一种基于全相关动态KPLS的故障诊断方法与流程
本发明涉及故障诊断领域,具体涉及一种基于全相关动态kpls的故障诊断方法。
背景技术:
由于现代工业过程在生产流程和自动化程度上都非常复杂,对可靠性和安全性的要求越来越高,系统任何部分的故障都可能导致整个系统故障。因此,早期检测潜在或发生的故障在工业过程中非常重要。在过去的几十年中,多变量统计过程监测(mspm)技术被广泛用于复杂工业过程的故障诊断。mspm主要包括主成分分析(pca),独立成分分析(ica)和偏最小二乘法(pls)。通过使用统计分析方法从大量输入和输出过程数据中提取潜在特征,以诊断工业过程的故障。因此,称为数据驱动方法的mspm通常用于工业系统中的过程监控和故障诊断。
在mspm技术中,pls是复杂工业过程中最常用的数据驱动方法之一。在pls算法中,从过程变量中提取潜在变量。pls的建模目标是使用潜在变量来描述输入和输出变量之间的关系,使用此模型可以通过输入变量预测输出变量,同时pls方法使用不相关的潜变量进行建模和分析。因此,pls具有处理缺陷数据和高度相关的过程数据的能力。针对较为复杂的非线性过程,标准pls不能更好实现的监控和故障监测。为了解决这个问题,已经提出了许多非线性pls方法来克服非线性输入和输出数据。在这些方法中核偏最小二乘法(kpls)是最常用的方法,它是通过引入核函数来解决非线性问题,非线性输入数据被映射到高维特征空间。在高维空间中,将线性不可分割性问题转化为线性分离问题。因此,kpls方法可以有效地解决非线性过程数据的线性化问题。
基于kpls模型,已经提出了许多故障诊断方法并成功应用于工业系统。有些现有技术,提出了动态核偏最小二乘建模方法来建立测量和质量指标之间的动态关系。有些现有技术,开发了一个全核pls(t-kpls)用于非线性质量相关的过程监控,其中输入空间被分为四个部分。有些现有技术,提出了一种定向核偏最小二乘监测方法来提取输出相关变量,构建了输入和输出变量之间更精细的关系。有些现有技术,开发了一种基于最优偏好矩阵(opm)的改进kpls方法,以解决主成分误导性解释的问题,从而调整过程变量的分布和协方差矩阵的特征值。有些现有技术,提出了一种基于多核局部最小二乘法的分散故障检测方法,用于检测大规模工业过程。
尽管标准kpls及其最近的修改方法被广泛用于监视和诊断工业故障,但在工业过程监控中仍然没有完全解决一些问题。在残余子空间中,残差局部变量的显著变化过程仍然与输出变量有关。所以,它使得kpls方法不适合用潜变量来诊断输出相关的故障。因此,有效的故障诊断方法对于现代工业过程仍然是必不可少的。
技术实现要素:
本发明的发明目的是提供一种适合用潜变量来诊断输出相关故障的故障诊断方法。
本发明提供一种基于全相关动态kpls的故障诊断方法,包括以下步骤:
离线建立主元模型,获取统计量控制限;
获取实时运算数据并计算实时统计量;
将统计量控制限与实时统计量进行比对,若实时统计量超出统计量控制则发出报警。
进一步的,
离线建立主元模型,获取统计量控制限包括以下步骤:
获取正常运行的数据;
对正常运行的数据进行预处理;
建立adkpls模型。
进一步的,
所述建立建立adkpls模型步骤包括以下步骤:
第一步:将原始数据集x分为输入变量a和输出变量b两个矩阵,分别确定动态阶次,分别构建增广矩阵φ(x)和y,其集合为增广矩阵xk(x),
xk(x)表示原始训练集x的增广矩阵;
第二步:计算全相关辅助矩阵
此处为计算全相关辅助矩阵,替代原始数据中φ(x)和y的相关性,为辅助矩阵与y进行主元提取得到主要的相关性变量提供依据。
第三步:初始化,
k表示主元个数,uk表示全相关辅助矩阵;
第四步:计算输入向量得分矩阵tk:tk=kuk,
