区块链链上数据结构化存储方法及系统与流程
本申请涉及区块链
技术领域:
,具体涉及一种区块链链上数据结构化存储方法及系统。
背景技术:
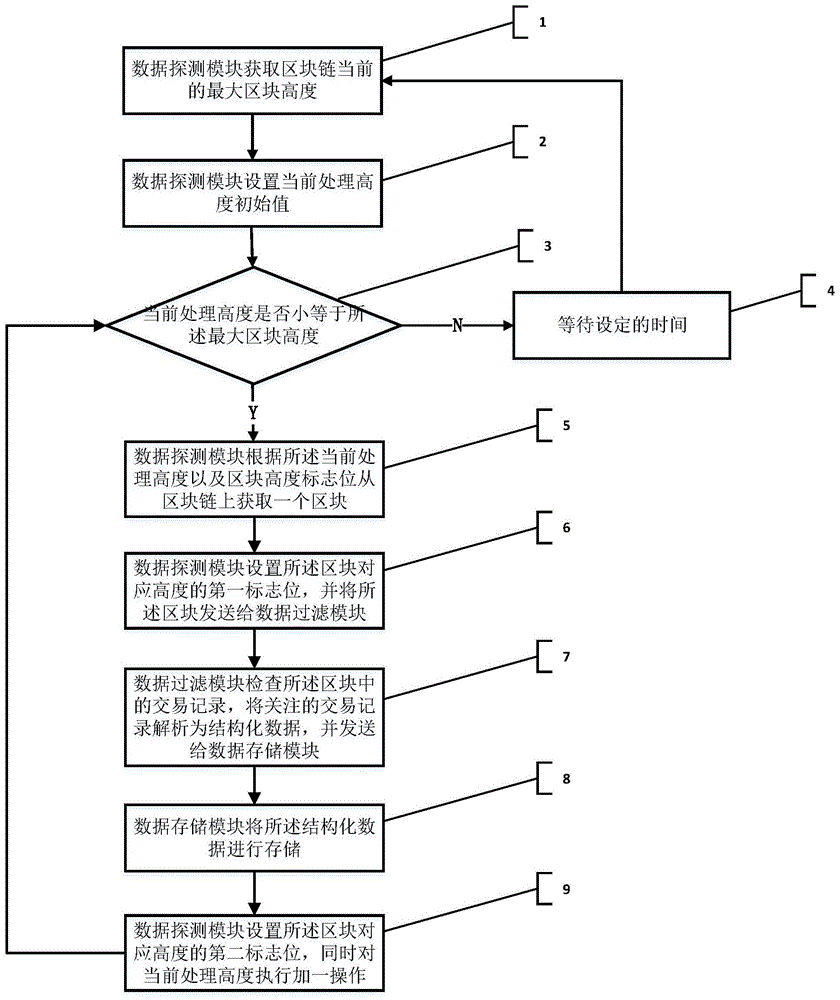
:区块链是分布式数据存储、点对点传输、共识机制、加密算法等计算机技术的新型应用模式。区块链(blockchain),是比特币的一个重要概念,它本质上是一个去中心化的数据库,同时作为比特币的底层技术,是一串使用密码学方法相关联产生的数据块,每一个数据块中包含了一批次比特币网络交易的信息,用于验证其信息的有效性和生成下一个区块。由于区块链网络所承载的数据随着时间的增长不仅数量在不断增大,而且数据的种类也花样繁多。这种情况下,要对链上数据进行存储和检索,主要存在以下几个问题:1.链上数据检索难。由于比特币网络对于数据的存储以交易核心,并非以所关注的业务为核心,加之数据量的增长,导致了链上数据检索的困难。2.将链上数据进行结构化存储难。若一个大区块存储2g数据,平均每十分钟出一个区块,则一天有288g数据,而且随着越来越多的企业将各自的数据上链,链上数据的种类越来越多,各种数据的结构化方式有所不同,这都导致了结构化数据存储十分不方便。3.如何处理区块链数据回退情况。在区块链的区块生成过程中,不同节点有可能在短时间内同时生成下一个区块并广播到区块链上,其它节点会在最先收到的区块基础上继续工作,这样就使得区块链在同一个高度上出现了不同的下一区块,区块链发生短暂的分叉。随着后续区块的不断产生,区块链会按照最长链原则,将最长的分叉链作为主链,所有节点在此基础上继续工作,而被放弃的分叉链接都成为了侧链,侧链上的区块称为孤块。当出现孤块的时候,链上数据会发生变化,这导致了已经结构化存储的数据也要进行相应的回退和更新,但目前还没有一个很好的处理机制。4.如何保证数据结构化存储过程中的数据的一致性。数据以块为单位存储在链上,在对链上数据进行结构化存储的过程中,进程可能会因为各种原因(如断电)中断,需要有一套机制能够保证获取的数据即不重复也不缺失。技术实现要素:本发明的目的之一在于克服以上缺点,提供一种区块链链上数据结构化存储方法,既能实时完整地获取区块链上的数据,同时支持多种不同格式数据的结构化转换,提供可灵活扩展数据存储方式和高效的数据查询方式。为了解决上述技术问题,本发明提供了一种区块链链上数据结构化存储方法,包括以下步骤:步骤1、数据探测模块获取区块链当前的最大区块高度;步骤2、数据探测模块设置当前处理高度初始值;步骤3、数据探测模块判断若所述当前处理高度小等于所述最大区块高度,则跳转至步骤5继续执行,否则执行步骤4;步骤4、数据探测模块等待设定的时间后跳转至步骤1继续执行;步骤5、数据探测模块根据所述当前处理高度以及区块高度标志位从区块链上获取一个区块;所述区块高度标志位包含区块链上每一区块对应高度的第一标志位和第二标志位;步骤6、数据探测模块设置所述区块的对应高度的第一标志位,并将所述区块发送给数据过滤模块;步骤7、数据过滤模块检查所述区块中的交易记录,将需要的交易记录解析为结构化数据,并发送给数据存储模块;步骤8、数据存储模块将所述结构化数据进行存储;步骤9、数据探测模块设置所述区块的对应高度的第二标志位,同时对所述当前处理高度执行加一操作,并跳转至步骤3继续执行;重复执行上述步骤,实现区块链上所有区块数据的结构化存储。