一种基于中间人的互联网数据采集方法及系统与流程
本发明涉及网络爬虫领域,具体涉及一种基于“中间人攻击”的数据采集方法及系统,能够对不同的应用程序以中间人代理修改流量数据攻击的方式不断注入不同的任务代码来完成对不同的页面的请求,并获取相关数据。
背景技术:
网络爬虫能够有效使用现有的各种资源自动抓取互联网中大量网页信息的程序,有时也被叫成“网络蜘蛛(spider)”。但是随着移动互联网的普及,更多的流量直接通过各种不同的终端应用进行分发,并不提供web访问或web访问会有部分数据受限,这样便给数据采集带来了极大的困难。
由网络爬虫爬取过程中需要获取请求url、发送web请求下载页面、从网页中解析结构化数据、重复数据过滤和种子任务处理,共计5个环节,每个环节消耗资源各不相同,且每个环节出现问题都会影响整个爬虫系统效率及稳定性。另外,随着互联网技术的日新月异,越来越多的信息不可通过传统的web渠道获取的信息越来越多,大量的信息近通过特定的应用程序传播,典型的如移动资讯应用等,而且其中大量的数据均为异步请求,以及使用https的加密数据,目前缺少一种兼容各种应用、各类数据的通用数据采集系统。
技术实现要素:
针对现有技术的不足,本发明提出一种基于中间人的互联网数据采集方法,其中包括:
步骤1、通过安装中间人代理证书至网页信息采集设备,建立该网页信息采集设备的中间人,该网页信息采集设备访问互联网中网页信息时,中间人代理该网页信息采集设备的全部网络流量;
步骤2、该中间人获取包含待采集网页url正则表达式的采集任务,捕获该全部网络流量中符合该url正则表达式的流量,作为中间流量,并将该采集任务注入该中间流量的html页面中,得到待解析页面并将其存入第一数据库;
步骤3、解析模块根据该第一数据库中待解析页面的url信息,将待解析页面分发给解析器实例进行解析,从中获取包含结构化数据的网页采集结果并将其存入第二数据库。
所述的基于中间人的互联网数据采集方法,其中该步骤2包括:该中间人根据该网页信息采集设备配置的https安全证书,对该网络流量中加密内容进行解密。
所述的基于中间人的互联网数据采集方法,其中步骤2中该采集任务的生成过程包括:根据预先配置的种子信息生成该采集任务,或者根据采集得到的网页采集结果生成新的该采集任务。
所述的基于中间人的互联网数据采集方法,其中步骤2包括:根据配置的url正则表达式对部分http/https请求进行拦截,返回空内容,以提高采集效率。
所述的基于中间人的互联网数据采集方法,其中步骤2中该采集任务包括:html页面采集任务和动态内容采集任务;该html页面采集任务包括跳转代码,跳转到下次要采集的url;该动态内容采集任务不仅包括跳转代码,还包括使用javascript代码获取相应的接口参数以及用被采集页面的javascript代码。
本发明还提出了一种基于中间人的互联网数据采集系统,其中包括:
模块1、通过安装中间人代理证书至网页信息采集设备,建立该网页信息采集设备的中间人,该网页信息采集设备访问互联网中网页信息时,中间人代理该网页信息采集设备的全部网络流量;
模块2、该中间人获取包含待采集网页url正则表达式的采集任务,捕获该全部网络流量中符合该url正则表达式的流量,作为中间流量,并将该采集任务注入该中间流量的html页面中,得到待解析页面并将其存入第一数据库;
