用于资源控制的设备、程序和方法与流程
1.本发明在于资源控制和资源管理的领域。特别地,实施例涉及有限资源到在物理环境(诸如电信网络)中的动态改变的任务集合的指派。
背景技术:
2.典型的电信网络包括诸如基站节点、核心网络组件、网关等之类的大量互连的元件。在此类系统中,在它的各种软件和硬件组件中有失灵(malfunctions)是自然的。通过事件或工单(ticket)来报告这些。网络维护团队需要有效地解决它们以拥有健康的电信网络。通常,这些维护团队需要最优规则来将诸如人、工具、装备等的可用固定资产/资源指派到未解决(活动/未决(pending))的工单。系统中活动工单的数量正在动态地改变,因为一些工单在它们被解决时离开系统,并且新工单由于网络中的新事件或失灵而进入系统。这使找到最优规则以将固定资产分配到活动工单是困难的。
3.尽管存在基于最优计划将资源指派到工单的现有方法,但是这经常仅相对于手头的当前工单来完成,并且指派不注意此类指派对系统的长期影响。例如,现有途径是要将资产手动映射到工单。无论何时工单到达网络操作中心noc,noc管理员都从那些可用的资产中指派所需的资产,目的是尽可能快地解决工单。虽然这种途径可以有效地处理当前在系统中的工单,但是在适当的时候,对资产利用的贪婪/自私途径将开始耗尽(draining)资产,并且促使将来工单具有更长的解决时间(因为由将来工单所需的资产被最近到达的工单占用)。
4.资产到资源的指派的问题在以下中讨论:ralph neuneier, "enhancing q
‑
learning for optimal asset allocation", nips 1997:936
‑
942 url:https://pdfs.semanticscholar.org/948d/17bcd496a81da630aa947a83e6c01fe7040c.pdf;以及enguerrand horel, rahul sarkar, victor storchan, "final report: dynamic asset allocation using reinforcement learning", 2016 url:https://cap.stanford.edu/profiles/cwmdfid=69080&cwmid=6175。
5.上面公开的途径不能被应用于物理环境中动态改变的任务场景。
6.提供用于在动态物理环境中控制资源到未决任务的指派的技术是可期望的,该技术至少部分地克服了在单独基础上按到达顺序处理每个未决任务的限制。
技术实现要素:
7.实施例包括一种设备,所述设备包括处理器电路和存储器电路,存储器电路存储处理指令,所述处理指令在由处理器电路执行时,促使处理器电路:在有限时间段结束时,执行来自用于执行物理环境中的任务的有限资源集的资源到未决任务的指派,包括制定指派,其中制定指派包括:使用强化学习算法来制定优化奖励函数值的映射,奖励函数值是由预定奖励函数基于表示资源的清单(inventory)和未决任务的表示以及映射而生成的值,映射是来自清单的单独资源到表示中的单独未决任务的映射,所制定的指派是根据所制定
的映射的。
8.资源集还可以被称为资产集合或固定资产集合。资源的有限性质指示资源到未决任务的指派负面影响用于其它未决任务的资源的可用性。在无限资源的情况下,相同情况并非如此。
9.有限时间段可以是有限时间片段(temporal episode)、预定时间窗口、固定周期或预定频率。例如,从预定开始点运行到预定终点。时间段可以被认为在含义上与时间窗口或时间片段或时间时段等同。有限时间段可以是一系列连续有限时间段中的一个。
10.简单地增加资产的数量可能不是可能的或可行的,因此实施例提供了用于实现有效使用固定量的资源的技术。实施例提供了通过使用强化学习算法来制定映射以利用所需的最少资产来解决尽可能多的工单来指派和处置可用资产/资源的有效机制。
11.有利地,实施例等待直到时间段结束为止,并且共同地处理在片段结束时资源到的全部未决任务的映射。以这种方式,共同地实现了同情未决任务的群组的指派,而不是简单地单独实现对每个未决任务的最佳解决方案。
