一种配置数据信息自动识别与归类方法及系统与流程
本发明涉及互联网技术领域,具体涉及一种配置数据信息自动识别与归类方法系统。
背景技术:
针对数据中心it基础架构的日趋复杂性带来运维越发困难现状,尤其在对配置信息数据采集、分类、维护过程中出现因依靠人力造成数据准确性、及时性以及一致性问题,提出在标准计算机协议或私有协议的配置信息数据自动采集方法和自动配置数据信息归类的方法。在数据采集的过程中调用配置变更脚本实现配置管理信息采集自动化,保证数据的准确性与实时性,再进一步使用机器学习方法对配置数据信息归类与挖掘,进而解决数据孤立问题,最大程度的体现运行数据的价值。企业级高度统一规划、管理、储存资源、属性、关系等配置信息,能让运维团队准确、实时掌握鲜活的数据中心资源动态,在监控预警、故障分析与处置、变更控制、风险研判、容量规划等领域有更真实的数据支撑,对于进一步提升信息化管理水平、提升运维保障能力,具有非常重要的价值。
现有的配置信息采集多自动化脚本的方法对数据进行采集,但是在归类和匹配主要依赖于字典匹配方法和人工识别的方法。字典匹配方法通过人工定义拟采集的配置数据类型列表,对数据进行逐一匹配,当发现数据满足模式匹配式时,定义此数据为配置参数信息。人工识别方法主要依赖于风险评估师的个人经验进行和预定义的拟采集的配置数据类型列表。风险评估师通常根据预定义的数据模型来进行评估。业界大多采用字典匹配方法和人工识别方法相结合的方式对配置数据信息进行识别,主要过程如下:用户定义配置信息模式匹配式,根据预定义的模型确定字典匹配范围,然后使用字典匹配对目标进行匹配扫描,在完成扫描后,通过人工对匹配结果过滤,并对模式数据模式匹配式进行优化。
配置信息字典匹配方法存在如下缺陷:1、识别精准度低,字典匹配采用的是模式化匹配的方式,因此数据字典的建立决定了配置信息识别准确度,当字典不完整或者字典建立有误时,会出现识别精度降低的问题;2、分类结果干扰,由于采用字典匹配,因此同一个数据信息会匹配到多个数据字典,由于传统数据字典未能进行加权计算,因此会造成分类结果的干扰,导致分类结果的不准确。
配置信息人工识别方法存在如下缺陷:1、识别速度慢,由于采用人工处理的方式,在面对大量数据的时候,人工梳理速度相对机器识别速度周期较长,而且对处理人员的专业素质要求较高;2、评判标准不统一,由于配置信息识别过程主要依赖与人的主观判断,因此不同的人对相同的数据可能会出现不同的评判标准,甚至同一个人在不同时间所识别的结果仍有不同,这就会导致配置信息识别结果的差异性。
技术实现要素:
发明目的:为了克服现有技术的不足,本发明提供一种配置数据信息自动识别与归类方法,可解决现有的配置数据识别和分类依赖于字典分类和人工分类存在的上述问题,本发明还提供一种配置数据信息自动识别与归类系统。
技术方案:本发明所述的一种配置数据信息自动识别与归类方法,包括:
(1)采用配置数据信息集合建立基础语料库,并进行预处理;
(2)对的预处理后的基础语料库进行特征提取,并建立特征语料库;
(3)将配置数据信息进行分词,并将分词后的结果与所述特征语料库中的特征词进行匹配;
(4)对匹配成功的数据信息进行质量评估。
进一步地,包括:
步骤(1)中,所述预处理操作包括:去除配置数据信息集中的无任何配置意义的数据和计算每个配置数据信息的加权值。
进一步地,包括:
所述计算每个配置数据信息的加权值具体通过tf-idf算法对每个配置数据信息进行计算,一个配置数据信息的tf-idf值越大,则表明这个配置信息所述数据信息集中越重要。
进一步地,包括:
所述配置数据信息包括服务器设备、网络设备、存储设备、操作系统的配置属性、台账属性、物理信息和运行数据,所述台账属性包括投运日期、维保信息、资产信息、厂家、型号、序列号、负责人,所述物理信息包括机房位置、机柜位置、u位,所述运行数据包括硬件运行状态和性能数据。
进一步地,包括:
所述配置数据信息集合建立基础语料库采用hdfs的分布式存储。
进一步地,包括:
步骤(4)中,所述质量评估包括将匹配错误的分类进行改正,包括重新划分特征词分类和多个特征词之间建立的匹配关系以及将未匹配到的特征词进行补充,扩展特征语料库。
进一步地,包括:
步骤(3)中,所述将分词后的结果与所述特征语料库中的特征词进行匹配包括将分词后的结果与特征词的配置信息进行匹配,所述配置信息包括特征词的加权值、特征词分类和特征词匹配模式。
一种配置数据信息自动识别与归类系统,包括:
数据日志采集模块,用于采用配置数据信息集合建立基础语料库,并进行预处理;
机器学习与数据挖掘模块,用于对的预处理后的基础语料库进行特征提取,并建立特征语料库;
匹配模块,用于将配置数据信息进行分词,并将分词后的结果与所述特征语料库中的特征词进行匹配;
业务分析模块,用于对匹配成功的数据信息进行质量评估。
进一步地,包括:
数据日志采集模块中,所述预处理操作包括:去除配置数据信息集中的无任何配置意义的数据和计算每个配置数据信息的加权值。
进一步地,包括:
所述计算每个配置数据信息的加权值具体通过tf-idf算法对每个配置数据信息进行计算,一个配置数据信息的tf-idf值越大,则表明这个配置信息所述数据信息集中越重要。
有益效果:本发明与现有技术相比,其显著优点是:本发明通过构建配置数据语料库,并对配置数据进行按照种类和配置属性进行分类,实现配置数据分类,从而提高敏感数据识别和分类效率和准确度。
附图说明
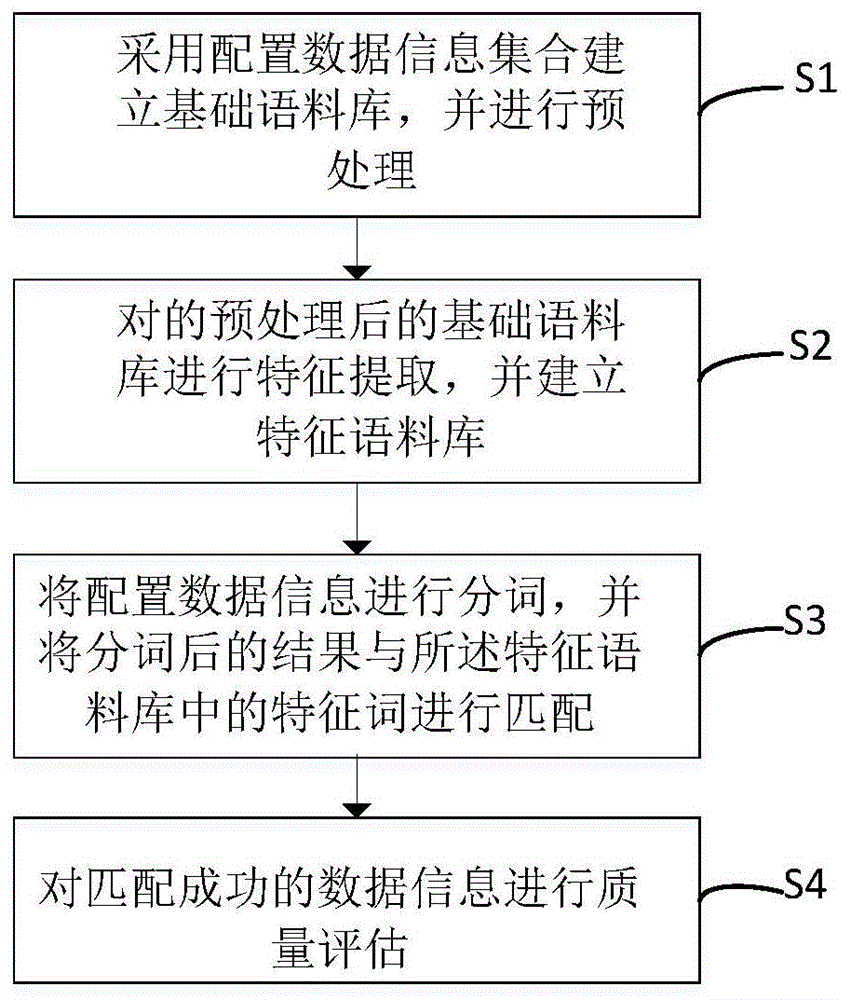
图1是本发明所述的方法流程图;
图2是本发明所述的系统结构示意图。
具体实施方式
本发明所述的配置数据信息自动识别与归类技术可以提高面向国网数据中心it基础架构多层次拓扑技术优化基于拓扑搜索的故障定位功能,且提高it基础架构动态感知技术,进一步为运维支撑平台应用的数据中心、工具中心、资源配置中心做技术支撑,现实国网自主知识产权的自动化运维平台。
如图1所示,本发明所述的一种配置数据信息自动识别与归类方法,包括:
s1采用配置数据信息集合建立基础语料库,并进行预处理;
将采集的配置数据信息存入到hdfs中,进而保持数据的一致性,同时采集的数据要分为两部分的数据,一是离线的数据,只需要对数据进行分析,不要考虑数据的实时;二是需要考虑数据的实时性,比如考虑机器的故障信息,就需要通过机器学习和数据挖掘进行对数据进行实时的统计分析,从而保证数据的实时性。
将使用自动化脚本得到的数据配置信息集合进行预处理操作。预处理操作包括去除数据集中的无意义配置数据和计算配置数据每个配置信息的加权值。其中去除无意义配置信息数据是指去除数据集中无任何意义的配置信息,计算配置信息的加权值则是通过tf-idf算法对每个配置信息进行计算,当一个配置信息的tf-idf值越大时则表明这个配置信息在数据集中的重要性越大。
