一种提高语义相似度训练方法及装置与流程
本发明涉及数据处理
技术领域:
,尤其涉及一种提高语义相似度训练方法及装置。
背景技术:
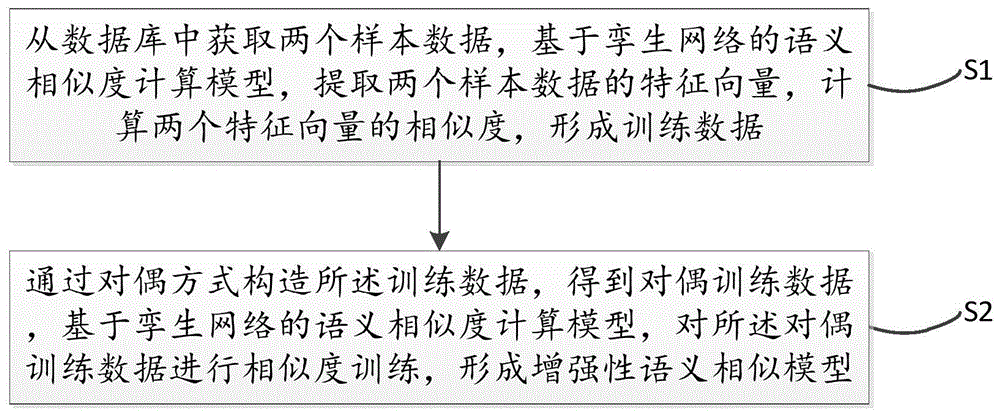
:随着人工智能的发展和普及,智能客服在社会的需求越来越大,而采用智能客服回答客户的问题基本都有一个行业内的知识库,常常称为faq问答对,faq问答对知识库的规模决定了一部分机器人的智能程度,机器人另外一部分的智能程度由相似问句检索决定,尤其是相似问句检索精度,如果知识库中存在相应的知识,但是相似度检索模块却没能检索到库中存在的问答对会导致机器人无法给出回答,显得智能程度很低;如果相似度检索模块检索到了错误的问答对,就会导致答非所问,会显得机器人非常傻,大幅度降低用户体验,如何提升faq检索精度成为智能客服的关键技术。现有计算语义相似度的主流方法为基于有监督的孪生网络,其网络结构为左右两个输入,各自输入一个句子,输出为两者是否相似的一个label,1表示相似,0表示不相似,左右两边共享权值。该方法对于判断两个词之间的相似性精度尚可,但是对于判断两个句子之间的相似性直接用cos效果尚缺,于是各种优化方法接踵而至,如采用负欧式距离作为距离度量等,目前最流行的方法为采用全连接函数,最后加上一个sigmoid函数用作二分类,得到相似或者不相似的label。技术实现要素:本发明提供一种提高语义相似度训练方法及装置,其主要目的在于实现能根据对偶构造出的数据,用于数据增强训练,提高数据相似度训练的精度。为实现上述目的,本发明还提供一种提高语义相似度训练方法,所述方法包括:s1:从数据库中获取至少两个样本数据,基于孪生网络的语义相似度计算模型,提取两个样本数据的特征向量,计算两个特征向量的相似度,形成训练数据;s2:通过对偶方式构造所述训练数据,得到对偶训练数据,基于孪生网络的语义相似度计算模型,对所述对偶训练数据进行相似度训练,形成增强性语义相似模型。优选的,步骤s1进一步包括:s11:所述两个样本数据分别作为所述基于孪生网络语义相似度计算模型的第一输入和第二输入,计算两个样本的相似度,并标注二者是否匹配的关联性标识;步骤s2进一步包括:s21:通过对偶方式构造所述两个样本数据分别作为所述基于孪生网络语义相似度计算模型的第二输入和第一输入,得到与步骤s11相同的相似度,并标注与步骤s11相同的关联性标识。优选的,所述是否匹配的关联性包括:所述两个样本数据之间为彼此关联,即二者匹配;所述两个样本数据之间为彼此不关联,即二者不匹配。优选的,所述数据库包括正样本数据和负样本数据;其中所述正样本数据用于存储关联匹配的多个样本数据;所述负样本数据用于存储不匹配的多个样本数据。为实现上述目的,本发明还提供一种提高语义相似度训练装置,所述装置包括:获取单元,用于从数据库中获取至少两个样本数据,基于孪生网络的语义相似度计算模型,提取两个样本数据的特征向量,计算两个特征向量的相似度,形成训练数据;对偶构造单元,用于通过对偶方式构造所述训练数据,得到对偶训练数据,基于孪生网络的语义相似度计算模型,对所述对偶训练数据进行相似度训练,形成增强性语义相似模型。本发明实现了基于孪生网络建立的语义相似度模型,利用权值共享以及相似的传递性,可以简单的通过相似的传递性对于孪生网络的训练做一个数据增强,即a与b相似,则必定有b与a相似,以此可以将训练数据集翻倍,提升孪生网络的精度。附图说明图1为本发明一实施例提供的提高语义相似度训练方法的流程示意图;图2为本发明一实施例提供的一种提高语义相似度训练装置的结构框图。本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。具体实施方式应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。本发明一实施例提供一种提高语义相似度训练方法,该方法应用于电子设备中,所述电子设备包括,但不限于医美机器人、终端、电子设备等等。该方法基于孪生网络建立的语义相似度模型,利用权值共享以及相似的传递性,可以简单的通过相似的传递性对于孪生网络的训练做一个数据增强,以此可以将训练数据集翻倍,提升孪生网络的精度。