一种基于遗传算法的异构多核处理器任务分配与调度策略的制作方法
本发明属于计算机系统结构领域,具体涉及一种基于遗传算法的cpu-gpu异构多核处理器任务分配与调度策略.
背景技术:
伴随着制造工艺的升级,特别是7纳米技术的应用,处理器体系结构发生了巨大的变革.传统的单核结构被物理设计极限和能耗等一系列原因所制约,必然导致摩尔定律重点由单纯的晶体管数量转移到可以被集成在芯片上的核心数量.多核处理器在一个芯片上集成多个处理单元,相比于单核架构优势明显,可以在相对较低的频率下运行单个处理器需要很高的频率才能提供的计算性能,完善单核处理器散热面积过小、高负载运行导致的散热问题.多核处理器架构已经得到了学术界和工业界的普遍认可.
根据处理器系统之间的内核差异,将多核处理器系统分为同构多核处理器系统和异构多核处理器系统.同构多核处理器系统在提升系统整体性能时存在一些不可避免且难以处理的问题.kumarr等人指出同构多核处理器只是简单的核堆砌,势必会增加能耗和散热的负担.在接近系统性能瓶颈时,继续通过简单的增加相同结构的处理器内核再也无法显著提高多核处理器整体性能,这也是非常著名的amdahl定理,整个系统的性能受到软件中必须串行部分的制约.异构多核处理器在一定程度上弥补了同构多核处理器的不足,rakeshkumar等人指出异构多核处理器虽然不能完全解决这一问题,但是可以在很大程度上缓和amdahl定律,并且在提升系统吞吐量,节约能耗等方面也相对于同构处理器有较大优势.着眼未来,异构是处理器系统发展的必然趋势.
虽然异构多核处理器在能耗方面优于同构多核处理器,但能耗问题仍然是制约处理器发展的一大障碍。
多核处理器系统的任务分配与调度对系统运行能耗有很大影响,在早期研究者致力于通过任务分配来降低同构多核处理器耗能,取得了出色的结果.随着异构多核处理器的兴起,很多研究者将研究重点转移到异构多核处理器系统的任务分配领域.异构多核处理器内部结构设计更加复杂,任务调度的难度更大.不少研究者将智能算法通过改进优化应用在异构多核处理器任务分配领域,取得了丰硕的成果.
baruahs对任务分配模型进行线性规划建模求解,通过解决线性规划问题处理任务分配,第一次论证了异构多核处理器的周期性任务分配是一个"np"难问题.虽然这是一个"np"难问题,但是很多算法可以解决异构多核处理器环境中实时任务分配问题,包括传统的实时任务调度算法,如截止-单调(dm)算法,速率-单调(rm)算法,最小松弛优先(llf)算法,最早期限优先(edf)算法,以及基于线性规划的(lp)算法和近年来非常热门的群体智能算法,如蚁群优化(aco),粒子群算法(pso),遗传算法(ga),蛙跳算法(sfla)等.
andrewj.page等为动态异构分布式系统开发了任务调度程序.它是一种基于遗传算法的任务分配方案,将任务动态映射到异构分布式系统.该算法已在java分布式系统上实现,并使用生物信息学、生物医学工程、计算机科学和密码学领域的一系列用例进行测试,实验表明该算法比其他常用的启发式算法获得了更高的效率.但是该模型中的任务之间没有依赖关系,导致了应用的局限性.ayarir等人将多目标遗传算法nsga-ii进行改进,应用到异构分布式多处理器系统上,旨在优化完工时间、内存消耗和通信成本.junchulchoi等人提出了一种基于遗传算法的调度方案,旨在最小化smp多核架构的执行延迟.将调度问题划分为四个子问题:节点到核心的映射,每个核心上节点的调度,内存对象生命周期的延长(代码,通道缓冲区,内部状态和临时变量),以及将内存对象放置到smp上.实验结果表明,与非优化方法和先前方法相比,该方案显著降低了重叠开销.rabehayari等人将遗传算法(ga)与单调速率调度(rm)相结合,应用在异构多核处理器任务分配中,旨在优化任务的最短完成时间.rabehayari等人设计了一种全新的染色体交叉方法,能够减少算法的迭代次数.但是作者建模时并未考虑任务间的依赖关系和通信代价,导致应用范围存在局限性,并且所提出的染色体交叉方法并不能用于带有依赖关系的任务分配模型中.
