一种通过减少数据传输实现GPU降耗的方法及系统与流程
本发明属于通过减少数据传输和缓存管理实现gpu降耗的方法及系统,特别涉及一种通过减少数据传输实现gpu降耗的方法及系统。
背景技术:
gpu拥有的众多alu(逻辑执行单元)使其具有高并发和高吞吐量的特性,广泛地应用于大数据处理、神经网络、人工智能等领域,受到了众多研究者和业内人士的欢迎。然而,随着gpu在高性能计算中的广泛应用,导致人们对于gpu的带宽要求也在不断的提高,而带宽的提升通常是伴随着功耗的增加为代价。过高的功耗,其带来的资源消耗十分恐怖,例如美国能源部橡树岭国家实验室的“泰坦”超级计算机,一个计算机节点就能消耗将近500瓦的电量,满负荷运算时功耗可达到8.2兆瓦。另外,功耗的增加使得硬件产生过多的热量,不仅缩短硬件的使用寿命,降低系统的可靠性,还影响着硬件设备性能的发挥,导致较低的能效比。因此,在不过多损害性能的同时,降低gpu的功耗是广大研究者必须解决的问题之一。
gpu功耗主要是由硬件产生。在硬件中,gpu的核心架构、核心的工艺制程和其“堆料”程度、空闲硬件运行等都会产生并影响功耗。gpu集成的晶体管数量越大,功耗就会越大;核心的工艺制程越粗糙,将会导致计算逻辑和硬件组件不能相互兼容,难以实现先进的低功耗架构;gpu的“堆料”程度如pcb基板,其包含的电子元件越多越精密,其功耗也会相应的得到增加;同时,空闲硬件在待机时也会需要能源的支撑,这也会产生部分功耗。
硬件组件之间的数据传输、计算任务执行等操作也会产生功耗。数据传输中的通信访问和副本复制需要相应的能源,当执行不合适的调度或数据复制策略时,就会导致数据冗余和多余的交互操作,同时也会增加功耗。数据爆炸式的增长,使得计算任务操作执行的频率越来越高,这将会消耗大量的资源,同时也会产生更多的能耗。因此,我们需要采取先进的降耗技术,缓解功耗带给系统的负面影响。
为此,全世界的科研人员经过了不懈的努力,提出了各种各样的新方法,这些方法可以被归为三类:(1)硬件方法;(2)中间件方法;(3)软件方法。
1.硬件方法
硬件方法主要是针对gpu的动态体系结构、缓存体系结构和互联网络进行设计,将多种专用控制器节能技术嵌入到现代处理器体系结构中,以降低能源使用,比如grape用于gpu的硬件控制系统,通过协调计算单元的使用、速度和内存速度,在达到指定性能的情况下实现最小化功耗;将内存和功耗管理相结合,定期调整物理内存的大小和超时值,通过关闭硬盘来降低平均功耗。
2.中间件方法
中间件方法是在硬件中部分实现的,硬件使中间件能够根据处理器温度关闭或减慢功能单元。硬件支持的中间件技术包括stop-and-go、动态电压频率缩放(dvfs)、高级配置与电源接口(acpi)和门控技术。其中,stop-and-go是动态电源管理(dpm)技术的最简单形式,dpm主要是通过关闭或改变空闲组件的状态来降低功耗的,而stop-and-go技术是可以在全局和局部范围内实现。在全局范围内,如果其中一个内核达到了制定的阈值温度,则该方案将会关闭整个芯片,直到它冷却下来恢复为止,而在局部范围内,只会关闭过热的内核,其他内核正常运作。
