神经网络方法、神经网络系统和计算机可读介质与流程
本发明的实施例大致涉及包括神经网络(nn)和存储器的数据和计算处理。更具体地,本发明的实施例涉及用于改善nn推断性能的存储器布局和转换。
背景技术:
神经网络(nn)是一种模仿人脑的机器学习。例如,nn接收输入(向量),并通过由节点(神经元)构成的一系列隐藏层,使用权重或过滤器来变换输入。每个节点可以连接到前一层中的节点以接收输入,最后一个输出层或完全连接层可以提供分类或类别分数。一种常用于图像分类的nn是卷积神经网络(cnn)——例如,使用cnn来确定输入图像是否显示车辆。cnn包括具有可学习的权重和偏差的节点(神经元)层。每个节点可以接收输入,并使用权重对每个输入执行点积(内核计算),以在不同输入之间求和。加权和被馈送到另一节点层中,从而使得输出层的分数可区分——即,一端的原始图像像素输入对输出端的分数进行分类以用于对图像进行分类。
对于cnn来说,在每个节点生成激活或结果可能需要大量的计算,这特别是因为cnn可能在每个层上具有以多个维度(例如宽度、高度和深度)排列的节点,并且可以有数千层。执行cnn计算来确定输入数据的分类(这被称为推断)需要大量的存储器使用,因为输入数据具有多个维度并且用来执行加权点积计算的内核函数需要大量的存储器存取。此外,物理存储器以线性一维方式存储数据,即一次一行,这需要与cnn使用的多维数据进行相关。因此,物理存储器中关于nn数据存储方式的数据布局会显著影响nn推断性能。
技术实现要素:
根据本公开的一方面,提供了一种神经网络方法,其包括:基于从神经网络nn的性能模拟导出的阈值,在多个不同的存储器布局中选择所述nn的存储器布局;以及在nn推断期间,使用所选择的存储器布局存储多维nn内核计算数据。
根据本公开的另一方面,提供了一种神经网络系统,其包括:一个或多个存储器,存储输入特征映射;多个乘法累加单元mac,用于接收所述输入特征映射,以执行神经网络nn的内核计算;以及变换逻辑,用于采用基于从所述nn的性能模拟中导出的阈值在多个不同的存储器布局中为所述nn选择的存储器布局来存储所述输出内核计算。
根据本公开的又一方面,提供了一种包括指令的非暂时性计算机可读介质,该指令如果由处理单元执行,则使得所述处理单元执行包括以下步骤的操作:基于从神经网络nn的性能模拟导出的阈值,在多个不同的存储器布局中选择所述nn的存储器布局;以及在nn推断期间,使用所选择的存储器布局存储多维nn内核计算数据。
附图说明
附图示出了示例和实施例,因此是示例性的,而不被认为是范围上的限制。
图1示出了多维数据的神经网络(nn)存储器布局的一个示例。
图2示出了使用nchw格式的内核计算的一个示例图。
图3示出了具有从输入数据生成元文件的nn模拟器的系统的一个示例框图。
图4a示出了绘制gflops相对于用于nchw布局和chwn布局的批次n的变化值的图表。
图4b示出了绘制gflops相对于用于nchw布局和chwn布局的通道c的变化值的图表。
图5示出了选择存储器布局的操作的流程图的一个示例。
图6示出了具有nn核心的nn系统的一个示例框图。
图7示出了图6的nn系统在nn推断性能期间变换存储器布局的操作的流程图的一个示例。
具体实施方式
以下详细描述提供了用于改善神经网络(nn)推断性能的存储器布局和转换的实施例和示例。对神经网络(nn)的引用包括任何类型的神经网络,包括深度神经网络(dnn)和卷积神经网络(cnn)。nn可以是机器学习算法或过程的实例,并且可以被训练来执行给定任务,例如对输入数据(例如,输入图像)进行分类。训练nn可以包括确定通过nn的数据的权重和偏差。一旦被训练,nn可以在任何数量的层通过使用这些权重和偏差计算输出来执行任务,以产生激活来确定输入数据的分类。因此,使用这些权重和偏差来运行或实现nn以确定输出(例如,类别分数)可以被称为推断。在以下实施例和示例中,nn推断可以在包括集成电路、片上系统(soc)、处理器、中央处理单元(cpu)或图形处理单元(gpu)的嵌入式设备、系统或硬件上执行。