本申请的方法数据探测模块通过采用对一个区块高度设置双标志位的方法来控制处理的完整性,数据过滤模块负责对自己需要的链上数据进行针对性的结构化,数据存储模块进行统一的存储管理控制,通过三个模块的分工合作实现区块链数据的结构化存储,部署灵活方便。进一步地,所述“数据探测模块根据所述当前处理高度以及区块高度标志位从区块链上获取一个区块”,具体为:步骤51、数据探测模块判断若所述当前处理高度的第一标志位已经设置,则执行步骤52,否则跳转至步骤55继续执行;步骤52、数据探测模块判断若所述当前处理高度的第二标志位已经设置,则执行步骤53,否则跳转至步骤54继续执行;步骤53、数据探测模块对所述当前处理高度执行加一操作,并跳转至步骤3继续执行;步骤54、数据探测模块调用数据存储模块删除所述当前处理高度对应的交易记录;步骤55、数据探测模块从区块链上获取所述当前处理高度对应的区块。通过对比区块高度的两个标志位,可以知道某一个块的处理情况是已经处理完成或尚未完成,若因某些原因导致的上一次处理未完成,则清除该区块高度对应的交易数据,重新处理,以保证数据的正确性和完整性。进一步地,所述数据过滤模块为多个,每个数据过滤模块各自接收所述数据探测模块发送的区块,将需要的交易记录解析为结构化数据,并发送给所述数据存储模块。针对一种数据类型可以设置一个数据过滤模块与其相对,这样无论多少种类型的结构化数据,都可以通过对应的数据过滤模块来达到支持,扩展性强,应用场景更加灵活。进一步地,所述数据存储模块包括多个数据库实例,所述“数据存储模块将所述结构化数据进行存储”,具体为:数据存储模块将所述结构化数据随机写入一个数据库实例中。数据存储模块通过设置多个数据库实例,采用随机插入的方式来解决数据量大的问题。随机插入支持无限扩容,一旦当前的数据库实例无法支持数据的容量,可以随意增加数据库实例。进一步地,所述的区块链链上数据结构化存储方法,还包括以下步骤:所述数据探测模块从区块链的内存池中获取未确认交易记录发送给所述数据过滤模块;所述数据过滤模块将需要的未确认交易记录解析为结构化数据,并发送给数据存储模块。通过获取内存池中尚未写入区块链中的交易数据,使得支持零确认交易,交易同步和查询更加实时。进一步地,所述的区块链链上数据结构化存储方法,还包括以下步骤:所述数据探测模块定时检查已处理区块的哈希值与当前区块链上对应高度区块的哈希值是否一致,若不一致,则清除所述区块高度标志位中对应高度的第二个标志位。通过控制区块高度的第二个标志位,实现在出现孤块的时候,自动地回退和更新交易数据,无需人工干预。进一步地,所述的区块链链上数据结构化存储方法,还包括以下步骤:所述数据存储模块在所有数据库实例中进行结构化数据的并发查询,并将查询结果进行汇总。数据存储模块通过设置多个数据库实例,通过并发统一查询,来实现在数据量大的情况下快速的检索,提高查询的性能。相应地,本申请还提供了一种区块链链上数据结构化存储系统,包括数据探测模块、数据过滤模块以及数据存储模块,其中,数据探测模块,用于获取区块链当前的最大区块高度;设置当前处理高度初始值,并根据所述当前处理高度以及区块高度标志位从区块链上获取一个区块;所述区块高度标志位包含区块链上每一区块对应高度的第一标志位和第二标志位;用于设置所述区块对应高度的第一标志位,并将所述区块发送给数据过滤模块;用于区块处理结束后设置所述区块对应高度的第二标志位,同时对所述当前处理高度执行加一操作;数据过滤模块,用于检查所述区块中的交易记录,将需要的交易记录解析为结构化数据,并发送给数据存储模块;数据存储模块,用于将数据过滤模块发送的所述结构化数据进行存储。