国内研究者徐立超将异构多核处理器架构设置为n个处理器节点,每个处理器节点含有不同种类的处理单元核,采用启发式算法对任务进行分组,这一步相当于同构多核处理器的任务分配,再使用遗传算法来进行任务调度.作者第一次提出用遗传算法解决异构多核处理器的耗能问题.黄璐将遗传算法改进后运用到云计算的任务分配模型中,还将模拟退火算法引用到遗传算法中,一定程度上避免了遗传算法的易早熟、陷入局部最优解的缺陷.田辉提出将有关联且不在同一处理单元上的任务进行复制的思想,使每个处理单元能独立执行计算任务,减少不同处理单元之间的通信开销.该方案使用混合粒子群算法调度任务,避免某个处理单元因任务分配过多导致计算机不能及时准确地得出结果.徐雨明等受生物学染色体启发,提出了一种异构计算系统中依赖任务调度的双螺旋结构遗传算法,旨在缩短完成时间.相对于传统的遗传算法,该算法有效的提高了收敛速度和有效性.邓蓉和刘梦青等则根据异构系统特点建模,并通过蚁群算法求解,在过程中对蚁群算法进行改进,使系统性能显著提升.重庆大学易娟根据任务图的不同特征,提出三种对应的算法.当任务图为路径时,提出path_assign算法,当任务图为树时,提出tree_assign算法,这两种算法都能在多项式时间内获得最优解.当处理一般性任务图时,给出了整数线性规划模型,该模型总能求出最优解,但当任务图变得比较复杂时,整数线性规划不能在短时间内求解.因此易娟提出了一种在多项式时间复杂度内的dag_heu启发式算法.该模型没有考虑到任务间通信代价也会对系统功耗有很大影响.
技术实现要素:
异构系统中不同类型的处理单元计算能力不同,本发明根据异构多核处理器和计算任务的特点,提出了一种基于遗传算法的cpu-gpu异构多核处理器任务分配与调度策略,用于解决用最小的能耗代价完成任务分配的问题。
本发明研究的异构多核处理器系统的处理单元数为m,每个处理单元一次可以执行一个子任务,这允许系统同时处理m个子任务.如何用最小的能耗代价完成任务的处理是本发明要解决的内容。
本发明所述异构多核处理器的任务分配与调度包括全局任务调度器中的任务分配和各个处理单元上的本地调度,主要过程可以分为以下几个步骤完成:首先将全局任务调度器中的一个任务按照各个子任务的顺序和通信信息转换为一个有向无环图,这个有向无环图用一个dag图表示;然后将各个子任务发送到各个处理单元,每个处理单元按照本地任务序列进行处理;最后在执行过程中运用改进的遗传算法对任务分配与调度方案进行优化,运用遗传算法找到接近最优解的任务分配与调度方案,得到的方案可以运用于下一次该任务的分配与调度,提高异构多核处理器系统的效能、节约能耗.
为了得到近似的最优异构多核处理器任务分配与调度策略,本发明采用以下方案.