dvfs通过动态调整电压和时钟频率来调节处理器的功耗,通过降低供电电压,可以减少因漏电而产生的功耗,同时降低时钟频率以降低电源电压,再一次降低功耗。acpi是计算设备中有效处理电源管理的行业标准。它为电源管理和监控提供与平台无关的接口,并且允许处理器通过将空闲设备移动到低功耗状态来实现功耗的降低。门控技术分为时钟门控(cg)和功率门控(pg),通过关闭芯片上暂时用不到的功能和它的时钟,从而实现降低静态功耗的目的。
3.软件方法
软件方法通过转移或调度任务来最小化热梯度来实现可预测的性能,其主要包括数据转发、任务调度、任务迁移。数据转发主要是针对片上l1缓存,通过制定策略降低l1数据缓存能耗。任务调度通过调度算法在不同核之间分配任务,以平衡功耗密度。而线程迁移是通过将已分配的线程根据线程的电源配置文件从过热的内核迁移到冷内核以实现功耗的降低。
以上三种方法目前均取得了较好的效果,但还存在进一步提升的空间,比如与硬件相关的方法相比较于软件方法成本比较高,同时硬件方法因为工艺制造水平问题,其对功耗的降低能力有限;在中间件方法中,同样存在着与硬件方法相同的问题,因为是在硬件中实现,这会增加方法构建的硬件成本,具有一定的局限性和复杂性;在软件方法中,cta调度会存在流多处理器(sm)中的负载不平衡问题,导致资源的空闲造成浪费;而防止温度热点的任务调度方案,可能因为频繁的在计算任务之间调度子任务,造成通信流量的增加和不必要的数据复制。因此,如何在不过多影响性能的情况下,进一步降低gpu功耗仍然是研究者需要面临的挑战之一。
技术实现要素:
本发明要解决的技术问题是提出一个通过减少数据传输和缓存管理降低gpu功耗的方法,利用将共享相同数据的线程放在同一个sm中的l1缓存中的思想,避免跨sm访存导致数据传输增加从而增加功耗,同时利用相应的缓存替换策略,降低数据传输频率,在不过多影响性能的情况下,进一步实现功耗的降低。
本发明解决上述技术问题的技术方案如下:
一种通过减少数据传输实现gpu降耗的方法,包括以下步骤:
步骤1、判断所有数据块与线程之间的依赖关系,将共享一个数据块的线程划分到一个线程组,若不同线程组之间有线程重叠,则比较对应数据块之和与缓存空间的大小,根据判断是否进行将多个线程组合为一个线程组的操作;之后,将每个线程组和共享的数据块放入一个流多处理器的l1缓存中;
步骤2、每次向l1缓存中插入数据块之前,首先判断缓存是否已满,若未满则直接将数据块c插入l1缓存,若已满则采取预设缓存替换策略,对l1缓存中的数据块进行淘汰替换。
进一步的,所述步骤1中,按照以下方案对数据块进行存储:设三组线程组a,b,c分别共享数据块a,数据块b和数据块c;na,nb,nc分别为数据块a、数据块b和数据块c的大小,m表示缓存空间大小,先判断线程组之间是否存在重叠线程,再比较数据块之和与缓存空间m的大小:
若线程组a,b存在重叠线程,则比较na+nb与m的值,若na+nb>m,则线程组a,b不能合并,先放入数据块a执行,随后判断线程组b,c是否存在重叠线程,若存在,则比较nb+nc与m的值,若nb+nc大于m则线程组b,c不能合并,先放入数据块b,等数据块b执行完成后放入数据块c;若线程组b,c存在重叠线程,且nb+nc<m,线程组b,c可以合并,数据块a执行完成后直接放入数据块b,c;若线程组b,c不存在重叠线程,放入数据块b,等b执行完成后放入数据块c;