为了改善nn推断性能,例如,nn基于从nn的性能模拟导出的阈值,在多个不同的存储器布局中选择一种存储器布局。nn在nn推断期间使用所选择的存储器布局来存储多维内核计算数据。要选择的存储器布局可以是通道、高度、宽度和批次(chwn)布局,批次、高度、宽度和通道(nhwc)布局以及批次、通道、高度和宽度(nchw)布局。如果nn内核计算数据不是采用的所选存储器布局,则nn针对所选存储器布局变换nn内核计算数据。一个示例是,使用例如ct、nt和fmt等阈值选择存储器布局。ct阈值是通道数阈值,nt阈值是批次数阈值,fmt是当前层每秒10亿次的浮点运算次数(gflops)/当前层存储器特征映射的阈值。这些阈值ct、nt和fmt可以基于nn的性能模拟进行优化和推导。
一个示例是,如果基于输入数据的通道数c小于ct阈值,或者如果基于输入数据的批次数n等于或大于nt阈值,则选择chwn布局。另一个示例是,如果浮点运算数除以存储器大小大于fmt阈值,则选择nhwc布局。另一个示例是,如果没有选择chwn和nhwc布局,则选择nchw布局。通过使用优化的阈值来选择特定的nn存储器布局,所选择的存储器布局改善了数据存储器存取和nn推断性能的计算效率。
详细描述中对“一个实施例”或“一个示例”的引用意味着结合该实施例或示例描述的特定特征、结构或特性可以被包括在本公开的至少一个实施例或示例中。在详细描述中,短语“在一个实施例中”或“在一个示例中”在不同地方的出现不一定指相同的实施例或示例。
如本文所述,将参考下面讨论的细节来描述各种实施例、示例和方面,并且附图将示出各种实施例和示例。以下描述和附图是说明性的,不应被认为是限制性的。描述了许多具体细节以提供对各种实施例和示例的透彻理解。然而,在某些情况下,没有描述众所周知的或传统的细节,以便于简明地论述实施例和示例。
神经网络存储器布局示例
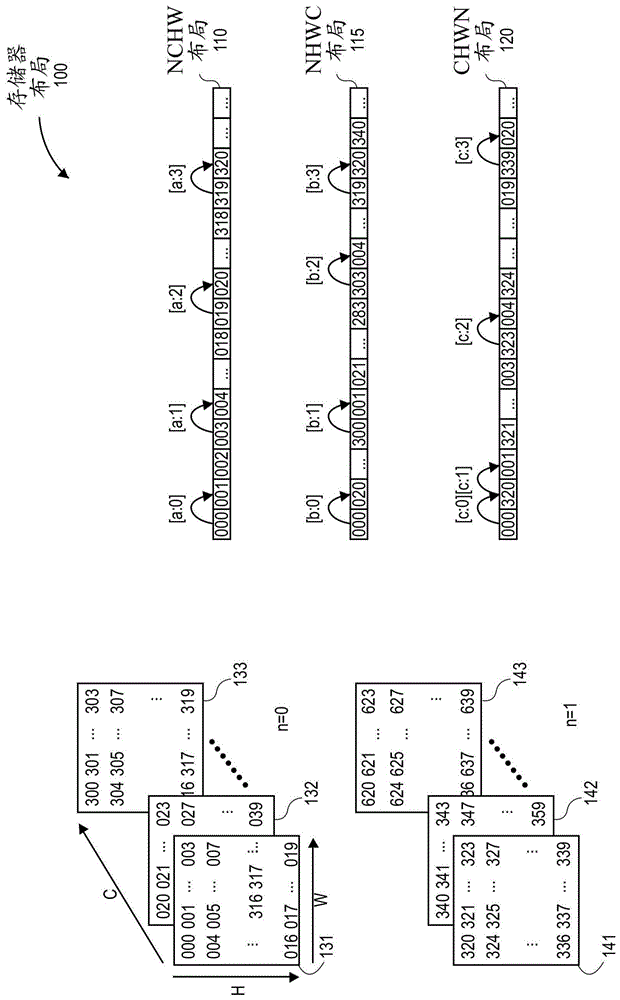
图1示出了多维数据的神经网络(nn)存储器布局100的一个示例。nn多维数据可以具有不同的格式,包括存储在线性存储器地址空间中的nchw布局110、nhwc布局120和chwn布局130。对于存储器布局100,c指的是作为特征映射例如特征映射131至133和141至143的通道。n指的是特征映射的批次或集合的数量,例如,在本例中,具有2个批次,由此n=2。批次由包括特征映射130至133的n=0和包括特征映射141至143的n=1索引。每个特征映射131至133和141至143具有高度h维度和宽度w维度。一个示例是,每个批次n=0和n=1的特征映射131至133和141至143可以指由nn处理的图像。
参考nchw布局110,该布局用于nn层的四维激活。nchw布局110可以用于两个批次,其中n=2并具有两个索引n=0和n=1,16个通道c,以及高度h和宽度w的5×4空间域。对于这些维度,nchw布局110示出了多维数据如何在存储器中线性布局,以便以nchw格式存储和存取。例如,在nchw布局110中,从第一批次n=0、第一通道或特征映射131的第一行(其中h和w=1)开始布局多维数据。在第一通道或特征映射131之后,从下一个通道或特征映射132开始以h和w将多维数据布局在存储器中,直到最后一个通道或特征映射133。多维数据然后进入下一批次(n=1),以h和w对于通道或特征映射141至143进行布局。
