一种基于二维特征点的人脸姿态实时估计方法与流程
本发明涉及人脸识别技术领域,更具体地说,它涉及一种基于二维特征点的人脸姿态实时估计方法。
背景技术:
“人脸识别”是指在视频或图像信息中确定人脸身份的过程。人脸识别包含了人脸检测与特征比对两部分,而人脸检测是指在图像信息中确定人脸位置、大小、姿态等信息,其作为其中的关键技术,近年来已成为模式识别、人脸信息处理领域的热点问题。
人脸检测对图片质量有较高的要求,曝光、人脸大小、模糊、姿态等因素都会对后续的特征比对产生影响,因此在特征比对前需要进行合规判断,曝光、大小、模糊这些信息通过传统的图像处理知识能方便求解出,而由于单张图像的深度信息缺失,人脸姿态的求解难度较大,而人脸识别需要保证人脸角度在合理范围,因此人脸姿态的求解尤为重要。人脸姿态的求解需要提取人脸的相关特征点,目前人脸检测性能较高的主要是mtcnnl2,cascadb等级联式神经网络,人脸特征点越多对于姿态求解越有利,而人脸特征点过多会导致网络结构的复杂化,而检测时间也会受到影响,因此我们需要在少量的特征点情况下寻求一种稳定的姿态求解算法。
现有文献(1)ramanand,zhux.facedetection,poseestimation,andlandmarklocalizationinthewild[c]//proceedingsofthe2012ieeeconferenceoncomputervisionandpatternrecognition(cvpr).2012:2879-2886和(2)fanellig,gallj,vangooll.realtimeheadposeestimationwithrandomregressionforests[c]//cvpr2011.ieee,2011:617-624均提出了一种基于深度学习的方法,即采集大量数据,并标注对应人脸角度,利用神经网络推算出人脸姿态,该类方法需要大量人力采集标注数据,并且当人脸在某个自由度上旋转时能有较好效果,当人脸在多个自由度旋转时效果较差,且文献(2)需要结合深度传感器,实施较困难;而传统的pnp方法在已知一定数量3维点和2维投影点对时能够求解出相对姿态信息,一般特征点较少时该类方法稳定性较差。
为此,提出一种基于二维特征点的人脸姿态实时估计方法。
技术实现要素:
针对现有技术存在的不足,本发明的目的在于提供一种基于二维特征点的人脸姿态实时估计方法,其根据相机成像原理求解出3d点重投影坐标,并根据投影点坐标与观测点坐标关系构建关于重投影误差的最小二乘问题,再结合李代数相关知识求解出最小二乘方程的雅克比矩阵,利用高斯牛顿法在梯度方向上迭代求解最小重投影误差,最终求解出人脸姿态角度,以解决上述背景技术中提出的问题。
为实现上述目的,本发明提供了如下技术方案:
一种基于二维特征点的人脸姿态实时估计方法,包括如下步骤:
步骤一、构建算法模型:
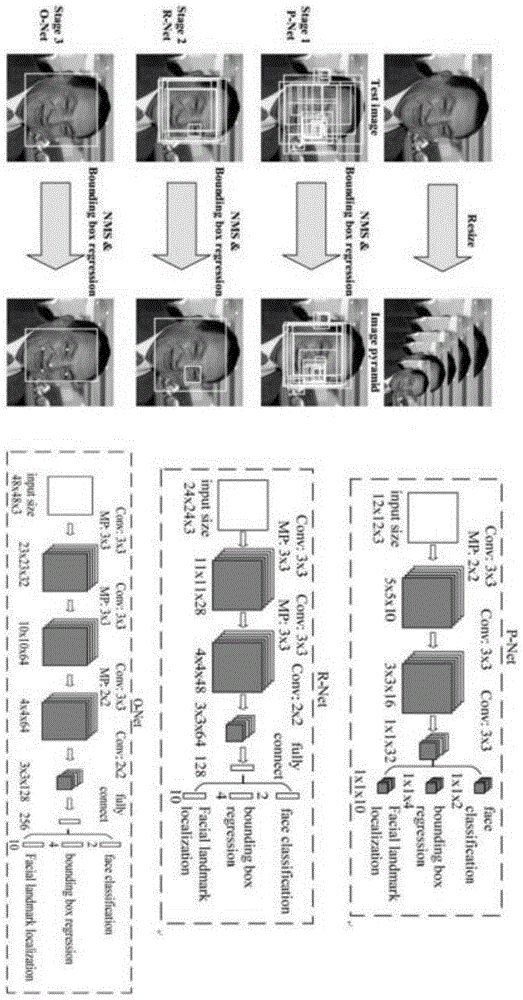
所述算法模型法由三个网络结构组成,三个所述网络结构分别为p-net和r-net以及o-net;
所述p-net用于获取人脸区域的候选窗口和边界框的回归向量,并用该边界框做回归,对候选窗口进行校准,然后通过非极大值抑制nms来合并高度重叠的候选框;
所述r-net用于通过边界框回归和非极大值抑制nms来去掉false-positive区域;
所述o-net用于对人脸区域进行更多的监督,同时用于输出五个特征点;
步骤二:假设已知特征点:
假设已知特征点三维坐标和图像中特征点的二维坐标,根据相机已标定的内参,根据估计位姿rt来估算特征点重投影误差;
考虑n个人脸特征点p以及他们的投影p,求解位姿rt,将位姿表示为李代数形式ξ,特征点三维坐标为
将上式表示为矩阵形式可得:
由于噪声影响,重投影坐标与观测坐标存在误差,因此需要构建最小二乘问题,最小化重投影误差以寻找最优位姿:
上述最小二乘问题采用高斯牛顿法或者lm方法求解,首先将误差线性展开:
由于相机姿态为6个自由度,因此j是一个2x6的矩阵,下面求解j的解析形式,即相机坐标系下人脸特征点坐标为
根据相机投影模型:
展开上式可得:
消去上式中s可得:
而根据链式法则,可知误差关于姿态的导数形式如下:
其中
取出前三维可得:
将两式相乘可得:
上述雅克比矩阵提供了优化过程中的梯度方向,后续利用高斯牛顿法完成姿态的求解:
根据上式可求解
综上所述,本发明主要具有以下有益效果:
本发明,针对少量特征点求解人脸姿态不稳定的问题,提出了一种基于二维特征点的人脸姿态实时估计方法,该方法首先根据相机成像原理求解出3d点重投影坐标,并根据投影点坐标与观测点坐标关系构建关于重投影误差的最小二乘问题,再结合李代数相关知识求解出最小二乘方程的雅克比矩阵,利用高斯牛顿法在梯度方向上迭代求解最小重投影误差,最终求解出人脸姿态角度,且经过实验证明,本发明中构建的算法模型在不同噪声和不同特征点对数量的情况下均具有较高的稳定性,在人脸识别前的合规判断中有重要的应用意义。
附图说明
图1为一种实施方式的基于二维特征点的人脸姿态实时估计方法的算法模型的示意图;
图2为一种实施方式的基于二维特征点的人脸姿态实时估计方法的重投影误差的示意图;
图3为一种实施方式的基于二维特征点的人脸姿态实时估计方法的仿真结果图;
图4为一种实施方式的基于二维特征点的人脸姿态实时估计方法的姿态求解结果图。
具体实施方式
以下结合附图1-4对本发明作进一步详细说明。
实施例
一种基于二维特征点的人脸姿态实时估计方法,如图1-2所示,包括如下步骤:
步骤一、构建算法模型:
所述算法模型法由三个网络结构组成,三个所述网络结构分别为p-net和r-net以及o-net;
所述p-net用于获取人脸区域的候选窗口和边界框的回归向量,并用该边界框做回归,对候选窗口进行校准,然后通过非极大值抑制nms来合并高度重叠的候选框;
所述r-net用于通过边界框回归和非极大值抑制nms来去掉false-positive区域;
所述o-net用于对人脸区域进行更多的监督,同时用于输出五个特征点;
步骤二:假设已知特征点:
假设已知特征点三维坐标和图像中特征点的二维坐标,根据相机已标定的内参,根据估计位姿rt来估算特征点重投影误差;
考虑n个人脸特征点p以及他们的投影p,求解位姿rt,将位姿表示为李代数形式ξ,特征点三维坐标为
将上式表示为矩阵形式可得:
由于噪声影响,重投影坐标与观测坐标存在误差,因此需要构建最小二乘问题,最小化重投影误差以寻找最优位姿:
上述最小二乘问题采用高斯牛顿法或者lm方法求解,首先将误差线性展开:
由于相机姿态为6个自由度,因此j是一个2x6的矩阵,下面求解j的解析形式,即相机坐标系下人脸特征点坐标为
根据相机投影模型:
展开上式可得:
消去上式中s可得:
而根据链式法则,可知误差关于姿态的导数形式如下:
其中
取出前三维可得:
将两式相乘可得:
上述雅克比矩阵提供了优化过程中的梯度方向,后续利用高斯牛顿法完成姿态的求解:
根据上式可求解
本实施例中还提供了对本发明提出的一种基于二维特征点的人脸姿态实时估计方法的实验验证:针对不同噪声以及不同特征点对量下的姿态估计情况,包括了姿态估计时间以及准确率,分别进行了仿真实验和真实实验。
仿真实验
我们在仿真环境中设置虚拟相机焦距为800,而图像大小为
人脸识别应用过程中特征点提取的数量越少,对网络复杂度要求越低,检测与识别速度也越快,本发明所述方法在提取5个特征点的情况下表现较好,能够满足人脸识别的实时性要求。
真实实验
本文也在真实场景对本文算法进行了测试,测试目标为摄像机下不同角度的人脸,如下图所示,图4为stevejobs在斯坦福大学演讲视频中多帧视频的姿态求解结果。在不同角度下本文算法具有较高的稳定性,可应用于人脸识别的合规性检测流程中,满足了识别工作的准确性与实时性要求。
综上所述:本发明,针对少量特征点求解人脸姿态不稳定的问题,提出了一种基于二维特征点的人脸姿态实时估计方法,该方法首先根据相机成像原理求解出3d点重投影坐标,并根据投影点坐标与观测点坐标关系构建关于重投影误差的最小二乘问题,再结合李代数相关知识求解出最小二乘方程的雅克比矩阵,利用高斯牛顿法在梯度方向上迭代求解最小重投影误差,最终求解出人脸姿态角度,且经过实验证明,本发明中构建的算法模型在不同噪声和不同特征点对数量的情况下均具有较高的稳定性,在人脸识别前的合规判断中有重要的应用意义。
本发明中未涉及部分均与现有技术相同或可采用现有技术加以实现。本具体实施例仅仅是对本发明的解释,其并不是对本发明的限制,本领域技术人员在阅读完本说明书后可以根据需要对本实施例做出没有创造性贡献的修改,但只要在本发明的权利要求范围内都受到专利法的保护。
- 还没有人留言评论。精彩留言会获得点赞!