若线程组a,b存在存在重叠线程,且na+nb<m,则线程组a,b可以合并,再判断线程组a,b的并集与线程组c是否存在重叠线程,若存在,则比较na+nb+nc与m的值,若na+nb+nc大于m,线程组a,b并集不能和线程组c合并,先放入数据块a,b,执行完成后放入数据块c;如果线程组a,b并集与线程组c不存在重叠线程,那么也是先放入数据块a,b,执行完成后放入数据块c;
若线程组a,b不存在重叠线程,那么先放入数据块a,再判断线程组b,c是否存在重叠线程,若存在,则比较nb+nc与m的值,若nb+nc大于m,则线程组b,c不能合并,放入数据块b,等b执行完成后放入数据块c;若nb+nc小于m,线程组b,c可以合并,数据块a执行完成后放入数据块b,c;若线程组b,c不存在重叠线程,放入数据块b执行完成后放入数据块c。
进一步的,所述步骤2中的缓存替换策略为:
设待插入l1缓存中的数据块为数据块c,选定l1缓存中最近一次被访问时间长度t最长的数据块j;
将选定数据块j与待插入数据块c大小进行比较:
若nj>nc,则将数据块j与数据块c置换;
若nj<nc,则通过遍历将缓存中各个数据块大小(除数据块j)与数据块c大小进行比较,当缓存中某一数据块的大小大于数据块c的大小时,停止比较,并将其与数据块c进行置换。
一种通过减少数据传输实现gpu降耗的系统,用于判断所有数据块与线程之间的依赖关系,将共享一个数据块的线程划分到一个线程组,若不同线程组之间有线程重叠,则比较对应数据块之和与m之间的大小,根据判断是否进行将多个线程组合为一个线程组的操作;之后,将每个线程组和共享的数据块放入一个流多处理器的l1缓存中;每次向l1缓存中插入数据块之前,首先判断缓存是否已满,若未满则直接将数据块c插入l1缓存,若已满则采取预设缓存替换策略,对l1缓存中的数据块进行淘汰替换。
进一步的,按照以下方案对数据块进行存储:设三组线程组a,b,c分别共享数据块a,数据块b和数据块c;na,nb,nc分别为数据块a、数据块b和数据块c的大小,m表示缓存空间大小,先判断线程组之间是否存在重叠线程,再比较数据块之和与缓存空间m的大小:
若线程组a,b存在重叠线程,则比较na+nb与m的值,若na+nb>m,则线程组a,b不能合并,先放入数据块a执行,随后判断线程组b,c是否存在重叠线程,若存在,则比较nb+nc与m的值,若nb+nc大于m则线程组b,c不能合并,先放入数据块b,等数据块b执行完成后放入数据块c;若线程组b,c存在重叠线程,且nb+nc<m,线程组b,c可以合并,数据块a执行完成后直接放入数据块b,c;若线程组b,c不存在重叠线程,放入数据块b,等b执行完成后放入数据块c;
若线程组a,b存在存在重叠线程,且na+nb<m,则线程组a,b可以合并,再判断线程组a,b的并集与线程组c是否存在重叠线程,若存在,则比较na+nb+nc与m的值,若na+nb+nc大于m,线程组a,b并集不能和线程组c合并,先放入数据块a,b,执行完成后放入数据块c;如果线程组a,b并集与线程组c不存在重叠线程,那么也是先放入数据块a,b,执行完成后放入数据块c;
若线程组a,b不存在重叠线程,那么先放入数据块a,再判断线程组b,c是否存在重叠线程,若存在,则比较nb+nc与m的值,若nb+nc大于m,则线程组b,c不能合并,放入数据块b,等b执行完成后放入数据块c;若nb+nc小于m,线程组b,c可以合并,数据块a执行完成后放入数据块b,c;若线程组b,c不存在重叠线程,放入数据块b执行完成后放入数据块c。
