一种知识图谱构建方法与流程
本发明涉及自然语言处理技术领域,更具体地,涉及一种知识图谱构建方法。
背景技术:
自然语言是指汉语、英语、法语等人们日常使用的语言,是自然而然的随着人类社会发展演变而来的语言,而不是人造的语言,它是人类学习生活的重要工具。概括说来,自然语言是指人类社会约定俗成的,区别于人工语言,如程序设计的语言。
自然语言处理(naturallanguageprocessing,nlp),是指用计算机对自然语言的形、音、义等信息进行处理,即对字、词、句、篇章的输入、输出、识别、分析、理解、生成等的操作和加工。自然语言处理的具体表现形式包括机器翻译、文本摘要、文本分类、文本校对、信息抽取、语音合成、语音识别等。可以说,自然语言处理就是要计算机理解自然语言,自然语言处理机制涉及两个流程,包括自然语言理解和自然语言生成。
当今社会,随着信息技术的发展与互联网的普及,大数据、云计算、人工智能已成为当前学术界的热点课题。自然语言处理是人工智能中最为困难的问题之一,如何实现人机间的信息交流,智能地筛选、处理海量的数据是人工智能界、计算机科学和语言学界的技术突破重点。因为人类语言有其特殊性、复杂性,使机器理解人类语言是一项艰巨的任务。尤其在自然语言处理的领域里,机器理解中文远比理解英文复杂的多。因此,如何使机器更好地解析中文,处理中文已成为了人工智能领域中无法绕开的难题。
知识图谱是一种以自然语言处理(nlp)为中心,结合应用数学、图形学、信息可视化的多种技术的知识组织形式和规范。在知识图谱里,每个节点表示现实世界中存在的“实体”,每条边为实体与实体之间的“关系”。知识图谱是关系的最有效的表示方式。实体通常指的是文本中具有特别意义或者指代性非常强的名词短语或者动词短语,通常包括人名、地名、机构名、时间、专有名词等。通俗地讲,知识图谱就是把所有不同种类的信息(heterogeneousinformation)连接在一起而得到的一个关系网络。知识图谱提供了从“关系”的角度去分析问题的能力。近来知识图谱在人工智能很多行业拥有成熟的应用,如搜索引擎、聊天机器人、智能医疗、智能硬件等。尽管知识图谱的应用如此广阔,但是当前的知识图谱构建方法并不成熟,仍存在需要人工构建、数据质量不高的缺点。因此,目前亟需一种构建更高质量知识图谱的方法。
技术实现要素:
为了解决上述问题,本发明提供一种知识图谱构建方法,该方法可构建更高质量知识图谱。
本发明采取的技术方案是:
一种知识图谱构建方法,所述方法包括:
步骤s1:获取语料集;
步骤s2:对语料集进行预处理;
步骤s3:转化语料集并存入数据库;
步骤s4:根据数据库构建知识图谱。
语料集即语言材料的集合,语料是构成语料库的基本单元,为文本形式。本方案的语料从网上获取,具体获取方式为:选取目标网页,把网页定义为document格式,将所有的数据转化为文本,之后对转化为文本的网页进行遍历,获取里面所有的文本数据,最后建立元素组集element存储获取到的所有文本数据。转化为文本的网页不仅包含文字内容,还包含html的标签、注释等,而标签包含文字样式等信息。为了后续读取解析工作方便,元素组把html内容与html标签分开存储。获取语料集之后,将其进行预处理,使其的噪音减少。由于三元组对于数据库存储性能高,因此把预处理后的语料集转化为三元组,然后,存入数据库。最后根据数据库所存的数据构建知识图谱。本方案与现有的知识图谱构建方法相比,构建出来的知识图谱的质量更高。