进一步地,所述数据探测模块还用于从区块链的内存池中获取未确认交易记录发送给所述数据过滤模块;所述数据过滤模块还用于将需要的未确认交易记录解析为结构化数据,并发送给数据存储模块。进一步地,所述数据探测模块还用于定时检查已处理区块的哈希值与当前区块链上对应高度区块的哈希值是否一致,若不一致,则清除所述区块高度标志位中对应高度的第二个标志位。区别于现有技术,本发明技术方案的有益效果有:1.本申请的方法数据探测模块通过采用对一个区块高度设置双标志位的方法来控制处理的完整性,数据过滤模块负责对自己需要的链上数据进行针对性的结构化,数据存储模块进行统一的存储管理控制,通过三个模块的分工合作实现区块链数据的结构化存储,部署灵活方便。2.通过对比区块高度的两个标志位,可以知道某一个块的处理情况是已经处理完成或尚未完成,若因某些原因导致的上一次处理未完成,则清除该区块高度对应的交易数据,重新处理,以保证数据的正确性和完整性。同时通过控制区块高度的第二个标志位,实现在出现孤块的时候,自动地回退和更新交易数据,无需人工干预。3.针对一种数据类型可以设置一个数据过滤模块与其相对,这样无论多少种类型的结构化数据,都可以通过对应的数据过滤模块来达到支持,扩展性强,应用场景更加灵活。4.数据存储模块通过设置多个数据库实例,采用随机插入的方式来解决数据量大的问题。随机插入支持无限扩容,一旦当前的数据库实例无法支持数据的容量,可以随意增加数据库实例。同时通过并发统一查询,来实现在数据量大的情况下快速的检索,提高查询的性能。5.通过获取内存池中尚未写入区块链中的交易数据,使得支持零确认交易,交易同步和查询更加实时。附图说明图1是本发明一种区块链链上数据结构化存储方法的步骤流程图。图2是本发明数据探测模块根据当前处理高度以及区块高度标志位从区块链上获取一个区块的步骤流程图。图3是本发明一种区块链链上数据结构化存储系统的架构图。具体实施方式下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。整个区块链上的数据是以块的形式存储在各个全节点上,本申请的区块链链上数据结构化存储方法就是对区块链上所有区块的数据进行获取,过滤后进行结构化转换再存储持久化。如图1,是本发明一种区块链链上数据结构化存储方法的步骤流程图,包括以下步骤:步骤1、数据探测模块获取区块链当前的最大区块高度;本发明中,数据探测模块负责从区块链的全节点上获取需要处理的区块转发给数据过滤模块。这里,区块高度是指区块链上每个区块的顺序编号,会随着区块的增加而不断增大。由于区块链上的区块在不断地增加,因此数据探测模块每次都要获取区块链当前的最大区块高度,用于判断是否有新的区块数据需要处理。步骤2、数据探测模块设置当前处理高度初始值;如
背景技术:
中所描述的,由于区块链上会发生分叉导致孤块生成,同时还可能导致链上的区块发生变化,由新的区块代替旧的区块。因此数据探测模块每次开始处理的时候,都要设置适当的处理高度初始值,以保证所有的区块会被正确的处理。在具体的实施例中,可以将当前处理高度设置为区块链的最小区块高度,通常为0,从小到大逐一遍历每个区块高度来判断区块是否需要重新处理。或者,如果已经知道在一定区块高度之后才有所关心的数据,可以通过设置参数的方式记录该高度值,数据探测模块读取该参数值作为初始处理高度。