12.强化学习算法可以分别基于任务和资源的特性之间的关联来操作。例如,对于任务集合的每个成员,任务集合的表示可以包括一个或多个任务特性。对于清单中表示的每个资源,清单可以包括一个或多个资源特性。强化学习算法被配置成学习并存储任务特性与资源特性之间的关联;并且制定映射包括将来自清单的单独资源到表示中的单独未决任务的映射约束到资源具有与所存储的关联中的相应的单独未决任务的任务特性相关联的资源特性。
13.有利地,所存储的关联提供了机制,通过所述机制,强化学习算法可以制定用于利用奖励函数来评估的潜在映射。
14.此外,强化学习算法可以被配置成响应于具有资源特性并且已经被指派到具有任务特性的任务的资源已经成功地执行任务的通知,来学习并存储任务特性和资源特性之间的关联。
15.有利地,强化学习算法接收关于过去指派的反馈,以便通知并临时提供(improvise)将来指派。
16.特别地,强化学习算法可以被配置成响应于表示资源到任务的历史指派的结果的信息以及相应的资源特性和任务特性,来学习并存储任务特性和资源特性之间的关联,其中所存储的关联包括关联强度的定量评估,响应于指示具有特定资源特性的资源到具有特定任务特性的任务的指派的肯定结果的信息,来增加特定资源特性和特定任务特性之间的定量评估。
17.有利地,此类定量评估可以提供手段,通过所述手段在存在有多个可行映射的情况下在多个候选映射之间进行选择。
18.作为用于对任务和资源之间的关联强度进行定量的另外的技术,可以是响应于指示具有特定资源特性的资源到具有特定任务特性的任务的指派的负面结果的信息,来减少特定资源特性和特定任务特性之间的定量评估。
19.实施例利用奖励函数来评估潜在映射,并且在数据空间中配置和制定映射以在物理环境中实现为指派。预定奖励函数是从所制定的映射得到的因子的函数,因子包括来自以下当中的一个或多个:预测完成的任务的数量、完成所述数量的任务的累积时间等。
20.实施例可以利用奖励函数来将与使用特定资源关联的消耗开销(诸如成本或co2排放)作为因子记入(factor)。例如,资源可以包括通过执行任务而消耗的一个或多个资源,清单包括资源的消耗开销的指示,在这种情况下,奖励函数因子可以包括:所映射的资源的预测的累积消耗开销。
21.可以包括在奖励函数中的另外的因子的示例包括有限资源集的使用率,在奖励函数值优化和使用率之间存在负相关。
22.实施例可应用在一系列实现中。例如,物理环境可以是物理设备并且每个未决任务是物理设备中的技术故障,并且未决任务的表示是每个技术故障的相应的故障报告;并且用于执行任务的资源是用于解决技术故障的故障解决资源。
23.特别地,可以的是,物理设备是电信网络。
24.可以通过事件或工单来报告典型电信网络中的失灵。需要通过在短时间量内最优地利用可用资产来解决这些工单。系统中活动工单的数量正在动态地改变,因为一些工单在其被解决时离开系统,并且新工单由于网络中的失灵而进入系统。工单是未决任务的表示。常规方法手动地或通过使用简单规则将资源分配到工单,所述简单规则仅考虑手头的当前工单,并且不注意此类选择对资产利用的长期影响、对工单解决时间的共同统计等。实施例利用基于评价性反馈的学习系统来解决此类缺点。实施例提供了具有状态(资源的表示和清单)、动作(映射和指派)和奖励(奖励函数)空间的策略的强化学习框架,以将可用资源分配到公开工单,同时抑制资源利用率以便保持资源可用于将来指派。
25.实施例还可以包括接口电路,接口电路被配置成通过将所制定的映射传递到资源集,根据所制定的映射来指派资源。
26.实施例包括一种计算机实现的方法,包括:在有限时间段结束时,执行来自用于执行物理环境中的任务的有限资源集的资源到未决任务的指派,包括制定指派,其中制定指派包括:使用强化学习算法来制定优化奖励函数值的映射,奖励函数值是由预定奖励函数基于表示资源的清单和未决任务的表示以及映射而生成的值,映射是来自清单的单独资源到表示中的单独未决任务的映射,所制定的指派是根据所制定的映射的。
