一种基于提升算法的硬件木马检测方法与流程
本发明属于集成电路检测技术领域,尤其涉及一种基于提升算法的硬件木马检测方法。
背景技术:
随着信息化社会的不断发展,集成电路的规模呈现爆炸性增加的趋势,其安全性不断受到挑战。硬件木马,指的是在硬件电路中被人为刻意加入的电路组成部分,或者是集成电路开发过程中无意留下的缺陷或隐患。与传统软件木马相比,硬件木马具有隐蔽,触发率低,作用机制复杂,一旦触发造成危害极大的特点。
现有的硬件木马检测技术主要分为四大类,分别是需要借助工具的物理检测和旁路分析,以及基于测试的功能测试和内建测试四大类技术。功能测试方法需要自动测试平台,通过输入测试向量的穷举方法进行测试,但是由于测试时间和测试数量比较大,应用范围有限。内建自测技术不需要外部工具,但是在芯片的生产过程中就要加入用于测试的模块,不能实现对整体电路的检测。物理检测和旁路分析需要用到精度较高的检测仪器,物理测试主要的特点是逆向工程剖析,但是只适用于结构较简单的芯片,但是由于其需要较多的投入和检测耗时,并不常用。旁路分析的检测精度高,同时条件限制比较少,并不需要木马被触发就可以实现检测,但是旁路分析所需要的物理量很难精确观察,而且容易受到噪声的影响,所以其实际应用也受到局限性。
技术实现要素:
本发明方法的目的是针对现有硬件木马检测技术的不足,提供一种基于提升算法的硬件木马检测技术,在大样本条件下具有比旁路分析手段更高的准确率。
本发明方法分为三个总步骤,分别为计算每个节点的cc0,cc1和co、dbscan聚类和用svmadaboost对特征点进行分类。
如图4所示,本发明方法的具体技术方案是:
过程一、根据集成电路的拓扑结构进行处理获得集成电路每个节点的第一、第二可控性值cc0、cc1和可观性值co;集成电路的拓扑结构是由节点通过逻辑门连接构成。
过程二、根据集成电路每个节点的第一、第二可控性值cc0、cc1和可观性值co采用matlab进行基于密度的聚类(dbscan),获得带类距离的矩阵x’;
过程三、采用弱分类器进行训练分类,并组合弱分类器获得最终分类器,用svmadaboost对特征点进行训练分类,进而采用最终分类器对待测集成电路处理获得的带类距离的矩阵x’进行处理,获得待测集成电路的硬件木马检测结果,即检测到待测集成电路处理中是否存在硬件木马。
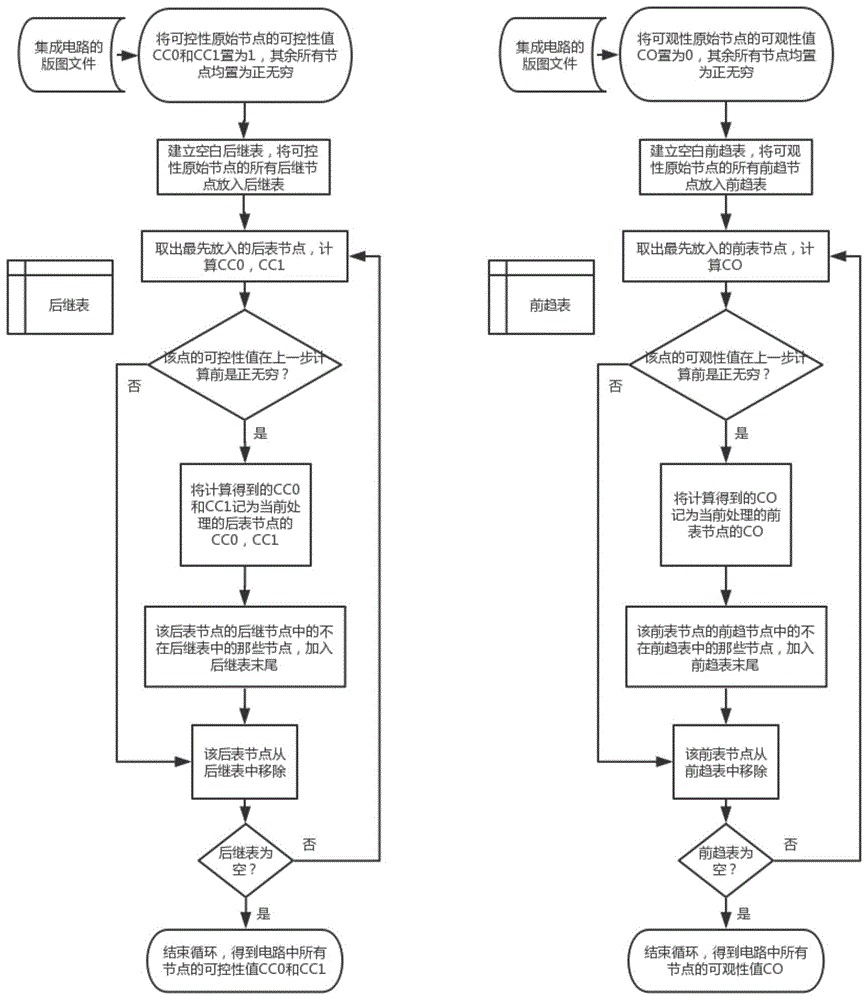
如图1所示,所述过程一,具体为:
步骤(11).首先将该电路的所有输入节点作为可控性原始节点,置其可控性值cc0和cc1为1,同时置所有其他节点的可控性值cc0和cc1为正无穷;
步骤(12).建立一个空白的后继表,将所有可控性原始节点的所有后继节点作为后表节点放入后继表中;
步骤(13)
步骤(13.1).按照后继表中的顺序从后继表中依次取出一后表节点,取出为从后继表中删除后表节点并进行判断,计算其可控性值cc0和cc1;具体实施还可判断:若在此计算过程前,该后表节点可控性值是正无穷,则置为该后表节点的可控性值,否则不做处理。