步骤3、数据探测模块判断若所述当前处理高度小等于所述最大区块高度,则说明区块链上有新增的区块尚未处理,则跳转至步骤5继续执行,否则,若所述当前处理高度大于所述最大区块高度,则说明区块链上的所有区块都已经处理完毕,则执行步骤4;步骤4、数据探测模块等待设定的时间后跳转至步骤1继续执行下一轮的操作;步骤5、数据探测模块根据所述当前处理高度以及区块高度标志位从区块链上获取一个区块;其中,区块高度标志位包含了区块链上每一区块对应高度的第一标志位和第二标志位,第一标志位表示该高度的区块已经开始处理,第二标志位表示该高度的区块处理完成。在具体的实施例中,区块高度标志位可以是数据库一张配置表,包含了区块高度、第一标志位以及第二标志位三个字段,若一个区块高度在该配置表找不到对应记录或者第一标志位和第二标志位被设置为0,则说明该区块未被处理过,否则,若第一标志位和第二标志位被设置为1,则说明该区块已经被处理完成。如图2,是本发明数据探测模块根据当前处理高度以及区块高度标志位从区块链上获取一个区块的步骤流程图,包括以下步骤:步骤51、数据探测模块判断若所述当前处理高度的第一标志位已经设置,则说明当前高度的区块曾经被处理过,则执行步骤52继续判断第二标志位,否则跳转至步骤55继续执行;步骤52、数据探测模块判断若所述当前处理高度的第二标志位已经设置,则说明该高度的区块已经处理完成,执行步骤53,否则,说明该高度的区块需要重新处理,则跳转至步骤54继续执行;步骤53、数据探测模块对所述当前处理高度执行加一操作,并跳转至步骤3继续检查下一个区块是否需要处理;步骤54、由于需要重新处理当前高度的区块数据,因此数据探测模块调用数据存储模块删除当前处理高度对应的所有交易记录;步骤55、数据探测模块从区块链上获取所述当前处理高度对应的区块。本申请的方法数据探测模块通过采用对一个区块高度设置双标志位的方法来控制处理的完整性,通过对比区块高度的两个标志位,可以知道某一个高度的区块是否处理完成,若因某些原因导致的上一次处理未完成,则清除该区块高度对应的交易数据,重新处理,以保证数据的正确性和完整性。步骤6、数据探测模块设置所述区块的对应高度的第一标志位,表示该高度的区块已经开始处理,并将所述区块发送给数据过滤模块;步骤7、数据过滤模块检查所述区块中的交易记录,将需要的交易记录解析为结构化数据,并发送给数据存储模块;本申请中,数据过滤模块是区块链上交易数据定制化处理的关键,它从数据探测模块处获取整个区块的数据,并对交易数据进行过滤和结构化处理。数据过滤模块本质上是一个交易的观察者,它逐一检查区块包含的每一笔交易,判断一笔交易是否是自己关心的交易记录,若发现是需要关注的交易,则对原始交易记录数据进行解析转换为结构化数据,这里结构化数据也称作行数据,是由二维表结构来逻辑表达和实现的数据,严格地遵循数据格式与长度规范,主要通过关系型数据库进行存储和管理。在一优选的实施例中,数据过滤模块可以为多个,通过在区块高度标志位中增加数据过滤模块编号标识,数据探测模块可以识别出每个数据过滤模块分别已经处理到哪个高度的区块,并发送下一个需要处理的区块。每个数据过滤模块将接收到的区块中需要的交易记录解析为结构化数据,并发送给所述数据存储模块,每个数据过滤模块之间互不干扰并行运行。通过为每一种数据类型设置一个数据过滤模块与其相对,无论多少种类型的结构化数据,都可以通过对应的数据过滤模块来达到支持,扩展性强,应用场景更加灵活。步骤8、数据存储模块将所述结构化数据进行存储;本申请中,数据存储模块负责所有结构化数据的统一存储管理,对结构化后的数据进行持久化。具体的实施例中,可以使用mysql或者mongodb等数据库来存储交易数据。