知识图谱构建方法及装置、计算设备、存储介质与流程
知识图谱构建方法及装置、计算设备、存储介质
[0001]
本申请要求于2019年08月26日提交的申请号为201910792526.0、发明名称为“一种知识图谱的构建方法和装置”的中国专利申请的优先权,其全部内容通过引用结合在本申请中。
技术领域
[0002]
本申请涉及云计算技术领域,特别涉及一种知识图谱构建方法及装置、计算设备、存储介质。
背景技术:
[0003]
越来越多的企业已经意识到知识对业务的重要性,迫切需要梳理业务中的知识体系,以提升工作效率和效果。知识图谱(knowledge graph,kg)作为知识组织与知识表示的一种表示形式,使用知识图谱表示知识体系已成为发展趋势。
[0004]
相关技术中,在构建知识图谱时,需要先结合业务所属领域的领域知识设计知识图谱本体模型,然后对业务所涉及的数据进行信息抽取,以获取数据中用于指示实体的信息,然后将抽取到的信息填充到知识图谱本体中,得到知识图谱。
[0005]
该知识图谱的构建过程通常采用定制化模块实现,该定制化模块是按照业务所属领域的领域需求定制的。但是,由于不同领域的需求不同,该定制化模块较难用于构建不同领域的知识图谱,导致其适用性较差。
技术实现要素:
[0006]
本申请提供了一种知识图谱构建方法及装置、计算设备、存储介质,可以解决相关技术中构建知识图谱的方法的适用性较差的问题。
[0007]
第一方面,本申请提供了一种知识图谱构建方法,该方法包括:接收信息抽取指令,信息抽取指令用于指示对构建知识图谱的源数据进行信息抽取采用的信息抽取策略;采用信息抽取指令所指示的信息抽取策略,对源数据进行信息抽取,得到多个多元组数据,每个多元组数据包括:用于指示实体的实体类型的信息、实体属性的信息和关联关系的信息;根据多个多元组数据,构建知识图谱,知识图谱记录源数据所包括的实体及不同实体之间的关系。
[0008]
本申请实施例提供的知识图谱构建方法,通过接收信息抽取指令,确定对构建知识图谱的源数据进行信息抽取采用的信息抽取策略,采用该信息抽取策略对源数据进行信息抽取得到多个多元组数据,然后根据该多个多元组数据构建知识图谱,相较于相关技术,能够根据业务需求配置信息抽取策略,并针对不用领域中的源数据采用不同的信息抽取策略,使得可以根据不同领域中的源数据构建知识图谱,保证了知识图谱构建方法的适用范围,提高了构建知识图谱的灵活性。
[0009]
可选地,在根据多个多元组数据,构建知识图谱之前,该方法还可以包括:获取用于构建知识图谱时需要使用的知识图谱本体模型,知识图谱本体模型定义知识图谱中多元
组数据的标准化描述;接收映射策略指令,映射策略指令用于指示根据多元组数据的标准化描述对多个多元组数据进行关联映射的映射策略;根据多元组数据的标准化描述和映射策略指令所指示的映射策略,对多个多元组数据进行关联映射,得到采用多元组数据的标准化描述进行标准化描述的多个多元组数据。相应的,根据多个多元组数据构建知识图谱的实现过程,包括:根据标准化描述后的多个多元组数据,构建知识图谱。
[0010]
关联映射也称知识映射。该知识映射是指建立从抽取元素与本体元素之间的映射关系,并根据该映射关系采用本体元素对对应的抽取元素进行标准化描述。通过知识映射可以实现多元组数据的统一表示,提高了知识图谱的可读性。
[0011]
在映射策略的一种实现方式中,可以获取每个抽取元素与本体元素的匹配度。当某一抽取元素与一个本体元素的匹配度大于匹配度阈值时,可以建立该抽取元素与该本体元素的映射关系,并指示使用该本体元素对该抽取元素进行标准化描述。
[0012]
在映射策略的另一种可实现方式中,用户可以通过终端配置映射策略。其实现过程包括:用户可以通过终端指示多元组数据中抽取元素与知识图谱本体模型定义的标准化描述的本体元素之间的映射关系,并指示使用本体元素对与其具有映射关系的抽取元素进行标准化描述。
[0013]
通过用户配置映射策略,并使用配置的映射策略对多元组数据进行关联映射,使得知识图谱构建装置能够针对不同类型的数据使用不同的映射策略,能够提高对多元组数据进行关联映射的准确性,提高了知识图谱构建的准确性。
[0014]
可选地,在根据多个多元组数据,构建知识图谱之前,该方法还可以包括:根据指定的多元组数据匹配策略,在多个多元组数据中,确定包括有指示同一实体的信息的不同多元组数据;对包括有指示同一实体的信息的不同多元组数据进行合并处理。相应的,根据多个多元组数据构建知识图谱的实现过程,包括:根据经过合并处理后的多个多元组数据,构建知识图谱。
[0015]
当根据多个源数据构建知识图谱时,用于指示同一实体的信息的表示方式可能不同,若直接根据提取出的多元组数据构建知识图谱,可能会将采用不同表示方式的同一实体当做不同的实体,导致构建的知识图谱无法准确反映源数据体现的内容。通过对包括有用于指示同一实体的元素的不同多元组数据进行合并处理,并根据经过合并处理后的多元组数据构建知识图谱,能够提高构建的知识图谱的准确性。
[0016]
在一种可实现方式中,在根据指定的多元组数据匹配策略,在多个多元组数据中,确定包括有指示同一实体的信息的不同多元组数据之前,该方法还包括:接收匹配策略指令,匹配策略指令用于指示判断不同多元组数据中是否包括有指示同一实体的信息的匹配算法和匹配度阈值。相应的,根据指定的多元组数据匹配策略,在多个多元组数据中,确定包括有指示同一实体的信息的不同多元组数据的实现过程,包括:当根据匹配策略指令所指示的匹配算法,确定两个多元组数据中指示实体的信息的匹配度不小于匹配度阈值时,确定两个多元组数据包括有指示同一实体的信息。
[0017]
通过匹配策略指令选择匹配算法,并使用选择的匹配算法判断不同多元组数据中是否包括有指示同一实体的元素,使得能够对基于不同领域中的数据获得的元素采用不同的匹配算法,能够提高知识映射的灵活度和获取匹配度的准确性,提高了知识图谱构建的准确性和全面性。
[0018]
可选地,源数据包括:来源不同的多路数据。也即是,本申请实施例提供的知识图谱构建方法能够针对多路数据构建知识图谱。相应的,采用信息抽取指令所指示的信息抽取策略,对源数据进行信息抽取,得到多个多元组数据的实现过程,可以包括:分别采用信息抽取指令所指示的对每路数据进行信息抽取采用的信息抽取策略,对每路数据进行信息抽取,得到分别与多路数据对应的多个多元组数据。此时,根据多个多元组数据,构建知识图谱的实现过程,包括:根据与多路数据对应的多个多元组数据,构建知识图谱。这样一来,能够提高根据多路数据构建知识图谱的构建效率。
[0019]
其中,在根据多个多元组数据,构建知识图谱之后,该方法还可以包括:在确定源数据发生更新后,根据信息抽取指令所指示的策略,对更新后的源数据中的增量数据进行信息抽取,得到增量数据对应的多个多元组数据;根据增量数据对应的多个多元组数据更新知识图谱。
[0020]
通过对知识图谱进行增量更新,能够减小根据更新后的源数据构建知识图谱过程中的额计算量,可以提高构建知识图谱的构建效率。
[0021]
在一种可实现方式中,采用信息抽取指令所指示的信息抽取策略,对源数据进行信息抽取的实现过程,可以包括:采用信息抽取指令所指示的ai模型,对源数据进行信息抽取。其中,ai模型为已经过训练的模型,且ai模型的训练样本使用知识图谱本体模型中多元组数据的标准化描述进行标注,知识图谱本体模型定义知识图谱中多元组数据的标准化描述。
[0022]
