一种将K-means与证据累积相结合的文本聚类方法与流程
本发明涉及文本聚类技术。
背景技术:
随着以在线社交网络为基础的应用程序和传感、存储技术的快速发展,在网络空间中衍生出大量具有复杂、多样特征的高维数据,其中文本数据在这些数据中占有很大比例。对网络空间中涌现的大规模高维多样的文本数据进行分类和聚类管理成为文本挖掘中的一个迫在眉睫的话题。
传统的文本聚类方法通常是单次聚类,这往往会导致随机的、不准确的聚类结果。即使在同一文本数据集上,不同的聚类算法或者带有不同参数的同一聚类算法都会影响最终聚类分割的准确性,聚类算法参数的微小变动很可能会使聚类结果大相径。文本数据上的单次聚类难以得到稳定的、准确的、一致的聚类结果,难以排除不同聚类算法之间的差异以及同一聚类算法内部参数之间的差异等随机因素对聚类结果准确度产生的影响。
以往研究者对于文本聚类的研究主要集中在单次聚类问题上,与融合聚类相比,单次聚类得到的聚类结果在准确定和一致性方面往往不能令人信服。以k-means算法为例,k-means算法与劳埃德算法(lioyd’salgorithm)密切相关,劳埃德算法的目的是在欧几里德空间的任何子集上找到一个统一的分割,使得每个子集上中点都被分配到距离其最近的中心点(cellcenter)所在的voronoi单元格。而k-means算法则使用离散集合来代替劳埃德算法中的voronoi图,为有限数量的点指定距离其最近的质心。k-means算法适用于文本聚类。将观察对象抽象为有限维欧氏空间中的数据的实例。k-means算法侧重于最小化损失函数,损失函数的定义为每个数据点与离其最近的质心之间的距离的平方和。损失函数的形式化定义如下:
其中,c为簇的集合,k为c中簇的个数,cq为簇,xi为cq中的数据点,||·||2为欧氏距离的平方。
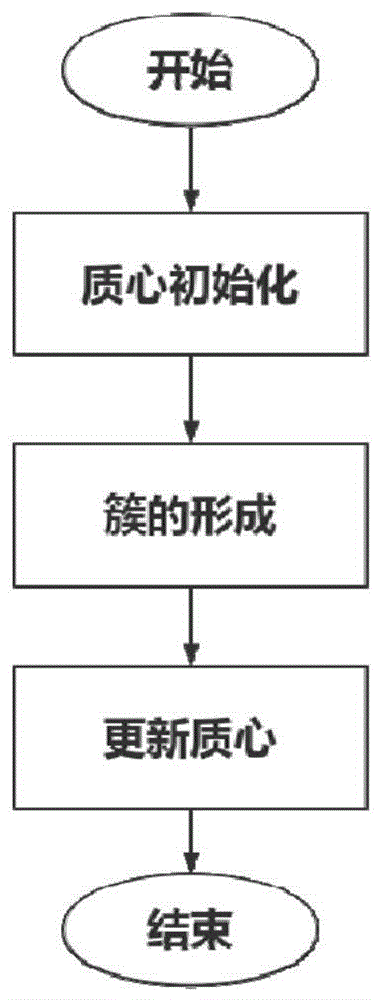
k-means算法分为三步,(1)质心初始化:从数据集中选取k个点作为初始质心,每个质心代表一个簇;(2)簇的形成:将数据集中的点分配到距离其最近的质心所代表的簇中;(3)更新质心:根据每个簇中点的分布,取其平均值作为新的质心点,返回步骤(2)。k-means算法终止的条件为达到最大迭代次数或者相邻两次迭代结果之间的损失函数差值小于可容忍值。k-means算法的步骤流程如图1所示。k-means迭代过程如图2所示。
k-means算法对复杂类型的数据具有很强的适应性。它将给定的数据集划分为预定义数量的簇。k-means从一组由用户指定的质心开始训练数据,然后在两个步骤之间进行迭代,即赋值和更新。但是,k-means是一种局部改进启发式方法,它对参数的值很敏感。k-means算法的输出在很大程度上依赖于初始质心(centroids)的设置,质心初始化过程的微小变化可能会对整个算法的输出产生重大影响。
针对传统的文本聚类问题,如何得到一致的、准确的、稳定的聚类结果仍是目前亟待解决的问题。
技术实现要素:
本发明的目的是为了解决传统的文本聚类方法一致性、准确性、以及稳定性差的问题,提供一种将k-means与证据累积相结合的文本聚类方法。
本发明所述的一种将k-means与证据累积相结合的文本聚类方法包括以下步骤:
步骤一、创建共协矩阵,具体包括以下步骤:
步骤一一、始化共协矩阵:将共协矩阵a中所有元素的值初始化为0,a是一个n×n的矩阵,n为数据集中数据点的个数,矩阵a中的元素aij代表第i个数据点xi与第j个数据点xj之间的相似度;
步骤一二、投票:选取不同的k的值,k为簇的数量,多次运行k-means算法,进而选择损失函数下降坡度最大的范围作为k-means算法参数k的最佳取值范围,将参数k在上述最佳取值范围内均匀取值,以每次取的值为基础多次运行k-means算法;对于任意两个数据点xi和xj,在每次使用k-means算法聚类的过程中,若数据点xi和xj被分配到同一个簇中,则其在共协矩阵a中的对应元素点aij的值增加1,否则aij的值不变;
步骤一三、标准化共协矩阵:将共协矩阵a中的每个元素除以m,实现a的标准化,m为步骤一二中运行k-means算法的次数;
