一种GPU通用的形态学加速方法与流程
本发明涉及一种gpu通用的形态学加速方法,属于图像处理技术领域。
背景技术:
形态学是图像处理的一种重要的数学工具,可以解决图像滤波、图像增强、纹理分析、图像重构、边缘检测和图像分割等图像处理问题,已经被广泛应用于计算机视觉、模式识别、遥感监测和生物医学影像等领域。其中,腐蚀和膨胀是最基本的两个形态学操作。
腐蚀和膨胀是将结构元素依次覆盖待处理图像的每个像素,将覆盖区域的局部最大值或最小值作为该点的值。但是随着图像和结构元素的增大,形态学操作需要的时间大大增长,无法满足实时图像处理方面的应用要求。常用的提高腐蚀和膨胀操作速度的方法有结构元素分解、边界元素优先处理,减少重复区域运算等几种方法。分解结构元素的方法一般适用于特定形状的结构元素,基于边界元素优先处理和基于减少重复区域运算的方法适用于二值图像,无法处理灰度图像。
gpu是计算机显卡的核心部件,通常被用于进行复杂的数学和几何计算。目前,主要的gpu型号有amd和nvidia。近年来,由于gpu在浮点计算和并行计算上拥有极其出色的性能,所以被广泛使用在数据挖掘、深度学习等需要大量重复计算的工程之中。gpu强大的并行计算功能能够有效提高形态学操作的速度。目前基于gpu实现形态学加速的方法大多依赖于nvidia公司推出的cuda平台,因此只适用于nvidia公司生产的gpu系列。本发明提出了一种基于gpu的通用的形态学加速方法,对不同形状的结构元素采取不同的处理方法,实现了形态学操作的加速。
技术实现要素:
技术问题:
分解结构元素的方法通用性受限;基于边界元素优先处理和减少重复区域运算的方法只适用于二值图像;利用gpu实现形态学操作的方法大多数依赖于cuda平台。针对这些问题,本发明提出一种gpu通用的形态学加速方法。
技术方案:
基于gpu的形态学加速方法,包括如下步骤:
步骤1:图像大小为p×q,结构元素大小为m×n,扩充图像的边缘,将图像的上下两条边各扩充(m-1)/2个像素,左右两边各扩充(n-1)/2个像素,扩充后图像高度为h,宽度为w,h和w满足:
h=p+m-1
w=q+n-1
填充扩充的区域,填充值为0,求二维结构元素的秩,若秩为1,转到步骤2,若秩不为1,转到步骤3;
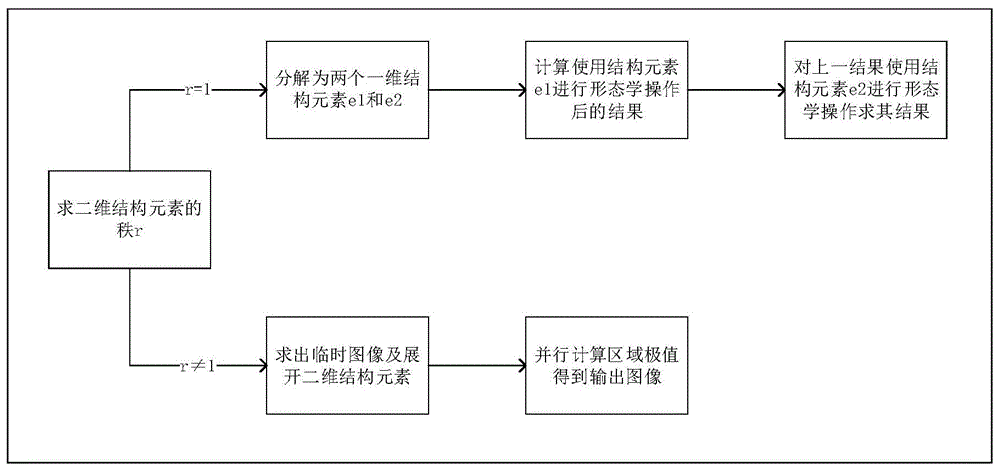
步骤2:将腐蚀和膨胀看作区域内极小值运算和极大值运算,若二维结构元素的秩为1,将二维结构元素分解成两个一维结构元素,即先进行一个垂直方向的极值运算,再进行一个水平方向的极值运算,得到腐蚀或膨胀后的图像;
步骤3:若二维结构元素的秩不为1,建立多个窗口,使得窗口宽度与结构元素宽度相等,窗口高度与填充后图像的高度相等,把每个窗口覆盖区域各展开成一列,得到临时图像,将二维结构元素也展开成一列;
步骤4:给临时图像分配p×q个线程,并行计算每个线程涉及区域的最大值或最小值,得到膨胀或腐蚀后的图像。
进一步地,步骤2中,若二维结构元素的秩为1,将其分解成一个行向量和一个列向量的乘积,行向量取二维结构元素中出现的第一行不全为0的行向量,列向量取二维结构元素中出现的第一列不全为0的列向量,若t为第一行元素不全为0的行向量,s为第一列不全为0的列向量,结构元素表示为
然后先将分解得到的列向量作为结构元素对填充后的图像进行腐蚀或膨胀操作,若将此结构元素从第一行第一列开始由左往右,由上到下逐像素移动,每次移动后求出当前覆盖区域的极值,一共需要p×w次移动;本方法利用gpu的并行计算能力,直接分配p×w个线程,每个线程同时计算结构元素覆盖的不同区域的极值,用yij表示经列向量作为结构元素进行腐蚀或膨胀操作后得到的第i行第j列元素的值,aus表示分解得到的列向量的第u行元素,则列向量作为结构元素膨胀操作后:
yij=max{xi+u-1,j},(1≤i≤p,1≤j≤w,1≤u≤m且aus=1)
接着将上一步计算得到的结果作为当前待处理图像,分解得到的行向量作为结构元素,分配p×q个线程,用zij表示经行向量作为结构元素进行腐蚀或膨胀操作后得到的第i行第j列元素的值即腐蚀或膨胀最终的结果,atv表示分解得到的行向量的第v列元素,并行计算结构元素覆盖区域极值,得到最终的膨胀后的最终的结果,即
zij=max{yi,j+v-1},(1≤i≤p,1≤j≤q,1≤v≤n且atv=1)。
步骤3从填充后图像的第一列开始建立窗口,窗口宽度与结构元素宽度相等,窗口高度与填充后图像的高度相等,即窗口大小为h×n,将窗口逐像素右移得到其余窗口,一共建立q个窗口,利用gpu的并行计算功能,同时把每个窗口覆盖区域各展开成一列,每列有h×n个元素,得到临时图像,临时图像高度为h×n,宽度为q,即
将二维结构元素也展开成一列,即
展开后的结构元素大小为(m×n)×1。
步骤4对于临时图像,每列创建p个线程,每个线程处理的起始像素为该列的第l个像素,l满足
(l-1)%n=0,(1≤l≤nh)
每个线程求该列第l个至第(l+mn-1)个像素的极值,临时图像共q列,一共创建(p×q)个线程,所有线程同时求其涉及的(m×n)个像素的极值,得到腐蚀或膨胀后的图像,用zij表示腐蚀或膨胀操作后得到的第i行第j列元素的值,用符号
其中,若进行膨胀操作
zij=max{xi+c-1,j+d-1},(1≤i≤p,1≤j≤q,1≤c≤m,1≤d≤n且acd=1)。
有益效果
对比于结构元素分解和边界像素优处理、减少重复区域计算的方法,本发明提供的方法可以处理任意形状的结构元素并且可以应用于灰度图;
对比于cuda提供的形态学操作函数,在二维结构元素秩为1时,随着结构元素的增大,本发明实现形态学操作与cuda提供的形态学操作函数相比速度大大提高。
对比于其他基于特定产商生产的gpu的形态学加速方法,本发明的形态学加速方法可以应用于各种型号的gpu。
附图说明
图1为本发明的整体算法示意图。
图2为对原始图像进行边界扩充和填充的示意图。
图3从左往右依次为秩为1的二维结构元素,秩不为1的结构元素示意图。
图4为图3中秩为1的二维结构元素分解示意图。
图5为使用图4中分解得到的两个一维结构元素对图2扩充后的图像进行膨胀操作的示意图。
图6为求临时矩阵以及结构元素展开的示意图。
图7为本发明的结果图。从左往右依次为原始图像(大小为256×272)、使用图3中秩为1的结构元素进行膨胀操作后的图像,使用图3中秩不为1的结构元素进行膨胀操作后的图像。
图8为使用秩为1的结构元素对图7中原始图像进行膨胀操作时,使用本方法与使用cuda提供的函数时间对比。t1表示本方法所需时间,t2表示cuda提供的函数所需时间,结构元素取矩形。可见结构元素增大时,本方法形态学操作速度优于cuda提供的函数。
具体实施方式
为详细说明本发明的技术内容、构造特征、所实现目的及其效果,下面将结合附图对本发明详予说明。
参阅图1,本发明为了解决所述的形态学加速问题,采用到的技术方案是一种基于gpu并行运算的通用方法,包括以下步骤:
步骤1:图像高度为p,宽度为q。结构元素高度为m,宽度为n,将结构元素表示为
首先扩充图像的边缘,将图像的上下两条边各扩充(m-1)/2个像素,左右两边各扩充(n-1)/2个像素,扩充后图像高度为h,宽度为w。h和w满足
h=p+m-1
w=q+n-1
扩充后图像表示为
填充扩充的区域,填充值为0。参阅图2,左边是原图像,大小为4×4,取结构元素大小为3×3,右边是填充后的图像,大小为6×6。