随着大区块时代的到来,区块链网络的数据会越来越大,数据存储模块作为持久化层需要有能够支持增容。因此,在一优选的实施例中,数据存储模块包括多个数据库实例,数据存储模块将所述结构化数据进行存储的时候,会随机挑选一个数据库实例,将结构化数据写入其中。在具体的策略上,可以选择轮流插入,第一条数据插入到第一个库,第二条第二个库,所有库轮一遍之后,再重新开始;也可以对交易取hash,并以hash值对数据库的数量求余,是几则存在第几个库;还可以在存储不足,扩展了新数据库实例的时候,一段时间内所有数据只往新加入的数据库实例存储,直到各个数据库实例中数据量差不多的时候,再采用其他均衡的策略。另外,若用户需要对关注的交易进行查询,则数据存储模块可以在所有数据库实例中进行结构化数据的并发查询,并将查询结果进行汇总返回给用户。通过设置多个数据库实例,采用随机插入的方式可以支持无限扩容,一旦当前的数据库实例无法支持数据的容量,可以随意增加数据库实例。同时通过并发统一查询,来实现在数据量大的情况下快速的检索,提高查询的性能。步骤9、当数据过滤模块将一个区块中关注的交易都结构化存储完成后,会通知数据探测模块,由数据探测模块设置所述区块的对应高度的第二标志位,表示该高度的区块已经处理完成,同时对所述当前处理高度执行加一操作,并跳转至步骤3继续判断下一区块是否需要处理;通过不断重复执行上述步骤,数据探测模块、数据过滤模块以及数据存储模块分工协作,实现随着区块链区块的增加不断地对所有区块数据进行结构化存储。在一优选的实施例中,本申请的区块链链上数据结构化存储方法,还包括以下步骤:所述数据探测模块从区块链的内存池中获取未确认交易记录发送给所述数据过滤模块;所述数据过滤模块将需要的未确认交易记录解析为结构化数据,并发送给数据存储模块。由于区块链在新的区块生成之前会将未确认的交易记录存放在全节点的内存池中,因此,数据探测模块可以内存池中的交易记录进行实时监控,一旦发现新的交易记录生成,就直接将该交易记录发送给数据过滤模块,由数据过滤模块判断是否是自己关注的交易,若是,则进行结构化处理并发送给数据存储模块进行持久化。通过获取内存池中尚未写入区块链中的交易数据,可以支持零确认交易,交易同步和后续的查询更加实时。在另一优选的实施例中,本申请的区块链链上数据结构化存储方法,还包括以下步骤:所述数据探测模块定时检查已处理区块的哈希值与当前区块链上对应高度区块的哈希值是否一致,若不一致,则清除所述区块高度标志位中对应高度的第二个标志位。由于区块链中每个区块的区块头中保存了当前块的哈希值信息,该哈希值由该区块的所有交易记录计算生成,每个已经生成的区块的哈希值都会保持不变,若已经处理的区块的哈希值与区块链上对应高度区块的哈希值不一致,则说明区块链上发生了分叉并且区块根据最长链原则发生了变化,原先的区块变成了孤块,因此,需要对该高度的区块数据进行重新处理。本申请中,只需将对应高度的第二个标志位清除,数据探测模块在下一次判断的时候,就会根据标志位进行重新处理。通过控制区块高度的第二个标志位,实现在出现孤块的时候,自动地回退和更新交易数据,无需人工干预。下面,以一具体的实施例来进一步说明本申请所述的区块链链上数据结构化存储方法。首先,在网络中部署多个mongo数据库的实例作为区块链数据存储区,同时,在网络中部署一个或者多个区块链的全节点实例。该实施例中,区块链上一笔交易记录如表1所示,该交易存在一个输入,三个输出。