步骤(13.2).将该后表节点的后继节点加入后继表末尾,若后继表中已有新加入的后继节点,则不再加入后继节点,将该后表节点从后继表中移除;
步骤(14).循环上述步骤(13)针对每个后继表中的后表节点进行处理,直到后继表为空则结束循环,得到电路中所有节点的可控性值cc0和cc1;
步骤(15).首先将电路的所有输出节点作为可观性原始节点,置其可观性值co为0,同时置所有其他节点的可观性值co为正无穷;
步骤(16).建立一个空白的前趋表,将所有可观性原始节点的所有前向节点作为前表节点放入前趋表中;
步骤(17)
步骤(17.1).按照前趋表中的顺序从前趋表中依次取出一前表节点,计算其可观性值co;具体实施中可再判断,若在此计算过程前,该前表节点可观性值是正无穷,则置为该点的可观性值,否则不做处理。
步骤(17.2).将该前表节点的前趋节点加入前趋表末尾,若前趋表中已有这些新加入的前趋节点,则不再加入前趋节点,将该前表节点从前趋表中移除;
步骤(18).循环上述步骤(17)针对每个前趋表中的前表节点进行处理,直到前趋表为空则结束循环,得到电路中所有节点的可观性值co。
本发明的后继节点是指位于逻辑门处理后的节点,前向节点是指位于逻辑门处理前的节点。例如a和b经与门输出c,a、b为c的前向节点,c为a、b的后继节点。
如图2所示,所述过程二,具体为:
所述过程二的基于密度的聚类具体包括:
输入:包含m个对象的数据集合x
邻域半径阈值ε
最大邻域点数m
输出:特征矩阵x’
步骤(21).在matlab中导入过程一得到的集成电路可测性数据x,其为m×6大小的整型矩阵,其中m为集成电路中的节点总数,对应为矩阵的行,集成电路可测性数据x的6列中的第一列代表与门数量na,第二列代表原始门数量np,第三列代表或门数量no,后三列包含着各节点的两个可控性值cc0、cc1和一个可观性值co;
具体实施中,节点的与门na、原始门np、或门no分别均设为该集成电路的与门na、原始门np、或门no的总数。
步骤(22).创建m×1的空白矩阵y,其中每一个元素为经过排序后的k-距离,是指每个节点在与其余所有节点计算相邻距离后排序获得的第k个最近的相邻距离,按照k-距离对各节点对应的行进行升序排序;
具体实施中,k取4,也就是对应的第4个最近点的距离,计算4-距离。
相邻距离为由与门na、原始门np、或门no、两个可控性值cc0、cc1和一个可观性值co的六个参数以欧式距离计算获得。
步骤(23).创建一个m×1大小的元素全为0的处理标志向量v,处理标志向量v的每个元素为节点对应的处理值,若处理标志向量v中的处理值为0,则表示未被处理过,若为1则处理过;
步骤(24).创建元组c,元组c中的元素是集合,元组c中包含多个集合,每一个集合包含着被识别为同一类的节点;
步骤(25).