然后求二维结构元素的秩。利用消元法,把二维结构元素看成一个个行向量,秩就是这些行向量的秩,也就是极大无关组中所含向量的个数。参阅图3,左边结构元素的秩为1,右边结构元素秩为2。若秩为1,转到步骤2,若秩不为1,转到步骤3;
步骤2:若二维结构元素的秩为1,将其分解成一个行向量和一个列向量的乘积。行向量取二维结构元素中出现的第一行不全为0的行向量,列向量取二维结构元素中出现的第一列不全为0的列向量。若t为第一行元素不全为0的行向量,s为第一列不全为0的列向量,结构元素可以表示为
参阅图4,将图3左边的秩为1的结构元素分解成一个列向量和一个行向量的乘积。
然后先将分解得到的列向量作为结构元素对填充后的图像进行腐蚀或膨胀操作,若将此结构元素从第一行第一列开始由左往右,由上到下逐像素移动,每次移动后求出当前覆盖区域的极值,一共需要p×w次移动。本方法利用gpu的并行计算能力,直接分配p×w个线程,每个线程同时计算结构元素覆盖的不同区域的极值,用yij表示经列向量作为结构元素进行腐蚀或膨胀操作后得到的第i行第j列元素的值,aus表示分解得到的列向量的第u行元素,则列向量作为结构元素膨胀操作后:
yij=max{xi+u-1,j},(1≤i≤p,1≤j≤w,1≤u≤m且aus=1)
接着将上一步计算得到的结果作为当前待处理图像,分解得到的行向量作为结构元素,分配p×q个线程,用zij表示经行向量作为结构元素进行腐蚀或膨胀操作后得到的第i行第j列元素的值即经腐蚀或膨胀操作得到的最终结果,atv表示分解得到的行向量的第v列元素,并行计算结构元素覆盖区域极值,得到最终的腐蚀或膨胀的最终的结果,即
zij=max{yi,j+v-1},(1≤i≤p,1≤j≤q,1≤v≤n且atv=1)。
参阅图5,将图2中填充后的图像作为待处理图像,结构元素采用图4中的结构元素。先将列向量作为结构元素,分配4×6=24个线程,每个线程同时计算此结构元素覆盖区域的极大值,接着将分解得到的行向量作为结构元素,分配4×4=16个线程,每个线程同时计算此结构元素覆盖区域的极大值,得到膨胀后的数组。
步骤3:参阅图6,从填充后图像的第一列开始建立窗口,窗口宽度与结构元素宽度相等,窗口高度与填充后图像的高度相等,即窗口大小为h×n。将窗口逐像素右移得到其余窗口,一共建立q个窗口,利用gpu的并行计算功能,同时把每个窗口覆盖区域各展开成一列,每列有h×n个元素,得到临时图像,临时图像高度为h×n,宽度为q,即
将二维结构元素也展开成一列,即
展开后的结构元素大小为(m×n)×1。如图6中所示,窗口a、b、c、d覆盖的区域分别展开成临时图像的第一列、第二列、第三列和第四列。展开后的结构元素大小为9×1。
步骤4:参阅图6,对于临时图像,每列创建p个线程,每个线程处理的起始像素为该列的第l个像素,l满足
(l-1)%n=0,(1≤l≤nh)
每个线程求该列第l个至第(l+mn-1)个像素的极值。临时图像共q列,一共创建(p×q)个线程,所有线程同时求其涉及的(m×n)个像素的极值,得到腐蚀或膨胀后的图像,用zij表示腐蚀或膨胀操作后得到的第i行第j列元素的值,用符号
其中,若对图像进行膨胀操作
zij=max{xi+c-1,j+d-1},(1≤i≤p,1≤j≤q,1≤c≤m,1≤d≤n且acd=1)。
图6中临时图像的a列创建了e、f、g、h这4个线程,它们处理的起始像素分别为该列的第1、4、7、10个像素,每个线程处理(3×3=9)个像素,临时图像共4列,一共创建了(4×4=16)个线程,每个线程求出其负责区域的极大值,得到膨胀后的结果。
- 还没有人留言评论。精彩留言会获得点赞!