该交易本身也是一个数据结构,比特币网络上存储数据通常以tx和block为单位,即通过txid和blockhash来找到对应的交易和对应的区块是比较容易的。这样的设计是为了比特币网络本身能够更好的运行,但对于一些搭建在比特币网络上的应用不是很友好。表1同时,该实施例中包含两个数据过滤模块,为便于区分,我们称之为address_filter和metanet_filter,其中,address_filter是针对一个比特币钱包应用进行数据过滤处理,其需要从区块链的交易记录中找到它关心的地址的相关交易流水。address_filter在得到交易记录的时候,通过解析锁定脚本和解锁脚本,可以得到参与这笔交易的地址,再把其结构化为方便根据地址查询的数据结构(如表2所示)。addresstxidindexisinputpre-txidpre-indexvalue地址1txid30truetxid21300地址2txid30false--100地址3txid31false--200表2另外,metanet是比特币网络上的另外一种协议,其以一个txid和一个公钥的二元组作为metanet的一个节点,节点由父节点生成,可以签署自己的子节点。metanet协议要求,记录有metanet节点的交易,首先有一个输入,该输入的解锁脚本有一个公钥的,以及公钥对应的私钥对交易的数字签名,该公钥即为,父节点的公钥。其次有一个输出的pkscript以操作符op_return开始,接着放上metanet的标志,即“meta”,然后放上要签署的子节点的公钥,称为pnode,最后放上父节点的paraenttxid。至此便产生一个以当前交易的txid和pnode的二元组构成的新的节点。由于metanet是一个由节点构成的树形结构,同样很不方便在比特币网络上检索。本实施例中,通过数据过滤模块metanet_filter,将tx数据转为如表三所示的数据结构,则更方便维护其树状结构。表3假设数据过滤模块address_filter的区块高度标志位中,区块高度小等于990的第一标志位和第二标志位均已经设置为1,其他区块高度的第一标志位和第二标志位均未设置(即为0),本申请所述的区块链链上数据结构化存储方法,包括以下步骤:步骤1、数据探测模块获取区块链当前的最大区块高度,假设取到的值为1000;步骤2、数据探测模块设置当前处理高度初始值,假设取区块链的最小区块高度,即设置为0;步骤3、数据探测模块判断所述当前处理高度0小于所述最大区块高度1000,则跳转至步骤5继续执行;步骤5、数据探测模块根据所述当前处理高度以及区块高度标志位从区块链上获取一个区块,包括以下步骤:步骤51、数据探测模块判断所述当前处理高度(0)的第一标志位已经设置,则说明当前高度的区块曾经被处理过,则执行步骤52继续判断第二标志位,否则跳转至步骤55继续执行;步骤52、数据探测模块判断当前处理高度(0)的第二标志位已经设置,则说明该高度的区块已经处理完成,执行步骤53,否则,说明该高度的区块需要重新处理,则跳转至步骤54继续执行;步骤53、数据探测模块对所述当前处理高度执行加一操作,即将当前处理高度设置为1,并跳转至步骤3继续检查下一个区块是否需要处理;由于区块高度小等于990的第一标志位和第二标志位均已经设置为1,因此重复上述步骤直至当前处理高度为991,跳转至步骤55继续执行。步骤54、由于需要重新处理当前高度的区块数据,因此数据探测模块调用数据存储模块删除当前处理高度对应的所有交易记录;步骤55、数据探测模块从区块链上获取所述当前处理高度(991)对应的区块。