(25.1).根据处理标志向量v从头到尾遍历矩阵y(此时y中已存放着每个节点的k-距离),找出其中未被处理过且k-距离最大的节点作为当前父节点,计算当前父节点在与所有其余节点之间的相邻距离,取在邻域半径阈值ε内的相邻距离对应的所有其余未处理节点作为子节点,把所有子节点和当前父节点一起归为元组c中的一个集合中,作为同一类;
步骤(25.2).判断该同一类中的节点数量是否超过了预设阈值的最大邻域点数m,若超过最大邻域点数m,则将按照与当前父节点的相邻距离排序,取前m-1个相邻距离最近的子节点和当前父节点一起归为一个集合中作为同一类;
步骤(25.3).对于当前父节点的每个没有与其划分到同一类中的子节点,如果该子节点被处理过(即查看处理标志向量v),则在处理标志向量v不作改变处理;如果该子节点未被处理过(即查看处理标志向量v),则在处理标志向量v标记为已处理,并作为当前子节点p;将当前子节点p与当前父节点的其余各个没有在任何类中的子节点计算相邻距离并将按照与子节点p的相邻距离排序,取相邻距离小于邻域半径阈值ε内的所有节点和子节点p一起归为一个集合中作为同一类,取相邻距离大于或等于邻域半径ε的所有节点一起归为一个集合中作为另一同一类;
步骤(25.4).将所有已在某一类中的节点标记(即在处理标志向量v中把该节点对应的行标记为已处理);
步骤(26).重复上述步骤(25)直到所有的节点都被处理过,则结束,进行下一步;
步骤(27).对于元组c中的同一类,利用与门na、原始门np、或门no、两个可控性值cc0、cc1和一个可观性值co的六个参数运用重心计算同一类的中心得到类的中心坐标,中心坐标为与门na、原始门np、或门no、两个可控性值cc0、cc1和一个可观性值co的六个参数构成;对于每个类,采用欧氏距离计算自身到其他每个类之间的类间距,取最大类间距作为该电路的类距离;
步骤(28).创建对应该集成电路的特征矩阵x’,其为1×7大小的整型矩阵,特征矩阵x’的7列中的第一列代表与门数量na,第二列代表原始门数量np,第三列代表或门数量no,第四列代表集成电路所有节点的第一可控性值的算术平均值,第五列代表所有节点的第二可控性值的算术平均值,第六列代表所有节点的可观性值的算术平均值,第七列代表集成电路的类距离。4、根据权利要求1所述的一种基于提升算法的硬件木马检测方法,其特征在于:
如图2所示,所述过程三,具体为:
步骤(31).利用过程二获得的结果,以若干个电路作为样本,建立有标记的样本训练集d={(x1,y1),·,(xi,yi),··,(xm,ym)},xi是1×7大小的整型矩阵,为第i个电路的特征矩阵x’,yi为该电路是否具有硬件木马的标签,为已知数据,yi属于{-1,1},m是该样本训练集d中的电路数量;
步骤(32).初始化各个弱分类器的权重系数w,w(n)=1/n,n=1,2...,n,w(n)表示第n个弱训练器的权重系数,n表示预先设定的弱分类器总数量;
步骤(33).对n从1到n,对于第n次过程,执行以下步骤:
步骤(33.1).对样本训练集d进行随机采样获取样本数量为m/2(若为小数则向下取整)的样本训练集作为第n个弱分类器的训练集dn;