tk表示输出变量的得分矩阵,k表示φ(x)φ(x)t的核运算;
第五步:标准化得分矩阵:tk=tk/||tk||;
第六步:计算输入向量负载矩阵:
pk表示输入向量负载矩阵;
第七步:计算迭代后的
第八步:重复第三部至第七步直到收敛;
第九步:计算与残差矩阵:
kk+1表示更新后的k值;
第十步:返回第四步。
本发明的有益效果是:本发明在输入和输出变量之间建立了更直接的关系。在抽油机生产过程上的仿真结果表明,本发明具有良好的故障检测与识别性能。
附图说明
图1kpls残差子空间与输出变量之间的相关性示意图。
图2基于动态主元分析的故障检测与诊断流程示意图。
图3kpls、adkpls检测故障1结果示意图。
图4故障1所有变量贡献率示意图。
图5kpls、adkpls检测故障2结果示意图。
图6故障2所有变量贡献率示意图。
具体实施方式
传统kpls(kpls表示基于核函数的偏最小二乘算法)在构造输入变量与输出变量时未考虑样本间的动态特性,使故障样本信息易被其他样本掩盖;同时,kpls未考虑所有变量对故障样本的影响,使变量间隐藏信息不能被完全表达。针对以上问题,本发明提出一种基于全相关动态kpls(allcorrelateddynamickpls,adkpls)的非线性化工过程故障诊断方法。该方法首先对原始数据进行动态特征分析研究,使组成的数据矩阵能很好地反映变量间的动态关系。然后分析证明了kpls中输出变量的变化会影响到输入残差空间,设计一个输出变量辅助矩阵,表征输入变量与输出变量的全相关性。最后,采用基于输入变量与输出变量之间的全相关信息构建贡献图以识别故障源变量。与kpls相比,在输入和输出变量之间建立了更直接的关系。在抽油机生产过程上的仿真结果表明,所提方法具有良好的故障检测与识别性能。
下面对本发明所提出方法的推导过程和具体实施方式进行说明。
1动态回归模型
1.1dkpls模型
在抽油机生产过程中,获得的数据中存在着非线性和时序相关性等问题,采用核函数转换为线性问题。针对原始数据中存在的时序相关特性,采用多元回归模型ar(b)使数据间具有动态特征,可表示为:
x(k)=α1x(k-1)+α2x(k-2)+αbx(k-b)
+…+αb+1y(k-1)+αb+2y(k-2)+αky(k-b)+εk(1)
其中,x(k)是动态变量,α1,α2,αd是动态回归系数,εk是动态误差,b是该模型的时滞值。用x(k)=(k-1),(k-2),…,(k-b)表示原始数据矩阵,能够良好地反映变量间动态特征。
1.2自回归模型阶次确定
dakpls实现自相关问题的关键就是要明确自回归阶次b,通常取b=1或2。如果需要更为精确的时滞值阶次,可采用统计假设检验方法。其基本思想是判断各变量之间是否具有自相关性,从而得到更为精确的阶次b。
由多元回归模型推导时滞值b阶的模型为xt=α1xt-1+α2xt-2+…+αpxt-b+εt,经计算得到该模型的残差平方和为sb;同理,b-1阶的模型为xt=α1xt-1+α2xt-2+…+αb-1xt-b+1+εt,残差平方和为sb-1。
假设b0:bp=0成立时,可作f分布统计量为f=sb-sb-1/2sb/(n-2b),选取显著水平α,以分子自由度1,分母自由度n-b,查表得fα。若f>fα,则说明b0不成立,b阶与b-1阶模型之间存在差异,取b阶。反之,取b-1阶。ar模型阶次b确定后,就可以得到原始数据对应的增广矩阵xb如下:
通过分别构建输入变量和输出变量的增广矩阵,使其分别体现数据之间的良好动态特性,挖掘出各自空间中存在的潜在变量,为后续构建辅助矩阵进行相关性分析奠定基础。
2构建adkpls模型