模块3、解析模块根据该第一数据库中待解析页面的url信息,将待解析页面分发给解析器实例进行解析,从中获取包含结构化数据的网页采集结果并将其存入第二数据库。
所述的基于中间人的互联网数据采集系统,其中该模块2包括:该中间人根据该网页信息采集设备配置的https安全证书,对该网络流量中加密内容进行解密。
所述的基于中间人的互联网数据采集系统,其中模块2中该采集任务的生成过程包括:根据预先配置的种子信息生成该采集任务,或者根据采集得到的网页采集结果生成新的该采集任务。
所述的基于中间人的互联网数据采集系统,其中模块2包括:根据配置的url正则表达式对部分http/https请求进行拦截,返回空内容,以提高采集效率。
所述的基于中间人的互联网数据采集系统,其中模块2中该采集任务包括:html页面采集任务和动态内容采集任务;该html页面采集任务包括跳转代码,跳转到下次要采集的url;该动态内容采集任务不仅包括跳转代码,还包括使用javascript代码获取相应的接口参数以及用被采集页面的javascript代码。
由以上方案可知,本发明的优点在于:
本发明提出一种基于“中间人攻击”的数据采集方法及系统,能够支持所有依靠集成浏览器内核功能来提供信息的应用的数据采集,包括多种类型的网页请求方式,结构化数据解析配置灵活。本系统采集过程模块化、职能化,大大提升数据抓取效率,大大降低了对各种应用程序数据采集的困难性。
本发明将“中间人攻击”技术运用数据采集系统中,将各个处理环节模块化并且每个模块职能单一,从而提高了整个系统的工作效率,使得系统水平扩展更方便简单。另一方面,本发明中引入redis消息队列用于模块之间的解耦,redis也具备高吞吐、高可用、易扩展的特点,因此引入redis这种存储介质也大大提高了本发明的效率和稳定性。
附图说明
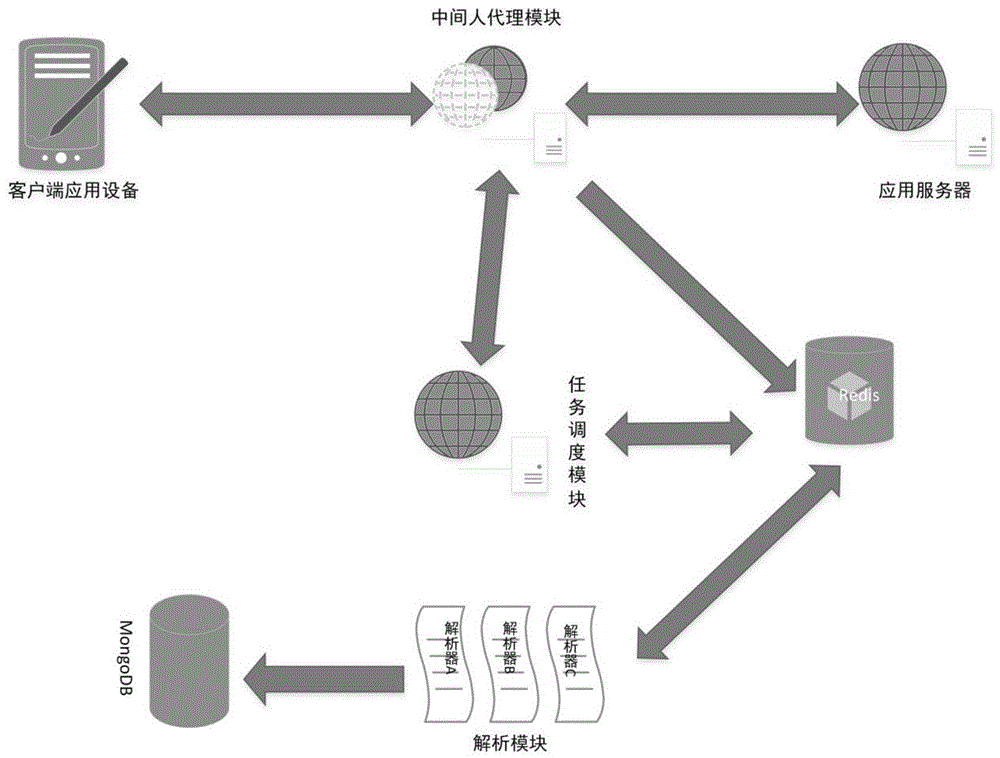
图1为本发明实施例的爬虫系统的架构图。
具体实施方式
为让本发明的上述特征和效果能阐述的更明确易懂,下文特举实施例,并配合说明书附图作详细说明如下。
本发明引入anyproxy代理工具来代理客户端应用的全部http/https流量,并通过预先在对应的采集设备上安装安全证书的方法保证了对https加密数据的解密。
本发明技术方案如下:
一种基于“中间人攻击”的数据采集方法,包括以下步骤:
1)需要采集的应用及设备,这部分为采集主体,但仅需配置中间人代理并安装中间人代理证书即可,并在需要采集的应用上访问任意页面初始化即可。
2)中间人代理模块主要负责实施“中间人攻击”,包括以下主要内容:
a)拦截过滤无效流量的请求,包括但不限于css文件、javascript文件、图片文件等资源文件。
b)使用预先配置的https证书对加密内容进行解密。
c)将需要采集的流量依据url正则表达式进行捕获并存入redis数据库缓存。
d)向任务调度模块请求新任务,并将任务注入到符合url正则表达式的html页面中。任务包括接下来要爬取的网页,但由于客户端的封闭性,客户端难以直接拿到新任务,因此本发明以注入到返回给客户端的网页的形式给客户端传达任务。