步骤6、数据探测模块设置所述区块的对应高度(991)的第一标志位,并将所述区块发送给数据过滤模块;步骤7、数据过滤模块检查所述区块中的交易记录,将需要的交易记录解析为结构化数据,并发送给数据存储模块;具体为:address_filter得到交易数据的时候,首先解析每一个vin解析锁定脚本,从中获得公钥信息,从公钥推导出比特币地址,查看是否是该钱包用户的地址,如果是,则对交易数据进行处理并发送给数据存储模块,接着解析每一个vout的锁定脚本,从中获取地址信息,查看是否钱包用户的地址,如果是,则对交易数据进行处理发送给数据存储模块。如果均不是,则不为当前数据过滤模块关心的数据,不进行处理。步骤8、数据存储模块将所述结构化数据进行存储;步骤9、数据探测模块设置所述区块的对应高度(991)的第二标志位,同时对所述当前处理高度执行加一操作,即设置当前区块高度为992,并跳转至步骤3继续执行;重复执行上述步骤,实现数据过滤模块address_filter将区块链上高度从991至1000的区块数据进行结构化存储,同时将区块高度标志位中从991到1000的区块高度的第一标志位和第二标志位都更新为1。同时,假设数据过滤模块metanet_filter的区块高度标志位中,区块高度小等于890的第一标志位和第二标志位均已经设置为1,区块高度等于891的第一标志位设置为1,第二标志位为0,其他区块高度的第一标志位和第二标志位均未设置(即为0),本申请所述的区块链链上数据结构化存储方法,包括以下步骤:步骤1、数据探测模块获取区块链当前的最大区块高度,值为1000;步骤2、数据探测模块设置当前处理高度,假设从参数配置表读取的初始处理高度配置值为800;步骤3、数据探测模块判断所述当前处理高度800小于所述最大区块高度1000,则跳转至步骤5继续执行;步骤5、数据探测模块根据所述当前处理高度以及区块高度标志位从区块链上获取一个区块,包括以下步骤:步骤51、数据探测模块判断所述当前处理高度(800)的第一标志位已经设置,则说明当前高度的区块曾经被处理过,则执行步骤52继续判断第二标志位,否则跳转至步骤55继续执行;步骤52、数据探测模块判断当前处理高度(800)的第二标志位已经设置,则说明该高度的区块已经处理完成,执行步骤53,否则,说明该高度的区块需要重新处理,则跳转至步骤54继续执行;步骤53、数据探测模块对所述当前处理高度执行加一操作,即将当前处理高度设置为1,并跳转至步骤3继续检查下一个区块是否需要处理;由于区块高度小等于890的第一标志位和第二标志位均已经设置为1,因此重复上述步骤逻辑直至当前处理高度被设置为891,跳转至步骤54继续执行。步骤54、由于需要重新处理当前高度(891)的区块数据,因此数据探测模块调用数据存储模块删除当前处理高度(891)对应的数据过滤模块metanet_filter已经入库的所有交易记录;步骤55、数据探测模块从区块链上获取所述当前处理高度(891)对应的区块。步骤6、数据探测模块设置所述区块的对应高度(891)的第一标志位为1,并将所述区块发送给数据过滤模块;步骤7、数据过滤模块检查所述区块中的交易记录,将需要的交易记录解析为结构化数据,并发送给数据存储模块;具体为:数据过滤模块metanet_filter首先查看vout中是否有以op_return操作符开头的,接着检查脚本后续是否为metanet的标志,即“meta”,再继续检查pnode,paraenttxid,如果这些都符合格式,则此为一个metanet节点,数据过滤模块metanet_filter将其结构化后发送给数据存储模块。