一种VR场景下人机协同抓取物体的方法与流程
本发明属于虚拟现实
技术领域:
,具体涉及一种vr场景下人机协同抓取物体的方法。
背景技术:
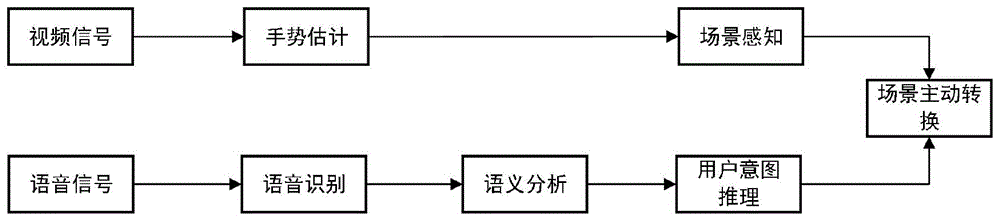
:虚拟现实(vr)技术是当今时代技术发展的产物,结合多种人机交互接口技术,可以为用户提供多通道输入和感知的接口。然而,在人们真正使用虚拟现实技术进行交互的过程中,往往存在3d虚拟物体由于距离过远和遮挡的原因使得用户并不能准确高效的操作自己想要交互的虚拟物体。技术实现要素:本发明的目的在于解决上述现有技术中存在的难题,提供一种vr场景下人机协同抓取物体的方法,能够协助用户准确高效地操作自己想要交互的虚拟物体。本发明是通过以下技术方案实现的:一种vr场景下人机协同抓取物体的方法,包括:同时进行手势识别和语音识别,其中,所述手势识别是采集人手的视频信号,根据所述视频信号驱动虚拟场景中的虚拟人手的运动,并获得手势识别结果;所述语音识别是采集用户的音频信号,对音频信号进行识别和语义分析,根据语义分析得到语音识别结果;根据所述手势识别结果和语音识别结果进行场景主动转换,协助用户完成操作。具体的,所述采集人手的视频信号,根据视频信号驱动虚拟场景中的虚拟人手的运动,并获得手势识别结果的操作包括:步骤a1,采集人手的视频信号,从所述视频信号中获取人手的深度图像以及人手的三维估计,将人手的三维估计中的各个节点映射到虚拟场景中的虚拟人手上,驱动虚拟人手的运动;步骤a2.通过虚拟人手的运动方向和虚拟人手的手掌垂直向量获得虚拟人手的抓取方向,以及虚拟人手与虚拟物体的位置关系,即手势识别结果。所述步骤a2的操作包括:利用下式计算t帧的抓取方向:其中为虚拟场景中的虚拟人手的运动方向,pt表示t帧时刻的手掌节点p的坐标,表示虚拟场景中的虚拟人手的手掌的垂直向量,i0t和m0t表示t帧时刻的虚拟人手的食指的第一个关节点、中指的第一个关节点的坐标;θ为和之间的夹角;判断θ是否小于10,如果是,则利用下式计算抓取方向dir:如果否,则不做任何处理;假设虚拟场景中一个虚拟物体的重心坐标为o,其与虚拟人手之间的向量表示为两者之间的距离为利用下式计算出抓取方向与向量之间的夹角,即虚拟人手与虚拟物体之间的位置关系:所述采集用户的音频信号,对音频信号进行识别和语义分析,根据语义分析得到语音识别结果的操作包括:步骤b1.采集用户的音频信号;步骤b2.对所述音频信号进行语音识别和语义分析获得语音识别结果,所述语音识别结果包括:主动对象、动作、属性和被动对象。所述根据所述手势识别结果和语音识别结果进行场景主动转换的操作包括:步骤c1,情景感知:判断虚拟人手当前是否处于抓取物体状态,如果是,则当前虚拟人手所指向的主动对象为绑定的虚拟物体,如果否,则虚拟人手指向的主动对象为虚拟人手本身;步骤c2.主动对象感知:判断虚拟人手和语音识别结果中的主动对象是否为同一个,如果是,则进入步骤c3,如果否,则进行主动对象转换,然后再返回步骤c2;步骤c3.接近对象关系感知:判断虚拟场景中是否存在想要接近的物体,如果是,则将虚拟场景的视角随着主动对象的移动向该物体拉近,拉近到设定距离时,转入步骤c4,如果否,则返回步骤c3;步骤c4.判断在虚拟场景中是否存在虚拟物体将被动对象遮挡住,如果是,则该虚拟物体为遮挡物体,将被动对象的坐标与遮挡物体的坐标进行互换,然后转入步骤c5,如果否,则转入步骤c5;步骤c5.用户与虚拟场景进行交互。