3)解析模块,解析模块根据response数据的url信息将不同的页面分发给不同解析器实例进行解析,从中获取结构化的数据并存入mongodb数据库,另外将和新任务相关的数据存入redis数据库以供任务调度模块使用生成新的任务。其中response数据指的应用服务器给客户端的响应数据,因此这个数据是服务器返回的。
4)任务调度模块,根据根据种子任务等预配置的基本信息来生成任务内容,亦可以根据解析模块解析出的数据生成新的任务;并根据任务的url对任务进行去重,以及任务的失败恢复。
5)数据存储模块主要负责存储相关数据,以及将各模块的功能进行解耦。解耦体现在数据存储模块可以记录其他功能模块需要写的数据,也可以让其他功能模块读取它们需要的数据,因此各个功能模块不需要直接与其它功能模块交互,只需要共用的数据存储模块就行。
进一步地,步骤1)主要是在采集环境中安装配置好中间人代理的网络地址以及网络端口以及安全证书,并在需要采集的应用访问任意的初始页面即可启动整个采集流程。
进一步地,步骤2)所述中间人代理模块包括四部分主要功能:
a)因为客户端应用设备上装有中间人代理模块颁发的安全证书,因此作为中间人可以截获客户端的https加密流量并查看明文内容。
b)在客户端请求request到达中间人代理时,中间人代理模块会检查其请求的url是否满足被过滤的条件,如果是需要过滤的内容则拦截其请求直接返回空内容。否则就将request转发到目标服务器。例如根据配置的url正则表达式对部分http/https请求进行拦截,返回空内容,该部分http/https请求包括css文件、javascript和图片文件等可能会降低采集效率及无用流量的请求进行拦截,直接返回空内容,来提高采集效率。因为css文件被用来渲染图形会占用大量的计算资源,另外javascript文件为代码浏览器执行也会耗费大量资源,最后是类似图片、音频等资源文件会占用大量网络带宽所以过滤拦截后能极大的提高采集效率以及采集的稳定性。
c)当目标服务器返回对应的response的时候,中间人代理会检查其url是否为需要采集的内容,若是,则将整个response存入redis数据库。
d)当目标服务器返回对应的response的时候,若内容为html页面,则中间人代理会检查其url是否匹配特定的正则表达式,如果匹配则向任务调度模块请求对应的任务,并将其注入到html页面中的<script>标签中。再将response传给客户端应用程序。
进一步地,所述3)解析模块,用于从redis数据缓存中取出待解析的内容,并根据其url将其分配给不同的解析器实例,在解析事咧解析完后会将结构化的数据存入mongodb以及和下次采集相关的信息如url,cookies等信息存入redis数据库缓存。
进一步地,步骤4)所述任务调度器:主要包括任务生成、任务调度、任务去重以及任务恢复。
进一步地,任务生成主要分为两种生成方式:一种为根据预先配置的种子信息生成任务,一种为根据已经采集过的信息生成新的任务;另外,任务也主要分为两种类型:一种为简单的html页面采集任务,一种为动态信息的内容如json等数据,这类任务需要相关的任务参数以及cookies等信息,并执行javascript相关代码才能完成采集。