进一步地,所述步骤s2包括:
步骤s2.1:对语料集进行清洗;
步骤s2.2:使用分词工具对清洗后的语料集进行分词;
步骤s2.3:对分词后的语料集进行词性标注;
步骤s2.4:通过依存句法分析器对词性标注后的语料集进行解析;
步骤s2.5:从解析后的语料集中提取名词短语,建立名词短语集。
在本方案中,对语料集进行清洗包括删除清洗和正则表达式匹配清洗。获取到语料集后,因为语料集中必定含有不需要的信息,因此必须先进行过滤,把无用的内容,如:广告、无用链接、html注释等无用内容的删除;编写描述关键词的正则表达式,将删除清洗后的语料集与正则表达式进行匹配,过滤掉与正则表达式不相符的部分。将有用的内容文本提取出来后,选取适用的标注集,例如:政策性文本,选取人民日报标注语料库。使用分词工具根据其字、词的含义进行分词,然后给每个词打上相应的词性标签。根据词性对语料集进行句法分析,句法分析能识别句子中所包含的句法成分以及这些成分之间的关系,联系上下文对句子进行更深层次的理解,消除词语之间的歧义,使信息错误率更低。本方案的句法分析为依存句法分析,其形式简洁,便于应用;因为没有采用基于标注数据集的深度学习方法,而是在传统的无监督学习方法的基础上进行训练,所以无需大量的人工数据标注,不仅高效快捷,还避免了标注数据集质量差而导致的误差,节省大量的人力财力。最后,从依存句法分析器解析完的语料集中准确地从提取名词短语,建立名词短语集。
进一步地,所述步骤s2.5提取名词短语的方式包括:
(1)根据短语中的定中关系结构提取;
(2)提取非定中关系下的有一定长度的名词。
具体地,(1)短语中的定中关系常用来描述汉语中动-名复合词汇,其定语可以从数量、领属、范围、特征、质料对中心语做出限定,构成限制性定语,描述性定语等等定中短语,根据句法解析的结果,将定中关系的词语进行组合则能还原其短语语义。由于定中短语词与词之间存在组合先后顺序,在本方案中还使用了二分插入的方法对其id进行搜索和插入,提高了提取速度的同时保证了短语的完整性。(2)因为分词工具有时候能够直接将识别比较长的名词短语识别成名词或者专有名词,所以是对(1)的补充。
进一步地,所述步骤s3包括:所述语料集转化为三元组,三元组(field,predicate,value);
其中field为数据列名,value为field对应的值,predicate为field与value之间的关系;
所述value包括数字类、地址类、名词性类。
上述的方法从语料集中提取了所有可能的名词短语,然而不可能所有的名词短语都属于实体。因此,需要对得到的名词短语集进行进一步的筛选才能存入数据库。本方案采用的筛选方法是种子库模板的方法。具体过程为:构建一个数据库,数据库中数据以三元组的方式存储,数据库已有的数据作为模板集,将语料集也转化为三元组,然后与模板集进行匹配,若是通过匹配,则存入数据库。
进一步地,所述field的获取过程包括:
步骤s3.11:获取数据库已有的数据集,作为短语模板集,利用bert预训练的语言模型将短语模板集转为句向量;
步骤s3.12:利用bert预训练的语言模型将名词短语集转为句向量;
步骤s3.13:计算短语模板集与名词短语集两个数据集短语之间的距离;
步骤s3.14:若相似度满足一定阈值则名词短语集的短语归为短语模板集的短语一类;
所述相似度的计算公式如下:
其中,ssimilar表示两个短语的相似度,余弦值的范围为[-1,1],vec1与vec2为bert模型中倒数第二层的输出,共768维向量。
进一步地,所述value的获取过程包括:
步骤s3.21:数字类的识别;
通过依存句法分析器对句子进行句法分析,分析每个词的词性是否属于量词和数词以及它们之间的字数距离,识别出是否属于数字类;
步骤s3.22:地址类的识别;
通过分词和实体标注对语料集进行训练,训练的模型采用基于字的bilstm-crf模型;
步骤s3.23:名词性类的识别;
利用bert预训练的语言模型将短语模板集、名词短语集转为句向量;
计算短语模板集与名词短语集两个数据集短语之间的距离,若短语模板集的任意一列中存在一个满足阈值的词,则将当前名词短语集的短语归为短语模板集当前列的短语一类。
因为数据库中的值不一定都是以名词短语的形式存在,也会有句子的存在。所以同样需要对其内容进行名词短语的抽取。在value的获取过程中,数据库中的短语模板集是符合实体要求的,然而由于数据库中的内容较多,造成噪声较多的存在。因此需要对其进行一次聚类筛选,以剔除无关的名词短语。同属一类的大多数名词短语语义上应该会比较接近以反映出该列的信息,同时存在噪声数据,并且噪声词之间不一定会相似。以数据库中的某一列获取的名词短语集为例,采用了计数的方法,记录每个名词短语与其他名词短语相似的个数,以剔除一些个数较少的名词短语。
进一步地,所述数字类、地址类、名词性类之间的关系类别包括:大于、小于、位于、是、否;所述关系类别具有关系约束为:大于、小于只用于描述数字类的关系约束;位于用于描述地址类;是、否用于描述剩下的类别。
具体地,三元组内为实体,实体之间的关系为:大于、小于、位于、是、否。其中实体value分为三类实体:数字类、地址类、名词类;这三类实体之间的关系类别存在关系约束:大于、小于只用于描述数字类的关系约束;位于用于描述地址类;是、否用于描述剩下的类别。
进一步地,所述数字类、地址类、名词性类具有模板词汇,所述模板词汇用于描述其关系类别,识别关系类别的过程为:
(1)定义关系类别及其对应的关系约束;
(2)定义关系类别对应的模板词汇;
(3)保证关系约束的前提下,通过模板词汇对名词短语进行检查和判断,如果不满足或无法识别,将其归为一个新的大类。
(4)具有反义的词汇,作为新的一类进行处理。
首先,定义实体之间的关系类别,并给关系类别加上关系约束。然后定义描述关系类别的模板词汇,最后在保证实体的关系类别符合关系约束的前提下,通过模板词汇识别实体的关系类别,若模板词汇无法识别实体的关系类别,把其归为一个新的大类,若存在“不大于”,“不小于”这类表达反义的词汇也需要额外作为新的一类进行处理,使用模板词汇识别关系类别不仅识别的准确率大大提升,所使用的模板词汇的定义还提供外部配置的方法,可以快速灵活的修改和配置。在未来性能变差的情况下,可以对其进行添加和删除,便于提高准确率,保证了算法的健壮性和可拓展性。
进一步地,所述三元组之间具有组间关系约束,所述组间关系约束可通过构建分类模型判别,所述分类模型的判别类型为and和or,and类定义为1,or类定义为0。
进一步地,所述分类模型的交叉熵损失函数为:
j=-[yglog(p)+(1-y)glog(1-p)]
其中,y表示样本的label,p表示样本预测为正的概率。