配置数据信息包含服务器、网络设备、存储设备、操作系统的配置属性、台账属性(投运日期、维保信息、资产信息、厂家、型号、序列号、负责人等)、物理信息(机房位置、机柜位置、u位)和运行数据(硬件运行状态、性能数据)等。
s2对的预处理后的基础语料库进行特征提取,并建立特征语料库。
建立好基础语料库后,需要对语料库中的配置信息进行识别和分类,评估出哪一个配置信息对于数据集是重要的。这一步骤需要通过风险评估师依据专业知识和计算出的加权值来判断重要性大的配置信息。同时建立特征语料库,包括特征词的加权值,特征词分类和特征词匹配模式。
s3将配置数据信息进行分词,并将分词后的结果与所述特征语料库中的特征词进行匹配;
将配置数据信息进行分词操作,将分词后的结果与特征语料库中的配置信息进行匹配,当匹配成功时,记录特征的加权值和类别,当某一类特征词加权值越高时,则表示配置数据信息越靠近这个类别。
s4对匹配成功的数据信息进行质量评估。
对识别和分类后的配置数据信息进行评价和改正。包括:(1)将匹配错误的分类进行改正,包括重新划分特征词分类和多个特征词之间建立的匹配关系。(2)将未匹配到的特征词进行补充,扩展特征语料库。
通过将自动化脚本得到的配置数据信息进行去除无意义信息参数,进而将剩下的配置数据进行特征提取操作,将配置数据信息与特征进行匹配,从而将配置数据信息进行分类。当自动化脚本得到的配置数据信息数量越多时,建立的特征语料库也将更加精确。这一过程得到的特征语料库将大大提高配置数据信息的分类效果,有效降低人工识别和字典匹配的不准确性。
在一种配置数据信息自动识别与归类方法的基础上,提出一种配置数据信息自动识别与归类系统,如图2所示,包括:
数据日志采集模块,用于采用配置数据信息集合建立基础语料库,并进行预处理;
机器学习与数据挖掘模块,用于对的预处理后的基础语料库进行特征提取,并建立特征语料库;
匹配模块,用于将配置数据信息进行分词,并将分词后的结果与所述特征语料库中的特征词进行匹配;
业务分析模块,用于对匹配成功的数据信息进行质量评估。
进一步地,包括:
数据日志采集模块中,所述预处理操作包括:去除配置数据信息集中的无任何配置意义的数据和计算每个配置数据信息的加权值。
进一步地,包括:
所述计算每个配置数据信息的加权值具体通过tf-idf算法对每个配置数据信息进行计算,一个配置数据信息的tf-idf值越大,则表明这个配置信息所述数据信息集中越重要。
进一步地,包括:
所述配置数据信息包括服务器设备、网络设备、存储设备、操作系统的配置属性、台账属性、物理信息和运行数据,所述台账属性包括投运日期、维保信息、资产信息、厂家、型号、序列号、负责人,所述物理信息包括机房位置、机柜位置、u位,所述运行数据包括硬件运行状态和性能数据。
进一步地,包括:
所述配置数据信息集合建立基础语料库采用hdfs的分布式存储。
进一步地,包括:
所述质量评估包括将匹配错误的分类进行改正,包括重新划分特征词分类和多个特征词之间建立的匹配关系以及将未匹配到的特征词进行补充,扩展特征语料库。
进一步地,包括:
所述将分词后的结果与所述特征语料库中的特征词进行匹配包括将分词后的结果与特征词的配置信息进行匹配,所述配置信息包括特征词的加权值、特征词分类和特征词匹配模式。
- 还没有人留言评论。精彩留言会获得点赞!