一种微服务关联分析与预测方法
本发明涉及一种服务关联分析预测的方法,尤其涉及一种面向微服务架构应用的服务关联分析与预测,属于计算机软件技术领域。
背景技术:
微服务是一种架构模式,它提倡将单一应用程序划分成一组小的服务,服务之间互相协调、互相配合,服务与服务间采用轻量级的通信机制互相协作(通常是基于http协议的restfulapi)。每个服务都围绕着具体业务进行构建,并且能够被独立的部署到生产环境中。微服务不仅表现出一种新的架构模式,也表现出一种新的组织模式。因此,在部署微服务应用时,需要对每个服务以及服务关联进行配置管理,目前主要通过服务编排技术来实现微服务应用的持续部署。服务编排指的是开发者选择、部署、监视以及动态控制服务资源配置,保证服务质量的一组操作。
当前在服务编排和部署配置方面的相关工作包括如下内容。
oasis组织制定提出了云应用程序的拓扑结构和编排规范tosca(thetopologyandorchestrationspecificationforcloudapplications)。tosca采用yaml或者xml描述云应用组件属性、组件关系以及组件的行为操作(包括安装、卸载等),创建应用部署拓扑和应用部署任务流程,简化云应用的生命周期管理。德国的斯图加特大学遵循tosca标准研发了编排系统opentosca(tobiasbinz,breitenbücheruwe,hauptflorian,etal.opentosca–aruntimefortosca-basedcloudapplications[m].service-orientedcomputing.springer.2013:692-5.),opentosca包含三大部分:图形化建模工具winery、执行环境opentoscacontainer和自助服务门户vinothek。随着服务网格技术的兴起,tosca模型缺乏对服务组件属性、组件关联和组件行为操作的定义和描述,无法满足微服务应用的拓扑描述和编排。此外,marcoautili(marcoautili,amletodisalle,francescogallo,claudiopompilio,andmassimotivoli.2018.model-drivenadaptationofservicechoreographies.inproceedingsofthe33rdannualacmsymposiumonappliedcomputing(sac'18))等人研究了模型驱动的服务编排适配方法,以分布式方式组合服务,通过制定一些规则对服务的交互进行外部协调和适应,从而自动组合服务生成服务编排。但是该方法没有面向一般用户提供服务编排配置管理的操作接口,也缺乏面向微服务应用的服务编排适配机制。
在服务编排过程中,基于服务实体描述或者服务接口描述等语义信息发现满足应用需求及相应约束的组合方案是实现服务编排推荐的重要前提。传统web服务通过wsdl(webservicesdescriptionlanguage)描述服务的属性和功能的本体规范,使得web服务成为计算机可理解的实体,从而便于实现服务的发现、调用、互操作、组合、验证和执行监控等。但是微服务应用使用服务契约(servicecontract)来描述和交付服务,传统基于wsdl的服务组合的方法并不适合微服务应用。
在微服务应用中,服务关联是进行服务编排的前提和依据,因此有效的发现或预测服务关联对于实现微服务的编排十分关键。
技术实现要素:
针对现有技术中存在的技术问题,本发明的目的在于提供一种微服务间关联发现和预测方法,从而为微服务编排提供有依据,辅助实现高效的微服务编排。
本发明的技术方案为:
一种微服务关联分析与预测方法,其步骤包括:
1)对微服务系统进行静态分析,获取该微服务系统中微服务关联知识;其中,微服务关联知识的关联模式包括显式直接关联和传递关联;
2)对于该微服务系统中的两待预测微服务x和y,以微服务x为质心,以服务契约为特征,计算微服务关联知识库rk中每一微服务与微服务x的距离向量;获取所有与微服务x的距离向量并归一化处理,得到相似服务列表xvec={x1,x2,…,xi,…};其中,微服务关联知识库rk用于存储已知的显示直接关联模式的微服务关联知识;xi为与微服务x相似度大于设定阈值的第i个微服务;
3)以微服务y为质心,以服务契约为特征,计算微服务关联知识库rk中每一微服务与微服务y的距离向量,获取所有与微服务y的距离向量并归一化处理,得到相似服务列表yvec={y1,y2,…,yi,…};yi为与微服务y相似度大于设定阈值的第i个微服务;