步骤二、在共协矩阵上运行层次聚类算法,具体包括以下步骤:
步骤二一、初始化相似矩阵:定义相似矩阵,将相似矩阵初始化为步骤一三中得到的标准化共协矩阵a,将数据集中每个元素视为一个簇,相似矩阵中每个元素的值代表其对应的两个数据点之间的相似度;
步骤二二、更新相似矩阵:更新相似矩阵过程包含3步:步骤a,根据单连准则,将最相似的两个簇合并为一个簇;步骤b,将同一个簇中元素的相似度的值设置为0,更新相似矩阵;步骤c,重新计算新生成的簇和原来的簇之间的相似度;不断重复上述步骤a至步骤c,直至所有簇被合并为一个簇;
步骤二三、构建最小生成树和剪枝;在步骤二二中,每次合并生成一个新的簇,则生成一条连接两个来自不同簇的数据点之间的无向边,步骤二二结束后,得到一个由所有无向边构成的树结构t,将t中权重小于预设值t的边剪掉,至此,所述文本聚类方法结束。
基于k-means的eac(证据累积)算法弥补了k-means的上述缺点,eac策略同时考虑多种不同的聚类结果,其主要思想是在多次聚类过程中,天然相似的点大概率被分配到同一个簇。eac策略可以用于平滑由多次运行k-means算法产生的不同聚类结果之间的差异,能够大大提高结果的可靠性、一致性以及准确率。
附图说明
图1为背景技术中k-means算法的流程图;
图2为背景技术中k-means算法的迭代过程,其中(a)为第1次迭代结果,(b)为第2次迭代结果,(c)为第5次迭代结果,(d)为第20次迭代结果;
图3为创建共协矩阵的流程图;
图4为在共协矩阵上运行层次聚类算法的流程图;
图5为基于k-means的eac算法的流程图。
具体实施方式
具体实施方式一:本实施方式所述的一种将k-means与证据累积相结合的文本聚类方法包括以下步骤:
步骤一、创建共协矩阵,具体包括以下步骤:
步骤一一、始化共协矩阵:将共协矩阵a中所有元素的值初始化为0,a是一个n×n的矩阵,n为数据集中数据点的个数,矩阵a中的元素aij代表第i个数据点xi与第j个数据点xj之间的相似度;
步骤一二、投票:选取不同的k的值,k为簇的数量,多次运行k-means算法,进而选择损失函数下降坡度最大的范围作为k-means算法参数k的最佳取值范围,将参数k在上述最佳取值范围内均匀取值,以每次取的值为基础多次运行k-means算法;对于任意两个数据点xi和xj,在每次使用k-means算法聚类的过程中,若数据点xi和xj被分配到同一个簇中,则其在共协矩阵a中的对应元素点aij的值增加1,否则aij的值不变;
步骤一三、标准化共协矩阵:将共协矩阵a中的每个元素除以m,实现a的标准化,m为步骤一二中运行k-means算法的次数;
步骤二、在共协矩阵上运行层次聚类算法,具体包括以下步骤:
步骤二一、初始化相似矩阵:定义相似矩阵,将相似矩阵初始化为步骤一三中得到的标准化共协矩阵a,将数据集中每个元素视为一个簇,相似矩阵中每个元素的值代表其对应的两个数据点之间的相似度;
步骤二二、更新相似矩阵:更新相似矩阵过程包含3步:步骤a,根据单连准则,将最相似的两个簇合并为一个簇;步骤b,将同一个簇中元素的相似度的值设置为0,更新相似矩阵;步骤c,重新计算新生成的簇和原来的簇之间的相似度;不断重复上述步骤a至步骤c,直至所有簇被合并为一个簇;
步骤二三、构建最小生成树和剪枝;在步骤二二中,每次合并生成一个新的簇,则生成一条连接两个来自不同簇的数据点之间的无向边,步骤二二结束后,得到一个由所有无向边构成的树结构t,将t中权重小于预设值t的边剪掉,至此,所述文本聚类方法结束。
基于k-means的eac是一个基于投票机制的聚类融合算法,eac的主要思想是相比于其他数据点,天然相似的数据点在多次聚类的过程中更有可能被分配到同一个簇中。基于k-means的eac算法综合考虑多次k-means聚类的分割结果。
基于k-means的eac算法的运行过程分为两步:一、创建共协矩阵;二、在共协矩阵上运行层次聚类算法。
在步骤一中,将数据集中的数据点从原始的数据特征空间映射到一个全新的特征空间中,新的特征空间中的特征不再是数据点与数据点之间的欧氏距离,而是数据点与数据点之间的相似度。将共协矩阵记作a,a是一个n×n的矩阵,n为数据集中数据点的个数。矩阵a中的元素aij代表第i个数据点xi与第j个数据点xj之间的相似度,即aij的值越大,则第i个数据点xi与第j个数据点xj越相似、越接近。如图3所示,共协矩阵的创建过程被分为三步进行:
步骤一一、始化共协矩阵:将共协矩阵a中所有元素的值初始化为0。
步骤一二、投票过程:选取不同的k(簇的数量)的值,多次运行k-means算法,进而选择损失函数下降坡度最大的范围作为最佳的k-means算法参数k的取值范围。在此基础上,将参数k在上述最佳取值范围内均匀取值,再次多次运行k-means算法。对于任意两个数据点xi和xj来说,在每次使用k-means算法聚类的过程中,若它们被分配到同一个簇中,则其在共协矩阵a中的对应元素点aij的值增加1,否则aij的值不变。
步骤一三、标准化共协矩阵:将共协矩阵a中的的每个元素除以m,实现a的标准化,m为②中运行k-means算法的次数。
在步骤二中,对共协矩阵a使用层次聚类算法,得出共协矩阵a在阈值(threshold)t下的层次结构。在本文中,使用单连准则作为层次聚类的连接准则。单连准则的定义如下:对于任意两个簇ci和cj,其相似度被定义为apq,其中xp∈ci,xq∈cj,也就是说数据点xp在簇ci中,数据点xq在簇cj中。apq为数据点xp和数据点xq在共协矩阵a中对应的元素值,即数据点xp和数据点xq之间的相似度。如图4所示,步骤二的详细过程可被分为3步:
步骤二一、初始化相似矩阵:定义相似矩阵(similaritymatrix),将相似矩阵初始化为步骤(1)中得出的共协矩阵a,将数据集中每个元素视为一个簇,相似矩阵中每个元素的值代表其对应数据点之间的相似度。
步骤二二、更新相似矩阵:更新相似矩阵过程包含3步:(a)根据单连准则,将最相似的两个簇合并为一个簇。(b)将同一个簇中元素的相似度的值设置为0,更新相似矩阵。(c)重新计算新生成的簇和原来的簇之间的相似度,返回(a)。不断进行上述步骤,直至所有簇被合并为一个簇。
步骤二三、构建最小生成树和剪枝;在步骤二二中,每次合并生成一个新的簇,则生成一条连接两个来自不同簇的数据点之间的边,这条边的权重(weight)被定义为两个簇之间的相似度。例如:在步骤二二中,簇ci和簇cj之间的相似度为apq,其中xp∈ci,xq∈cj,apq为数据点xi和数据点xj之间的相似度;若簇ci和簇cj被合并为一个新的簇,则建立一条连接数据点xi和数据点xj的无向边,这条边的权重为apq。因此,随着步骤二二进行完毕,得出一个树结构t,将t中权重小于t的边剪掉。
将g视为数据集中的数据点连接而成的完全无向图,g中的边的权重被设置为其连接的数据点之间的相似度的相反数,即共协矩阵a中相应位置元素的值取负。根据prime算法思想,最小生成树t其实是无向完全图g上的最小生成树。
本实施方式所述的文本聚类方法的整体流程如图5所示。
基于k-means的eac算法的伪码表示如下:
输入:x:数据集,xi∈rd;
k:初始质心的数量;
m:运行k-means算法的次数;
t:权重阈值(用于剪枝);
输出:数据集中数据点的分割结果;
过程:1.初始化共协矩阵a:将a中元素的值设置为0;
2.运行下列操作m次:
2.1用k-means++算法(k-means++是2007年由d.arthur等人提出的用于选取k-means质心的算法)在数据集x中选取k个质心;
2.2在上述条件下,运行带elkan三角不等式(elkan三角不等式为charleselkan在2003年提出的用于加速k-means算法的不等式)约束的k-means算法;
2.3投票机制:对于任意一对数据点xi和xj,若它们被分配到同一个簇,
aij=aij+1;
3.标准化共协矩阵:
4.在共协矩阵a上运行层次聚类算法,获得数据集x的一致的、稳定的、准确的聚类分割结果。其中层次聚类使用的连接准则为单连准则:
4.1构建无向完全图:构建出以共协矩阵-a为邻接矩阵的无向完全图g;
4.2寻找最小生成树:计算无向完全图g上的最小生成树t;
4.3剪枝:剪去最小生成树t中权重小于-t的边;
4.4剪枝后得出的每个连通树均为一个簇。
结束。
- 还没有人留言评论。精彩留言会获得点赞!