一种目标典型活动模式偏离告警方法与流程
本发明属于计算机领域,具体涉及一种目标典型活动模式偏离告警方法。
背景技术:
随着移动目标定位技术(如gps、无线电定位等)的快速发展,可获取的目标移动数据(如生物足迹,车辆行驶轨迹,飞机、船舶航迹等)的数据量日益增长,这些数据中蕴藏着丰富的知识与信息。在对目标轨迹数据分析挖掘的过程中人们发现,目标的活动往往存在规律性,表现在:一是目标存在相对固定的频繁活动范围,即活动热点区域;二是目标存在相对固定的一条或多条典型活动轨迹序列,例如飞机、船舶的固定航线。这种规律性称为典型活动模式。在对目标实时活动位置监测的过程中,及时发现目标活动偏离其典型模式并进行告警通知,具有重要的意义。现有技术中目标的典型轨迹序列通常是预先知晓的,而实际情况中典型轨迹往往未知,需要从历史活动数据中总结提取,而目标活动容易受到各种实时因素影响,因此基于预设典型轨迹序列的目标活动偏离告警并不准确。
技术实现要素:
本发明的目的在于提供一种目标典型活动模式偏离告警方法。
实现本发明目的的技术解决方案为:一种目标典型活动模式偏离告警方法,包括如下步骤:
步骤1,采集目标历史轨迹数据,构建目标历史轨迹数据集;
步骤2,利用基于密度的聚类方法对轨迹点划分簇,对得到的每一个轨迹点簇求取外包多边形,提取目标历史活动热点区域;
步骤3,基于网格编码方法计算轨迹点序列对应的网格编码序列,对网格编码序列中连续相同的值进行去重,提取目标历史轨迹的空间网格序列集;
步骤4,基于动态时间规整方法计算目标历史轨迹空间网格序列集中两两序列之间的相似度,选择相似度小于预设阈值的序列对进行簇合并,提取目标典型轨迹集;
步骤5,判断目标当前轨迹是否全部位于目标历史活动热点区域内,若否,则进行等级二的典型活动模式偏离告警,否则不告警;
步骤6,对目标当前轨迹进行空间网格剖分,获得空间网格序列集,计算目标当前轨迹空间网格序列与目标典型轨迹网格序列集内所有典型轨迹的空间网格序列之间的相似度;
步骤7,基于目标当前轨迹与目标典型轨迹集内所有典型轨迹之间的相似度,判断相似度是否全部小于预设的阈值,若否,则不进行告警,若是,则进行等级一的典型活动模式偏离告警。
本发明与现有技术相比,其显著优点为:1)从目标历史活动轨迹数据中提取出目标活动典型轨迹,目标活动偏离告警更加准确;2)对目标活动偏离典型活动轨迹和热点活动区域的情况进行告警通知,通过其偏离程度决定告警等级,供使用者进行决策处置的优点。
附图说明
图1是本发明目标典型活动模式偏离告警方法的流程图。
具体实施方式
下面结合附图和具体实施例,进一步说明本发明方案。
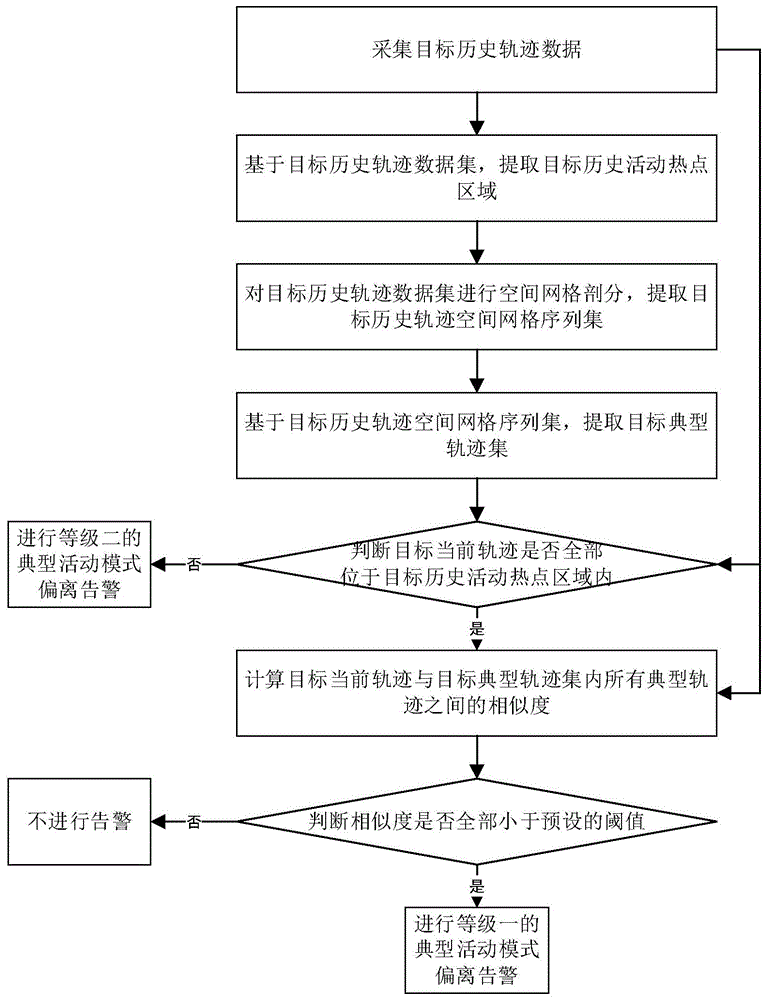
如图1所示,目标典型活动模式偏离告警方法,包括如下步骤:
步骤1,采集目标历史轨迹数据;
目标历史轨迹数据可以是由各种定位技术、装置(如船载gps系统等)收集到的历史轨迹信息,包含经纬度信息、时间戳信息等位置细节信息;目标历史轨迹数据集中的任一条轨迹,可以是带有时间戳信息的、有始有终的活动轨迹,任一时间戳可以有对应的经纬度位置信息。
步骤2,基于目标历史轨迹数据集,提取目标历史活动热点区域;
提取目标历史活动热点区域采用基于密度的聚类方法中的dbscan算法,将目标历史轨迹数据集作为算法输入,输出轨迹点划分簇,对得到的每一个轨迹点簇求取其外包多边形,所得到的多边形集即为所述目标历史活动热点区域。
(1)dbscan(density-basedspatialclusteringofapplicationswithnoise)是一种典型的密度聚类算法,算法流程简要介绍如下:
输入:样本集d=(x1,x2,...xm),邻域参数(ε,minpts),其中,xi为第i个目标历史轨迹数据,ε为样本的邻域距离阈值,minpts为邻域中样本个数的阈值。