27.实施例还包括一种计算机程序,所述计算机程序当由具有处理器硬件的计算装置执行时,促使处理器硬件执行方法,所述方法包括:在有限时间段结束时,执行来自用于执行物理环境中的任务的有限资源集的资源到未决任务的指派,包括制定指派,其中制定指派包括:使用强化学习算法来制定优化奖励函数值的映射,奖励函数值是由预定奖励函数基于表示资源的清单和未决任务的表示以及映射而生成的值,映射是来自清单的单独资源到表示中的单独未决任务的映射,所制定的指派是根据所制定的映射的。
附图说明
28.现在将参照附图仅通过示例的方式描述实施例,在所述附图中:图1示出了实施例的过程中的逻辑步骤的流程;图2示出了实施例的设备;图3示出了实施例的设备;以及图4示出了实施例的实现。
具体实施方式
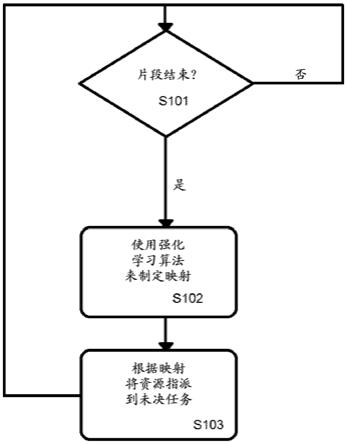
29.图1示出了实施例的过程中的逻辑步骤的流程。例如,过程可以是实施例本身,或者可以由实施例执行。
30.步骤s101到s103表示将来自用于执行物理环境中的任务的有限资源集中的资源指派到未决任务(包括制定指派)的过程。
31.过程定义了循环,使得它可以被连续地执行。可以是在s101的后续实例之间实现默认的固定时间步长(time step)。例如,时间步长可以是与片段的长度的固定关系,例如是0.1x、0.5x或1x片段的长度。或者时间步长可以是固定的时间长度,诸如1分钟、10分钟、30分钟或1小时。
32.实施例不直接响应于任务变得未决(即,到达或被报告)而将资源指派到新的未决任务。相反,实施例至少等待直到片段结束为止,在此期间新的未决任务变得未决,以将资源指派到任务。任务变得未决的时间可以是向实施例报告任务的时间,或者实施例以其它方式变得知道未决任务的时间。
33.步骤s101检查是否已经达到片段的结束(即,预定时间段的结束)。例如,步骤s101可以包括在执行图1的过程中涉及的处理器硬件,从而执行对操作系统、系统时钟或提供实时数据的外部应用的调用,以检查当前时间是否匹配当前片段被调度至结束的时间。备选地,可以是在每个时段结束时启动定时器,所述定时器使用系统时钟以跟踪自先前时段结束以来的时间,以及当自先前时段结束以来所经过的时间等于片段的持续时间时,流程继续到步骤s102,并且定时器重置成0并重新启动。
34.在s102,在可用资源的表示和未决任务的表示之间制定映射。例如,步骤102可以包括使用强化学习算法来制定优化奖励函数值的映射,奖励函数值是由预定奖励函数基于表示资源的清单和未决任务的表示以及映射而生成的值,映射是来自清单的单独资源到表示中的单独未决任务的映射。
35.映射是在逻辑层上,并且可以是数据处理步骤。资源是用于执行任务的有限资源,诸如人工资源和硬件。资源的数据表示可以被称为清单。清单是资源的数据中的记录并且可以包括诸如调度信息之类的资源的可用性的指示,或者简单地是指示资源是可用或不可用的标志。换言之,清单可以是存储器或数据存储中的资源的表现。清单是动态的、正在改变以表示来自以下当中的一个或多个:资源的可用性的改变、资源的特性的改变、添加到资源集或从资源集移除的资源。未决任务是物理环境中需要修复的故障,或者是物理环境中的某一其它形式的任务。未决任务的表示也是动态的、随着未决任务被实施例接收或以其它方式被通知给实施例而正在改变、以及正在改变以表示由于任务正在被执行或完成而不再未决的任务。
36.映射将未决任务的数据表示链接到资源的数据表示。特别地,通过使用强化学习算法来制定映射以优化奖励函数值。可以通过对包括清单的当前版本和未决任务的当前表示的输入数据执行算法来制定映射,其中当前可以被认为是在最近完成的片段的结束时。
37.对于任务集合的每个成员,任务集合的表示可以包括一个或多个任务特性。例如,任务特性可以定义来自以下当中的一个或多个:预期任务完成所花费的时间长度、任务将要完成的时间、任务的描述符、任务id、完成任务所需的资源的指示、完成任务所需的资源特性的指示、成本上限(ceiling)或成本范围(其中本文档中任何地方的成本可以指财务、
性能或co2排放)以及任务的地理位置。
