人脸活体检测方法、系统、设备及可读存储介质与流程
本发明涉及图像识别技术领域,特别涉及一种人脸活体检测方法、系统、设备及可读存储介质。
背景技术:
人脸识别,是基于人的脸部特征信息进行身份识别的一种生物识别技术,该技术正越来越广泛的应用于安防、金融、教育等各个行业领域中。目前主流的人脸识别技术只能区分不同人脸之间的区别,而无法辨别是否用户本人在使用人脸识别。当用户的人脸信息泄露,不法分子就可以通过用户的人脸信息制作照片、视频、三维人脸模型来欺骗人脸识别系统,造成用户的财产和信息损失,因此需要人脸活体检测技术来判别进行识别的人脸的载体是否是真实的人,还是照片、视频、面具等非活体攻击手段。
现有的单目活体检测的方法有:1.提取单帧图片中人脸的纹理信息或屏幕中的摩尔纹;2.通过深度学习进行单帧单目人脸估计;3.通过深度学习进行多帧单目人脸估计。其中,纹理特征与环境光照和相机类型有关,摩尔纹与相机的分辨率有关,导致该类特征的鲁棒性较差,无法应对多环境下多类型相机的活体检测;基于深度学习的单帧人脸图像的人脸深度估计算法也只考虑人脸区域的特征,且也与图像的纹理强相关,特征的鲁棒性依然不高;基于深度学习的多帧人脸图像的人脸深度估计算法融合了多帧图像中的信息,在一定程度上提高了深度估计的鲁棒性,但是依然只考虑了人脸区域的特征,没有引入更鲁棒的特征。
技术实现要素:
本发明要解决的技术问题是如何提供一种鲁棒性好的人脸活体检测方法、系统、设备及可读存储介质。
为了解决上述技术问题,本发明的技术方案为:
第一方面,本发明提出一种人脸活体检测方法,包括步骤:
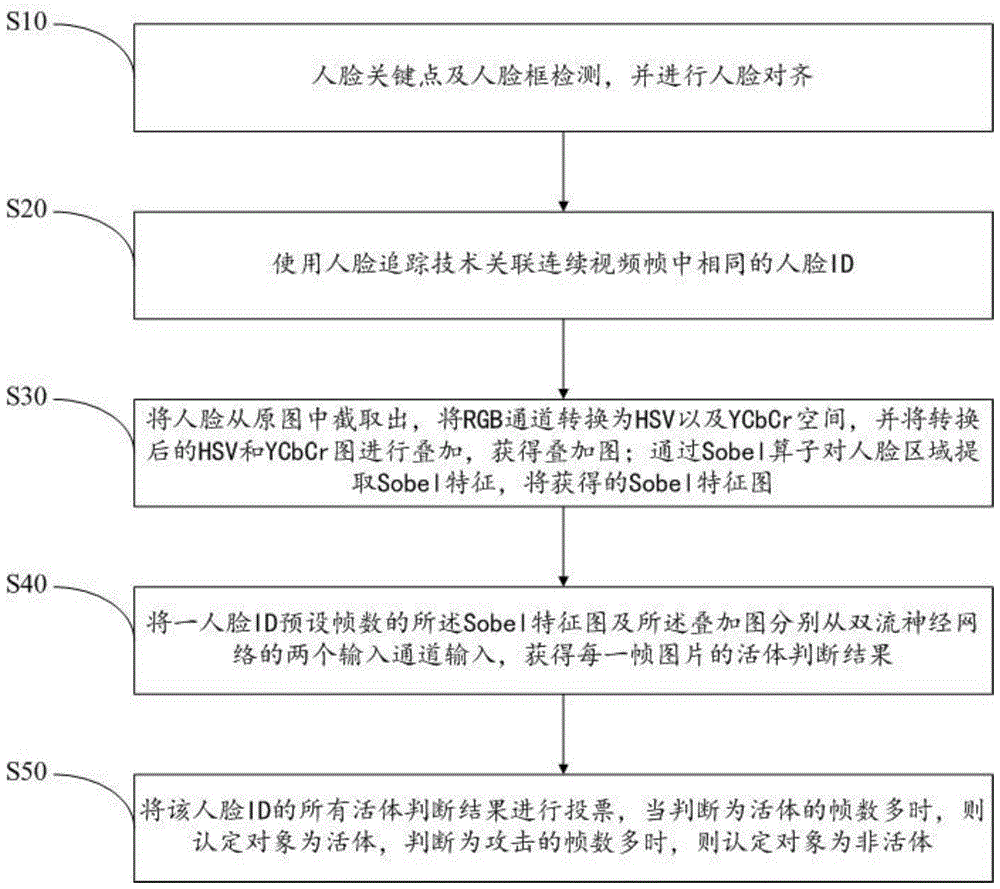
通过人脸检测得到人脸框以及人脸关键点的坐标,并通过人脸关键点的坐标进行人脸对齐;
使用人脸追踪技术关联连续视频帧中相同的人脸id;
将人脸从原图中截取出,将rgb通道转换为hsv以及ycbcr空间,并将转换后的hsv和ycbcr图进行叠加,获得叠加图;通过sobel算子对人脸区域提取sobel特征,将获得的sobel特征图;
将一人脸id预设帧数的所述sobel特征图及所述叠加图分别从双流神经网络的两个输入通道输入,获得每一帧图片的活体判断结果;
将该人脸id的所有活体判断结果进行投票,当判断为活体的帧数多时,则认定对象为活体,判断为攻击的帧数多时,则认定对象为非活体。
优选地,将人脸框面积大于图片的预设比例的图片以及人脸长宽小于预设大小的图片删除。
优选地,在通过sobel算子对区域提取sobel特征的步骤之前,还包括对所述区域使用高斯算子进行去噪。
优选地,在进行人脸对齐之后还包括步骤:过滤劣质的人脸图片。
优选地,在步骤通过sobel算子对人脸区域提取sobel特征之前,还包括将原图中的人脸框中心向外扩充,以将人脸框扩大。
优选地,对于每一张输入的图像a,gx和gy分别与图像a做卷积得到
优选地,通过多任务级联卷积神经网络来检测得到人脸框以及人脸关键点的坐标。
另一方面,本发明还提出一种人脸活体检测系统,包括:
人脸检测模块:通过人脸检测得到人脸框以及人脸关键点的坐标,并通过人脸关键点的坐标进行人脸对齐;
人脸追踪模块:使用人脸追踪技术关联连续视频帧中相同的人脸id;
图获取模块:将人脸从原图中截取出,将rgb通道转换为hsv以及ycbcr空间,并将转换后的hsv和ycbcr图进行叠加,获得叠加图;通过sobel算子对人脸区域提取sobel特征,将获得的sobel特征图;
活体检测模块:将一人脸id预设帧数的所述sobel特征图及所述叠加图分别从双流神经网络的两个输入通道输入,获得每一帧图片的活体判断结果;
投票模块:将该人脸id的所有活体判断结果进行投票,当判断为活体的帧数多时,则认定对象为活体,判断为攻击的帧数多时,则认定对象为非活体。
又一方面,本发明提出了一种人脸活体检测设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述的人脸活体检测方法的步骤。