由于ai模型的训练样本是使用知识图谱本体模型中多元组数据的标准化描述进行标注的,当使用该标注样本训练得到的ai模型抽取信息时,采用该ai模型抽取到的多元组数据是采用知识图谱本体模型中定义的本体元素表示的信息,这样能够减少后续根据本体元素对抽取出的多元组数据进行标准化描述的过程,简化知识图谱构建的过程,提高知识图谱的构建效率。
[0023]
第二方面,本申请提供了一种知识图谱构建装置,该装置包括:接收模块,用于接收信息抽取指令,信息抽取指令用于指示对构建知识图谱的源数据进行信息抽取采用的信息抽取策略;抽取模块,用于采用信息抽取指令所指示的信息抽取策略,对源数据进行信息抽取,得到多个多元组数据,每个多元组数据包括:用于指示实体的实体类型的信息、实体属性的信息和关联关系的信息;构建模块,用于根据多个多元组数据,构建知识图谱,知识图谱记录源数据所包括的实体及不同实体之间的关系。
[0024]
可选地,该装置还包括:获取模块,用于获取用于构建知识图谱时需要使用的知识图谱本体模型,知识图谱本体模型定义知识图谱中多元组数据的标准化描述;接收模块,还用于接收映射策略指令,映射策略指令用于指示根据多元组数据的标准化描述对多个多元组数据进行关联映射的映射策略;映射模块,用于根据多元组数据的标准化描述和映射策略指令所指示的映射策略,对多个多元组数据进行关联映射,得到采用多元组数据的标准化描述进行标准化描述的多个多元组数据。
[0025]
相应的,构建模块,具体用于:根据标准化描述后的多个多元组数据,构建知识图谱。
[0026]
可选地,该装置还包括:确定模块,用于根据指定的多元组数据匹配策略,在多个多元组数据中,确定包括有指示同一实体的信息的不同多元组数据;合并模块,用于对包括
有指示同一实体的信息的不同多元组数据进行合并处理。
[0027]
相应的,构建模块,具体用于:根据经过合并处理后的多个多元组数据,构建知识图谱。
[0028]
可选地,该接收模块,还用于接收匹配策略指令,匹配策略指令用于指示判断不同多元组数据中是否包括有指示同一实体的信息的匹配算法和匹配度阈值。
[0029]
相应的,确定模块,具体用于:当根据匹配策略指令所指示的匹配算法,确定两个多元组数据中指示实体的信息的匹配度不小于匹配度阈值时,确定两个多元组数据包括有指示同一实体的信息。
[0030]
其中,源数据包括:来源不同的多路数据,此时,抽取模块,具体用于:分别采用信息抽取指令所指示的对每路数据进行信息抽取采用的信息抽取策略,对每路数据进行信息抽取,得到分别与多路数据对应的多个多元组数据。
[0031]
相应的,构建模块,具体用于:根据与多路数据对应的多个多元组数据,构建知识图谱。
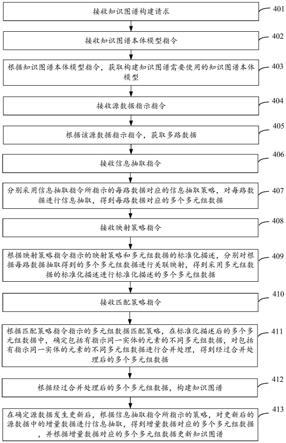
[0032]
可选地,该抽取模块,还用于在确定源数据发生更新后,根据信息抽取指令所指示的策略,对更新后的源数据中的增量数据进行信息抽取,得到增量数据对应的多个多元组数据;
[0033]
相应的,构建模块,还用于根据增量数据对应的多个多元组数据更新知识图谱。
[0034]
可选地,该抽取模块,具体用于:采用信息抽取指令所指示的ai模型,对源数据进行信息抽取;其中,ai模型为已经过训练的模型,且ai模型的训练样本使用知识图谱本体模型中多元组数据的标准化描述进行标注,知识图谱本体模型定义知识图谱中多元组数据的标准化描述。
[0035]
第三方面,本申请提供了一种计算设备,该计算设备包括处理器和存储器;存储器中存储有计算机程序;处理器执行计算机程序时,计算设备实现第一方面提供的知识图谱构建方法。
[0036]
第四方面,本申请提供了一种非易失性的存储介质,当存储介质中的指令被处理器执行时,实现第一方面提供的知识图谱构建方法。
附图说明
[0037]
图1是本申请实施例提供的一种知识图谱构建装置的部署示意图;
[0038]
图2是本申请实施例提供的另一种知识图谱构建装置的部署示意图;
[0039]
图3是本申请实施例提供的一种计算设备的结构示意图;
[0040]
图4是本申请实施例提供的一种知识图谱构建方法的流程图;
[0041]
图5是本申请实施例提供的一种根据两路数据构建知识图谱的逻辑框图;
[0042]
图6是本申请实施例提供的一种选择知识图谱本体模型的界面示意图;
[0043]
图7是本申请实施例提供的一种知识图谱本体模型的示意图;
[0044]
图8是本申请实施例提供的一种选择源数据的界面示意图;
[0045]
图9是本申请实施例提供的一种选择信息抽取策略的界面示意图;
[0046]
图10是本申请实施例提供的一种选择映射策略的界面示意图;
[0047]
图11是本申请实施例提供的一种选择匹配策略的界面示意图;
[0048]
图12是本申请实施例提供的一种知识图谱的示意图;
[0049]
图13是本申请实施例提供的一种知识图谱构建装置的结构示意图;
[0050]
图14是本申请实施例提供的一种知识图谱构建装置的结构示意图。
具体实施方式
[0051]
为使本申请的目的、技术方案和优点更加清楚,下面将结合附图对本申请实施方式作进一步地详细描述。
[0052]
为便于理解本申请实施例提供的知识图谱构建方法,下面先对知识图谱的相关知识进行介绍。
[0053]
知识图谱是一种语义网络,其用图的形式描述客观事物。知识图谱由许多节点及不同节点之间的连接组成。节点用于表示人或组织等实体的实体类型或实体属性。节点之间的连接 (也称作边)表示节点所表示的实体之间具有某种关联关系。其中,实体可以使用实体类型、实体属性和关联关系共同表示。表示某实体的实体类型的节点与表示该实体的实体属性的节点之间的关联关系可以包括:该实体类型与该实体属性之间的归属关系。表示某实体的实体类型的节点与表示其他实体的实体类型之间的关联关系可以包括:该实体与该其他实体之间的外部联系。
[0054]
在本申请实施例中,知识图谱可以应用于多种应用场景。例如,在信息推荐系统中,可以基于知识图谱进行信息推荐。或者,在文本分类过程中,可以基于知识图谱进行分类。或者,在语义搜索过程中,可以基于知识图谱进行搜索。或者,在故障分析系统中,针对出现的故障,可以根据知识图谱所呈现的各个实体的属性和实体之间的关联关系,确定出现故障的原因,实现故障的分析等。
[0055]
实体是具有可区别性且独立存在的某种事物。如某一个人、某一个城市、某一种植物或某一种商品等。实体是知识图谱中的最基本元素,不同的实体间存在的关系可能不同,且不同实体具有的实体属性可能不同。
[0056]
例如,在表示某演员基本信息的知识图谱中,节点可以表示该演员的家庭成员、朋友、合作伙伴、代表作品、经纪公司和毕业院校等实体类型;或者,节点可以表示各个实体类型所指示的实体的演员的姓名、身高和国籍等实体属性;表示实体类型的节点与表示实体属性的节点之间的边,可以表示该实体属性与该实体类型的归属关系;表示该演员的节点与表示家庭成员的节点之间的边可以表示该演员与家庭成员之间的夫妻关系、父女关系和父子关系等;表示该演员的节点与表示朋友的节点之间的边可以表示该演员与朋友之间的朋友关系;表示该演员的节点与表示合作伙伴的节点之间的边可以表示该演员与合作伙伴之间的合作关系;表示该演员的节点与表示演员的代表作品的节点之间的边可以表示该演员与该演员的代表作品之间的归属关系;表示该演员的节点与表示经纪公司的节点之间的边可以该演员与经纪公司之间的合约关系;表示该演员的节点与表示毕业院校的节点之间的边可以表示该演员与毕业院校之间的关系。
[0057]