38.对于清单中表示的每个资源,清单可以包括一个或多个资源特性。例如,资源特性可以包括来自以下当中的一个或多个:资源成本、资源可用性、资源id、资源类型、资源可以完成的(一种或多种)类型任务的(一个或多个)任务、地理位置、地理范围。
39.强化学习算法可以被配置成学习并存储任务特性和资源特性之间的关联,使得制定映射包括将来自清单的单独资源到表示中的单独未决任务的映射约束到资源具有与所存储的关联中的相应的单独未决任务的任务特性相关联的资源特性。强化学习算法可以通过监测资源到任务的过去的指派和那些指派的结果来学习关联。例如,强化学习算法被配置成响应于具有资源特性并且已经被指派到具有任务特性的任务的资源已经成功地执行任务的通知,来学习并存储任务特性和资源特性之间的关联。例如,关联可以被加权,其中权重通过引起任务被完成的指派而递增或者通过引起未完成的任务的指派而递减。可选地,递增和/或递减可以与所花费的时间成反比。
40.映射找到将优化奖励函数的资源到未决任务的指派。奖励函数生成表示所制定的映射的奖励函数值,其中映射本身是影响奖励函数值的变量或因子。强化学习算法负责根据未决任务的表示和清单来找到将生成最优的(即,取决于函数的配置的最高或最低的)奖励函数值的资源到未决任务的映射。
41.强化学习算法可以在反馈回路中,其中将关于所实现的指派的信息(诸如完成指派内的每个未决任务的时间、任务完成率、实现的成本、实现的co2成本等等)反馈回算法。反馈算法可以被强化学习算法用来配置奖励函数和/或预测影响奖励函数值的奖励函数的因子。
42.预定奖励函数相对于其针对特定片段的执行而被预定(即,在片段完成时固定奖励函数),但是奖励函数可以例如响应于观察到的指派结果而在执行之间是可配置的。预定奖励函数是在制定映射中强化学习算法将值所归属到的因子的函数,值被组合以生成奖励函数值。强化学习算法在制定优化奖励函数值的映射中可以执行重复地调整映射并且针对调整的映射评估奖励函数值的迭代过程。
43.强化学习算法还可以被配置成在训练或观察阶段期间调整奖励函数,使得在训练/观察阶段期间观察到的并且导致有益结果(即,资源的低成本、有效使用)的指派相对导致不良结果(即,资源的高成本、无效使用)的指派有利。强化学习算法可以被配置成响应于表示资源到任务的历史指派的结果的信息以及相应的资源特性和任务特性,来学习并存储任务特性和资源特性之间的关联。所存储的关联包括关联的定量评估,响应于指示具有特定资源特性的资源到具有特定任务特性的任务的指派的肯定结果的信息,来增加定量特定资源特性与特定任务特性之间的定量评估。响应于指示具有特定资源特性的资源到具有特定任务特性的任务的指派的负面结果的信息,来减少特定资源特性和特定任务特性之间的定量评估。
44.以抑制资源使用的方式来指派资源可能是可期望的。这通过包括资源的使用率作为预定奖励函数的因子的实施例能够实现。奖励函数值优化与使用率之间存在负相关,使得奖励函数倾向于针对较低的资源使用率而被优化。
45.映射可以是以调度的形式,所述调度指示哪些资源被指派到哪些未决任务以及何时被指派到哪些未决任务,其中何时被指派到哪些未决任务可以被指示为绝对时间或指示
为与另一未决任务有关的定时(例如,资源b被指派到任务1,并且在任务1完成之后,资源b被指派到任务2)。
46.一旦制定了映射,则在s103处根据映射将资源指派到未决任务。映射的制定在s102处是数据处理操作。资源到任务的指派与物理环境中资源本身到未决任务的指派有关。指派可以通过发布调度、通过向资源发出指令或命令来实现,并且可以包括传送到未决任务要被执行的位置或者以其它方式将资源移动到未决任务要被执行的位置。
47.资源全部或部分地由有限资源组成。有限资源是不能简单地按需复制而没有限制的资源。也就是说,其资源存在有限的数量或量。资源可以包括对数量或复制没有实际限制(资源的示例可以是访问安全存储装置所需的密码,或者另外的示例是电子指令手册)的无限资源。有限资源可以包括例如执行未决任务所需的计算机软件的许可证,其中指派包括使软件许可证可用于执行相应的未决任务的用户或实体。