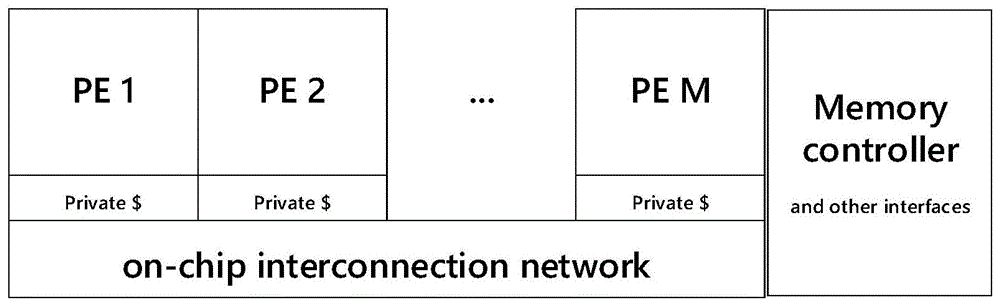
一种基于遗传算法的cpu-gpu异构多核处理器系统任务分配与调度策略,异构多核处理器结构图如图1所示,处理单元(pe)有cpu和gpu两种类型,每个pe通过片上结构相连,pe之间的距离为两个pe之间的曼哈顿距离.
异构多核处理器任务分配与调度的研究热点是存在约束的任务模型.该研究用具有方向的dag图表示任务间约束及通信关系.用五元组(g{t,e,t,d,e})描述dag任务图的任务节点、节点间依赖关系以及通信量,其中t是每个子任务节点的集合;e是所有子任务之间依赖关系的集合,在图中表现为连接两个子任务节点的有向边,用一个n×n阶矩阵表示,若存在依赖关系则nij值设为1,否则为0;t表示不同类型的pe在执行任务的时间消耗,使用n×m的二维数组表示,其中tij的值为任务i在编号为j的处理单元中的预估执行时间;d为具有依赖关系的任务间通信量矩阵,也是一个n×n阶矩阵,dij表示任务i与任务j之间的通讯代价,若无通讯则将值设置为c(极大整数);e是不同pe执行不同子任务所产生的能量消耗,也用一个n×m阶矩阵来表示,eij的值为任务i在编号为j的pe中的能量消耗.该模型表达了平台的异构性.
任务分配与调度方案用二维矩阵pij表示,任务分配与调度执行矩阵,若编号为i的任务在编号为j的处理单元上执行,则pij的值设为1,否为0.
本发明所述的异构多核处理器的任务分配与调度包括全局任务调度器中的任务分配和各个处理单元上的本地调度,包括以下步骤:首先将全局任务调度器中的一个任务按照各个子任务的顺序和通信信息转换为一个有向无环图,这个有向无环图用一个dag图表示;然后将各个子任务发送到各个处理单元,每个处理单元按照本地任务序列进行处理;最后在执行过程中运用改进的遗传算法对任务分配与调度方案进行优化,找到接近最优解的任务分配与调度方案,得到的方案可以运用于下一次该任务的分配与调度,其特征在于:所述的改进的遗传算法包括以下步骤:
第一步:初始化遗传算法参数,并根据系统模型特点生成初始种群,初始种群的每个个体代表一种任务分配方案,所述种群生成方法具体如下:
(i)根据dag任务图计算所有任务的高度值h(ti);
(ii)将所有任务随机分配给异构多核处理单元;
(iii)将每个核心上被随机分配的任务按照(i)中所得到的h(ti)从小到大排序,排序结果即为该处理单元上任务的执行顺序;
(iv)若初始种群规模达到要求,则执行步骤二;否则转回(ii);
传统的遗传算法随机产生初始种群,并无任何条件限制,但是考虑到任务模型中任务间具有依赖关系,所以在本模型中对传统遗传算法产生初始种群方法进行改进,使之适应任务模型.
第二步:计算种群中所有个体的适应度函数值(fitnessfunction),并根据适应度由大到小的顺序对种群中的所有个体进行排序;
第三步:染色体交叉(crossover)产生新的种群,具体为:对步骤二中排序后的相邻的两条染色体进行交叉操作产生后代,对产生的后代与其亲代重新计算适应度,并根据适应度由大到小的顺序选择出新的种群,且新种群规模与亲代种群规模保持一致;
第四步:染色体变异(mutation)产生新种群,变异概率pm如下给出:
其中,fitmax是指种群中所有调度方案里最大的适应度函数值,fits是指调度方案s的适应度,fit是指种群中所有调度方案的平均适应度函数值.