在知识图谱中,可以通过多元组数据组织数据。该多元组数据可以包括三元组数据、四元组或五元组等。其中,三元组数据的表示形式包括:“节点-边-节点”和“节点-属性名-属性值”。三元组中第一个词语可视为主语,三元组中第二个词语可视为谓语,三元组中第三个词语可视为宾语,该主谓宾的关系即为三元组中第一个词语和第三个词语之间的关
系。示例地,在使用表示形式“节点-属性名-属性值”表示的三元组数据“曹操-小名-阿瞒”中,主语是曹操,谓语是小名,宾语是阿瞒,该主谓宾的关系为曹操的小名是阿瞒,该关系即为用于表示“曹操”的节点与用于表示“阿瞒”的属性值之间的关系。
[0058]
本申请实施例提供了一种知识图谱构建方法,通过接收信息抽取指令,确定对构建知识图谱的源数据进行信息抽取采用的信息抽取策略,并采用该信息抽取策略对源数据进行信息抽取得到多个多元组数据,然后根据该多个多元组数据构建知识图谱,相较于相关技术,能够根据业务需求配置信息抽取策略,并针对不用领域中的源数据采用不同的信息抽取策略,使得可以根据不同领域中的源数据构建知识图谱,保证了知识图谱构建方法的适用范围,提高了构建知识图谱的灵活性。
[0059]
本申请实施例提供的知识图谱构建方法可以由知识图谱构建装置执行。该知识图谱构建装置可以通过有线网络或无线网络,与终端建立通信连接,使得终端可以通过该通信连接向知识图谱构建装置发送指令,以控制知识图谱构建装置根据该指令所指示的内容执行本申请实施例提供的知识图谱构建方法。例如,终端可以向知识图谱构建装置发送指示获取用于构建知识图谱的源数据的指令,知识图谱构建装置接收到该指令后,可以根据该指令获取源数据,并根据源数据执行本申请实施例提供的知识图谱构建方法。或者,终端可以向知识图谱构建装置发送信息抽取指令,知识图谱构建装置接收到该信息抽取指令后,可以采用该信息抽取指令指示的信息抽取策略对源数据进行信息抽取,并根据抽取得到的多个多元组数据构建知识图谱。
[0060]
其中,终端可以为智能手机、笔记本电脑、平板电脑、个人台式电脑和智能摄相机等。且该终端中可以安装有客户端,用户可以通过该客户端与知识图谱构建装置交互。或者,用户也可以通过终端中的网页与知识图谱构建装置交互。
[0061]
图1是本申请实施例提供的一种知识图谱构建装置的部署示意图,如图1所示,该知识图谱构建装置01可部署在云环境中。云环境是云计算模式下利用基础资源向用户提供云服务的实体。云环境包括云数据中心和云服务平台,云数据中心包括云服务提供商拥有的大量基础资源。例如云数据中心包括计算资源、存储资源和网络资源等,且该计算资源可以是大量的计算设备(例如服务器)。可选的,知识图谱构建装置01可以独立地部署在云数据中心中的服务器或虚拟机上,或者,知识图谱构建装置01可以分布式地部署在云数据中心中的多台服务器上,或者,知识图谱构建装置01可以分布式地部署在云数据中心中的多台虚拟机上,再或者,知识图谱构建装置01可以分布式地部署在云数据中心中的服务器和虚拟机上。
[0062]
如图1所示,知识图谱构建装置01可以由云服务提供商在云服务平台上,抽象成一种构建知识图谱的云服务,用户在云服务平台购买该云服务后,云环境可以利用该知识图谱构建装置01向用户构建知识图谱的云服务。并且,用户可以在终端上通过应用程序接口 (application program interface,api),或者云服务平台提供的网页界面,将用于构建知识图谱的源数据上传至云环境,以供知识图谱构建装置01根据该源数据构建知识图谱。在完成知识图谱构建后,知识图谱构建装置01可以将构建得到的知识图谱发送至用户使用的终端,或者将知识图谱存储在云环境,例如:呈现在云服务平台的网页界面上,以供用户查看。
[0063]
除此之外,该知识图谱构建装置01的部署方式还可以有多种。在另一种部署方式
中,该知识图谱构建装置01可以在逻辑上分成多个部分,每个部分具有不同的功能,该多个部分可以分布式地部署在不同的环境中,部署在不同环境中的多个部分协同实现为用户构建知识图谱的功能。例如:如图2所示,该多个部分可以分别部署在终端计算设备、边缘环境和云环境中的任意两个或三个中。终端计算设备包括:终端服务器、智能手机、笔记本电脑、平板电脑、个人台式电脑和智能摄相机等。边缘环境为包括距离终端计算设备较近的边缘计算设备集合的环境。边缘计算设备包括:边缘服务器、拥有计算力的边缘小站等。
[0064]
应理解的是,本申请不对知识图谱构建装置01的哪些部分具体部署在什么环境进行限制性的划分,实际应用时可根据终端计算设备的计算能力、边缘环境和云环境的资源占有情况或具体应用需求进行适应性的部署。
[0065]
在知识图谱构建装置01的又一种部署方式中,当知识图谱构建装置01为软件装置时,该知识图谱构建装置01可以由服务提供商以应用程序的形式发布,用户可以将该应用程序下载至用户使用的终端中,并在终端中使用该知识图谱构建装置01的功能。
[0066]
在知识图谱构建装置01的再一种部署方式中,知识图谱构建装置01也可以单独部署在任意环境的一个计算设备上。如图3所示,该计算设备100可以包括总线101、处理器102、通信接口103和存储器104。处理器102、存储器104和通信接口103之间通过总线101 通信。
[0067]
其中,处理器102可以是硬件芯片,该硬件芯片可以是专用集成电路(application-specific integrated circuit,asic),可编程逻辑器件(programmable logic device,pld)或其组合。上述pld可以是复杂可编程逻辑器件(complex programmable logic device,cpld),现场可编程逻辑门阵列(field-programmable gate array,fpga),通用阵列逻辑(generic array logic, gal)或其任意组合。处理器810也可以是通用处理器,例如,中央处理器(central processing unit,cpu),网络处理器(network processor,np)或者cpu和np的组合。
[0068]
存储器104可以包括易失性存储器(volatile memory),例如随机存取存储器(random access memory,ram)。存储器104还可以包括非易失性存储器(non-volatile memory, nvm),例如只读存储器(read-only memory,rom),快闪存储器,hdd或ssd。存储器 104中存储有用于构建知识图谱的可执行代码,处理器102读取存储器104中的该可执行代码以执行本申请实施例提供的知识图谱构建方法。存储器104中还可以包括操作系统等其他运行进程所需的软件模块和数据等。且操作系统可以为 linux
tm
,unix
tm
,windows
tm
等。
[0069]
图4为本申请实施例提供的一种知识图谱构建方法的流程图。该知识图谱构建方法可以根据一路数据或多路数据构建知识图谱,下面以根据多路数据构建知识图谱,且构建知识图谱的过程由知识图谱构建装置执行为例,对该知识图谱构建过程进行说明。同时,为便于理解,本申请实施例还提供了根据两路数据(分别为源数据1和源数据2)构建知识图谱的逻辑框图(图5)。如图4和图5所示,知识图谱构建方法包括以下步骤:
[0070]
步骤401、接收知识图谱构建请求。
[0071]
在用户需要采用知识图谱构建装置构建知识图谱时,可以通过终端向知识图谱构建装置发送知识图谱构建请求,以请求构建知识图谱。
[0072]
步骤402、接收知识图谱本体模型指令。
[0073]