具体地,一个句子可以抽取不止一个三元组,若要进一步描述这些三元组之间的关系,以充分还原该句子的语义,需要构建一个分类模型,此模型用于判别三元组之间的关系,由于关系的类别仅仅为“and”’和“or”,数量较少,所以此模型可以取得不错的效果。
与现有技术相比,本发明的有益效果为:
(1)基于无监督学习的基础上进行实体提取与标注,避免了标注数据集质量差而导致的误差,构建出来的知识图谱的质量更高。
(2)分词与词性标注无需人工标注,节省了大量的人力财力。
(3)模板词汇为外部配置,可快速灵活的修改和配置,增强了算法的通用性和健壮性。
附图说明
图1为本发明的系统需求图;
图2为本发明的句法分析图;
图3为本发明的图谱可视化图。
具体实施方式
本发明附图仅用于示例性说明,不能理解为对本发明的限制。为了更好说明以下实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
实施例
本实施例提供一种知识图谱构建方法,所述方法包括:
步骤s1:获取语料集;
步骤s2:对语料集进行预处理;
步骤s3:转化语料集并存入数据库;
步骤s4:根据数据库构建知识图谱。
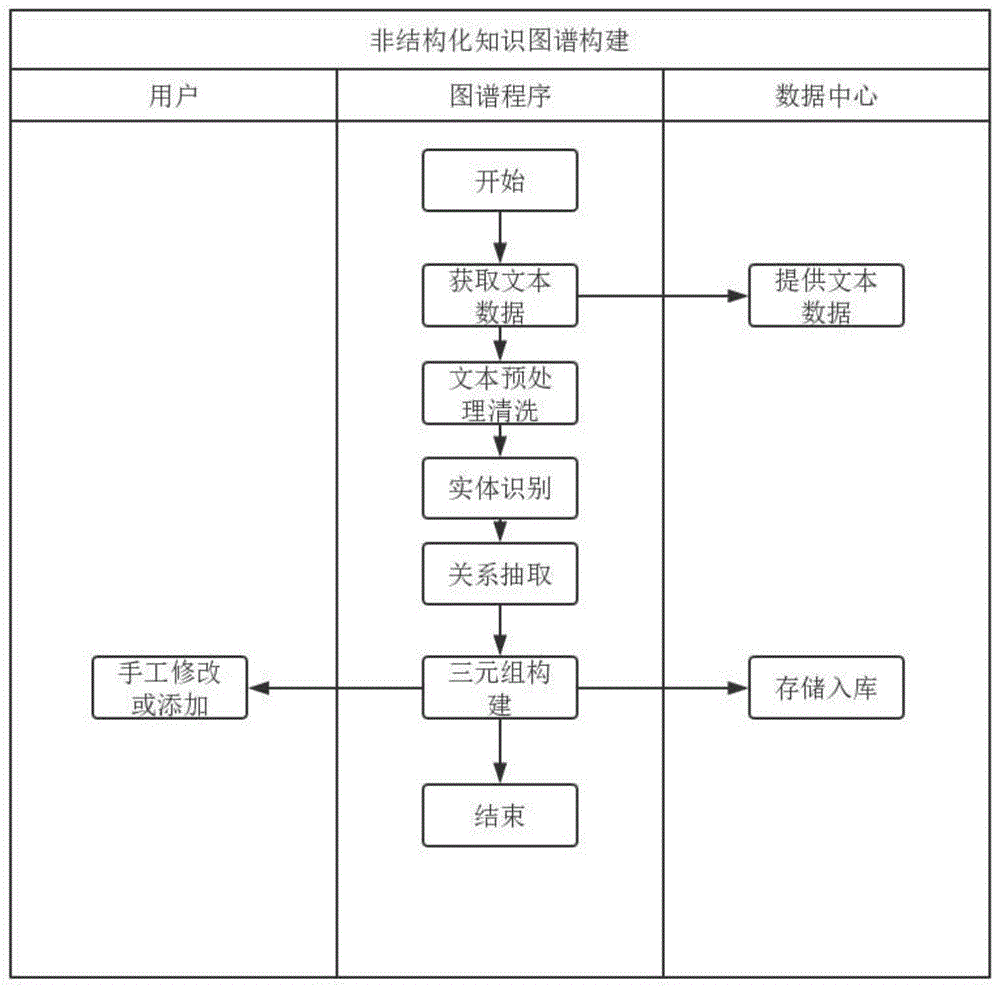
图1为本发明的系统需求图,如图所示,首先,获取文本数据对应步骤s1:获取语料集,具体获取方式为:从网上选取目标网页,把网页定义为document格式,将所有的数据转化为文本,之后对转化为文本的网页进行遍历,获取里面所有的文本数据,最后建立元素组集element存储获取到的所有文本数据。转化为文本的网页不仅包含文字内容,还包含html的标签、注释等,而标签包含文字样式等信息。为了后续读取解析工作方便,元素组把html内容与html标签分开存储。然后,对文本进行预处理清洗对应步骤s2:对语料集进行预处理,使文本的噪音减少。由于三元组对于数据库存储性能高,因此把预处理后的语料集转化为三元组存入数据库,具体过程为:对清洗后的文本进行先进行实体识别,再进行关系抽取,最后完成三元组的构建,存入数据库。这过程对应步骤s3:转化语料集并存入数据库。
根据数据库所存的三元组可构建知识图谱。本实施例与现有的知识图谱构建方法相比,构建出来的知识图谱的质量更高。图3为本发明的图谱可视化图,图谱如图所示。
进一步地,所述步骤s2包括:
步骤s2.1:对语料集进行清洗;
步骤s2.2:使用分词工具对清洗后的语料集进行分词;
步骤s2.3:对分词后的语料集进行词性标注;
步骤s2.4:通过依存句法分析器对词性标注后的语料集进行解析;
步骤s2.5:从解析后的语料集中提取名词短语,建立名词短语集。
在本实施例中,对语料集进行清洗包括删除清洗和正则表达式匹配清洗。获取到语料集后,因为语料集中必定含有不需要的信息,因此必须先进行过滤,把无用的内容,如:广告、无用链接、html注释等无用内容的删除;编写描述关键词的正则表达式,将删除清洗后的语料集与正则表达式进行匹配,过滤掉与正则表达式不相符的部分。将有用的内容文本提取出来后,选取适用的标注集,例如:政策性文本,选取人民日报标注语料库。使用分词工具根据其字、词的含义进行分词,然后给每个词打上相应的词性标签。根据词性对语料集进行句法分析,句法分析能识别句子中所包含的句法成分以及这些成分之间的关系,联系上下文对句子进行更深层次的理解,消除词语之间的歧义,使信息错误率更低。本实施例的句法分析为依存句法分析,其形式简洁,便于应用;因为没有采用基于标注数据集的深度学习方法,而是在传统的无监督学习方法的基础上进行训练,所以无需大量的人工数据标注,不仅高效快捷,还避免了标注数据集质量差而导致的误差,节省大量的人力财力。最后,从依存句法分析器解析完的语料集中准确地从提取名词短语,建立名词短语集。