所述步骤c2中的所述主动对象转换的操作包括:将语音识别结果中的主动对象作为被动对象;将虚拟人手指向的主动对象作为语音识别结果中的主动对象。所述步骤c3中的判断虚拟场景中是否存在想要接近的物体的操作包括:判断虚拟场景中的物体o(x1,y1,z1)是否满足以下条件:γt<10且如果是,则判定存在想要接近的物体,如果否,则判定不存在想要接近的物体。所述步骤c3中的所述将虚拟场景的视角随着主动对象的移动向该物体拉近的操作包括:设虚拟场景中的摄像机的原坐标为c(x2,y2,z2),随着主动对象的移动,视角也向着想要接近的物体移动,利用下式计算摄像机的新坐标ct(x,y,z):所述步骤c3中的所述设定距离为:摄像机的新坐标与想要接近的物体的距离小于等于10。所述步骤c4中的判断在虚拟场景中是否存在虚拟物体将被动对象遮挡住的操作包括:为虚拟场景中的每一个物体设置一个包围盒;从摄像机的坐标沿z轴方向扫描,直到被动对象的坐标点,在扫描过程中判断是否存在一个虚拟物体的包围盒在z轴方向上的投影与被动对象的包围盒相交,如果是,则判定存在虚拟物体将被动对象遮挡住,如果否,则判定不存在虚拟物体将被动对象遮挡住。与现有技术相比,本发明的有益效果是:利用本发明能够协助用户准确高效地操作自己想要交互的虚拟物体。附图说明图1为本发明方法的步骤框图;图2为本发明方法所使用的虚拟人手;图3为本发明方法的语法规则;图4为本发明方法中的虚拟场景主动转换步骤框图。具体实施方式下面结合附图对本发明作进一步详细描述:本发明通过interrealsense进行手势估计并驱动虚拟人手,利用科大讯飞语音识别sdk识别用户的语音输入,即音频信号,然后对识别出的语音进行语法分割得到用户的操作意图,通过对3d虚拟场景的情景感知使场景主动变换协助用户完成操作。本发明方法的步骤如图1所示,包括:同时进行手势识别和语音识别,其中,所述手势识别是采集人手的视频信号,根据视频信号驱动虚拟场景中的虚拟人手的运动,并获得手势识别结果,即图1中的场景感知;所述语音识别是采集用户的音频信号,对音频信号进行识别和语义分析,根据语义分析得到语音识别结果,即图1中的用户意图推理;根据所述手势识别结果和语音识别结果进行场景主动转换,协助用户完成操作。具体的,所述手势识别是采集人手的视频信号,根据视频信号驱动虚拟场景中的虚拟人手的运动,并获得手势识别结果的操作包括:步骤a1.通过interrealsense获取人手的深度图像,通过interrealsense本身自带的sdk得到真实人手的三维估计,然后将真实人手的三维估计中的21个节点(如图2所示,21个节点包括每根手指的4个节点和一个手掌节点,所有的手指均是从手掌节点延伸出来的,21个节点具体如下:手掌节点p、拇指上从手掌节点向指尖方向依次为第一个节点t0到第4个节点t3,食指上从手掌节点向指尖方向依次为第一个节点i0到第4个节点i3,中指上的从手掌节点向之间方向依次为第一个节点m0到第4个节点m3,无名指上从手掌节点向指尖方向依次为第一个节点r0到第4个节点r3,小指上的从手掌节点向之间方向依次为第一个节点l0到第4个节点l3。)映射到虚拟场景中的虚拟人手上,驱动虚拟人手的运动,具体的,通过interrealsense所获取的21个坐标点是在相机坐标系下的坐标点,而虚拟人手是在虚拟场景下的,因此需要将相机坐标系下的点转换成虚拟场景坐标系下的坐标点。对于不同的虚拟场景需要做的映射关系不同,在unity下相机坐标系的坐标点和unity坐标系下坐标点的比例关系为1:100。