(a)检查样本集d中每点的邻域,若样本集中任一点xi的邻域包含点数量多于minpts,则创建一个以xi为核心对象的簇;
(b)迭代各样本点,合并这些核心对象直接密度可达的样本对象;
其中,直接密度可达的定义为:如果p在q的邻域内,而q是一个核心对象,则称对象p从对象q出发时是直接密度可达的。
(c)当没有新的点添加到任何簇时,算法结束。
输出:簇划分c={c1,c2,...ck},其中,ci为第i个轨迹点划分簇;
(2)求取轨迹点簇外包多边形的方法如下:
(a)将点簇中经度坐标值最小的点设为初始点p,记录点p坐标;
(b)以p为基点,从12点方向开始逆时针扫描,记录扫描到的第一个点q坐标;
(c)以q为新的基点,从12点方向开始逆时针扫描,记录扫描到的第一个点坐标;
(d)重复基点更新和扫描,直到回到初始点p,记录的所有点坐标即为外包多边形的顶点。
步骤3,对目标历史轨迹数据集进行空间网格剖分,提取目标历史轨迹空间网格序列集;
空间网格剖分是基于网格编码方法,将目标历史轨迹作为输入,计算轨迹点序列对应的网格编码序列;将轨迹点序列转换成的网格编码序列中连续相同的值进行去重,仅保留连续不同的网格编码,获得空间网格序列集;
(1)空间网格剖分是基于网格编码方法,将目标历史轨迹点序列转换成网格编码序列,轨迹点序列指的是任一条由有限个轨迹点有序组成的有始有终的轨迹,类似的,所得到的网格编码序列指的是任一条有有限个网格编码有序组成的有始有终的序列。轨迹点数据的网格编码可以直接通过如下公式(1)由经纬度转换得到:
其中,c,r,span=180/2l为中间变量,l为网格划分级数,int为取整,geocode为轨迹点对应的网格编码。
(2)从网格编码序列中连续相同的值进行去重,仅保留连续不同的网格编码,即获得空间网格序列集。
步骤4,基于目标历史轨迹的空间网格序列,提取目标典型轨迹集;
步骤4.1、基于动态时间规整方法,计算目标历史轨迹空间网格序列集中,两两序列之间的相似度;计算相似度采用动态时间规整方法中的dtw算法,将基于步骤3得到的空间网格序列作为输入,计算得到两两网格序列的相似度。dtw(dynamictimewarping)是一种通过把时间序列进行延伸和缩短,来衡量两个时间序列之间的相似度的方法,算法的简要原理如下:
输入时间序列a=(a1,a2,...am),b=(b1,b2,...bn),其中a=(a1,a2,...am),b=(b1,b2,...bn)由目标历史轨迹点构成;
(a)构建代价矩阵(costmatrix)d,大小为m*n,其中m为时间序列a长度,n为时间序列b长度。
(b)采用动态规划思想,通过如下公式迭代地计算矩阵d:
d(i,j)=dist(i,j)+min[d(i-1,j),d(i,j-1),d(i-1,j-1)](2)
其中,d(i,j)为代价矩阵(i,j)位置的值,dist(i,j)为时间序列a中第i点ai与时间序列b中第j点bj的距离,dist(i,j)的具体计算方法如下:
(b-1)利用下述公式,将两点网格编码转换为经纬度坐标值;
其中,plat为轨迹点经度值,plon为轨迹点纬度值,%为取余。
(b-2)设点ai的经纬度坐标为(lona,lata),点bj的经纬度坐标为(lonb,latb),经过下述处理过程:按照0度经线的基准,东经取经度的正值,西经取经度负值,北纬取90-纬度值,南纬取90+纬度值,得到处理后的两点坐标(mlona,mlata)和(mlonb,mlatb)
(b-3)根据下述公式计算两经纬度坐标点距离:
其中,c为中间变量,sin为正弦函数,cos为余弦函数,arccos为反余弦函数,r≈6371(km)为地球半径,dist为两点间距离;
(c)时间序列a,b之间的相似度定义为s=d(m,n)/(m+n)。
步骤4.2,对目标历史轨迹空间网格序列进行编号,判断所述两两序列之间的相似度是否小于预设的阈值,若是,则记录下当前两个序列对应的编号;