知识图谱本体模型指令用于指示构建知识图谱所使用的知识图谱本体模型。知识
图谱本体模型(也称本体,ontology)是知识图谱的骨架和基础。知识图谱本体模型是对特定领域中的多元组数据的标准化描述。也即是,该知识图谱本体规定了知识图谱中应该包括的用于指示实体的实体类型的标准化描述、实体属性的标准化描述和关联关系的标准化描述等多元组数据中元素的标准化描述。由于知识图谱本体规定了知识图谱中应该包括的多元组数据的标准化描述,根据知识图谱本体模型构建知识图谱,可以避免知识图谱中包括无用信息,并保证知识图谱中的实体类型、实体属性和关联关系等元素能够采用统一方式进行描述。其中,为便于描述,将通过信息抽取得到的多元组数据中的元素称为抽取元素,将多元组数据中元素的标准化描述称为本体元素。
[0074]
用户可以通过终端向知识图谱构建装置发送知识图谱本体模型指令,以指示构建知识图谱时需要使用的知识图谱本体模型。并且,该知识图谱本体模型指令中可以携带有该知识图谱本体模型。或者,该知识图谱本体模型指令中可以携带有知识图谱本体模型的标识号或存储地址,以便于知识图谱构建装置能够根据该知识图谱本体模型指令获取对应的知识图谱本体模型。
[0075]
其中,知识图谱构建装置的部署环境中可以存储有知识图谱本体模型,且该存储的知识图谱本体模型可以为在知识图谱构建装置中构建的模型,也可以为在终端中构建并存储在该部署环境中的模型。并且,为提高构建知识图谱的灵活性,该知识图谱构建装置除了具有创建知识图谱本体模型的功能,还可以具有对已创建的知识图谱本体模型进行修改和删除,及对知识图谱本体模型中的本体元素进行增加、删除和修改的功能。
[0076]
在一种可实现方式中,知识图谱构建装置的部署环境中可以预先存储有多个备选的知识图谱本体模型,此时,用户可以通过终端在知识图谱构建装置的设置界面中选择知识图谱本体模型,并在选择完成后,可以通过在设置界面中执行指定操作,以触发发送知识图谱本体模型指令。示例的,图6是本申请实施例提供一种知识图谱构建装置的设置界面的示意图,如图6所示,用户可以在该设置界面中选择构建知识图谱时需要使用的知识图谱本体模型,并点击“下一步”按钮,以触发发送知识图谱本体模型指令。
[0077]
步骤403、根据知识图谱本体模型指令,获取构建知识图谱需要使用的知识图谱本体模型。
[0078]
知识图谱构建装置接收到知识图谱本体模型指令后,可以按照知识图谱本体模型指令的指示获取知识图谱本体模型。例如,当知识图谱本体模型指令中携带有知识图谱本体模型的标识号时,知识图谱构建装置可以根据该标识号,在其部署环境中查找该标识号所指示的知识图谱本体模型,以得到该标识号所指示的知识图谱本体模型。
[0079]
示例地,图7为根据步骤402中的知识图谱本体模型指令,获取的知识图谱本体模型的示意图。如图7所示,该知识图谱本体模型定义了知识图谱中应包括的实体的实体类型标准化描述、实体属性的标准化描述和关联关系的标准化描述。其中,知识图谱中应包括的实体类型(如图7中的实心圆点所示)有:人物、歌曲和电影等实体类型。人物的实体属性(如图7中的空心圆点所示)包括:名字、生日、国籍、身高和性别。歌曲的实体属性包括:发布日期和名称。电影的实体属性包括:上映时间和上映国家。人物与人物之间的关联关系包括:配偶关系、氏族成员关系、父母关系和亲子关系。人物与歌曲之间的关联关系包括:演唱关系。人物与电影之间的关联关系包括:主演关系或导演关系。电影与歌曲之间的关联关系包括:使用关系。
[0080]
需要说明的是,在构建知识图谱的过程中,可以根据业务需求确定是否执行步骤402。并且,知识图谱构建装置中可以默认配置有用于构建知识图谱的知识图谱本体模型,在不执行步骤402时,在该步骤403中,知识图谱构建装置可以获取该默认配置的知识图谱本体模型,并使用该默认配置的知识图谱本体模型构建知识图谱。但是,当执行步骤402时,若根据应用需求选择知识图谱本体模型,能够针对不同领域使用不同的知识图谱本体模型,能够提高构建的知识图谱与领域的适配度,进而提高知识图谱构建的准确性。
[0081]
步骤404、接收源数据指示指令。
[0082]
终端可以向知识图谱构建装置发送源数据指示指令,该源数据指示指令用于指示构建知识图谱的源数据。在一种可实现方式中,该源数据指示指令中可以携带有用于构建知识图谱的源数据。在另一种可实现方式中,该源数据指示指令中可以携带有用于构建知识图谱的源数据的存储地址,以通知知识图谱构建装置在该存储地址所指示的存储位置中获取源数据。
[0083]
示例地,当知识图谱构建装置部署在云环境中时,用户可以通过终端预先将源数据存储在云数据中心中,并通过终端向知识图谱构建装置发送源数据指示指令,且该源数据指示指令携带有源数据在云数据中心中的存储地址,以通知知识图谱构建装置根据该存储地址在云数据中心中获取该源数据。
[0084]
并且,源数据指示指令所指示的源数据可以为经过预处理的数据。该预处理可以包括:将数据的数据类型转换为知识图谱构建装置能够直接使用的数据类别。例如,终端将源数据存储在与数据中心中之后,云数据中心可以将该源数据的数据类型转换成json数据格式,或将源数据转换成逗号分隔值(comma separated values,csv)文件格式中的数据等,使得知识图谱构建装置在获取源数据后,无需对源数据进行数据转换,可以直接使用该经过预处理后的数据,以减小知识图谱构建装置构建知识图谱时的数据处理量。
[0085]
可选的,该源数据指示指令中还可以携带有源数据的数据类别、编码方式和源数据使用的分隔符等,以通知知识图谱构建装置源数据的数据类别、编码方式和源数据使用的分隔符等信息。需要说明的是,知识图谱构建装置也可以自动识别源数据的数据类别、编码方式和源数据使用的分隔符等信息,本申请实施例对其不做具体限定。
[0086]
进一步的,可以在知识图谱构建装置的设置界面中选择是否需要在源数据指示指令中携带上述信息。并且,在选择完成后,可以在该设置界面中执行指定操作,以触发发送携带有对应信息的源数据指示指令。示例的,图8是本申请实施例提供一种知识图谱构建装置的设置界面的示意图,如图8所示,用户可以在该设置界面中选择构建知识图谱所需的一路或多路数据,并设置源数据的名称,添加每路数据的存储地址,填写源数据的数据类别、编码方式和源数据使用的分隔符等信息,还可以选择是否设置源数据的标题行。在完成该设置界面的配置后,用户可以点击设置界面中的“下一步”按钮,以触发发送源数据指示指令。
[0087]
需要说明的是,本申请实施例不限定用于构建知识图谱的源数据的类型和来源。例如,源数据的类型可以为表格结构化数据或文本非结构化数据等。源数据可以为来源于百度百科的数据、来源于豆瓣电影的数据、来源于娱乐新闻文本数据或来源于企业内部的数据库或文档库等数据。并且,本申请实施例也不限定源数据的获取方式,例如,可以通过分布式爬虫方式获取来自网页的数据。
[0088]
步骤405、根据该源数据指示指令,获取多路数据。
[0089]
知识图谱构建装置接收到源数据指示指令后,可以按照源数据指示指令的指示获取源数据。例如,当源数据指示指令中携带有源数据的存储地址时,知识图谱构建装置可以在该存储地址所指示的存储位置中获取源数据。或者,当该源数据指示指令中携带有源数据时,知识图谱构建装置可以直接读取该源数据指示指令中携带的源数据。示例地,假设根据源数据指示指令获取了两路数据,该两路数据均为章某某1的相关介绍信息,其中,表1为知识图谱构建装置根据源数据指示指令从某网站中获取的一路数据,表2为知识图谱构建装置根据源数据指示指令从某数据库中获取的另一路数据。