得到虚拟场景下的坐标点后就可以驱动虚拟人手的每一个结点按照虚拟场景下的坐标点运动;这些采用现有技术即可实现,在此不再赘述;步骤a2.通过虚拟人手的运动方向和虚拟人手的手掌垂直向量能够反映用户想要抓取物体的大致方位,能一定程度上表达用户抓取意图,当人手的运动方向和手掌垂直向量大致一致(即θ<10)时才是用户想要真正的抓取方向,计算t帧的抓取方向公式如下:其中为虚拟场景中的虚拟人手的运动方向,pt表示t帧时刻的手掌节点p的坐标,表示虚拟场景中的虚拟人手的手掌的垂直向量,i0t和m0t表示t帧时刻i0与m0(即虚拟人手的食指的第一个关节点、中指的第一个关节点)的坐标。θ为和之间的夹角,当θ<10时,抓取方向dir为:如果θ大于等于10,就认为虚拟人手可能是在任意运动,即运动方向和手掌方向不一致,因此不认为是想要抓取某一物体,只是在场景中任意移动,即不计算抓取方向,不做任何处理。假设虚拟场景中某一虚拟物体的重心坐标为o,其与虚拟人手之间的向量表示为两者之间的距离为与(3)相同可以计算出抓取方向与向量之间的夹角为:所述采集用户的音频信号,对音频信号进行识别和语义分析,根据语义分析得到语音识别结果的操作包括:步骤b1.对输入的音频信号进行语音识别,本发明采用命令控制方的语音识别进行搭建,即采用科大讯飞语音识别sdk识别用户的语音输入,以此增加系统的可靠性。手势识别和语音识别是同时进行的。步骤b2.使用语法规则库进行语音识别:建立语法规则库(这个规则库是在使用本发明方法之前已经建立的,使用该方法时直接使用该规则库就可以了),不同的3d虚拟场景需要建立语法规则库不同,但是可以按照如下规则进行建立(不同的虚拟场景具体的语音命令会有所不同,但是都可以通过图3的规则进行语法划分),首先,将场景中可能出现的短语或关键词作为元素并将其进行分类,然后存入到语法规则词汇库中,限制语音识别的文本范围,有利于提高语音识别的准确率。在语音识别过程中,语音识别根据语法规则中预定义的词汇和结构组成生成识别结果。例如语音“用酒精灯加热那个圆底烧瓶”可以按照表1所示的方式进行解读:主动对象(ao)动作(a)属性(p)被动对象(po)酒精灯加热那个圆底烧瓶表1其中主动对象“酒精灯”和属性“那个”都是可选识别项,因为有可能存在主动对象和属性词汇省略的情况出现,“加热”、“酒精灯”作为语义的关键词,一般情况下即可明确操作者的操作意图。但当关键词在场景中构成的语义命令产生歧义的时候,属性则作为必要识别项,来补充语义命令的完整性,避免歧义,用这种方式建立的语法规则如图3所示。语音识别的结果包括主动对象、动作、属性和被动对象。所述根据所述手势识别结果和语音识别结果进行场景主动转换,协助用户完成操作的操作包括:对于虚拟环境中的基本交互任务,可以看成是在某些情景条件以及相关规则得以匹配的情况下才会触发。因此,通过情景感知技术,预测虚拟交互过程中可能的任务,虚拟场景主动进行转换协助用户完成交互操作,具体转换的流程如图4所示,包括:情景感知、主动对象感知、场景拉近和场景旋转,具体如下步骤c1,情景感知:判断虚拟人手当前是否处于抓取物体状态(根据虚拟手的形状与虚拟手与虚拟物体之间的距离来进行判断,采用现有的多种方法即可实现),如果是,则当前虚拟人手所指向的主动对象为绑定的虚拟物体,如果否,则虚拟人手指向的主动对象为虚拟人手本身。步骤c2.主动对象感知:判断虚拟人手和语音识别结果所指向的主动对象是否为同一个,如果虚拟人手指向的对象aoh与语音识别结果中的主动对象aos为同一个,则进入步骤c3,否则,需要进行主动对象转换。