在nchw布局110中,[a:n]是指在nchw布局110的存储器中以一维格式布局的多维数据的跳跃。在[a:0],在第一行中从左到右是特征映射131中的000和001处的值,000和001是特征映射131中的索引。在[a:1],多维数据跳到特征映射131的下一排或下一行(h=2),如003和004处的值,直到特征映射131的h=5和w=4。在[a:2],多维数据跳到下一通道或特征映射132(c=2),如019和020处的值,直到特征映射132的h=5和w=4。在[a:3],多维数据跳转到下一批次n=1的第一特征映射141,如319和320处的值。关于nchw布局110中的多维数据如何线性存储在物理存储器中的偏移函数(a)是:
nchw(n,c,h,w)=n*chw+c*hw+h*w+w(a)
nchw的小写字母表示w是最内部的维度,因此存储器中相邻的两个元素将共用相同的n、c和h索引,并且它们的w索引将相差1。在这个示例中,n是这里最外面的维度,使得如果取相同的像素(c,h,w),但是在下一个图像上,数据跳到整个图像尺寸c*h*w。
参考nhwc布局115,从第一批次n=0的每个特征映射131至133的h和w开始布置多维数据。例如,在nhwc布局115中的[b:0]处,第一行中从左到右是特征映射131中h和w=1处的000处的值、特征映射132中h和w=1处的020处的值,并且在存储器中线性地继续到最后的特征映射133。在[b:1],多维数据转到h=1的w维度中的下一个数据,如300001处的值,直到w=4。在[b:2],多维数据跳转到下一行或者h=2,如特征映射133中303处和特征映射131中004处的值。在[b:3],多维数据跳到下一批次n=1的第一特征映射141,如319320处的值。关于nhwc布局110中的多维数据如何线性存储在物理存储器中的偏移函数(b)是:
nhwc(n,h,w,c)=n*hwc+h*wc+w*c+c(b)
在nhwc布局115中,最内部的维度是通道([b:0]),之后是宽度([b:1])、高度([b:2]),最后是批次([b:3])。
参考chwn布局120,多维数据从每个批次n=0和n=1的h和w处的通道开始布局。例如,在chwn布局120中的[c:0]处,第一排中从左到右是在h和w=1处的批次n=0的特征映射131中的000处的值,以及批次n=1中的特征映射141中的320处的值。在[c:1],多维数据来到h=1的w维度中的下一个数据,如特征映射131中w=2的001处的值。在[c:2],多维数据从特征映射141中的h=1处的行跳到特征映射131中的h=2处的行的w=1处,如特征映射131中004处的值。在[c:3],多维数据从批次n=1的特征映射141的第一通道中的最后一行跳到第二通道特征映射132的h和w=1处,如特征映射141中339处的值到c=2的下一通道特征映射132中020处的值。关于chwn布局120中的多维数据如何线性存储在物理存储器中的偏移函数(c)是:
chwn(c,h,w,n)=c*hwn+h*wn+w*n+n(c)
在chwn布局120中,维度顺序从最内到最外依次为批次([c:0])、宽度([c:1])、高度([c:2])、通道([c:3])。
神经网络内核计算示例
图2示出了使用nchw格式的内核计算的一个示例图200。在这个示例中,内核214至217是卷积神经网络(cnn)的过滤器k0至kn。该示例可以用于单指令多数据(simd)指令,使得在一个周期中可以读取4×浮点(fp)32位=128位。内核214至217(k0至kn)可以包括用于cnn的n个卷积层的1×1过滤器。输入y0至y2可以从3×3特征映射201至203(ch0至ch2)的值导出,这些值可以以nchw格式(1×3×3×3)存储。内核计算可以使用其他存储器布局格式,如nhwc或chwn布局。