进一步的,所述缓存替换策略为:
设待插入l1缓存中的数据块为数据块c,选定l1缓存中最近一次被访问时间长度t最长的数据块j;
将选定数据块j与待插入数据块c大小进行比较:
若nj>nc,则将数据块j与数据块c置换;
若nj<nc,则通过遍历将缓存中各个数据块大小(除数据块j)与数据块c大小进行比较,当缓存中某一数据块的大小大于数据块c的大小时,停止比较,并将其与数据块c进行置换。
本发明的有益效果为:由于本发明技术是对gpu内部的线程调度和缓存管理方法进行改进,所以相比较于与硬件相关的技术,其成本较低,并且实现方法简单;将共享相同数块的线程放在同一个流多处理器(sm)中,避免了频繁的跨流多处理器(sm)访存,减少了内存争用现象和不必要数据复制状况的出现;本发明技术以减少数据传输的角度,显著地减少了gpu的整体功耗。
附图说明
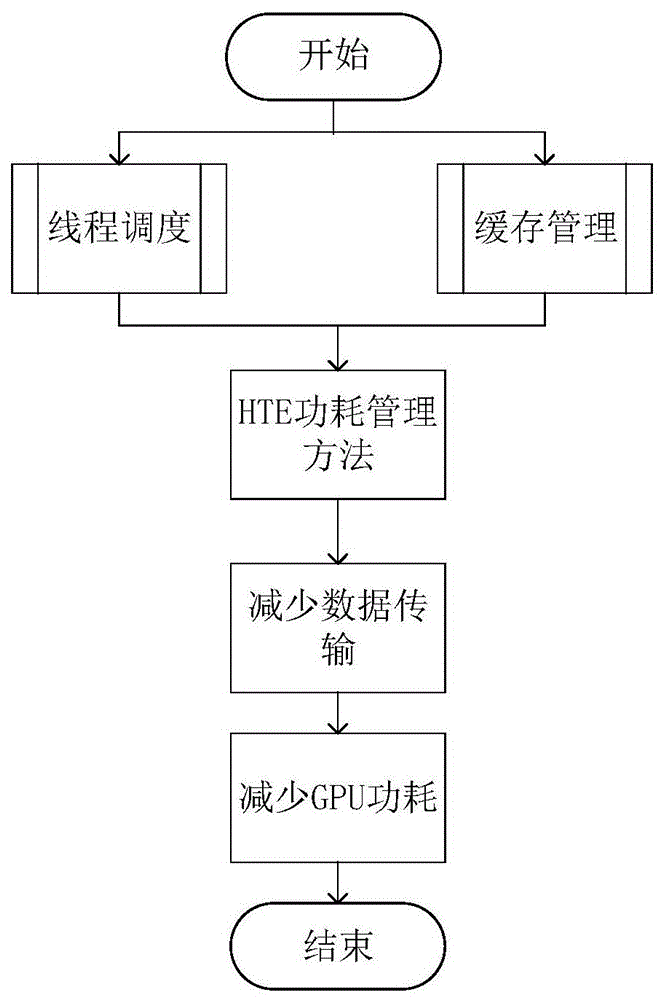
图1是本发明的总体流程示意图;
图2是本发明中根据线程与数据块依赖关系构造的二维矩阵图;
图3为本发明中线程调度策略流程图;
图4是本发明中缓存管理策略流程图。
具体实施方式
以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释本发明,并非用于限定本发明的范围。
图1是本发明的总体流程示意图,提出一个hte功耗管理方法,此方法包含线程调度和缓存管理两个方向,通过减少数据传输,来减少gpu的功耗。
图2是本发明中根据线程与数据块依赖关系构造的二维矩阵图。横排为数据块id,纵排为线程id。当线程与数据块之间存在依赖关系时,即线程需要访问此数据块时,它们之间的关系将被被标记为“1”,如果不需要访问此数据块,它们之间的关系将会被标记为“0”。由于一个线程最多访问两个数据块,所以通常情况下根据依赖关系构造的二维矩阵是一个稀疏矩阵。
图3是本发明中线程调度策略流程图,其主要过程为:
1.对各个线程和数据块进行标记,以进行区分。通常情况下,线程id为:thid=blockidx.x*blockdim.x*blockdim.y+threadidx.y*blockdim.x+threadidx.x(threadidx表示一个线程的索引,blockidx表示一个线程块的索引,blockdim表示线程块的大小)。而各个数据块都增加了一个id字段,用以标识各个数据块进行区分。
2.记录数据块与线程之间的依赖关系,构造二维矩阵;
3.根据二维矩阵,将共享相同数据块的不同线程分为一组线程组,即初步表明这些线程将会被放在同一个sm中的l1缓存中;
4.根据二维稀疏矩阵将共享相同数据块的线程“合并”为线程组,并对存在交集的线程组进行“合并”,直至线程组之间不存在交集。在图2矩阵中,横排表示数据块id,标记为数据块a,b,c,d,e,纵排表示线程id,标记为线程1,2,3,4,5,6。由图可知,数据块a被线程1,2共享;数据块b被线程1,3共享;数据块c被线程4,5共享;数据块d被线程5,6共享;数据块e只有6访问。