进一步地,所述步骤s2.5提取名词短语的方式包括:
(1)根据短语中的定中关系结构提取;
(2)提取非定中关系下的有一定长度的名词。
具体地,(1)短语中的定中关系常用来描述汉语中动-名复合词汇,其定语可以从数量、领属、范围、特征、质料对中心语做出限定,构成限制性定语,描述性定语等等定中短语,图2为本发明的句法分析图,如图所示,单纯的使用分词工具进行分词会将“华南理工大学”分割为“华南”“理工”“大学”,而根据句法解析的结果,将定中关系的词语进行组合则能还原其短语语义。由于定中短语词与词之间存在组合先后顺序,在本实施例中还使用了二分插入的方法对其id进行搜索和插入,提高了提取速度的同时保证了短语的完整性。(2)因为分词工具有时候能够直接将识别比较长的名词短语识别成名词或者专有名词,所以是对(1)的补充。
进一步地,所述步骤s3包括:所述语料集转化为三元组,三元组(field,predicate,value);
其中field为数据列名,value为field对应的值,predicate为field与value之间的关系;
所述value包括数字类、地址类、名词性类。
上述的方法从语料集中提取了所有可能的名词短语,然而不可能所有的名词短语都属于实体。因此,需要对得到的名词短语集进行进一步的筛选才能存入数据库。本实施例采用的筛选方法是种子库模板的方法。具体过程为:构建一个数据库,数据库中数据以三元组的方式存储,数据库已有的数据作为模板集,将语料集也转化为三元组,然后与模板集进行匹配,若是通过匹配,则存入数据库。
进一步地,所述field的获取过程包括:
步骤s3.11:获取数据库已有的数据集,作为短语模板集,利用bert预训练的语言模型将短语模板集转为句向量;
步骤s3.12:利用bert预训练的语言模型将名词短语集转为句向量;
步骤s3.13:计算短语模板集与名词短语集两个数据集短语之间的距离;
步骤s3.14:若相似度满足一定阈值则名词短语集的短语归为短语模板集的短语一类;
所述相似度的计算公式如下:
其中,ssimilar表示两个短语的相似度,余弦值的范围为[-1,1],vec1与vec2为bert模型中倒数第二层的输出,共768维向量。
进一步地,所述value的获取过程包括:
步骤s3.21:数字类的识别;
通过依存句法分析器对句子进行句法分析,分析每个词的词性是否属于量词和数词以及它们之间的字数距离,识别出是否属于数字类;
步骤s3.22:地址类的识别;
通过分词和实体标注对语料集进行训练,训练的模型采用基于字的bilstm-crf模型;
所述模型第一层为look-up层,将句子的每个字映射为embedding矩阵;第二层为双向lstm,充分提取句子特征,第三层为crf层,结合训练标签,对句子进行序列标注的预测。
步骤s3.23:名词性类的识别;
利用bert预训练的语言模型将短语模板集、名词短语集转为句向量;
计算短语模板集与名词短语集两个数据集短语之间的距离,若短语模板集的任意一列中存在一个满足阈值的词,则将当前名词短语集的短语归为短语模板集当前列的短语一类。