一个示例是,输入特征映射201至203的索引可以是m(cin)*3(hin)*3(win)。内核214至217(k0至kn)可以具有维度(3×1×1×n),并且内核计算的输出被称为输出(output)。内核k0至kn的索引可以是n(cout)*m(cin)*kh*kw。输出的索引可以是cout*hout*wout。生成输出的内核计算(d)可以表示为:
其中h表示特征映射高度,w表示特征映射宽度。
在该cnn示例中,过滤器包括权重(即突触),输入和输出特征映射包括激活(即输入和输出节点或神经元)。参考内核计算(d),cpu或gpu或其他处理单元可以使用simd指令集来执行乘法累加(mac)运算,这是过滤器的矩阵乘法计算,以输入在c、h和w上求和的数据。也可以使用其他指令集,例如单指令多线程simt。一个示例是,参考图2,输出218可以被计算为output00=ch0[0][0]*k0y0+ch1[0][0]*k0y1+ch2[0][0]*k0y2,并且输出219可以被计算为output20=ch0[2][0]*kny0+ch1[2][0]*kny1+ch2[2][0]*kny2。
存储器布局模拟示例和阈值
图3示出了系统300的一个示例框图,系统300具有从输入数据301生成元文件304的nn模拟器302。nn模拟器302可以包括任何类型的嵌入式设备、系统或硬件,包括集成电路、片上系统(soc)、处理器、中央处理单元(cpu)或图形处理单元(gpu),以执行nn推断,包括如上所述和图2中的cnn的内核计算。一个示例是,nn模拟器302可以模拟图6所示的nn系统600。
一个示例是,nn模拟器302可以使用前馈网络对输入数据301执行cuda-convnetcnn实现方案,并且可以对输入数据301执行cudnn实现方案,这可以为诸如前向和后向卷积、汇集、标准化和激活层的标准例程提供高度调谐的实现方案。输入数据301可以是任何类型的数据,例如,具有任何数量的特征映射和通道(包括红色(r)通道、蓝色(b)通道和绿色(g)通道)的图像数据。
参考图4a,nn模拟器302可以基于模拟来测量图表405中示出的n个批次的不同值的nchw格式和chwn格式的每秒10亿次的浮点运算次数(gflops)。例如,cudnn推断模拟可以使用nchw格式的数据,cuda-convnet推断模拟可以使用chwn格式生成图表405。值n可以代表16、32、64、128和256批次的输入数据或特征映射,这些输入数据或特征映射可用于cudnn和cuda-convnet两种模拟。在n值为16、32和64时,nchw格式比使用chwn格式执行会执行更多的gflops。在n值为128和256时,使用nchw的cuda-convnet推断的执行比使用nchw的cudnn执行更多的gflops。在本例中,在n值在64到128之间时,使用chwn格式的执行开始输出执行nchw格式的执行。从这个示例中可以看出,nt阈值可以确定为在n=64和n=128之间。