步骤(33.2).计算训练集dn的标准差γ,以核函数为高斯核,用训练集dn训练弱分类器gn(x’);
步骤(33.3).计算弱分类器gn(x’)在初始的样本训练集d上的分类误差率,其中分类误差率:
其中,en表示该弱分类器gn(x’)在样本训练集d上的分类误差率,i(gn(xi)≠yi)表示第n个弱分类器分类样本训练集d的每一个样本是否被分错的代表值,如果是,则代表值为1,如果分类正确,则代表值为0;
步骤(33.4).计算弱分类器gn(x’)的系数:
步骤(34).重复进行上述步骤,构建最终分类器:
其中,f(x’)表示最终分类器,若f(x’)为1,则特征矩阵x’的集成电路含硬件木马,若f(x’)为-1,则特征矩阵x’的集成电路不含硬件木马,sign表示符号函数,为集成电路的特征矩阵。
所述方法针对集成电路,用于大规模集成电路的硬件木马检测。
具体实施的所述的集成电路有m个节点,节点间通过逻辑门连接,主要是由n1个原始门、n2个与门和n3个或门组成。节点为集成电路的一处工艺点。
所述的弱分类器采用支持向量机svm。
本发明的有益效果是:
本发明第一次利用集成电路的可测学理论和机器学习算法来预测集成电路是否含有硬件木马。在本发明之前,本领域尚未找到一套类似的方法进行任意集成电路的硬件木马分析。同时本发明的机器学习使用了广受好评的dbscan聚类算法,在传统的集成电路评价标准上添加了类密度,可以显著减少分类器的分类错误率。
在技术贡献上,本发明可以直接应用于工业上的硬件木马检测。厂商只需要提供集成电路的版图,本发明中的算法可以直接判断该电路是否含有硬件木马,且流程简单,可以大大提高电路设计人员的故障检测效率。
附图说明
图1为计算电路中每个节点的cc0,cc1,co的步骤流程图;
图2为应用dbscan聚类流程图;
图3为应用svmadaboost训练最终分类器流程图;
图4为本发明的总检测流程图。
具体实施方式
下面结合附图和实施例对本发明作进一步说明。
如图4所示,按照本发明内容的完整方法实施的实施例如下:
从github网站的公开主页上下载以下37个含有硬件木马标签的集成电路版图文件,导入到xilinxise开发环境中,综合,实现,得到其np(原始门数量)na(与门数量)与no(或门数量)。
运用本发明成果,如图1所示流程,在matlab软件中计算每个电路中所有节点的第一第二可控性值和可观性值,并如图2所示流程对每个电路进行聚类分析得到每个电路的特征矩阵x’。将这37个特征矩阵x’作为37行,得到下表:
可以从图中明显的看到,含硬件木马的电路的类距离明显大于不含硬件木马电路的类距离。
设定弱分类器的个数n为20个。如图3所示流程,建立样本训练集并运用python进行训练得到弱分类器后组合成最终分类器。对于这些弱分类器和最终分类器,统计分类错误个数,计算错误率与权重系数。结果如下:
用此训练得到的分类器应用于其他硬件电路检测是否含有硬件木马。
- 还没有人留言评论。精彩留言会获得点赞!