第一个网格所对应的k2-tree表示完成,将该网格标记为已访问。
步骤3.5:重复步骤3.1-3.4,直到cluster中的每一个元素都已经被访问,由此得到经过簇抽离后的邻接矩阵进行k2-tree紧凑表示,以及该k2-tree的t向量和l向量,其中t向量为k2-tree中除最后一层节点外的其余节点,l向量是k2-tree的最后一层节点。
对上述所得到的大规模图数据表示的应用均基于以下两个查询为前提,即直接邻居节点查询和反向邻居节点查询:
(1)直接邻居节点查询
当利用对上述所得到的大规模图数据表示来进行直接邻居节点查询时,首先查询boundary表中的起始行和终止行,将节点映射到每一个簇所对应的的k2-tree中,然后对满足条件的k2-tree进行自顶而下的遍历,依次返回直接邻居节点。其具体步骤如下:
步骤4.1:设待查询的节点的行编号为number-line,生成一个空的直接邻居队列queue-line,遍历边界表boundary中每一个记录的起始行start-line和终止行end-line。如果number-line>=start-line并且number-line<=end-line,转到步骤4.2,否则不访问该记录,重复步骤4.1。
步骤4.2:在簇记录表cluster中的找到该记录对应的k2-tree,调用k2-tree的查询算法(查询过程中会用到t向量和l向量,此为现有技术,不再赘述),若在该k2-tree中存在该节点的直接邻居,将其纳入到queue-line中。
步骤4.3:返回最终的queue-line,该queue-line中的元素为节点行编号为number-line的直接邻居。
(2)反向邻居节点查询
当利用对上述所得到的大规模图数据表示来进行反向邻居节点查询时,首先查询boundary表中的起始列和终止列,将节点映射到每一个簇所对应的的k2-tree中,然后对满足条件的k2-tree进行自顶而下的遍历,依次返回反向邻居节点。其具体步骤如下:
步骤4.1:设待查询的节点的列编号为number-column,生成一个空的反向邻居队列queue-column,遍历边界表boundary中每一个记录的起始列start-column和终止列end-column。如果number-column>=start-column并且number-column<=end-column,转到步骤4.2,否则不访问该记录,重复步骤4.1。
步骤4.2:在簇记录表cluster中的找到该记录对应的k2-tree,调用k2-tree的查询算法(查询过程中会用到t向量和l向量,此为现有技术,不再赘述),若在该k2-tree中存在该节点的反向邻居,将其纳入到queue-column中。
步骤4.3:返回最终的queue-column,该queue-column中的元素为节点列编号为number-column的反向邻居。
为了更加直观的描述本发明,下面通过一个具体实例对其进行进一步说明:
s1、对于给定了一个具有16个节点,17条边的图g1,先用邻接矩阵描述图的结构信息,如图2所示。
s2、根据设定的网格密度阈值density-threshold设置为0.25,距离阈值distance-threshold设置为1,网格的划分参数设置为k=2,将邻接矩阵划分为64个大小相同的网格。
s3、根据预先设置的密度阈值,将筛选出的符合密度阈值的网格纳入到记录表list中,list=((1,2),(1,3),(2,2),(2,6),(2,7),(3,7),(4,4),(5,4),(5,5),(6,2),(7,4),(8,6))。根据预先设置的距离阈值,依次遍历list中的每一个网格,计算当前网格和其它网格之前的距离,将距离小于等于1的网格划分合并重组,纳入到簇记录表cluster中。此时,cluster[0]=(1,2),(1,3),(2,2)),cluster[1]=((2,6),(2,7),(3,7)),cluster[2]=((4,4),(5,4),(5,5)),cluster[3]=((6,2),(7,4)),cluster[4]=((8,6))。
s4、依次遍历cluster中的每一个网格,计算每一个当前网格cluster[i]和其他网格cluster[j]的距离,j≠i。若距离小于等于1,则更新cluster,直到cluster不在改变。此时,cluster[0]=(1,2),(1,3),(2,2)),cluster[1]=((2,6),(2,7),(3,7)),cluster[2]=((4,4,(5,4),(5,5)),cluster[3]=((6,2),(7,4)),cluster[4]=((8,6))。经过聚类处理后的图g1邻接矩阵,如图3所示。
s5、用边界表boundary记录下每个网格cluster[i]的起始行,终止行,起始列,终止列。此时boundary=((1,2,2,3),(2,3,6,7),(4,5,4,5),(6,7,2,3),(8,8,6,6))。
s6、对于簇记录表cluster中的每一个网格cluster[i],分别用k2-tree进行紧凑表示,如图4所示。
对于上述所给定图g1采用传统的k2-tree表示时,如图5所示,其t和l向量的总和为112bit,而采用我们的方法只需要65bit,对于boundary所占的存储空间,在处理上百万个节点和边的网页图时,基本可以忽略不计。当需要查询节点9的直接邻居时,我们查询boundary表,得出它的邻居位于第三个簇中,然后再到第三个簇中查询对应的k2-tree,就能够得到。由此可见,我们的方法不仅在存储空间上节省了42%,而且k2-tree的高度也得以降低,因此查询时间也会减少。
综上所述,在本发明实施例提供的大规模图数据表示方法中,与传统的k2-tree压缩机制相比。该方法能充分的挖掘邻接矩阵中任意位置的稠密区域,一方面能够有效的降低存储空间开销,另一方面也能够降低节点邻居查询时间。随着图数据的不断产生和积累,本方法能够对未来大规模图数据表示办法提供一种新的思路。
需要说明的是,尽管以上本发明所述的实施例是说明性的,但这并非是对本发明的限制,因此本发明并不局限于上述具体实施方式中。在不脱离本发明原理的情况下,凡是本领域技术人员在本发明的启示下获得的其它实施方式,均视为在本发明的保护之内。
- 还没有人留言评论。精彩留言会获得点赞!