参考图4b,nn模拟器302可以基于模拟,针对不同的c值或通道数量,以nchw格式和chwn格式测量gflops,如图表410所示。例如,cudnn推断模拟可以使用nchw格式的数据,cuda-convnet推断模拟可以使用chwn格式生成图表410。c的值可以是1、3、16、32、64、128、256、384和512个图像通道或特征映射,它们可以用于cudnn和cuda-convnet模拟。在c值为1、3和16时,使用chwn格式的执行比使用nchw格式的执行会执行更多的gflops。在c值为32到512时,使用nchw格式的执行比使用chwn格式的执行会执行更多的gflops。在这个示例中,在16和32之间的c值,阈值ct可以在c=16和c=32之间确定。也可以生成其他类型的图表,并确定阈值(例如在确定gflops/存储器大小的阈值fmt时对于不同存储器大小的gflops),其中一种格式相对于gflops性能输出另一种格式。图表405和410中的gflops性能可以基于在某个存储器带宽上有屋顶线(roofline)的nn的屋顶线性能。图表、屋顶线数据和确定的阈值,例如nt、ct和fmt,可以存储在元文件306中,以在在此描述的实施例和示例中用于选择存储器布局以改善nn推断性能。
软件中的存储器布局选择示例
图5示出了为nn选择存储器布局的操作500的流程图的一个示例。一个示例是,任何类型的嵌入式设备、系统或硬件,包括集成电路、片上系统(soc)、处理器、中央处理单元(cpu)或图形处理单元(gpu),以实现程序代码、固件或软件来为诸如图6的系统600的nn执行操作500的框502至519。对于图5的示例,cnn被称为具有任意数量的卷积层n。操作500可以被包括作为nn的优化特征。
在框502,nn开始用于nn推断性能的卷积层n。最初,nn数据使用nchw格式。
在框504,在层n执行内核计算,包括权重和激活计算。框504处的权重和激活可以在框508至519中使用,以选择用于优化目的的存储器布局并改善推断性能。
在框508,检查通道c是否小于通道阈值ct。如果是(y),则在框510,选择chwn布局。例如,参考图4b,当c小于32时,chwn布局输出根据gflops执行nchw布局。此外,在nchw布局中使用的存储器变换性能的成本很高。
如果在框508为否(n),则在框512,检查批次n是否大于批次阈值nt。如果是(y),则在框514,选择chwn布局。例如,参考图4a,当n>64时,chwn布局在gflops方面优于nchw布局。这里,chwn布局是优选的选择,因为n足够大,可以实现存储器合并和数据再利用。
如果在框512为否(n),则在框516,检查当前层的gflops/当前层存储器是否大于特征映射fmt阈值。如果是(y),则在框518,选择nhwc布局作为优选布局。
如果在框516为否(n),则在框519,选择nchw布局,或者如果当前布局仍然是nchw布局,则保持现状。
操作500自身重复,直到所有卷积层n已经被执行。对于使用gpu的一些示例,ct、nt和fmt可以是(32、128、60),其他类型的nn引擎或处理单元,ct、nt和fmt可以是(4、16、30)。基于nn设计、存储器大小等,ct、nt和fmt可以使用任意数量的值,这可以使用如图3至图4b中讨论的模拟来确定。
在处理完所有卷积层n之后,在框506,nn可以生成模型元文件,并且在硬件中离线转换权重存储器布局,这将在图6至图7中解释。
用于变换存储器布局的硬件配置示例
图6示出了具有nn核心601的nn系统600的一个示例框图。nn核心601包括nnmac602和缩放块603、激活块604和汇集块605。nnmac602可以是多维计算单元,用于计算如图2中公开的内核计算,以计算输出(d),该输出包括由累加器620累加的矩阵点积计算,并且累加器的输出在缩放块603缩放。缩放后,在激活块604生成用于卷积层激活数据。激活数据604可以由汇集块605汇集,汇集块605汇聚输入特征映射或通道的每个小区域内的信息,并对结果进行下采样。汇集块605通过外围组件互连快速(pcie)接口615耦合到主机616,并且通过高级可扩展接口(axi)总线610耦合到nn系统600的其他组件。