步骤9、数据探测模块设置所述区块的对应高度(891)的第二标志位,同时对所述当前处理高度执行加一操作,即设置当前区块高度为892,并跳转至步骤3继续执行;重复执行上述步骤,实现区块链上高度从891至1000的区块数据的结构化存储,同时将区块高度标志位中从891到1000的区块高度的第一标志位和第二标志位都更新为1。需要说明的是,上述实施例中,数据探测模块根据数据过滤模块address_filter和metanet_filter的区块高度标志位信息,根据处理逻辑从区块链上分别获取相应的区块发送给数据过滤模块,每个数据过滤模块按照自己的方式进行数据的过滤和结构化,再发送给数据存储模块,两个数据探测模块的数据处理独立互不干扰。如图3,是本发明一种区块链链上数据结构化存储系统的架构图,包括数据探测模块、数据过滤模块以及数据存储模块,其中,数据探测模块,用于获取区块链当前的最大区块高度;设置当前处理高度初始值,并根据所述当前处理高度以及区块高度标志位从区块链上获取一个区块;所述区块高度标志位包含区块链上每一区块对应高度的第一标志位和第二标志位;用于设置所述区块对应高度的第一标志位,并将所述区块发送给数据过滤模块;用于区块处理结束后设置所述区块对应高度的第二标志位,同时对所述当前处理高度执行加一操作;数据过滤模块,用于检查所述区块中的交易记录,将需要的交易记录解析为结构化数据,并发送给数据存储模块;在一优选的实施例中,数据过滤模块可以为多个,通过在区块高度标志位中增加数据过滤模块编号标识,数据探测模块可以识别出每个数据过滤模块分别已经处理到哪个高度的区块,并发送下一个需要处理的区块。每个数据过滤模块将接收到的区块中需要的交易记录解析为结构化数据,并发送给所述数据存储模块,每个数据过滤模块之间互不干扰并行运行。通过为每一种数据类型设置一个数据过滤模块与其相对,无论多少种类型的结构化数据,都可以通过对应的数据过滤模块来达到支持,扩展性强,应用场景更加灵活。数据存储模块,用于将数据过滤模块发送的所述结构化数据进行存储。在一优选的实施例中,数据存储模块包括多个数据库实例,数据存储模块将所述结构化数据进行存储的时候,会随机挑选一个数据库实例,将结构化数据写入其中。另外,若用户需要对关注的交易进行查询,则数据存储模块可以在所有数据库实例中进行结构化数据的并发查询,并将查询结果进行汇总返回给用户。通过设置多个数据库实例,采用随机插入的方式可以支持无限扩容,一旦当前的数据库实例无法支持数据的容量,可以随意增加数据库实例。同时通过并发统一查询,来实现在数据量大的情况下快速的检索,提高查询的性能。在一优选的实施例中,本申请所述的区块链链上数据结构化存储系统,所述数据探测模块还用于从区块链的内存池中获取未确认交易记录发送给所述数据过滤模块;所述数据过滤模块还用于将需要的未确认交易记录解析为结构化数据,并发送给数据存储模块。在另一优选的实施例中,本申请所述的区块链链上数据结构化存储系统,所述数据探测模块还用于定时检查已处理区块的哈希值与当前区块链上对应高度区块的哈希值是否一致,若不一致,则清除所述区块高度标志位中对应高度的第二个标志位。上述具体实施方式只是对本发明的技术方案进行详细解释,本发明并不只仅仅局限于上述实施例,凡是依据本发明原理的任何改进或替换,均应在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1