48.图2示出了实施例的设备10。设备10包括存储器电路12、处理电路14和接口电路16。在其中未决任务110要被执行的物理环境100中,存在资源集120。资源集120和存储器电路之间的链路指示出某一链路,通过该链路将资源120到任务110的指派传递到资源120。然而,它不排除物理环境100与设备10之间的其它逻辑与通信链路。
49.例如,在从计算机程序接收到合适的指令时,设备10可以执行图1的方法的步骤中的一些或全部。设备10可以例如位于核心网络、基站或其它无线电接入节点的服务器、或连接到核心网络、基站或其它无线电接入节点、或者位于运行执行图1的方法的步骤的一个或多个虚拟机的数据中心中的服务器。参考图3,设备10包括处理器或处理电路14、存储器12和接口16。存储器12包含由处理器14可执行的指令,使得设备10可操作来进行图1的方法的步骤中的一些或全部。指令还可以包括用于执行一个或多个电信和/或数据通信协议的指令。指令可以以计算机程序的形式被存储在存储器12上,或者以其它方式可访问处理器14。在一些示例中,处理器或处理电路14可以包括一个或多个微处理器或微控制器,以及可以包括数字信号处理器(dsp)、专用数字逻辑等的其它数字硬件。可以由任何类型的集成电路(诸如专用集成电路(asic)、现场可编程门阵列(fpga)等)实现处理器或处理电路14。存储器12可以包括适合用于处理器的一种或若干类型的存储器,诸如只读存储器(rom)、随机存取存储器、高速缓冲存储器、闪速存储器装置、光存储装置、固态盘、硬盘驱动器等。
50.物理环境100是未决任务110要在其中被执行的环境。例如,物理环境100可以是电信网络,并且未决任务可以是要补救的故障。资源集120是可以在执行任务中使用的有限资源集。资源是有限的,因此通过资源120到任务110的指派来改变集合,因为至少由于执行未决任务所花费的持续时间,可用于执行其它任务的该资源的数量或量减小。
51.设备10至少在维护未决任务110的表示(其是动态的,因为新任务变得未决并且现有未决任务完成)以及资源的表示(清单)以及它们用于被指派到未决任务并且执行未决任务的可用性方面维护物理环境100的状态的表示。表示可以由存储器电路12存储,并且可以通过经由接口电路16接收的信息更新。此类信息可以包括来自以下当中的一个或多个:新的未决任务的报告、指示先前未决任务的完成的信息、表示资源的可用性的信息、指示资源的地理位置的信息、表示正发起的未决任务的执行的信息。
52.使用强化学习算法来找到优化奖励函数值的映射,由设备10使用表示以制定资源到任务的映射,奖励函数基于包括来自以下当中的一个或多个的因子:将由映射完成的未
决任务的数量、任务完成的总时间或平均时间(或任务的累积未决时间)、净消耗资源和资源利用率。
53.所制定的映射是由设备10得出的映射,其优化了针对给定输入的奖励函数值,即在片段结束时物理环境中的未决任务的表示,以及在片段结束时物理环境中的资源的表示(清单)。
54.一旦已经制定了映射,则设备10执行资源120到任务110的指派。例如,指派可以经由接口电路16执行。接口电路可以是网络中经由网络与物理环境100中的资源120中的一个或多个资源通信的节点。可以由网络中的装置指令或由网络中的装置控制资源120。网络可以是例如计算机网络或电信网络。指派的形式可以正输出表示实现映射的指令集合或调度的数据,所述数据由资源集120可读取以实现映射/指派。
55.图3示出了设备310的另一示例,其也可以位于核心网络、基站或其它无线电接入节点的服务器、或连接到核心网络、基站或其它无线电接入节点、或者位于运行执行图1的方法的步骤的一个或多个虚拟机的数据中心中的服务器。参考图3,设备310包括多个功能模块,所述多个功能模块可以在例如从计算机程序接收到合适的指令时执行图1的方法的步骤。可以采用硬件和/或软件的任何适当组合来实现设备310的功能模块。模块可以包括一个或多个处理器,并且可以被集成到任何程度。设备310用于执行来自用于执行物理环境中的任务的有限资源集的资源到未决任务的指派,包括制定指派。参考图3,设备310包括控制器或控制器模块3101,以用于确定有限时间段何时完成,并且用于获得输入数据,从而包括物理环境中的未决任务的数据表示和用于执行物理环境中的任务的资源的数据表示。设备310还包括用于使用强化学习算法来制定优化奖励函数值的映射的映射器或映射模块3102,奖励函数值是由预定奖励函数基于表示资源的清单和未决任务的表示以及映射而生成的值,映射是来自清单的单独资源到表示中的单独未决任务的映射。设备310还包括指派器或指派模块3103,以用于例如通过指令或以其它方式输出调度,根据映射将资源指派到任务,所述调度实现或以其它方式表示到物理环境中的资源的所制定的映射。