4)根据微服务关联知识库rk将xvec与yvec中的微服务两两构成微服务关联对:{x1→yy1,x1→y2,x1→y3,…},对应的微服务关联知识为{cms(x1,y1),cms(x1,y2),cms(x1,y3),…,cms(m,n),…},根据微服务关联知识库rk确定第i个微服务关联对的微服务关联知识cms(m,n),cms(m,n)=1代表微服务m与微服务n之间存在关联,cms(m,n)=0代表微服务m与微服务n之间不关联;
5)通过公式
进一步的,如果微服务x的服务定义中直接包含对微服务y的声明依赖,则微服务x和微服务y对应的微服务关联知识的关联模式为显式直接关联;如果微服务x的服务定义中声明了对变量z的关联,而变量z的值表示的是微服务y,则微服务x和微服务y对应的微服务关联知识的关联模式为传递关联。
进一步的,获取显式直接关联的匹配规则模式为:{协议}[分割符]{关联服务名}[分割符]{服务操作}[分隔符]。
进一步的,通过正则表达式定义的服务关联规则cmrre1=[^#](https?|ftp|file|http?|tcp?)://[-a-za-z0-9+&@#/%?=~_|!:,.;]+[-a-za-z0-9+&@#%=~,获取显式直接关联模式的微服务关联知识。
进一步的,通过对微服务x的服务声明和描述及配置文件进行分析,提取其中的赋值表达式,并判断该赋值表达式中微服务x中是否有对服务变量y的声明,构成微服务x的赋值表达式集合;如果该表达式集合为空,则微服务x和y不关联,如果不空,微服务y作为值赋予了变量z,则提取变量z,并判断该微服务x的直接调用链路集合中是否包含该变量z,如果包含,则微服务x和y之间存在传递关联模式的微服务关联知识。
进一步的,通过规则cmrre2=/^[a-za-z\$_][a-za-z\d_]*$/[=]y过滤判断微服务y是否作为值赋予一变量,得到微服务x的表达式集合,如果该表达式集合为空,则微服务x和y不关联,如果不空,微服务y作为值赋予了变量z,则提取变量z,并判断该微服务x的直接调用链路集合中是否包含该变量z,如果包含,则微服务x和y之间存在传递关联模式的微服务关联知识。
进一步的,如果判定微服务x和微服务y存在关联,则将微服务x和微服务y及其对应的微服务关联知识添加到微服务关联知识库rk中。
进一步的,通过计算两微服务之间的向量余弦距离得到所述距离向量。
一种计算机可读存储介质,其特征在于,存储一计算机程序,所述计算机程序包括用于执行上述所述方法中各步骤的指令。
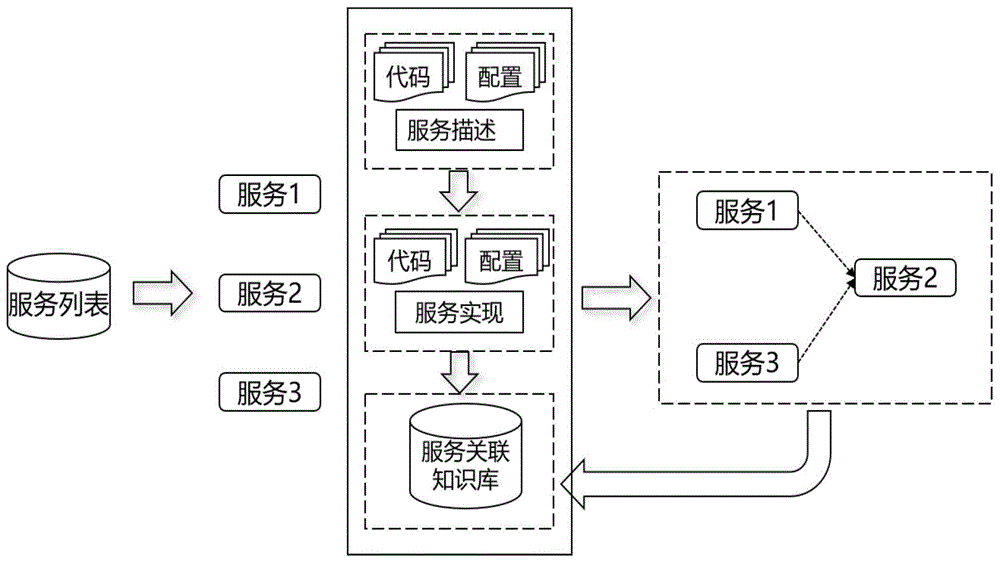
本发明方法流程如图1所示,具体包括了以下几个步骤:
1.微服务关联静态分析,对微服务代码、配置等数据静态分析,获取新的微服务关联知识(即微服务关联知识库rk中不存在的微服务关联关系)。微服务之间存在显式的直接关联和传递关联两种可能的关联模式。显式直接关联中,对于微服务x和y,x的服务定义中直接包含对y的声明依赖;传递关联中,对于微服务x和y,这时x的服务定义中声明了对变量z的关联,而z的值表示的是微服务y,因此实际声明的还是微服务x与y之间存在的关联。
对于显式的直接关联,服务的调用关系链存在特定的模式,例如,服务ts-admin-order-service中调用服务ts-order-other-service、ts-order-service等服务的调用链表示如下:
http://ts-order-other-service:12032/orderother/findall,
http://ts-order-service:12031/order/delete;
根据这些观察和总结,发现其模式为:{协议}[分割符]{关联服务名}[分割符]{服务操作}[分隔符];
因此,对于显式的直接关联本发明方法通过正则表达式定义的服务关联规则cmrre1分析服务x调用服务y的调用链,cmrre1=[^#](https?|ftp|file|http?|tcp?)://[-a-za-z0-9+&@#/%?=~_|!:,.;]+[-a-za-z0-9+&@#%=~,得到微服务调用链路集合。对于微服务x,其服务调用链路集合表示为linkrelationlist={link1,link2,link3…},该集合中包括了微服务x分别调用的微服务,比如link1为微服务x调用了微服务y、link2为微服务x调用了微服务z、link2为微服务x调用了微服务k等。如果集合为空,则不存在关联;如果集合不空且linkrelationlist包含微服务y,则存在x和y之间的关联。