在本节中,提出adkpls算法。根据kpls算法推导输入残差子空间与输出变量的相关性,构建输出变量辅助矩阵,基于动态模型,提出adkpls算法。
2.1kpls算法
在kpls中,输入与输出向量分别建立回归模型如下:
其中,i表示kpls中保留的隐变量个数,通过交叉检验得到,tl为输入向量的得分矩阵,pl为输入向量的负载矩阵,ql为输出向量负载矩阵,φi(x)和
2.2输入残差子空间与输出变量的相关性
kpls中输入残差子空间φi(x)与输出向量y存在着相关性,证明如下:
tl为kpls中的主元得分向量,φi(x)为kpls中的残差向量。
当i≥l时,φit(x)tl=0(5)
公式(4)可以化简为
由于在kpls中输入、输出向量的负载向量pi和qi分别可以写为
pi=φi-1t(x)ti/titti(7)
将公式(7)和(8)带入公式(6)得到
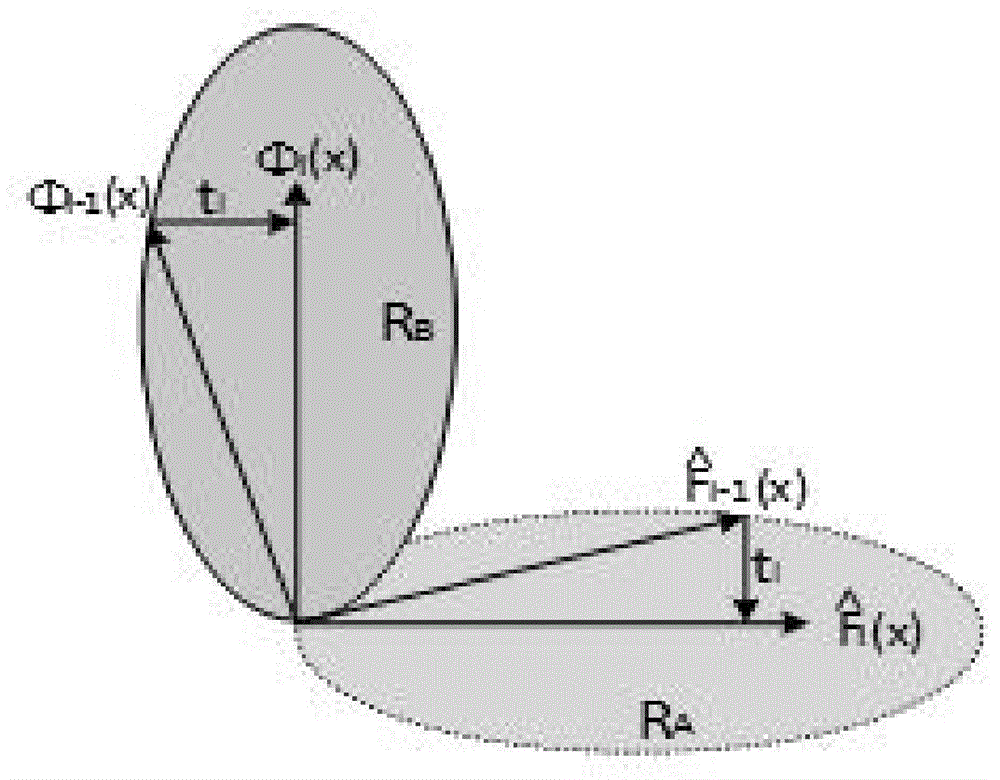
图1所示为kpls残差子空间与输出变量关系图,其中ra为kpls中输入向量φ(x)变化范围,rb为kpls中输出向量y的变化范围,且φi(x)与
2.3构造辅助矩阵
把增广矩阵xk(x)分为输入φ(x)和输出y两个矩阵,并在输出变量中构建辅助矩阵
其中,
对于
因为φ(x)与ξy完全无关,有
cov(φ(x),ξy)=ε(φ(x),ξy)=0(12)
所以公式(11)可以简化为
因此,
其中
为了使输入变量和输出变量之间的协方差达到最大,采用拉格朗日乘子法
其中w1和c1分别是输入变量e0和输出变量f0的轴向量(e0=x和f0=y1),对s分别求关于w1,c1,τ,υ的偏导且置0,记θ=2τ=2υ,则θ是优化问题的目标函数且使θ达到最大必须有
在kpls推导中,公式(16)可以写为
由上得出
φi-1(x)φi-1t(x)f0ci=θφi-1(x)wi(18)
由公式(16)得到
φi-1(x)wi=φi-1(x)φi-1t(x)f0ci/θ(20)
将公式(20)引入(19)结合f0ci=ti有
由
yytφi-1(x)pi=ti(22)
因为φi-1(x)pi=ti,
φi(x)=φ(x)-yytφ(x)/yty(23)
其中,1/yty是用于归一化输出相关变化的值,所以
由于
因为φt(x)φ(x)是一个满秩方阵,
2.4adkpls算法
基于动态回归模型理论上,推导了输入变量残差与输出变量存在着相关性,从而构造全相关辅助矩阵
adkpls具体算法如下表所示:
在模型实现主元提取之前,需对高维空间进行中心化运算:
其中,
3基于adkpls算法的故障检测
与pls和kpls类似,hotelling’st2统计量和spe统计量仍是idkpls故障检测两个重要统计量。t2统计量反映变量在主元空间的变化:
t2=tnewλ-1tnew(27)
其中,λ-1是得分矩阵的协方差的逆。其控制线可通过f分布获得t2=i(n2-1)×f(i,n-i,α)/n(n-i),f(i,n-i,α)是对应于检验水平为α,自由度为i和n-i条件下的f分布临界点。
spe统计量反映样本向量在残差空间投影的变化:
其中,n1是测试数据样本个数,xt=knewuk/(tktknewuk),knew是测试核矩阵。其控制限可通过其近似分布来计算:
其中,
4实验研究
在本节中,通过中国大港油田油井的实际生产数据用于验证本发明提出的算法adkpls的有效性。在实际工业生产中,抽油机的电压和电流参数反映了故障情况,电压和电流数据集不能直接用来建立模型,可通过傅里叶模型变幻得到。本发明在实验中使用抽油机的相应电压和电流数据来建立故障诊断模型,这里故障1是连抽带喷,故障2是气体影响,故障3是供液不足。本发明从2016年11月20日至2018年4月16日抽取了连续1000组数据集,训练集由500组样本数据构成,测试集由500组样本数据构成。在训练集中,前250个数据集是正常样本,后250个数据集是故障样本。在测试集中,前300个数据集是正常样本,后200个数据集是故障样本。
