基于门控循环单元网络集成的水质预测方法与流程
【技术领域】
本发明涉及一种基于门控循环单元网络集成的水质预测方法,属于水环境检测领域。
背景技术:
水是生命的源泉,是生物赖以生存和经济发展的必要条件。目前我国666个城市中就有近一半的城市缺水。更糟糕的是,在水资源如此缺乏的情况下,受我国工业化进程的快速发展及河流自净能力下降的影响,全国七大水系超70%的河段遭到污染,城市水域约90%遭到严重污染。水污染问题已经成为我国经济社会发展的最重要制约因素之一,水污染的防治得到了国家和地方政府高度重视。根据水质监测历史数据,建立水质预测模型,精确预测水体中污染物的成分变化及未来发展趋势,从而为水污染控制和治理提供信息和技术支持、为水环境保护的具体实施措施提供可靠依据。建立有限可靠的水质预测模型可以将事后治理转换为事前预防,是近年来水环境科学领域研究的热点。
由于水质成分的多样性和复杂性,水质指标直接往往存在高度的非线性关系,传统线性方法很难建立精准的水质预测模型。目前典型的水质模拟模型的研究主要运用了mike21水力水质模型、efdc水动力模块、annagnps流域水文非点源模型和结合一维随机水质降解和二位迁移扩散模型,但这些模型的建立需要充分考虑的自然环境影响,需要专业的人员进行评估,在模型的建立时候需要运用大量的先验知识。门控循环单元作为一种优秀的深度学习时间序列预测方法,可以有效地挖掘和利用动态时间序列的隐藏信息。近年来,集成学习在很多分类和回归任务中体现出了极大的优势,受集成学习巨大性能的启发,本申请人提出了一种基于门控循环单元网络时间序列预测集成方法来解决上述问题,以提高水质的预测精度。
技术实现要素:
本发明专利针对上述现有技术存在的缺陷,设计了一种基于门控循环单元网络集成的水质预测方法。本发明专利的技术系统能很好的利用历史水质指标数据实现水质指标的预测,实现水污染的防治。
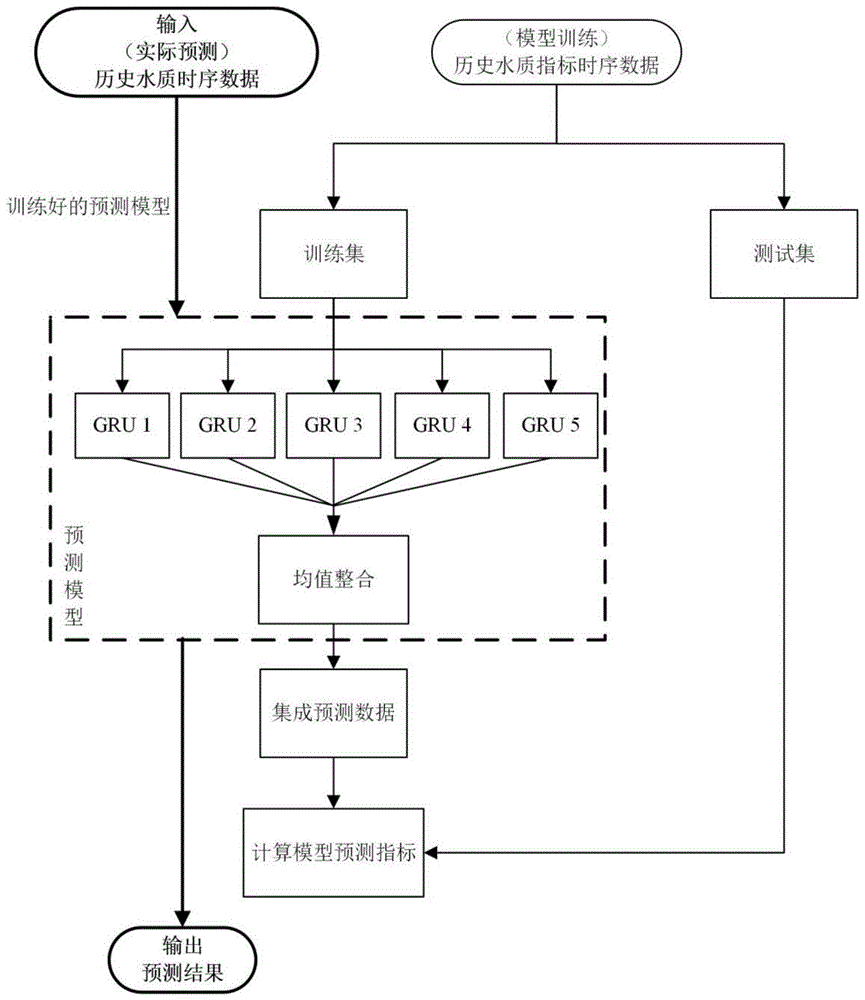
为实现水质的精准预测,本发明专利提出了基于门控循环单元网络集成的水质预测方法。为了提高单一深度学习方法的泛化能力和鲁棒性,在本专利所提出的方法中,首先用m个具有不同隐藏层数和不同神经元个数的门控循环单元(gru),分别预测水质指标的时序数据,以探索和利用时间序列的隐含信息。然后用均值法集成m个gru的输出结果。要求本发明专利的有益效果:本发明专利由python3.6.5的keras工具搭建,再结合正确的数据采集和参数优化,有效提高水质预测精度,从而提高水环境保护的效率。如图1为算法流程图。
整个算法的结构的具体步骤如下:
步骤1:数据采集后进行预处理,得到水质指标时序数据,并划分数据集为训练集和测试集;
步骤2:不同结构的gru网络的搭建;
步骤3:将水质指标时序数据训练数据输入gru,运用反向传播和梯度下降对m个gru网络进行训练;
gru神经网络是循环神经网络(rnn)中的一种特殊变体,gru能够通过其特有的记忆和遗忘模式,对时间序列信息进行动态时间建模,从而得到更好的预测效果。gru门控单元网络包含一个重置门rt,一个更新门zt,其训练过程为:每一个时刻,gru单元通过更新门接收当前输入的水质信息xt与上一个时刻的隐藏状态ht-1,接收输入信息后,通过矩阵点乘运算,由激活函数sigmoid决定神经元是否被激活。同时,gru的重置门接收xt与ht-1,重置门的运算结果决定有多少过去的水质信息需要被忘记。另外,当前时刻输入的水质信息经过运算与重置门的输出信息叠加,再经过激活函数tanh形成了当前的记忆内容ht’。当前记忆ht’与前一步输入ht-1再通过更新门的动态控制,最终决定门控单元的输出内容ht。计算公式如下:
zt=σ(w(z)xt+u(z)ht-1)
rt=σ(w(r)xt+u(r)ht-1)
ht'=tanh(wxt+rt·uht-1)
ht=zt·ht-1+(1-zt)·ht'