种群中个体适应度的平均值。变异的具体操作为:对于每一个个体产生一个[0,1]之间的一个随机数p,若p大于变异概率pm,则该个体进行变异操作,单个染色体变异的过程具体为:该染色体的随机位置对应值得改变,该值的改变对应着子任务执行的处理器编号的改变。对变异后的个体与其亲代重新计算适应度,并根据适应度由大到小的顺序选择出新的种群,且新种群规模与亲代种群规模保持一致;
遗传算法的参数中变异概率pm的选择对遗传算法行为和性能有较大影响.传统的遗传算法对个体随机地进行变异操作,当变异概率过大时,容易使种群中适应度较高的优秀个体的基因遭到破坏,进入随机搜索;而变异率过低又难以引入新的基因,使算法迭代后期搜索陷入停滞,出现早熟、陷入局部最优解等问题,此时形成的映射方案并不是全局最优方案.如果经过反复试验来确定pm的值,比较繁琐.为了有效地保留种群中的优良个体,又保证有效地产生一些较好的新个体,对传统遗传算法中的变异概率进行改进是有必要的.
第五步:若达到最大迭代次数,则输出适应度函数最大的任务分配方案;
否则分别寻找连续多代种群的最优解,然后根据连续多代种群最优解之间的汉明距离判断是否潜在早熟收敛情况,若未发生早熟则转入第三步;若发生早熟现象则启用注入策略后转入第二步。
在改进的遗传算法中提高算法质量的关键除了改进变异算子外,还有强大的补充多样性机制.该机制基于注射策略,即注入用户定义的随机数量的人工染色体(映射解决方案).每当检测到潜在的早熟收敛情况时,就会激发这种注射策略.该机制基于检测连续世代最佳解决方案间的汉明距离.如果最佳解决方案在一代代之后保持相同,则注入策略启动.该策略能解决遗传算法中存在易收敛、易早熟、陷入局部最优等问题。
选取适应度函数直接影响到算法的收敛速度以及能否找到最优解.适应度函数的复杂度与算法迭代次数密切相关,所以适应度函数的设计应尽可能简单,尽可能使计算的时间复杂度小。
与大多数智能算法相同,遗传算法也根据适应度函数的值来判断其解得好坏,适应度值大则为较优解、反之则为较差解.设当前种群的规模为scale,调度方案s执行时异构多核处理器产生的功耗记为:etotal(s),当前种群运行功耗总和esum为:
由于目标是使得系统的功耗降低,所以将调度方案s适应度函数值定义如下:
本发明建立了异构多核处理器系统功耗模型.针对所建立的映射模型,异构处理器系统能耗由三部分组成:背景功耗(eback)、通讯功耗(etran)、运行功耗(ecomp).背景功耗不管处理单元是否被使用一直存在.通讯功耗是任务之间通讯所产生的能耗.运行功耗是处理单元执行任务时所消耗的能量.这三类能耗总和就是处理器消耗的总耗能.当处理单元上没有任务运行时,此时主要能耗就是背景功耗.
所述调度方案s的功耗etotal(s)如下所示:
etotal(s)=eback(s)+etran(s)+ecomp(s)
其中,eback(s)为调度方案s的背景功耗,设处理器计算任务总时间为t,eback为单位时间内产生的背景功耗,则
etran(s)为调度方案s的通讯功耗,设单位通信量传输单位距离需要的功耗为etran,相邻两个处理单元的距离设为单位距离l,不同处理单元间的距离用它们之间的曼哈顿距离l表式,例如编号为0和3的处理单元之间的距离用l13=2l.