[0090]
表1
[0091][0092]
表2
[0093]
姓名:章某某1明星关系:章某某2(哥哥)别名:1某某章国籍:中国性别:女职业:演员、制片人、歌手身高:164厘米代表作:英雄、我的父亲母亲、十面埋伏出生日期:1979年2月9日歌曲:十面埋伏
[0094]
步骤406、接收信息抽取指令。
[0095]
信息抽取指令用于指示对源数据进行信息抽取采用的信息抽取策略。信息抽取是指从源数据中提取出多元组数据。该多元组数据可以包括:用于指示实体的实体类型的信息、实体属性的信息和关联关系的信息等。信息抽取指令指示信息抽取策略的实现方式可以包括:信息抽取指令中携带有信息抽取算法的算法标识。知识图谱构建装置中预先存储有多个备选信息抽取算法的程序指令,知识图谱构建装置接收到信息抽取指令中携带的算法标识后,可以根据该算法标识在多个备选信息抽取算法中确定该算法标识所指示的信息抽取算法,并使用该信息抽取算法对源数据进行信息抽取。其中,当根据多路数据构建知识图谱时,对该多路数据进行信息抽取采取的信息抽取策略可以相同或不同,本申请实施例对其不做具体限定。
[0096]
在一种可实现方式中,该信息抽取指令可以为在知识图谱构建装置的设置界面中选择信息抽取算法后,通过执行指定操作后触发的。示例的,图9是本申请实施例提供一种知识图谱构建装置的设置界面的示意图,如图9所示,用户可以在该设置界面分别为不同源数据选择对应的信息抽取策略,并点击“下一步”按钮,以触发发送信息抽取指令。
[0097]
步骤407、分别采用信息抽取指令所指示的每路数据对应的信息抽取策略,对每路数据进行信息抽取,得到每路数据对应的多个多元组数据。
[0098]
对不同类型的数据进行信息抽取时采用的信息抽取策略可以不同。示例地,对于结构化数据和半结构化数据,可以采用固定的规则进行信息抽取,或者,可以采用人工智能(artificial intelligence,ai)模型进行信息抽取。其中,固定的规则的表示方式可以包
括:通过通用的算法模型、预置的插件脚本和配置化的函数插件等表示。可选的,该固定的规则可以为正则表达式、规则函数或基于语义的分析方法等。
[0099]
对于非结构化数据,可以采用根据数据自适应变化的规则进行信息抽取。例如,可以采用ai模型进行信息抽取。并且,在使用ai模型进行信息抽取前,可以采用标注样本对ai 模型进行训练,以保证该ai模型具有较优的信息抽取性能。进一步地,标注样本可以使用知识图谱本体模型中的本体元素进行标注。当使用该标注样本训练得到的ai模型抽取信息时,由该ai模型抽取到的多元组数据是采用知识图谱本体模型中定义的本体元素表示的信息,这样能够减少后续根据本体元素对抽取出的多元组数据进行标准化描述的过程,简化知识图谱构建的过程,提高知识图谱的构建效率。
[0100]
并且,知识图谱构建装置还可以配置有功能插件自定义功能。该功能插件自定义功能是指在部署知识图谱构建装置时,预留用于接入功能插件的输入接口和输出接口,并规定该输入接口和输出接口需要满足的条件,以便于用户根据应用需求自定义的功能插件,并在自定义的功能插件的输入满足该输入接口的限制条件、输出满足该输出接口的限制条件时,使用该自定义的功能插件对源数据进行信息抽取。通过配置功能插件自定义的功能,能够便于用户根据应用需求自行配置功能插件,能够进一步提高构建知识图谱的灵活性,使得本申请实施例提供的知识图谱构建方法能够应用于更多的知识图谱构建场景,保证了该知识图谱构建方法的应用范围。
[0101]
下面以采用ai模型进行信息抽取为例,分别针对三种信息抽取场景对信息抽取的实现过程进行说明。该三种信息抽取场景分别为:模式约束下的信息抽取场景、开放信息抽取场景和事件抽取场景。
[0102]
在模式约束下的信息抽取场景中,每次信息抽取过程抽取一个指定类型的多元组数据。在每次信息抽取过程中,依次使用谓语模型(predicate model)、主语模型(subject model) 和宾语模型(object model)对待抽取数据进行信息抽取。其中,待抽取数据可以为源数据中的部分数据,例如,可以为源数据中的一个句子。谓语模型用于判断待抽取数据中是否存在指定类型的多元组数据。该谓语模型的输入为待抽取数据,该谓语模型的输出为待抽取数据中是否存在该指定类型的多元组数据的结果。主语模型用于在待抽取数据中存在指定类型的多元组数据时,从待抽取数据中抽取该指定类型的多元组数据的主语。该主语模型的输入为该待抽取数据和该指定类型的多元组数据的类型信息。该主语模型的输出为该指定类型的多元组数据的主语。宾语模型用于在待抽取数据中存在指定类型的多元组数据时,从待抽取数据中抽取该指定类型的多元组数据的宾语。该宾语模型的输入为该待抽取数据、该指定类型的多元组数据的类型说明、及该指定类型的多元组数据的主语。该宾语模型的输出为该指定类型的多元组数据的宾语。
[0103]
该谓语模型、主语模型和宾语模型均具有输入层、特征提取层和输出层。输入层用于按照字或词对待抽取数据进行划分,使用向量表示划分后的每部分数据,并指示划分后的每部分数据在待抽取数据中的位置(即位置嵌入(position embedding)功能)。特征提取层用于提取从输入层输入的向量的特征。输出层用于根据特征提取层提取的特征判定划分后的每部分数据的类型。
[0104]
可选地,谓语模型、主语模型和宾语模型的输入层均可以使用bert模型(一种语言表征模型)实现。谓语模型、主语模型和宾语模型的特征提取层均可以使用膨胀门卷积神经
网络 (dilate gated convolutional neural network,dgcnn)模型(一种语言表征模型)实现。谓语模型、主语模型和宾语模型的输出层均可以使用sigmoid函数(一种s型函数)实现。
[0105]
例如,从句子“《森林报-秋》是2007年二十一世纪出版社出版的图书,作者是(苏联)维
·
比安基”中,其包含的三元组数据为(森林报-秋,作者,维
·
比安基)、(森林报-秋,出版时间, 2007年)、(森林报-秋,出版社,二十一世纪出版社)、(森林报-秋,类型,图书)、(维
·
比安基,国籍,苏联)、(维
·
比安基,类型,人物)等。在模式约束下的信息抽取场景中,指定类型的三元组数据为(图书,作者,人物)、(图书,出版社,出版社)、(人物,国家,国籍),那么上述句子中可以抽出的结果分别为(森林报-秋,作者,维
·
比安基)、(森林报-秋,出版社,二十一世纪出版社)、(维
·
比安基,国籍,苏联)。
[0106]
在开放信息抽取场景中,不需要限定抽取指定类型的多元组数据,可以直接在待抽取数据中抽取多元组数据,且抽取出的多元组数据中的主语、谓语和宾语为待抽取数据中直接出现了的词语。在每次信息抽取过程中,依次使用谓语模型、主语模型和宾语模型对待抽取数据进行信息抽取。其中,谓语模型用于从待抽取数据中抽取多元组数据的谓语。该谓语模型的输入为该待抽取数据,该谓语模型的输出为多元组数据的谓语。主语模型用于从待抽取数据中抽取多元组数据的主语。该主语模型的输入为该待抽取数据和多元组数据的谓语。该主语模型的输出为该多元组数据的主语。宾语模型用于从待抽取数据中抽取多元组数据的宾语。该宾语模型的输入为该待抽取数据、该多元组数据的主语和谓语。该宾语模型的输出为该多元组数据的宾语。其中,该谓语模型、主语模型和宾语模型的实现方式,可以相应参考前述模式约束下的信息抽取场景中谓语模型、主语模型和宾语模型的实现方式。
[0107]