56.如将在下面的实现示例中所展示的,实施例可以被应用于将资源指派到电信网络(作为物理环境的示例)中的故障。
57.实施例使用强化学习方法来制定固定资产(人、技能、工具、装备等)(资源的示范)到报告故障(未决任务表示的示范)的工单的映射。实施例提供或实现了对动态物理环境(由活动工单表示)起作用以选择动作(由资产到工单的映射来表示)以使长期奖励最大化的过程。动作是资产到技术故障的指派,并且由强化学习算法通过制定资产到工单的映射来优化的奖励函数来表示长期奖励。
58.图4示出了针对电信网络中的工单处置而实现的实施例。设备4010可以具有图2的设备10、图3的设备310或其组合的布置和功能性。设备4010执行图1中示出的方法的方法示范。指派4020是针对第i个时间段的资产到工单的指派,并且因此可以由a
i
指代。指派4020是由接口电路16向图2中的资源集120输出的指派的示范,诸如表示实现资源(资产)到任务(工单)的映射的指令集合或调度的数据。指派4020是图3的指派器3103的输出的示范。电信网络4100是图2的物理环境100的示范。环境4110中的任务的表示是在本文档的其它地方被提及的未决任务的表示的示范。环境4110中的任务的表示可以被称为环境的状态。环境4110中的任务的表示可以是在时间段结束时未决任务的表示。特定地,在第i个片段结束时
outage)。来自监测指示相同类型及其结果的先前工单的强化学习算法知道达到解决的最小资产集合是例如x资产。x资产可以包括人力和/或装备,并且这些资源的使用表示成本(财务或在例如co2排放方面)。例如,考虑在其中没有实现实施例(但是出于比较性的目的提供以帮助理解)的场景,并且一旦接收到工单,则要求现场服务工程师去到场地并修复故障,并且然后在接收到另一工单的时间(这也要求工程师去到并进行场地修复),并且新的场地位置非常接近第一场地所在的位置,还将相同人员派遣到新的场地而也不是派遣新服务工程师去到那里将会是有好处的。在解决第二工单中可能存在延迟,但是如果仅存在两个工程师(资产)可用于监视网络,则在要求他们去到离这两个场地非常远的场地的情况下保留第二工程师以防另一场地断电发生可以是优选的。在缺少该实施例的情况下,在比较性示例中,以仅考虑最近到达的工单的需要的方式,在每个工单一到达就处理每个工单将已经导致将两个工程师都派遣到类似的场地,这可能已经非常快地解决了两个工单,但是潜在的第三工单解决将被严重延迟。在相同情况下实现的实施例通过等待片段的结束并且然后不仅仅关注每工单的局部最优解决方案而是关注对片段的全局最优解决方案来引起更有效的总体资源使用。强化学习算法通过观察图案(pattern)来学习如何使用资产以用于全局最优奖励,并且随时间学习对于未决任务的给定组合和可用于执行任务的资源的给定组合的最佳指派图案(即,映射)。
65.为了解释实施例的效果,将提供在其中没有实现实施例的比较性示例。
66.在其中没有应用实施例的比较性示例中,考虑以下工单在给定定时到达:
任务id到达时间花费的时间(以小时为单位)tt类型指派的资源t100:002所要求的密码重置a1t200:104硬件替换排队t300:451断电排队
在先到来先服务(first
‑
come
‑
first
‑
served)的基础上,当相应的工单(表示任务)到达系统时,资产被指派到未决任务。如果用于完成新的未决任务所需的资产被先前的任务锁定,则用于新未决任务的工单被简单地排队并等待直到所需的资产的释放为止。
67.下面提供了可用用于到未决任务的指派的资源的清单:资产储存库信息