因为数据库中的值不一定都是以名词短语的形式存在,也会有句子的存在。所以同样需要对其内容进行名词短语的抽取。在value的获取过程中,数据库中的短语模板集是符合实体要求的,然而由于数据库中的内容较多,造成噪声较多的存在。因此需要对其进行一次聚类筛选,以剔除无关的名词短语。同属一类的大多数名词短语语义上应该会比较接近以反映出该列的信息,同时存在噪声数据,并且噪声词之间不一定会相似。以数据库中的某一列获取的名词短语集为例,采用了计数的方法,记录每个名词短语与其他名词短语相似的个数,以剔除一些个数较少的名词短语。
其伪代码如下:
begin
foriin名词短语集:
forjin名词短语集[i+1,:]:
计算相似度
if相似度满足阈值:
名词短语集[i]的计数+1
新的名词短语集=名词短语集[从大到小取计数前40%的名词短语]
end
进一步地,所述数字类、地址类、名词性类之间的关系类别包括:大于、小于、位于、是、否;所述关系类别具有关系约束为:大于、小于只用于描述数字类的关系约束;位于用于描述地址类;是、否用于描述剩下的类别。
具体地,三元组内为实体,实体之间的关系为:大于、小于、位于、是、否。其中实体value分为三类实体:数字类、地址类、名词类;这三类实体之间的关系类别存在关系约束:大于、小于只用于描述数字类的关系约束;位于用于描述地址类;是、否用于描述剩下的类别。
进一步地,所述数字类、地址类、名词性类具有模板词汇,所述模板词汇用于描述其关系类别,识别关系类别的过程为:
(1)定义关系类别及其对应的关系约束;
(2)定义关系类别对应的模板词汇;
(3)保证关系约束的前提下,通过模板词汇对名词短语进行检查和判断,如果不满足或无法识别,将其归为一个新的大类。
(4)具有反义的词汇,作为新的一类进行处理。
首先,定义实体之间的关系类别,并给关系类别加上关系约束。然后定义描述关系类别的模板词汇,最后在保证实体的关系类别符合关系约束的前提下,通过模板词汇识别实体的关系类别,若模板词汇无法识别实体的关系类别,把其归为一个新的大类,若存在“不大于”,“不小于”这类表达反义的词汇也需要额外作为新的一类进行处理,使用模板词汇识别关系类别不仅识别的准确率大大提升,所使用的模板词汇的定义还提供外部配置的方法,可以快速灵活的修改和配置。在未来性能变差的情况下,可以对其进行添加和删除,便于提高准确率,保证了算法的健壮性和可拓展性。
进一步地,所述三元组之间具有组间关系约束,所述组间关系约束可通过构建分类模型判别,所述分类模型的判别类型为and和or,and类定义为1,or类定义为0。
进一步地,所述分类模型的交叉熵损失函数为:
j=-[yglog(,)+(1-y)glog(1-p)]
其中,y表示样本的label,p表示样本预测为正的概率。
具体地,一个句子可以抽取不止一个三元组,若要进一步描述这些三元组之间的关系,以充分还原该句子的语义,需要构建一个分类模型,此模型用于判别三元组之间的关系,由于关系的类别仅仅为“and”’和“or”,数量较少,所以此模型可以取得不错的效果。
显然,本发明的上述实施例仅仅是为清楚地说明本发明技术方案所作的举例,而并非是对本发明的具体实施方式的限定。凡在本发明权利要求书的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!