再一方面,本发明还提出一种人脸活体检测的可读存储介质,其上存储有计算机程序,其特征在于:该计算机程序被处理器执行时间实现上述的人脸活体检测方法的步骤。
采用上述技术方案,将人脸从原图中截取出,将rgb通道转换为hsv以及ycbcr空间,并将转换后的hsv和ycbcr图进行叠加,获得叠加图;通过sobel算子对人脸区域提取sobel特征,将获得的sobel特征图;将一人脸id预设帧数的所述sobel特征图及所述叠加图分别从双流神经网络的两个输入通道输入,获得每一帧图片的活体判断结果,完成对一人脸id进行活体检测;本专利通过基于单目相机实现活体检测,无需额外的设备,成本低,适用范围广;加入了除人脸以外的特征,提高了模型的鲁棒性;基于多相机采集的大量数据和深度学习的方法,克服了传统单目活体方法不适用于不同相机和场景的问题;采用人脸优选和多帧投票策略,提高了实际应用时算法的稳定性。此外,整个活体判断过程无需用户配合,且速度较快,能给用户带来较好的体验感。
附图说明
图1为本发明人脸活体检测方法一实施例的步骤流程图;
图2为本发明人脸活体检测方法一实施例的sobel算子的x方向的卷积核;
图3为本发明人脸活体检测方法一实施例的sobel算子的y方向的卷积核。
具体实施方式
下面结合附图对本发明的具体实施方式作进一步说明。在此需要说明的是,对于这些实施方式的说明用于帮助理解本发明,但并不构成对本发明的限定。此外,下面所描述的本发明各个实施方式中所涉及的技术特征只要彼此之间未构成冲突就可以相互组合。
参照图1,本发明提出一种人脸活体检测方法,包括步骤:
通过人脸检测得到人脸框以及人脸关键点的坐标,并通过人脸关键点的坐标进行人脸对齐,过滤劣质的人脸图片。;
使用人脸追踪技术关联连续视频帧中相同的人脸id;
将人脸从原图中截取出,将rgb通道转换为hsv以及ycbcr空间,并将转换后的hsv和ycbcr图进行叠加,获得叠加图;对区域使用高斯算子进行去噪。将原图中的人脸框中心向外扩充,以将人脸框扩大。通过sobel算子对人脸区域提取sobel特征,将获得的sobel特征图;
将一人脸id预设帧数的sobel特征图及叠加图分别从双流神经网络的两个输入通道输入,获得每一帧图片的活体判断结果;
将该人脸id的所有活体判断结果进行投票,当判断为活体的帧数多时,则认定对象为活体,判断为攻击的帧数多时,则认定对象为非活体。
具体地,将人脸框面积大于图片的预设比例的图片以及人脸长宽小于预设大小的图片删除。
具体地,对于每一张输入的图像a,gx和gy分别与图像a做卷积得到
具体地,通过多任务级联卷积神经网络来检测得到人脸框以及人脸关键点的坐标。
采用上述技术方案,将人脸从原图中截取出,将rgb通道转换为hsv以及ycbcr空间,并将转换后的hsv和ycbcr图进行叠加,获得叠加图;通过sobel算子对人脸区域提取sobel特征,将获得的sobel特征图;将一人脸id预设帧数的sobel特征图及叠加图分别从双流神经网络的两个输入通道输入,获得每一帧图片的活体判断结果,完成对一人脸id进行活体检测;本专利通过基于单目相机实现活体检测,无需额外的设备,成本低,适用范围广;加入了除人脸以外的特征,提高了模型的鲁棒性;基于多相机采集的大量数据和深度学习的方法,克服了传统单目活体方法不适用于不同相机和场景的问题;采用人脸优选和多帧投票策略,提高了实际应用时算法的稳定性。此外,整个活体判断过程无需用户配合,且速度较快,能给用户带来较好的体验感。
本发明的另一实施例中,活体检测的步骤为:
s1:人脸框检测
本发明使用mtcnn进行人脸检测得到人脸框的坐标位置以及5点人脸关键点,其中人脸框坐标用来过滤人脸框面积大于全图1/3或人脸长宽小于200pixel的人脸,5点人脸关键点用来将人脸对齐到固定的模板上得到对齐人脸图像。
s2:人脸图像优选