参照图1所示,为本发明一实施例提供的提高语义相似度训练方法的流程示意图,流程示意图应用于电子设备中。该方法可以由一个电子设备执行,该电子设备可以由软件和/或硬件实现。本实施例提高语义相似度训练方法并不限于流程图中所示步骤,此外流程图中所示步骤中,某些步骤可以省略、步骤之间的顺序可以改变。所述方法包括:s1:从数据库中获取至少两个样本数据,基于孪生网络的语义相似度计算模型,提取两个样本数据的特征向量,计算两个特征向量的相似度,形成训练数据;s2:通过对偶方式构造所述训练数据,得到对偶训练数据,基于孪生网络的语义相似度计算模型,对所述对偶训练数据进行相似度训练,形成增强性语义相似模型。优选的,步骤s1进一步包括:s11:所述两个样本数据分别作为所述基于孪生网络语义相似度计算模型的第一输入和第二输入,计算两个样本的相似度,并标注二者是否匹配的关联性标识;例如,对于孪生网络的训练数据格式通常如下,对于相似的句子标注为1,对于不相似的句子标注为0,如下表所示:第一输入第二输入标注句子1句子21句子1句子20..................句子1句子21步骤s2进一步包括:s21:通过对偶方式构造所述两个样本数据分别作为所述基于孪生网络语义相似度计算模型的第二输入和第一输入,得到与步骤s11相同的相似度,并标注与步骤s11相同的关联性标识。优选的,所述是否匹配的关联性包括:所述两个样本数据之间为彼此关联,即二者匹配;所述两个样本数据之间为彼此不关联,即二者不匹配。优选的,所述数据库包括正样本数据和负样本数据;其中所述正样本数据用于存储关联匹配的多个样本数据;所述负样本数据用于存储不匹配的多个样本数据。例如,对于孪生网络的训练,将以上类似的句子输入进去训练是目前所有的孪生网络所共有的,但由于权值共享以及相似的传递性,可以简单的通过相似的传递性对于孪生网络的训练做一个数据增强,即a与b相似,则必定有b与a相似,以此可以将训练数据集翻倍,提升孪生网络的精度。以下为数据增强后的数据,如下表所示:第一输入第二输入标注句子1句子21对偶构造句子2句子11句子1句子20对偶构造句子2句子10..................上表中,通过对句子对偶构造出的数据,用于数据增强训练,通过此种方式训练孪生网络在内部数据集上精度可提高0.5%个点左右。本方案提出一种训练孪生网络数据增强的方法,利用相似的传递性,通过一个简单的原输入和对偶输入加入到训练集中训练孪生网络,有效提高基于孪生网络的语义相似度的精度。参照图2所示为本发明一实施例提供的一种提高语义相似度训练装置的结构框图;所述装置包括:获取单元,用于从数据库中获取至少两个样本数据,基于孪生网络的语义相似度计算模型,提取两个样本数据的特征向量,计算两个特征向量的相似度,形成训练数据。进一步包括:(1)所述两个样本数据分别作为所述基于孪生网络语义相似度计算模型的第一输入和第二输入,计算两个样本的相似度,并标注二者是否匹配的关联性标识;(2)通过对偶方式构造所述两个样本数据分别作为所述基于孪生网络语义相似度计算模型的第二输入和第一输入,得到与上述(1)相同的相似度,并标注与上述(1)相同的关联性标识。对偶构造单元,用于通过对偶方式构造所述训练数据,得到对偶训练数据,基于孪生网络的语义相似度计算模型,对所述对偶训练数据进行相似度训练,形成增强性语义相似模型。所述两个样本数据之间为彼此关联,即二者匹配;所述两个样本数据之间为彼此不关联,即二者不匹配。所述数据库包括正样本数据和负样本数据;其中所述正样本数据用于存储关联匹配的多个样本数据;所述负样本数据用于存储不匹配的多个样本数据。本方案实现了基于孪生网络建立的语义相似度模型,利用权值共享以及相似的传递性,可以简单的通过相似的传递性对于孪生网络的训练做一个数据增强,即a与b相似,则必定有b与a相似,以此可以将训练数据集翻倍,提升孪生网络的精度。上述实施例中的实施方案可以进一步组合或者替换,且实施例仅仅是对本发明的优选实施例进行描述,并非对本发明的构思和范围进行限定,在不脱离本发明设计思想的前提下,本领域中专业技术人员对本发明的技术方案作出的各种变化和改进,均属于本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1