定义:lij为子任务i和子任务j之间的距离,用它们所在处理单元之间的距离表示,规定在同一处理单元计算的两个任务间距离为0.矩阵d表示子任务之间的通信量矩阵,dij为任务通讯矩阵d中的元素,若任务i与j在同一处理单元计算,则元素dij置为0.
则调度方案s的通讯功耗如下可由下计算:
ecomp(s)为调度方案s的计算功耗,具体表示如下:
其中,n为任务总量,m为处理单元总量,cij为任务i在处理单元j上执行的能量消耗,pij为任务分配与调度执行矩阵中的元素,若任务i在处理单元j上执行,则pij的值设为1,否为0。
步骤二中所述的当前种群运行功耗总和esum的计算公式具体如下:
步骤五中所述的早熟收敛的判断条件为:当连续多代种群最优解之间的汉明距离为0时,判断为早熟收敛。
步骤五中所述的注入策略指随机产生任务分配方案并将其加入现有种群中迭代过程中。
步骤五中所述的最优解指种群中适应度最大的任务分配方案。
有益效果
在以往研究中,研究者目标是最小化完工时间表,能耗因素被次要看待.随着处理器发展,能耗逐渐成为制约处理器发展的最主要因素之一,本发明将能耗作为任务分配与调度模型的首要考虑因素.通过对异构多核处理器系统的任务进行分配和调度降低能耗、提高效能.
附图说明
为使本发明的目的、策略更加通俗易懂,下面将结合附图对本发明进一步说明.
图1为本发明所研究的cpu-gpu异构多核处理器系统结构图;
图2为dag任务图;
图3为基于改进遗传算法的任务分配与调度方案流程图.
具体实施方式
本发明研究的是一种基于遗传算法的cpu-gpu异构多核处理器任务分配与调度策略,异构多核处理器为了充分的利用计算优势,并行计算的任务数也迅速增加.处理器的设计结构等方面也变得更加复杂,随之也给处理器的任务分配与调度带来许多问题.合理的任务分配与调度策略能够有效节约处理器耗能、提高效能.在异构系统中,不同核结构的核心的计算能力不同,发明所研究的cpu-gpu异构多核处理器系统结构图如图1所示,假设异构多核处理器核心数为m,建立一个长度为m的一维数组p表示这m个核心,记为p{p0,p1,p2,p3,…pm-1}
步骤1,将全局任务调度器中的一个任务按照各个子任务的顺序和通信信息转换为一个有向无环图,这个有向无环图用一个dag图表示如图2所示.图2表示一个由14个子任务组成的任务模型,这个14个子任务将在图1所示的m个处理单元组成的异构多核处理器系统上执行.m个处理单元理论上可以同时处理m个子任务.每个dag任务图表示一个任务节点、节点间依赖关系及通信量组成的五元组,记为g{t,e,t,d,e},用t表示单个子任务节点的集合,图2中有14个节点;e是所有子任务之间依赖关系的集合,用一个n×n阶矩阵表示,若存在依赖关系则nij值设1,否则设置值为0,图中n12值为1,n24则为0;t表示不同种类的核心在执行任务时所消耗的时间,可以通过使用一个n×m的二维数组表示,其中tij的值为任务i在编号为j的处理单元中的预估执行时间;d为具有依赖关系任务间的通信量矩阵,也是一个n×n阶矩阵,dij表示任务i与任务j之间的通讯代价,若无通讯则将值设置为c(是一个非常大的整数)图中d12值为23,d24则为c;e是不同核心上执行不同子任务所产生的能量消耗,也用一个n×m阶矩阵来表示,eij的值为任务i在编号为j的核心中能耗。
步骤2,初始化遗传算法参数,并根据系统模型特点生成初始种群.初始种群的每个个体代表着一条染色体,一条染色体即为一种映射方案.每条染色体由一串基因组成,每个基因代表一个任务,基因的值表示异构多核处理器处理单元的编号.传统的遗传算法随机产生初始种群,并无任何条件限制,考虑到任务间具有依赖关系,所以在本模型中根据以下规则生成种群:
(i)根据dag任务图计算所有任务的高度值h(ti);
(ii)将所有任务随机分配给异构多核处理单元;
(iii)将每个核心上被随机分配的任务按照(i)中所得到的h(ti))从小到大排序,排序结果即为该处理单元上任务的执行顺序;
(iv)若初始种群规模达到要求,则执行步骤二;否则转回(ii);
步骤3,计算种群中所有个体的适应度函数值(fitnessfunction),并根据适应度由大到小的顺序对种群中的所有个体进行排序;
异构多核处理器系统功耗由背景功耗、通讯功耗、运行功耗三部分组成,即调度方案s的功耗etotal(s)如下所示:
etotal(s)=eback(s)+etran(s)+ecomp(s)
其中,eback(s)为调度方案s的背景功耗,无论pe是否正在执行任务,背景功耗一直存在,它只与总的运行时间有关.设处理器计算任务总时间为t,eback为单位时间内产生的背景功耗,则
etran(s)为调度方案s的通讯功耗,通讯功耗与存在通信的两个处理单元间距离有关,当任务分配与调度方案确定后,可根据任务在具体处理单元的位置计算通讯功耗.设单位通信量传输单位距离需要的功耗为etran,相邻两个处理单元的距离设为单位距离l,不同处理单元间的距离用它们之间的曼哈顿距离l表式,例如编号为0和3的处理单元之间的距离用l13=2l.
定义:lij为子任务i和子任务j之间的距离,用它们所在处理单元之间的距离表示,规定在同一处理单元计算的两个任务间距离为0.矩阵d表示子任务之间的通信量矩阵,dij为任务通讯矩阵d中的元素,若任务i与j在同一处理单元计算,则元素dij置为0.
则调度方案s的通讯功耗如下可由下计算:
ecomp(s)为调度方案s的计算功耗,具体表示如下:
其中,n为任务总量,m为处理单元总量,cij为任务i在处理单元j上执行的能量消耗,pij为任务分配与调度执行矩阵中的元素,若任务i在处理单元j上执行,则pij的值设为1,否为0。
种群中所有调度方案的能耗和记为esum,则调度方案s(0≤s≤scale-1)的适应度函数计算公式如下:
步骤3,染色体交叉(crossover)产生新的种群,具体为:对步骤二中排序后的相邻的两条染色体进行交叉操作产生后代,对产生的后代与其亲代重新计算适应度,并根据适应度由大到小的顺序选择出新的种群,且新种群规模与亲代种群规模保持一致;
步骤4,染色体变异(mutation)产生新种群,变异概率pm如下给出:
其中,fitmax是指种群中所有调度方案里最大的适应度函数值,fits是指调度方案s的适应度,fit是指种群中所有调度方案的平均适应度函数值.
种群中个体适应度的平均值。变异的具体操作为:对于每一个个体产生一个[0,1]之间的一个随机数p,若p大与变异概率pm,则该个体进行变异操作,单个染色体变异的过程具体为:该染色体的随机位置对应值得改变,该值的改变对应着子任务执行的处理器编号的改变.与上一部相同,经过变异的染色体也需要通过轮盘选择新种群;
步骤5,若达到最大迭代次数,则输出适应度函数最大的任务分配方案;否则分别寻找连续多代种群的最优解,然后根据连续多代种群最优解之间的汉明距离判断是否潜在早熟收敛情况,若未发生早熟则转入第三步;若发生早熟现象则启用注入策略后转入第二步。
步骤6,在步骤5中得到的全局近似最优解作为下一次任务执行的分配与调度方案,该方案能够在下一次任务执行时降低处理器系统功耗,提升效能。
- 还没有人留言评论。精彩留言会获得点赞!