一种医学CT图像中病变的识别方法与流程
本发明属于医学技术领域,特别是涉及一种医学ct图像中病变的识别方法。
背景技术:
近年来,随着深度学习的发展,人工智能越来越成熟,ai+是利用人工智能技术以及互联网平台,让人工智能与传统行业、新型行业进行深度融合,创造新的发展生态。如今ai+已经成为一种趋势,而在所有领域当中,医疗是被认为可以最早开始现实应用的领域。
医学ct图像是用以发现病变的主要手段之一,因此其智能识别方法也受到了广泛的关注。在专利《病变识别模型的训练方法、验证方法和病变图像识别装置/cn201710584595.3》中,公开了一种病变识别模型的训练方法,包括:利用获取的病变图像样本对fasterrcnn网络进行训练,得到病变识别模型。还相应提供了基于该病变识别模型的病变图像识别装置和病变识别模型的验证方法。该发明提供的病变识别模型的训练方法,基于深度学习理念设计,在使用该模型进行病变识别时,可以较为准确地判断病灶的位置和类型。专利《基于深度学习和数据融合的肺结节分级判定方法和系统/cn201710340309.9》公开了一种基于深度学习和数据融合的肺结节分级判定方法和系统,该发明采用深度学习中的卷积神经网络模型,并结合多源数据整合技术,通过验证与测试得出专门针对ct肺结节进行分级判定的方法,且判定过程全面且可靠,有效提高了判定结果的准确性,进而能够有效地辅助医生进行疾病诊断工作。类似的技术可见于cn201611042753.4、wous16025266、us15225597、wous17024071专利。这些技术的共同特点是采用了深度学习模型,需要大量的运算资源与有标注样本,因此存在一定的局限性。
技术实现要素:
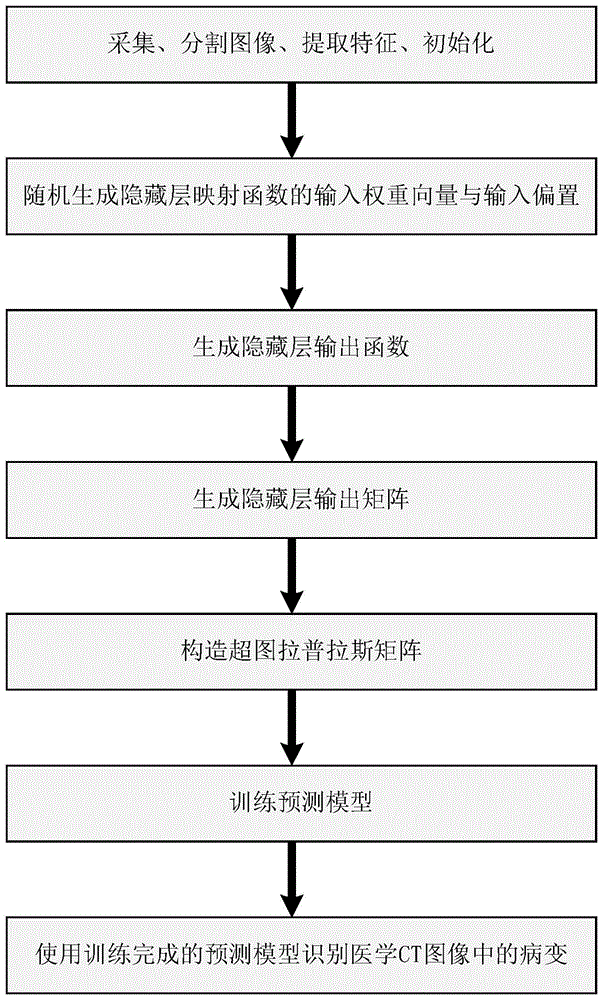
本发明克服现有技术的不足,提出一种医学ct图像中病变的识别方法,其过程如下:
步骤1、采集大量医学ct图像,对于每张图像,采用一种或几种固定大小的窗口对其进行随机分割,以得到一系列子图
初始化:人工设定以下参数:平滑系数λ1>0,风险系数λ2>0,损失系数c0>0,隐藏层节点数n>0,风险阈值
步骤2、随机生成隐藏层映射函数的输入权重向量
随机生成n个w,得到w1,...,wn;随机生成n个b,得到b1,...,bn;
步骤3、生成隐藏层输出函数:
h(x)=[g(w1,b1,x),...,g(wn,bn,x)]t
其中,g(w,b,x)为激活函数,x表示样本,上标t表示矩阵的转置;
步骤4、生成隐藏层输出矩阵:
h=[h(x1),...,h(xn)]t
步骤5、构造超图拉普拉斯矩阵:
其中,dv为顶点度的对角矩阵,de为超边度的对角矩阵,q为边权的对角矩阵,p为事件矩阵,i为单位阵;这些矩阵的计算方式如下:
定义v为顶点集合,v∈v表示一个顶点,e为v子集的一个族且满足ue∈ee=v,e为超边,每个超边e的权值表示为q(e),每个顶点v的度定义为d(v)=∑e∈e|v∈eq(e),每个超边e的度定义为δ(e)=|e|;用一个|v|×|e|矩阵表示事件矩阵p,如果v∈e,则p的第v行第e列元素p(v,e)=1,否则p(v,e)=0,d(v)=∑e∈eq(e)p(v,e),δ(e)=∑v∈vp(v,e),d(v)为dv对角线上的第v个元素,δ(e)为de对角线上的第e个元素,q(e)为q的对角线上的第e个元素;
步骤6、训练预测模型:
步骤601:令
步骤602:得到预测模型如下:
其中,in为n维单位阵,c为n×n的对角阵,其前l个对角元素为
步骤603:令
步骤604:计算
步骤7:将新的医学ct图像按照一种或几种固定大小的窗口对其进行随机分割,得到一系列子图,提取特征后得到每个子图的特征向量x并带入模型f(x)进行预测。
其中,所涉及的激活函数g(w,b,x)为:
或:
其中,医学ct图像子图的特征提取方法采用自动编码器、或视觉词典。
其中,所述自动编码器包括至少一个卷积层和一个池化层。
该发明具有以下优点:1)仅仅需要专家为医疗影像进行少量的标注;2)能够充分利用数据分布与先验连接信息,以实现少量数据下的高准确性分类;3)模型训练高效,无需借助大量昂贵的高速计算机;4)能够一定程度上提升分类精度的下界。
附图说明
图1为本发明方法流程图;
图2为本发明图像分割示意图;
具体实施方式
下面结合实例对本发明作进一步描述,但本发明的保护范围并不限于此。
如图1所示,本发明包括以下步骤:
步骤1、采集大量医学ct图像,对于每张图像,采用一种或几种固定大小的窗口对其进行随机分割,以得到一系列子图
初始化:人工设定以下参数:平滑系数λ1>0,风险系数λ2>0,损失系数c0>0,隐藏层节点数n>0,风险阈值
步骤2、随机生成隐藏层映射函数的输入权重向量
随机生成n个w,得到w1,...,wn;随机生成n个b,得到b1,...,bn;
步骤3、生成隐藏层输出函数:
h(x)=[g(w1,b1,x),...,g(wn,bn,x)]t
其中,g(w,b,x)为激活函数,x表示样本,上标t表示矩阵的转置;
步骤4、生成隐藏层输出矩阵:
h=[h(x1),...,h(xn)]t
步骤5、构造超图拉普拉斯矩阵:
其中,dv为顶点度的对角矩阵,de为超边度的对角矩阵,q为边权的对角矩阵,p为事件矩阵,i为单位阵;这些矩阵的计算方式如下:
定义v为顶点集合,v∈v表示一个顶点,e为v子集的一个族且满足ue∈ee=v,e为超边,每个超边e的权值表示为q(e),每个顶点v的度定义为d(v)=∑e∈e|v∈eq(e),每个超边e的度定义为δ(e)=|e|;用一个|v|×|e|矩阵表示事件矩阵p,如果v∈e,则p的第v行第e列元素p(v,e)=1,否则p(v,e)=0,d(v)=∑e∈eq(e)p(v,e),δ(e)=∑v∈vp(v,e),d(v)为dv对角线上的第v个元素,δ(e)为de对角线上的第e个元素,q(e)为q的对角线上的第e个元素;
步骤6、训练预测模型:
步骤601:令
步骤602:得到预测模型如下:
其中,in为n维单位阵,c为n×n的对角阵,其前l个对角元素为
步骤603:令
步骤604:计算
步骤7:将新的医学ct图像按照一种或几种固定大小的窗口对其进行随机分割,得到一系列子图,提取特征后得到每个子图的特征向量x并带入模型f(x)进行预测。
优选地,所涉及的激活函数g(w,b,x)为:
优选地,所涉及的激活函数g(w,b,x)为:
优选地,医学ct图像子图的特征提取方法采用自动编码器。
优选地,医学ct图像子图的特征提取方法采用视觉词典。
优选地,所述自动编码器包括至少一个卷积层和一个池化层。
图2展示了从原图中分割出子图的方式,首先我们先确定窗口的尺寸,然后将随机选择窗口的左上角点的位置,进而从原图中分割出一张张子图。
在构造超图时,超图的一个顶点对应到一个样本,某个样本x与距离x最近的k个样本共同构成一个超边。
对于采集到的医学影像,一般需要做一些图像预处理工作,对待识别的所述医学ct图像进行转正、缩放、滤波、分辨率调整处理。
no为病变类型的数量加1是因为:对于每个子图,要求将其分类到规定的病变类型或者无病变。
以下是一组推荐的初始化方式:
平滑系数λ1=0.1,风险系数λ2=0.01,损失系数c0=0.3,隐藏层节点数n=40,风险阈值
提供以上实施例仅仅是为了描述本发明的目的,而并非要限制本发明的范围。本发明的范围由所附权利要求限定。不脱离本发明的精神和原理而做出的各种等同替换和修改,均应涵盖在本发明的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!