本步骤采用人脸优选算法过滤极端情况(过曝、人脸角度过大等)下的人脸,并使用人脸追踪技术关联连续视频帧中相同的人脸id,保证每个视频中单独的人脸id只进行一定最优帧的活体判断。
s3:活体检测方法
s31:对于s1检测到的人脸,通过s2的人脸优选后,在原图中截取出来,从rgb通道转换为hsv以及ycbcr空间,并将转换后的hsv和ycbcr图进行叠加,作为双流网络的第一个输入。
s32:以s1检测到的人脸框中心,向外将人脸框扩大为原本的1.5倍,对该区域用gaussian算子进行去噪后,使用sobel算子对该区域提取sobel特征得到特征图。sobel算子的卷积核如图2图3所示。
其中gx表示x方向的卷积核,gy表示y方向的卷积核。对于每一张输入的图像a,gx和gy分别与图像a做卷积得到agx,agy,之后输出图像ag的每一个像素的值为:
s33:将s2优选出的同一个id的多张(本发明取5张)符合要求的图片输入s32学习好的深度学习网络,将判断结果进行多帧投票,当判断为活体的帧数多时,则认定对象为活体;判断为攻击的帧数多时,则认定对象为非活体。
本发明实施例中,对图片进行活体判断的深度学习网络使用resnet(残差网络)作为基础网络的双输入通道,两个输入分支在分别进行特征提取后,通过se-module对两个分支提取出的特征进行选择性激发融合,再经过数层卷积对融合后的特征进行特征提取,获得活体判断结果。深度学习网络的目标函数为focal损失函数。
需要说明的是,resnet(残差网络)是由来自microsoftresearch的4位学者提出的卷积神经网络,在2015年的imagenet大规模视觉识别竞赛中获得了图像分类和物体识别的优胜。残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率。其内部的残差块使用了跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题。
另一方面,本发明还提出一种人脸活体检测系统,包括:
人脸检测模块:通过人脸检测得到人脸框以及人脸关键点的坐标,并通过人脸关键点的坐标进行人脸对齐;
人脸追踪模块:使用人脸追踪技术关联连续视频帧中相同的人脸id;
图获取模块:将人脸从原图中截取出,将rgb通道转换为hsv以及ycbcr空间,并将转换后的hsv和ycbcr图进行叠加,获得叠加图;通过sobel算子对人脸区域提取sobel特征,将获得的sobel特征图;
活体检测模块:将一人脸id预设帧数的sobel特征图及叠加图分别从双流神经网络的两个输入通道输入,获得每一帧图片的活体判断结果;
投票模块:将该人脸id的所有活体判断结果进行投票,当判断为活体的帧数多时,则认定对象为活体,判断为攻击的帧数多时,则认定对象为非活体。
又一方面,本发明提出了一种人脸活体检测设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行程序时实现上述的人脸活体检测方法的步骤。
再一方面,本发明还提出一种人脸活体检测的可读存储介质,其上存储有计算机程序,其特征在于:该计算机程序被处理器执行时间实现上述的人脸活体检测方法的步骤。
本系统通过人脸检测和图像优选模块,过滤一些质量比较差的人脸,例如遮挡,头部姿态角度过大,之后提取人脸周边一定范围内的sobel特征,融合人脸区域的图像,作为网络的输入,使用改进后的双流resnet网络进行学习,基于大量高质量数据进行学习得到高鲁棒性的特征,能有效的抵抗常见的攻击手段。整个活体判断过程无需用户配合,且速度较快,能给用户带来较好的体验感,鲁棒性较强。
以上结合附图对本发明的实施方式作了详细说明,但本发明不限于所描述的实施方式。对于本领域的技术人员而言,在不脱离本发明原理和精神的情况下,对这些实施方式进行多种变化、修改、替换和变型,仍落入本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!