例如,经过步骤b2识别出的语音意图如表2所示:主动对象(ao)动作(a)属性(p)被动对象(po)null加热那个圆底烧瓶表2从表2可以看出,主动对象内容缺省,此时,需要将识别出的语音意图结合情景知识库来识别隐含的信息(通过科大讯飞语音识别sdk识别出的语义和情景知识库获得语音意图所指向的主动对象),即从场景知识库中得到语音识别结果中的主动对象aos为“酒精灯”。而此时虚拟人手中没有任何物体,即虚拟人手指向的对象为虚拟人手本身,那么就需要进行主动对象的转换,即将原先语音识别结果中的主动对象“酒精灯”转换为被动对象po,将语音识别结果中的主动对象aos转换为虚拟人手,然后再进行主动对象是否一致的判断。所述主动对象转换过程可以描述如下:ifaos≠aoh:po←aosaos←aoh步骤c3.接近对象关系感知:如果虚拟场景中存在一个物体o(x1,y1,z1)使得γt<10且则判断为想要接近该物体,那么场景的视角会主动拉近,设虚拟场景中的摄像机的原坐标为c(x2,y2,z2),随着主动对象的移动,视角也向着想接近物体移动,摄像机的新坐标ct(x,y,z)为:当相机坐标与想要接近物体的距离小于等于10时相机不再拉近,进入步骤c4,如果不满足上述条件则继续进行接近对象关系感知的判断,即返回步骤c3;步骤c4.判断被动对象在虚拟场景中是否存在被遮挡的情况,此处的遮挡一般来说是深度上的遮挡,即z轴方向上的遮挡。利用aabb算法为每一个虚拟场景中的物体设置一个包围盒,假设被动对象的坐标为b(x,y,z),其aabb包围盒的两个顶点为(xamin,yamin,zamin)和(xamax,yamax,zamax),遮挡检测即为从相机坐标沿z轴方向向内扫描,直到被动对象的坐标点,判断是否存在一个虚拟物体的包围盒(xpmin,ypmin,zpmin),(xpmax,ypmax,zpmax)在z轴方向上的投影与被动对象的包围盒相交,具体如表3所示:表3如果返回true,即相交,则设所述虚拟物体为遮挡物体,将被动对象的位置与遮挡物体位置互换,即将两者的坐标点进行互换,实现被动物体的前置,然后转入步骤c5,如果没有遮挡,则直接进入步骤c5步骤c5.进行接下来的.用户与虚拟场景的交互动作。具体的交互方法采用现有的多种交互方法即可,不在本发明的保护范围内。需要说明的是,所述主动对象有可能是虚拟人手或者虚拟人手所抓取的物体,所述虚拟物体是指除了主动对象和被动对象之外的虚拟场景中的所有物体,所述遮挡物体是指如果存在一个虚拟物体满足“遮挡”(遮挡条件由“判断遮挡算法”决定),那么该物体为遮挡物体。本发明能够通过融合用户的手势输入和语音输入感知用户的真实意图,即计算机能够知道用户想要对哪个物体进行操作。然后,通过对虚拟场景的感知了解到用户将要操作的行为是否存在交互困难(具体是指主动对象与被动对象是否距离过远,或者被动对象与主动对象之间存在遮挡的情况),如果存在交互困难那么场景会主动的进行拉近摄像头或者交换遮挡物与被动交互对象的位置,从而降低交互难度,使得交互的过程更加高效准确。上述技术方案只是本发明的一种实施方式,对于本领域内的技术人员而言,在本发明公开了应用方法和原理的基础上,很容易做出各种类型的改进或变形,而不仅限于本发明上述具体实施方式所描述的方法,因此前面描述的方式只是优选的,而并不具有限制性的意义。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1