根据比较性示例中的先到来先服务的资产映射系统,6小时之后的工单解决的总体周转(turnover)将仅为1。当创建工单时,由于资源a1具有所需的技能集合,所以资源a1被指派到任务。然而,这具有以下结果:对于接下来的2小时,a1被锁定在任务上,并且因此当创建下一工单集合时,a1是不可用的。同样地,在t1完成之后,立即将a1指派到由t2表示的任务,并且因此当t3到达时,a1是不可用的。t1在02:00完成(t
n1 = 2:00);t2在06:00完成(t
n2 = 5:50);并且t3在07:00完成(t
n3 = 6:15),因此t
n = 02:00 + 05:50 + 06:15 = 14:05。
68.现在将呈现对相同工单/任务集合的实施例的实现。考虑按小时的片段,整点开始(以便t1在片段00:00至01:00到达)。一般地,在片段i结束时,物理环境由未决任务集合表示,并且基于未决任务的表示、资源的表示(即,清单)和奖励函数,强化学习算法将制定指派。
69.这里的奖励函数是,其中n
i = 3。由于n
i
是常数,所以通过min()和优化使用率c
i
来最大化奖励函数。
70.设备4010等待直到片段在0100结束为止,以执行指派。在01:00,任务指派如下:
任务id到达时间花费的时间(以小时为单位)tt类型指派的资源t100:002所要求的密码重置a2t200:104硬件替换a1t300:451断电排队的(a1)
在05:10,状态是:
任务id到达时间花费的时间(以小时为单位)tt类型状态t100:002所要求的密码重置在01:00+2:00=03:00完成(a2)t200:104硬件替换在01:00+4:00=05:00完成(a1)t300:451断电在01:00+1:00=02:00完成(a1)
6小时后,所解决的工单的数量的运转(turn around)将会是3。这样,系统学习将特定资源分配到任务以实现最高工单解决的最佳可能结果。t1在03:00完成(t
n1 = 3:00);t2在05:00完成(t
n2 = 4:50);并且t3在02:00完成(t
n3 = 1:15),因此t
n = 03:00 + 04:50 + 01:15 = 8:05。
71.强化学习算法经由从物理环境中的资源反馈回设备的信息来制定指派并监测结果。强化学习算法随时间学习物理环境中不同类型的未决任务所需要的资产的集合或种类。这种学习来自以某种形式在工单描述中的任务的表示,以及解决任务所需的(一个或多个)资产和所花费的时间。强化学习算法存储任务特性和资源特性之间的关联,并且基于历史指派的结果来调整关联,以利用关联以用于将资产指派到新工单。因此,当在片段结束时工单被包括在未决任务的表示中并且强化学习算法识别之前在(一个或多个)资产曾被指派到的历史工单中已经存在的任务特性和报告的结果(并且被用来记录或修改资产和任务之间的关联或其特性)时,强化学习算法在制定映射中利用存储的关联。强化学习算法可以使用关联,使得分配用于特定工单的资源将不过剩并且可以用于将来传入工单的解决(即,通过支持适合用于任务的资产并且其具有与其它任务特性的更少关联)。换言之,强化学习算法可以被配置成支持资源到任务的映射,其中资源具有与未决任务(或其特性)的存储的关联,并且所述未决任务(或其特性)与具有与更多数量的任务特性相关联的未决任务(或
其特性)的资源相比,与更少的任务特性相关联。
72.因此,基于强化学习算法有助于提升资产到所引起工单的有效分配,并且在选择针对将来的工单保留资产的指派中变得有效。
73.管理的服务设置中的主要任务中的一个是清单管理。特定挑战是需求预报。在任何时间,有益的是,在清单中具有可用用于将来未决任务的资源而不是在任何一个时间利用全部资源。如果清单中要求任何资源,必须提前通知好供应商以供应所述资源。强化学习算法可以使用未决任务到达类型和时间的历史图案来预测特定类型的未决任务将何时到达,并且因此可以在映射中对这些预测进行考虑。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1