其中,w(z)和u(z)是gru更新门的权重;w(r)和u(r)是遗忘门的权重;w与u是当前时刻的记忆权重;σ(·)代表sigmoid激活函数;tanh(·)代表了tanh激活函数;运算符号“·”代表向量的内积形式。gru通过梯度下降法迭代更新所有的参数,计算所有参数基于损失函数的偏导数。
步骤4:搭建最终的预测模型,运用均值法集成训练好的m个gru网络输出结果;
步骤5:将最终模型进行保存,输入测试集进行识别效果测试,最终模型可用于实际水质预测环节。
本专利采用均方误差(mse)作为损失函数,
其中yi是真实的水质情况,ypi是预测的水质情况。
衡量算法的指标为rmse——均方根误差,mape——平均百分比误差,mae——平均绝对误差和拟合优度——r2。
本发明专利算法进行有效进行水质预测,并达到0.085的rmse,0.056的mae,0.848%的mape和0.53的r2的预测效果。
【附图说明】
图1是算法的流程图
图2是门控循环单元结构图
图3是算法结果图
【具体实施方式】
如图1所示为流程图,本专利的实现是集成了m=5不同结构的gru,gru内部结构如图2所示。本算法具体步骤如下:
步骤1:数据采集后进行预处理,得到水质指标时序数据,并划分数据集为训练集和测试集;
步骤2:不同结构的gru网络的搭建;
步骤3:输入训练集,运用反向传播和梯度下降对五个gru网络进行训练;
步骤4:搭建最终的预测模型,运用均值法集成训练好的五个gru网络输出结果;
步骤5:将最终模型进行保存,输入测试集进行识别效果测试,最终模型可用于实际水质预测环节。
所述步骤1包括以下步骤:
步骤1.1:数据采集:本专利的实现方法所采集的数据为:同一位置的4种典型水质指标的历史时序数据,即ph值、do、codmn和nh3-n,但不仅限于这四种指标;
步骤1.2:数据预处理:对指标历史时序数据进行均值法缺失值填补和标准化后得到最终的历史时序数据集。
步骤1.3:数据集划分:将历史时序数据集以8:2的比例划分为训练集和测试集。
所述步骤2包括以下步骤:
不同结构gru网络的搭建:gru-1有l1个隐藏层,每个隐藏层上分别有na(a=1,2,...,l1)个神经元个数。gru-2有l2个隐藏层,每个隐藏层上分别有nb(b=1,2,...,l2)个神经元个数。gru-3有l3个隐藏层,每个隐藏层上分别有nc(c=1,2,...,l3)个神经元个数。gru-4有l4个隐藏层,每个隐藏层上分别有nd(d=1,2,...,l4)个神经元个数。gru-5有l5个隐藏层,每个隐藏层上分别有ne(b=1,2,...,l5)个神经元个数。
所述步骤3包括以下步骤:
步骤3.1:初始化网络内部参数,并将训练集并行输入5个不同的gru中进行同时训练;
步骤3.2:使用反向传播和梯度下降调节所搭建网络的内部参数;
步骤3.3:进行n轮训练后模型收敛。
步骤3.4:训练结束后保存每个训练好的gru模型。
所述步骤4包括以下步骤:
模型的输入数据直接分别输入到每个gru,得到的每个输出结果进行均值整合后才为最终模型的输出预测结果。
所述步骤5包括以下步骤:
步骤5.1:将未经过训练的样本数据输入最终训练好的预测模型
步骤5.2:数据通过模型,分别喂5个不同的gru模型,得到不同的预测结果;
步骤5.3:将所有的预测结果求均值后,与真实值进行对比,得到最终的模型评价指标;
步骤5.4:最终的预测模型可以用于实际水质监测环节。
最终模型的评估结果如表1所示,预测效果以ph值为例如图3所示。从表1可以看出,gru集成方法对比其他单个gru的效果,取得最低的rmse为0.085,0.056的最低mae,0.848%的最低mape和0.53的最高r2。因此,本专利中的算法拥有较好的实用前景和泛化能力。
表1集成结果表
应说明的是,以上实施例仅用以说明本发明专利水质预测说明,而不是对本发明专利的限定。本领域的普通技术人员应当理解,可以对本设计的技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!