对于故障1,监测结果如图3所示。图3a可以看出,kpls在t2和spe均在第300个样本处发生跳变,但控制线不能很好的检测到故障,正常样本依旧属于故障,误报率结果高。图3b,adkpls在第300个样本成功检测到故障,同时正常样本数值超过控制限较少,效果相对比较明显;spe统计量中正常样本比t2统计量超过控制限明显较少,且输出相对稳定变化,说明输入残差子空间的变化确实受到输出变量的影响。
贡献率通过分析每个变量对检测指标的敏感度来解释故障原因,可以成功定位故障组件。由图4可知,图4a中t2和spe贡献率最大分别是变量5和变量37,图4b中t2和spe贡献最大分别是变量41和变量28,故障1在实际生产中,t2统计量是由变量41引起的故障,即是由于电压、电流引起的故障,从而得到第300个采样点t2统计量贡献图法故障诊断与故障1所描述故障相符。证明通过动态回归模型使使数据间的相关性更为密切。
对于故障2,监测结果如图5所示。图5a可以看出,t2能在第300个样本点处成功检测到故障,同时正常样本数值超过控制限较少,spe因控制限太小,不能正常进行故障检测。图5b中t2和spe均能在第300个样本点处成功检测到故障,并且效果显著。spe统计量中正常样本比t2统计量超过控制限明显较少,且输出相对稳定变化。与kpls相比,adkpls方法在监测故障2方面更有效。
由图6可知,图6a中t2和spe贡献率最大分别是变量23和变量28,图3b中t2和spe贡献最大分别是变量36和变量28。故障2在实际生产中,t2统计量是由变量36引起的故障,spe是由变量28引起的故障,从而得到第300个采样点spe统计量贡献图法故障诊断与故障2所描述故障相符。证明通过adkpls模型对数据间隐藏变量的挖掘,使数据间的相关性更为密切;再构造输入变量与输出变量全相关特征,使数据间故障变量定位更准确。
通过对抽油机生产过程数据进行统计过程监控,利用kpls和adkpls算法得到的各变量贡献率进行分析,最终用t2和spe统计量的误报率和漏报率作为衡量监控性能的指标,结果如下表所示。
表1统计过程监控性能对比(%)
在多故障分类中,计算故障的误报率和漏报率时,其他故障样本被认为是“正常样本”。因此,误报警率是被识别为正常的“故障样本”的数量与正常样本的总数的比率;漏报警率是故障的“正常样本”的数量与故障样本的总数的比率。由表分析可知,所提出算法的误报警率和漏报警率在控制限基础上都比较低,说明基于adkpls的多元统计过程监控方法在抽油机生产过程故障检测与诊断方面具有优良的监控性能,适用于复杂的非线性和动态工业过程。
5结论
在本发明中,结合动态自回归模型,使原始数据间具有强动态性,再分析证明了kpls输入残差变量与输出变量之间的相关性,通过构造全相关辅助矩阵,使输入变量与输出变量全相关。结果证明了adkpls监测方法比kpls监测方法表现出更好的监测性能,表明所提出的adkpls监测方法对于监测质量相关过程更有效。
本发明提出了一种新的数据驱动的adkpls算法用于抽油机系统。首先,全相关性的kpls与动态模型进行关联,构建后的数据能够良好地体现变量间隐藏的动态特性。其次,输出变量的变化会影响到输入残差子空间,通过构建一个输出变量辅助矩阵,使其与所有输入变量具有相关性。最后,在抽油机系统中输入和输出变量之间有着更直接的关系,实验结果表明了所提出的adkpls算法的有效性。
- 还没有人留言评论。精彩留言会获得点赞!