进一步地,任务调度主要是更根据不同的应用程序分配给其不同的采集任务,并控制其采集速率,避免被封禁。
进一步地,任务去重主要根据url来去重,仅需在redis数据库中使用一个统一的去重队列即可,每次在生成任务时去查询该url是否已经被访问过就行。
进一步地,任务恢复功能需要识别出采集失败的任务,并适时安排其恢复。
本发明的有益效果如下:
本发明提出的一种基于“中间人攻击”的数据采集方法及系统,能够支持以浏览器内核为核心的应用的数据采集任务,以及根据url正则可以采取灵活地配置,另外爬取过程模块化、职能化,大大提升数了对应用程序数据采集的效率,具有好的适用性和通用性。
在图1中客户端应用设备即为安装了需要采集信息的应用的设备,需要在该设备上配置中间人代理配置。在配置完成后可以看到中间人代理模块会代理客户端设备与应用服务器间的所有流量并适时实施“中间人攻击”,并且中间人代理模块会与任务调度模块以及redis数据库交互。最后采集的数据经过解析器解析后存入mongodb数据库。
本发明基于“中间人攻击”的数据采集系统,采集过程包括五个模块,处理过程模块化、职能单一化,且模块之间采用redis数据缓存解耦,大大提高爬虫系统的效率。保证了数据抓取的稳定性,同时也大大降低了系统的运维成本。
以下为与上述方法实施例对应的系统实施例,本实施方式可与上述实施方式互相配合实施。上述实施方式中提到的相关技术细节在本实施方式中依然有效,为了减少重复,这里不再赘述。相应地,本实施方式中提到的相关技术细节也可应用在上述实施方式中。
本发明还提出了一种基于中间人的互联网数据采集系统,其中包括:
模块1、通过安装中间人代理证书至网页信息采集设备,建立该网页信息采集设备的中间人,该网页信息采集设备访问互联网中网页信息时,中间人代理该网页信息采集设备的全部网络流量;
模块2、该中间人获取包含待采集网页url正则表达式的采集任务,捕获该全部网络流量中符合该url正则表达式的流量,作为中间流量,并将该采集任务注入该中间流量的html页面中,得到待解析页面并将其存入第一数据库;
模块3、解析模块根据该第一数据库中待解析页面的url信息,将待解析页面分发给解析器实例进行解析,从中获取包含结构化数据的网页采集结果并将其存入第二数据库。
所述的基于中间人的互联网数据采集系统,其中该模块2包括:该中间人根据该网页信息采集设备配置的https安全证书,对该网络流量中加密内容进行解密。
所述的互联网中网页信息的采集系统,其中模块2中该采集任务的生成过程包括:根据预先配置的种子信息生成该采集任务,或者根据采集得到的网页采集结果生成新的该采集任务。
所述的互联网中网页信息的采集系统,其中模块2包括:根据配置的url正则表达式对部分http/https请求进行拦截,返回空内容,以提高采集效率。
所述的互联网中网页信息的采集系统,其中模块2中该采集任务包括:html页面采集任务和动态内容采集任务;该html页面采集任务包括跳转代码,跳转到下次要采集的url;该动态内容采集任务不仅包括跳转代码,还包括使用javascript代码获取相应的接口参数以及用被采集页面的javascript代码。
- 还没有人留言评论。精彩留言会获得点赞!