一个示例是,输出结果可以存储在诸如静态随机存取(sram)存储器609或双倍数据速率(ddr)存储器614的存储器中,该存储器可以是ddr同步动态随机存取存储器(sdram),具有控制存储器存取和去往和来自ddr存储器614的数据传输的ddr控制器(ddrctrl)613。nn核心601的输出结果可以由数字信号处理器(dsp)或精简指令集控制(risc)处理器608处理,用于输入数据例如图像的分类。dsp或risc处理器608还可以实现用于优化nn系统600的存储器布局的程序代码、固件或软件。输入数据或图像可以从耦合到nn系统600内的图像信号处理器611的相机612获得。来自isp611的图像数据可以存储在ddr614或sram609或两者中,用于由nn核心601进行处理,以实现nn推断性能,从而对输入数据进行分类。
一个示例是,dsp或risc处理器608可以实现如图5所述的操作500,以确定存储器布局的转换或变换。dsp或risc处理器608可以发信号给变换逻辑607或与变换逻辑607通信,以将存储器布局变换成用于另一存储器布局的格式,如图7所述。变换逻辑607可以包括现场可编程门阵列(fpga)、可编程逻辑阵列(pla)或其他硬连线逻辑,以将一种存储器布局转换成另一种存储器布局。例如,变换逻辑607可以包括通过将n映射到c、c映射到h、h映射到w以及w映射到n来将nchw布局映射到chwn布局的逻辑。变换逻辑607可以通过将n映射到n、c映射到h、h映射到w以及w映射到c来将nchw布局映射到nhwc布局。其他示例是,变换逻辑可以使用维度到维度映射将任何多维布局映射到具有相同维度的其他多维布局。
图7示出了图6的nn系统600在nn推断性能期间变换存储器布局的操作700的流程图的一个示例。在该示例中,操作700描述了cnn推断性能。
在块702,用于卷积内核计算的初始输入特征映射数据采用nchw格式存储在卷积层n的ddr存储器614中。
在块704,nnmac在块706使用层n输入blob和权重执行内核计算,例如矩阵点积累加,其可以采用nchw格式存储在ddr存储器614中。
在块708,来自nnmac块704的输出特征映射采用nchw格式。
在块710,将来自块708的nchw格式的输出特征映射变换成chwn格式。例如,dsp或risc处理器608可以基于元文件数据发信号或通知变换逻辑607,以执行来自块708的nchw格式的输出特征映射到chwn格式的变换。对于其他示例,在块710,可以基于存储在元文件中的阈值,例如ct、nt和fmt,将块708处的输出特征映射变换成其他格式,例如nhwc格式,如图5中所描述的。
在块712,已经变换成chwn格式的输出特征映射是到下一卷积层n+1的输入特征映射。
在块716,在层n+1,将chwn格式的输入特征映射输入到nnmac,并接收权重。层n+1权重被加载到在块714离线优化的ddr存储器614,并使用层n+1输入blob和权重在卷积层n+1执行内核计算,例如矩阵点积累加。
在块718,将块716的nnmac的输出存储为chwn格式的特征映射,并且处理下一卷积层,直到所有卷积层被处理。
在前面的说明中,参考特定的示例性实施例及其示例描述了本发明。然而,显而易见的是,在不脱离所公开的实施例和示例的更宽的精神和范围的情况下,可以对其进行各种修改和改变。因此,说明书和附图被认为是说明性的,而不是限制性的。
- 还没有人留言评论。精彩留言会获得点赞!