例如,从句子“《森林报-秋》是2007年二十一世纪出版社出版的图书,作者是(苏联)维
·
比安基”中,其包含的三元组数据为(森林报-秋,作者,维
·
比安基)、(森林报-秋,出版时间, 2007年)、(森林报-秋,出版社,二十一世纪出版社)、(森林报-秋,类型,图书)、(维
·
比安基,国籍,苏联)、(维
·
比安基,类型,人物)等。在开放信息抽取场景中,由于抽取出的多元组数据中的主语、谓语和宾语需要是待抽取数据中直接出现了的词语,因此,述句子中可以抽出的结果为(森林报-秋,作者,维
·
比安基)。
[0108]
在事件抽取场景中,每次抽取出的数据为多个指定类型的多元组数据组成的事件。在执行信息抽取操作前,需要预先定义事件类型和事件属性。其信息抽取逻辑为:先识别事件的触发词和事件类型,然后抽取事件元素,并判断每个事件元素的角色。在每次信息抽取过程中,依次使用主语模型、谓语模型和宾语模型对待抽取数据进行信息抽取。其中,主语模型用于判断待抽取数据中是否存在预先定义的事件类型和触发词。该主语模型的输入为该待抽取数据。该主语模型的输出为待抽取数据中是否存在预先定义事件类型的结果。谓语模型用于判断待抽取数据中是否存在预先定义的事件属性。该谓语模型的输入为该待抽取数据和该预先定义的事件类型的类型信息,该谓语模型的输出为待抽取数据中存在的事件属性。宾语模型用于从待抽取数据中抽取事件属性的属性值。该宾语模型的输入为该待抽取数据、预先定义的事件类型的类型信息和待抽取数据中存在的事件属性的属性信息。该宾语模型的输出为每个事件属性的属性值。该主语模型、谓语模型和宾语模型的输出构成事件。其中,该谓语模型、主语模型和宾语模型的实现方式,可以相应参考前述模式
约束下的信息抽取场景中谓语模型、主语模型和宾语模型的实现方式。
[0109]
例如,待抽取数据为“香蕉公司将于西部时间9月12日上午10点(北京时间9月13日凌晨1 点)举行新品发布会,发布会地点是全新建造的史蒂夫
·
乔布斯剧院。根据目前的消息,这次发布会上香蕉公司将会发布ichne8、ichne7s、ichne7s plus、ichne ch 3以及全新ichne tv”。定义事件类型为“发布会”,事件属性包括“时间”、“地点”、“公司”、“产品”。
[0110]
在抽取过程中,主语模型用于判断待抽取数据是否出现事件类型“发布会”。其输入是待抽取数据,其输出是待抽取数据中是否有事件类型“发布会”的结果,且主语模型还可以标注待抽取数据中的触发词“新品发布会”,用以区分待抽取数据中可能出现的多个同类型的事件。
[0111]
谓语模型用于根据待抽取数据中出现的事件类型,判断待抽取数据中是否出现了事件属性“时间”、“地点”、“公司”、“产品”。其输入是待抽取数据和该事件类型的类型信息,其输出是待抽取数据中存在的事件属性。
[0112]
宾语模型用于从待抽取数据中抽取事件属性的属性值。其输入是待抽取数据、事件类型“发布会”和事件属性“时间”、“地点”、“公司”、“产品”。其输出是待抽取数据中每个事件属性的属性值,例如,对应事件属性“时间”,其输出为:西部时间9月12日上午10点,对应事件属性“地点”,其输出为:史蒂夫
·
乔布斯剧院,对应事件属性“公司”,其输出为:苹果公司,对应事件属性“产品”,其输出为:ichne8、ichne7s、ichne7s plus、ichne ch 3以及全新ichne tv。
[0113]
根据主语模型、谓语模型和宾语模型的输出,可以得到多个三元组数据:(发布会,公司,香蕉公司),(发布会,时间,西部时间9月12日上午10点),(发布会,地点,史蒂夫
·
乔布斯剧院),(发布会,产品,ichne8),(发布会,产品,ichne7s)等等。这些三元组数据构成事件抽取的结果:
[0114]
事件类型:发布会;
[0115]
公司:香蕉公司;
[0116]
时间:西部时间9月12日上午10点;
[0117]
地点:史蒂夫
·
乔布斯剧院;
[0118]
产品:ichne8,ichne7s,ichne7s plus,ichne ch 3,ichnetv。
[0119]
需要说明的是,在构建知识图谱的过程中,可以根据业务需求确定是否执行步骤406。并且,知识图谱构建装置中可以默认配置有信息抽取策略,在不执行步骤406时,在该步骤 407中,知识图谱构建装置可以使用默认配置的信息抽取策略对源数据进行信息抽取。但是,通过选择对源数据进行信息抽取的信息抽取策略,使得知识图谱构建装置能够针对不同领域中的源数据采用不同的信息抽取策略,能够提高从源数据中抽取到的信息的准确性,保证了根据不同领域中源数据构建的知识图谱的准确性,保证了知识图谱构建方法的适用范围,提高了构建知识图谱的灵活性。
[0120]
步骤408、接收映射策略指令。
[0121]
映射策略指令用于指示根据本体元素对多个多元组数据进行关联映射(也称知识映射, knowledge mapping)的映射策略。知识映射是指建立从抽取元素与本体元素之间的映射关系,并根据该映射关系采用本体元素对对应的抽取元素进行标准化描述。例如,当知识图谱本体模型定义的多元组数据中主语的形式化表达为“名称”时,若抽取的多元组数据
中主语为“名字”,则根据映射策略可以建立“名称”与“名字”的映射关系,并根据该映射关系将“名字”标准化描述为“名称”。其中,当根据多路数据构建知识图谱时,多路数据对应的映射策略可以相同或不同,本申请实施例对其不做具体限定。
[0122]
在映射策略的一种实现方式中,知识图谱构建装置可以获取每个抽取元素与本体元素的匹配度。当某一抽取元素与一个本体元素的匹配度大于匹配度阈值时,知识图谱构建装置可以建立该抽取元素与该本体元素的映射关系,并指示使用该本体元素对该抽取元素进行标准化描述。例如,当抽取元素“名字”与本体元素“名称”的匹配度大于匹配度阈值时,可以建立“名称”与“名字”的映射关系,并根据该映射关系将“名字”标准化描述为“名称”。
[0123]
此时,映射策略指令用于指示根据匹配度建立本体元素和抽取元素的映射关系,及获取匹配度所使用的匹配度算法。例如,映射策略指令可以指示根据匹配度建立本体元素和抽取元素的映射关系,且获取匹配度使用的匹配度算法可以为编辑距离相似度算法。
[0124]
在映射策略的另一种可实现方式中,用户可以通过终端在知识图谱构建装置的设置界面中配置映射策略。其实现过程包括:用户可以通过终端指示抽取元素与本体元素之间的映射关系,并指示使用本体元素对与其具有映射关系的抽取元素进行标准化描述。用户完成配置后,可以通过在设置界面中执行指定操作,触发发送映射策略指令。并且,由于在步骤403 中确定知识图谱本体模型后,该知识图谱本体模型所定义的本体元素就确定了,因此,配置映射策略的过程实质为根据已确定的本体元素,分别指示与不同本体元素具有映射关系的抽取元素的过程。
[0125]
示例的,图10是本申请实施例提供一种知识图谱构建装置的设置界面的示意图,如图 10所示,用户可以在该设置界面中,分别添加与本体元素具有映射关系的抽取元素。例如,对于已知的本体元素中的实体类型(即本体实体类型)“名称”,可以添加与其存在映射关系的抽取元素中的实体类型(即抽取实体类型)为“名字”,以对实体类型进行映射。对于本体元素关联关系(即本体关联关系),可以添加与其存在映射关系的抽取元素中的关联关系(即抽取关联关系),以对关联关系进行映射。对于已知的本体元素中的实体属性(即本体实体属性),可以添加与其存在映射关系的抽取元素中的实体属性(即抽取实体属性),以对实体属性进行知识映射。并且,还可以根据知识图谱本体模型的类别(即本体类别)对知识图谱的类别进行类型映射。在完成配置后,可以点击“下一步”按钮,以触发发送映射策略指令。