所以,共享数据块a的线程1,2和共享数据块b的线程1,3存在交集线程1;共享数据块c的线程4,5和共享数据块d的线程5,6存在交集线程5;共享数据块d的线程5,6和需要数据块e的线程6存在交集线程6。为了尽可能地减少数据传输,需要将存在交集的线程组进行“合并”,即线程1,2,3为共享数据块a,b的一组,但是共享数据块c,d的线程4,5,6和共享数据块d,e的线程5,6依旧存在交集线程5,6。根据本文方法的主要思路,通常情况下会将拥有交集的线程组继续“合并”,即线程4,5,6共享数据块c,d,e。
5.由于受到l1缓存空间有限的限制,可能会出现数据块不能同时放入缓存中的情况,所以需要在将线程组进行“合并”之前,比较线程组对应的数据块之和与缓存空间的大小,从而判断是否要对线程组进行合并。流程图中假设共享数据块的数量为3,被表示为数据块a,b,c,对应为线程组a,b,c,na,nb,nc分别为数据块a,b,c的大小,m表示缓存空间大小。根据以上方法实践,会出现以下三种情况:
(1)若线程组a,b存在重叠线程,则比较na+nb与m的值,若na+nb>m,则线程组a,b不能合并,先放入数据块a执行,随后判断线程组b,c是否存在重叠线程,若存在,则比较nb+nc与m的值,若大于m则线程组b,c不能合并,先放入数据块b,等数据块b执行完成后放入数据块c;若线程组b,c存在重叠线程,且nb+nc<m,线程组b,c可以合并,数据块a执行完成后直接放入数据块b,c;若线程组b,c不存在重叠线程,放入数据块b,等b执行完成后放入数据块c;
(2)若线程组a,b存在存在重叠线程,且na+nb<m,则线程组a,b可以合并,再判断线程组a,b的并集与线程组c是否存在重叠线程,若存在,则比较na+nb+nc与m的值,若大于m,线程组a,b并集不能和线程组c合并,先放入数据块a,b,执行完成后放入数据块c;如果线程组a,b并集与线程组c不存在重叠线程,那么也是先放入数据块a,b,执行完成后放入数据块c;
(3)若线程组a,b不存在重叠线程,那么先放入数据块a,再判断线程组b,c是否存在重叠线程,若存在,则比较nb+nc与m的值,若大于m,则线程组b,c不能合并,放入数据块b,等b执行完成后放入数据块c;若小于m,线程组b,c可以合并,数据块a执行完成后放入数据块b,c;若线程组b,c不存在重叠线程,放入数据块b执行完成后放入数据块c。
图4是本发明中缓存管理策略流程图,其主要过程为:
1.对每个数据块添加时间标签字段t,用以记录每个数据块最近被访问的时间,并记录每个数据块大小n,用以之后数据块之间的大小比较;
2.该流程图假设l1缓存中存在的数据块数量为i,其中被选定的数据块由j表示,其大小为nj,插入数据块表示为c,其大小为nc。首先判断缓存是否已满,如果没有满则直接插入,否则对缓存中数据块最近被访问时间t进行排序,选定拥有最久最近被访问时间的数据块j;
3.将选定数据块j与插入数据块c大小进行比较。将会出现以下两种情况:
(1)若nj>nc,则将数据块j与数据块c置换;
(2)若nj<nc,则通过遍历将缓存中各个数据块大小(除数据块j)与数据块c大小进行比较,当缓存中某一数据块的大小大于数据块c的大小时,停止比较,并将其与数据块c进行置换。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!