对于传递关联,方法通过规则cmrre2过滤判断y是不是作为某值赋予某变量,cmrre2=/^[a-za-z\$_][a-za-z\d_]*$/[=]y,得到微服务x的表达式集合assignmentexpressionlist。如果集合为空,微服务x和y不关联,如果不空,以z=y为集合的一个元素为例子,提取z,在linkrelationlist判断是否包含z,如果包含,则微服务x和y之间存在传递关联模式的微服务关联知识。
正则表达式cmrre2是为了分析提取服务x中赋值类型表达式的语义信息,通过对微服务x的服务声明和描述及配置文件进行分析,提取其中的赋值表达式,构成x的赋值表达式集合;正则表达式cmrre2对应的是服务x中有对某服务变量的声明,比如z,而z作为变量又可被赋值为y,y表示一个具体的服务。那么,如果通过前一步的直接关联分析得到的集合linkrelationlist中包含了x对z的依赖,由于现在分析可知z能够实例化为y,因此,x也依赖于y。
2.微服务关联预测,对于待预测微服务x和y,结合已有的微服务关联知识库rk(relationknowledge),包含步骤1取得的新的微服务关联知识,预测微服务x和y之间可能的关联。
1)rk中所有微服务的集合为msset={s1,s2,s3,…},rk中存储微服务关联知识表示为{s1→s2,s2→s3,…};
2)基于机器学习聚类分析,以服务x作为质心,以服务契约为特征,计算msset中每一服务与服务x的距离向量,获取所有与服务x的距离向量,归一化处理,得到相似服务列表:xvec={x1,x2,x3,…};
3)以服务y作为质心,以服务契约为特征,计算msset中每一服务与服务y的距离向量,归一化处理,得到相似服务列表:yvec={y1,y2,y3,…};
4)xvec与yvec中的微服务两两构成微服务关联对:{x1→y1,x1→y2,x1→y3,…},这些关系对应已有的关联知识:{cms(x1,y1),cms(x1,y2),cms(x1,y3),…,cms(m,n),…},cms(m,n)表示任意微服务m与n之间的关联,根据微服务关联知识库rk确定第i个微服务关联对的微服务关联知识cms(m,n),cms(m,n)=1代表存在关联,cms(m,n)=0代表不关联。
5)通过余弦相似度和已有的服务关联知识计算x和y的相似度,公式如下所示,得到一组相似度值p1,p2,p3,…,pn,取其中的最大值(假设为pi(1≤i≤n))作为微服务x和y之间可能存在关联的预测结果,即prediction(x,y)=max{p1,p2,p3,…,pk},其中(m,n)分别表示与服务x和y相似的服务集合中第i对相似服务,cms(m,n)表示两者在知识库rk中是否存在已知的关联方法;将阈值设为0.5,即当prediction(x,y)≥0.5时认为微服务x和y存在关联,否则不存在。
xm是微服务m的特征向量,yn是微服务n的特征向量,x为微服务x的特征向量,y为微服务y的特征向量。
3.微服务关联关系的迭代复用,对于预测正确的微服务关联,方法将其加入服务关联知识库复用rk,用以进一步训练提高预测的精度,从而提高后续的微服务关联预测的效率。
本发明的积极效果为:
采用本发明的方法,可以有效修提高,对于存在大量微服务关联的大规模复杂应用系统而言,本发明方法能够显著提升微服务关联分析和发现的效率,进而提高微服务编排效率。
附图说明
图1为本发明方法流程图。
具体实施方式
下面结合附图和实施例对本发明做进一步说明。
以当前主要的开源微服务系统铁路订票系统trainticket为例,它包括了车票查询、预订、付款、改签和用户通知等41个与业务逻辑相关定位服务。
本方法首先通过分析服务间的调用链来获取显式存在的微服务关联。比如在trainticket系统中的微服务ts-admin-order-service调用了微服务ts-order-other-service和ts-order-service等,存在的服务调用链包括:http://ts-order-other-service:12032/orderother/findall,http://ts-order-service:12031/order/delete,采用步骤1中的cmrre1规则可以从服务的代码和配置文件中获取到上述服务中存在的关联信息。
其次,方法收集了大量的开源微服务系统中的服务关联数据构建服务关联知识库rk,然后使用本发明中步骤2中的关联预测方法,对trainticket系统中的服务关联进行预测。
最后,使用本发明中所述方法从trainticket系统中共发现了所有49个微服务关联中的37个,同时准确率和召回率分别达到88.10%和92.5%
上述案例证明本发明方法能够基于静态分析和关联预测对大规模微服务间的关联关系进行有效的发现,对于后续分析微服务间的依赖和调用关系,以及提高微服务应用的编排效率都有积极作用。
- 还没有人留言评论。精彩留言会获得点赞!