[0126]
步骤409、根据映射策略指令指示的映射策略和多元组数据的标准化描述,分别对根据每路数据抽取得到的多个多元组数据进行关联映射,得到采用多元组数据的标准化描述进行标准化描述的多个多元组数据。
[0127]
知识图谱构建装置在获取映射策略指令后,可以根据该映射策略指令指示的映射策略,根据本体元素对多个多元组数据进行知识映射,得到采用本体元素进行标准化描述的多个多元组数据。通过知识映射可以将抽取元素按照知识图谱本体模型定义的本体元素进行标准化描述,实现了抽取元素的统一表示,提高了知识图谱的可读性。
[0128]
需要说明的是,在构建知识图谱的过程中,可以根据业务需求确定是否执行步骤408。并且,知识图谱构建装置中可以默认配置有映射策略,在不执行步骤408时,在步骤409中,知识图谱构建装置可以使用默认配置的映射策略对多元组数据进行关联映射。但是,通
过选择映射策略,并使用选择的映射策略对多元组数据进行关联映射,使得知识图谱构建装置能够针对不同类型的数据使用不同的映射策略,能够提高对多元组数据进行关联映射的准确性,提高了知识图谱构建的准确性。
[0129]
步骤410、接收匹配策略指令。
[0130]
当根据多个源数据构建知识图谱时,用于指示同一实体的信息的表示方式可能不同,若直接根据提取出的多元组数据构建知识图谱,可能会将采用不同表示方式的同一实体当做不同的实体,导致构建的知识图谱无法准确反映源数据体现的内容。因此,在根据多元组数据构建知识图谱之前,还可以判断不同多元组数据中是否包括有用于指示同一实体的元素,并对包括有用于指示同一实体的元素的不同多元组数据进行合并处理(也称知识融合, knowledge conflation),以便于根据经过合并处理后的多元组数据构建知识图谱,进而提高构建的知识图谱的准确性。例如,根据表1所示的源数据进行信息提取得到的实体类型的信息为“名称:章某某1”,根据表2所示的源数据进行信息提取得到的实体类型的信息为“名称: 1某某章”,两者虽然表示方式不同,但两者均用于指示同一实体,此时,可以对两者进行知识融合。
[0131]
该匹配策略指令用于指示判断不同多元组数据中是否包括有用于指示同一实体的元素的匹配算法和匹配度阈值。知识图谱构建装置可以根据该匹配度算法获取不同多元组数据中元素的匹配度,当不同多元组数据中元素的匹配度不小于匹配度阈值时,确定该不同多元组数据中元素用于指示同一实体,此时,可以将该用于指示同一实体的不同多元组数据中的元素进行合并。
[0132]
在一种可实现方式中,知识图谱构建装置的部署环境中可以预先存储有多种匹配算法的程序,此时,可以在知识图谱构建装置的设置界面中选择需要使用的匹配算法,并在选择完成后,通过在设置界面中执行指定操作,触发发送匹配策略指令。示例的,图11是本申请实施例提供一种知识图谱构建装置的设置界面的示意图,如图11所示,用户可以在该设置界面中针对不同的元素,选择对其进行知识融合时需要使用的匹配算法和匹配度阈值。并且,还可以分别针对实体的不同实体属性分别设置匹配算法和匹配度阈值,且对具有多个实体属性的实体,在判断该实体与其他实体是否为相同的实体时,其判断结果可以为该实体的不同实体属性对应的匹配算法的算法结果的“集成”。例如,可以为该实体的不同实体属性对应的匹配算法的算法结果的交集。类似的,每个属性也可以配置有多个匹配算法。在设置完成后,可以点击“下一步”按钮,以触发匹配策略指令。
[0133]
步骤411、根据匹配策略指令指示的多元组数据匹配策略,在标准化描述后的多个多元组数据中,确定包括有指示同一实体的元素的不同多元组数据,对包括有指示同一实体的元素的不同多元组数据进行合并处理,得到经过合并处理后的多个多元组数据。
[0134]
对包括有指示同一实体的元素的不同多元组数据进行合并处理,是指采用相同表示方式表示采用不同表示方式的同一实体,使得用于指示同一实体的元素的表示方式相同。
[0135]
示例地,根据表1所示的源数据进行信息提取得到的三元组数据分别为(章某某1,身高,164厘米)、(章某某1,性别,女)、(章某某1,国籍,中国)、(章某某1,生日, 1979年2月9日)、(章某某1,兄妹,章某某2)、(章某某1,主演,我的父亲母亲)、 (章某某1,主演,卧虎藏龙)。根据表2所示的源数据进行信息提取得到的三元组数据分别为(1某某章,身高,164厘
米)、(1某某章,性别,女)、(1某某章,兄妹,章某某 2)、(1某某章,主演,我的父亲母亲)、(1某某章,主演,英雄)、(章某某1,主演,十面埋伏)、(1某某章,演唱者,十面埋伏)。根据匹配策略指令指示的多元组数据匹配策略进行知识融合后,得到以下三元组数据:(章某某1,身高,164厘米)、(章某某1,性别,女)、(章某某1,国籍,中国)、(章某某1,生日,1979年2月9日)、(章某某1,兄妹,章某某2)、(章某某1,主演,我的父亲母亲)、(章某某1,主演,十面埋伏)、(章某某1,主演,英雄)、(章某某1,演唱者,十面埋伏)。
[0136]
需要说明的是,在构建知识图谱的过程中,可以根据业务需求确定是否执行步骤410。并且,知识图谱构建装置中可以默认配置有匹配算法和对应的匹配度阈值。在不执行步骤410 时,在该步骤411中,知识图谱构建装置可以使用默认配置的匹配算法和对应的匹配度阈值,判断不同多元组数据中是否包括有用于指示同一实体的元素。但是,通过选择匹配算法,并使用选择的匹配算法判断不同多元组数据中是否包括有指示同一实体的元素,使得知识图谱构建装置能够对基于不同领域中的数据获得的元素采用不同的匹配算法,能够提高知识映射的灵活度和获取匹配度的准确性,提高了知识图谱构建的准确性和全面性。
[0137]
步骤412、根据经过合并处理后的多个多元组数据,构建知识图谱。
[0138]
其中,知识图谱记录源数据所包括的实体及不同实体之间的关系。前述步骤401至步骤 411均为构建知识图谱的准备工作,在完成准备工作后,即可根据经过合并处理后的多个多元组数据构建知识图谱。该根据多元组数据构建知识图谱的过程可以理解为:按照经过合并处理后的多个多元组数据中各个元素之间的关系,将多个多元组数据连接成语义网络的过程。并且,语义网络中的每个节点对应一个多元组数据中的实体类型或实体属性,节点之间的关系对应多元组数据中的关联关系的信息,且节点之间箭头的起点对应多元组数据中用作主语的元素,箭头的终点对应多元组数据中用作宾语的元素。
[0139]
示例地,图12为根据步骤411中经过合并处理后的多元组数据构建的知识图谱的示意图。如图12所示,该知识图谱记录了用于指示实体的多元组数据中的实体类型、实体属性及关联关系,该知识图谱通过图的形式表示出了表1和表2的源数据,提高了源数据的可视化程度,提高了根据该源数据进行分析的便捷程度。
[0140]
步骤413、在确定源数据发生更新后,根据信息抽取指令所指示的策略,对更新后的源数据中的增量数据进行信息抽取,得到增量数据对应的多个多元组数据,并根据增量数据对应的多个多元组数据更新知识图谱。
[0141]
当已构建的知识图谱的源数据发生更新时,可以获取更新后的源数据相对于该源数据的增量数据,并根据该增量数据更新该已构建的指示图谱,得到更新后的源数据对应的知识图谱。例如,可以先对增量数据进行信息抽取,得到增量数据对应的多个多元组数据,然后对增量数据对应的多个多元组数据进行知识映射,再对经过关联映射后的增量数据对应的多个多元组数据进行知识融合,然后根据经过知识融合后的多个多元组数据更新指示图谱。通过对知识图谱进行增量更新,能够减小根据更新后的源数据构建知识图谱过程中的额计算量,可以提高构建知识图谱的构建效率。