相似度预设的阈值选取的标准可以是:根据具体应用场景下,一条轨迹的轨迹点与另一条轨迹的轨迹点中最近的点的欧式距离的平均值小于一个值时,两条轨迹在具体应用场景意义下“足够接近”,则该值可作为预设阈值。如在本专利的一个实施例中,当两条飞机的轨迹点距离平均值小于10km时,两条飞机轨迹可认定为“足够接近”,则相似度阈值预设为10000米。
步骤4.3,统计序列对应的编号的出现次数,按次数从多至少对编号排序,提取编号对应的序列;
步骤4.4,对编号对应的序列进行簇合并,获取目标典型轨迹集;
对序列进行簇合并采用的是层次聚类方法,将步骤4.3得到的网格序列作为输入,输出得到簇合并后的固定数量的目标典型轨迹集。层次聚类(hierarchicalclustering)是聚类算法的一种,通过计算不同类别数据点间的相似度来创建一棵有层次的嵌套聚类树。在聚类树中,不同类别的原始数据点是树的最低层,树的顶层是一个聚类的根节点。算法的简要原理如下:
(a)计算输入数据集中网格序列两两之间的相似度;
(b)保留相似度最大的一对数据点类中,数据点数量较大的类;
(c)反复迭代这一过程,当进一步的迭代导致非期望结果时,上述过程结束,停止条件如:达到预先给定的簇数目。
层次聚类方法中使用的相似度计算方法与步骤401中使用的动态时间规整方法相同;目标典型轨迹集的预设固定数量为人为事先设置的值,一些实施例中,该值取5,即得到的目标典型轨迹集中包含典型轨迹数量为5。
步骤5,判断目标当前轨迹是否全部位于目标历史活动热点区域内,若否,则进行等级二的典型活动模式偏离告警;
目标当前轨迹可以是由各种定位技术、装置(如船载gps系统等)收集到的目标当前轨迹信息;目标历史活动热点区域是由步骤201得到的多边形集;等级二的典型活动模式偏离告警是指,发出通知使用者的告警信息,告知使用者目标当前活动轨迹较大地偏离了目标历史典型活动模式。
步骤6,对目标当前轨迹进行空间网格剖分,获得空间网格序列集,计算目标当前轨迹网格序列与目标典型轨迹网格序列集内所有典型轨迹网格序列之间的相似度;
获取目标当前轨迹空间网格序列的方法与步骤301、302中采用的方法相同。目标当前轨迹网格序列与目标典型轨迹网格序列集内所有典型轨迹网格序列之间的相似度计算采用的是最长公共子序列方法,将基于步骤404得到的目标典型轨迹集中的各条典型轨迹与目标当前轨迹作为输入,输出得到目标当前轨迹与各典型轨迹之间的相似度。最长公共子序列(longestcommonsubsequence,lcs)是一种衡量两个时间序列之间的相似度的方法。算法的简要原理如下:
输入时间序列a=(a1,a2,…am),b=(b1,b2,…bn),其中a=(a1,a2,…am),b=(b1,b2,...bn)分别由目标当前轨迹网格序列与目标典型轨迹网格序列构成;
(a)构建代价矩阵(costmatrix)d,大小为m*n,其中m为时间序列a长度,n为时间序列b长度。
(b)采用动态规划思想,通过如下公式迭代地计算矩阵d:
其中,d(i,j)为代价矩阵(i,j)位置的值,dist(i,j)为时间序列a中第i点ai与时间序列b中第j点bj的距离,thr为预设的距离阈值,max为求最大值;
(c)时间序列a,b之间的相似度定义为s=d(m,n)/max(m,n)
步骤7,基于步骤6得到的目标当前轨迹与目标典型轨迹集内所有典型轨迹之间的相似度,判断相似度是否全部小于预设的阈值,若否,则不进行告警,若是,则进行等级一的典型活动模式偏离告警。
相似度预设的阈值选取的标准可以是:选取的阈值使得目标当前轨迹与典型轨迹之间在空间距离上足够接近时,计算出的相似度应大于阈值;等级一的典型活动模式偏离告警是指,发出通知使用者的告警信息,告知使用者目标当前活动轨迹较小地偏离了目标历史典型活动模式。
- 还没有人留言评论。精彩留言会获得点赞!