[0142]
综上所述,本申请实施例提供的知识图谱构建方法,通过接收信息抽取指令,确定对构建知识图谱的源数据进行信息抽取采用的信息抽取策略,采用该信息抽取策略对源数据进行信息抽取得到多个多元组数据,然后根据该多个多元组数据构建知识图谱,相较于
相关技术,能够根据业务需求配置信息抽取策略,并针对不用领域中的源数据采用不同的信息抽取策略,使得可以根据不同领域中的源数据构建知识图谱,保证了知识图谱构建方法的适用范围,提高了构建知识图谱的灵活性。
[0143]
本申请实施例提供的知识图谱构建方法的步骤先后顺序可以进行适当调整,步骤也可以根据情况进行相应增减,例如,可以根据应用需求选择是否执行上述步骤402、步骤406、步骤408和步骤410。任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,可轻易想到变化的方法,都应涵盖在本申请的保护范围之内,因此不再赘述。
[0144]
本申请实施例还提供了一种知识图谱构建装置。如图13所示,该知识图谱构建装置80 可以包括:
[0145]
接收模块801,用于接收信息抽取指令,信息抽取指令用于指示对构建知识图谱的源数据进行信息抽取采用的信息抽取策略。
[0146]
抽取模块802,用于采用信息抽取指令所指示的信息抽取策略,对源数据进行信息抽取,得到多个多元组数据,每个多元组数据包括:用于指示实体的实体类型的信息、实体属性的信息和关联关系的信息。
[0147]
构建模块803,用于根据多个多元组数据,构建知识图谱,知识图谱记录源数据所包括的实体及不同实体之间的关系。
[0148]
可选地,如图14所示,知识图谱构建装置80还包括:
[0149]
获取模块804,用于获取用于构建知识图谱时需要使用的知识图谱本体模型,知识图谱本体模型定义知识图谱中多元组数据的标准化描述。
[0150]
接收模块801,还用于接收映射策略指令,映射策略指令用于指示根据多元组数据的标准化描述对多个多元组数据进行关联映射的映射策略。
[0151]
映射模块805,用于根据多元组数据的标准化描述和映射策略指令所指示的映射策略,对多个多元组数据进行关联映射,得到采用多元组数据的标准化描述进行标准化描述的多个多元组数据。
[0152]
相应的,构建模块803,具体用于:根据标准化描述后的多个多元组数据,构建知识图谱。
[0153]
可选地,如图14所示,知识图谱构建装置80还包括:
[0154]
确定模块806,用于根据指定的多元组数据匹配策略,在多个多元组数据中,确定包括有指示同一实体的信息的不同多元组数据。
[0155]
合并模块807,用于对包括有指示同一实体的信息的不同多元组数据进行合并处理。
[0156]
相应的,构建模块803,具体用于:根据经过合并处理后的多个多元组数据,构建知识图谱。
[0157]
可选地,接收模块801,还用于接收匹配策略指令,匹配策略指令用于指示判断不同多元组数据中是否包括有指示同一实体的信息的匹配算法和匹配度阈值。
[0158]
相应的,确定模块806,具体用于:当根据匹配策略指令所指示的匹配算法,确定两个多元组数据中指示实体的信息的匹配度不小于匹配度阈值时,确定两个多元组数据包括有指示同一实体的信息。
[0159]
可选地,源数据包括:来源不同的多路数据,抽取模块802,具体用于:分别采用信
息抽取指令所指示的对每路数据进行信息抽取采用的信息抽取策略,对每路数据进行信息抽取,得到分别与多路数据对应的多个多元组数据。
[0160]
相应的,构建模块803,具体用于:根据与多路数据对应的多个多元组数据,构建知识图谱。
[0161]
可选地,抽取模块802,还用于在确定源数据发生更新后,根据信息抽取指令所指示的策略,对更新后的源数据中的增量数据进行信息抽取,得到增量数据对应的多个多元组数据.
[0162]
相应的,构建模块803,还用于根据增量数据对应的多个多元组数据更新知识图谱。
[0163]
可选地,抽取模块802,具体用于:采用信息抽取指令所指示的ai模型,对源数据进行信息抽取。
[0164]
其中,ai模型为已经过训练的模型,且ai模型的训练样本使用知识图谱本体模型中多元组数据的标准化描述进行标注,知识图谱本体模型定义知识图谱中多元组数据的标准化描述。
[0165]
综上所述,本申请实施例提供的知识图谱构建装置,通过接收模块接收信息抽取指令,确定对构建知识图谱的源数据进行信息抽取采用的信息抽取策略,抽取模块采用该信息抽取策略对源数据进行信息抽取得到多个多元组数据,然后构建模块根据该多个多元组数据构建知识图谱,相较于相关技术,能够根据业务需求配置信息抽取策略,并针对不用领域中的源数据采用不同的信息抽取策略,使得可以根据不同领域中的源数据构建知识图谱,保证了知识图谱构建方法的适用范围,提高了构建知识图谱的灵活性。
[0166]
所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的装置和模块的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
[0167]
本申请实施例还提供了一种计算设备,该计算设备包括处理器和存储器;该存储器中存储有计算机程序;该处理器执行计算机程序时,该计算设备实现本申请实施例提供的知识图谱构建方法。该计算设备可以为服务器或终端,该计算设备的结构请相应参考图3中计算设备的结构,此处不再赘述。
[0168]
可选地,该计算设备可以工作在ai平台和大数据平台上,以利用该ai平台构建、训练和部署本申请实施例提供的知识图谱构建方法中使用到的ai模型,并从该大数据平台中获取源数据,及利用该大数据平台进行数据处理。
[0169]
本申请实施例还提供了一种存储介质,该存储介质为非易失性计算机可读存储介质,当存储介质中的指令被处理器执行时,实现本申请实施例提供的知识图谱构建方法。
[0170]
本申请实施例还提供了一种包含指令的计算机程序产品,当计算机程序产品在计算机上运行时,使得计算机执行本申请实施例提供的知识图谱构建方法。
[0171]
本领域普通技术人员可以理解实现上述实施例的全部或部分步骤可以通过硬件来完成,也可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,上述提到的存储介质可以是只读存储器,磁盘或光盘等。
[0172]
在本申请实施例中,术语“第一”、“第二”和“第三”仅用于描述目的,而不能理解为指示或暗示相对重要性。术语“至少一个”是指一个或多个,术语“多个”指两个或两个以上,除非另有明确的限定。
[0173]
本申请中术语“和/或”,仅仅是一种描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示:单独存在a,同时存在a和b,单独存在b这三种情况。另外,本文中字符“/”,一般表示前后关联对象是一种“或”的关系。
[0174]
以上所述仅为本申请的可选实施例,并不用以限制本申请,凡在本申请的构思和原则之内,所作的任何修改、等同替换、改进等,均应包含在本申请的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1