使用一个或更多个神经网络的流体模拟的制作方法
使用一个或更多个神经网络的流体模拟
背景技术:
1.流体模拟是计算机图形学、应用数学和其他领域的一个长期存在的问题。使用传统技术来计算高分辨率流体模拟具有挑战性,因为流体模拟需要大量的计算资源来计算具有大量水粒子的场景,诸如具有河流或水体的场景。主要的计算瓶颈与足够小以提供稳定性的时间步长有关。使用传统技术进行流体模拟的模拟时间可能在数小时到数天的范围内,因此可能无法实时实现高分辨率的流体模拟。因此,使用传统技术计算高分辨率流体模拟对于某些用例可能不切实际,诸如计算机模拟和视频游戏。
附图说明
2.将参考附图描述根据本公开的各个实施例,其中:
3.图1示出了根据各种实施例可以执行的用于计算机图形应用的流体模拟的示例。
4.图2示出了根据各种实施例可以利用的示例流体不可压缩性约束。
5.图3a示出了根据各种实施例可以利用的生成密度张量的示例方法。
6.图3b示出了根据各种实施例可以利用的示例刚体掩模张量。
7.图4示出了根据各种实施例可以利用的示例网络。
8.图5示出了根据各种实施例可以执行的示例内部深度至空间操作。
9.图6示出了根据各种实施例可以用于执行的模拟的第一示例过程。
10.图7示出了根据至少一个实施例的推理和/或训练逻辑;
11.图8示出了根据至少一个实施例的推理和/或训练逻辑;
12.图9示出了根据至少一个实施例的示例数据中心系统;
13.图10示出了根据至少一个实施例的计算机系统;
14.图11示出了根据至少一个实施例的计算机系统;
15.图12示出了根据至少一个实施例的计算机系统;
16.图13示出了根据至少一个实施例的计算机系统;以及
17.图14示出了根据至少一个实施例的计算机系统。
具体实施方式
18.在以下描述中,将描述各个实施例。为了说明的目的,阐述了具体的配置和细节以便提供对实施例的透彻理解。然而,对于本领域的技术人员来说显而易见的是,可以在没有具体细节的情况下实践实施例。此外,可以省略或简化众所周知的特征,以免使所描述的实施例不清楚。
19.如上所述,由于实时高分辨率流体模拟所需的时间步长造成的计算瓶颈,流体模拟是计算机图形学、应用数学和其他领域长期存在的问题。流体模拟的传统方法包括欧拉计算范式(基于网格)和拉格朗日计算范式(基于粒子)。使用欧拉计算范式执行流体模拟的方法使用规则网格上的标量和矢量物理场,并通过求解压力、粘度、表面张力和不可压缩性的纳维-斯托克斯等式。使用拉格朗日计算范式执行的方法使用称为粒子的离散实体中已
知的量来近似纳维-斯托克斯等式中的连续量。
20.虽然在使用纳维-斯托克斯等式的流体模拟中可以强制不可压缩性,但是这些计算非常耗时,因此,在实时流体模拟中使用可能不切实际。因此,需要计算高分辨率流体模拟,在不求解纳维-斯托克斯等式的情况下强制执行流体的不可压缩性。
21.根据各种实施例的方法提供的流体模拟,与传统方法相比,显著减少了时间和存储器需求。特别地,各种实施例为包含在粒子域的给定子域中的大量粒子生成密度张量和刚体图张量。密度张量可以以多种不同的格式表示,并且可以包括体素。刚体图张量可以表示为在模拟场景中特定帧期间密度张量中哪些体素被刚体覆盖的二进制确定。总的来说,刚体图张量可以表示具有三个空间维度的网络(例如,经过训练的神经网络)的输入信道。网络可以对输入信道应用一系列操作(例如,卷积、扩张卷积、三维像素混洗等),以预测帧末尾处每个粒子的更新位置和更新速度。与求解纳维-斯托克斯等式的经典方法相比,这种方法可以在几乎无界的模拟域内处理数以千万计的粒子。在一些实施例中,可以使用基于位置的流体方法来收集数据,但是在各种实施例的范围内也可以使用其他解算器(solver)。
22.各种其他功能可以在各个实施例中实现,以及在本文其他地方讨论和建议。
23.如上所述,在各种情况下可能需要实时执行高分辨率流体模拟。例如,如图1的示例图像100所示,用于电影或视频游戏的计算机图形应用程序可能涉及显示对象102落入或移动穿过水体或盆地(basin)106。虽然在各种示例中使用了“盆地”,但应当理解,粒子域可以被划分为多个子域,对象可以通过这些子域移动。在至少一些实施例中,如本文别处更详细地讨论的,可以为各种实施例中的每个子域构建密度和刚体掩模,并且运行网络,并且这些任务不限于特定盆地。为了以逼真的方式模拟和渲染水的运动和位移,可以使用粒子模拟,其中水的“液滴”(droplets)被模拟为单个粒子104,并且粒子的行为由粒子模拟确定,所述粒子模拟可以考虑诸如位置、速度,以及各种粒子的不可压缩性。在许多情况下,模拟可以在一个或更多个处理器上执行,诸如一组图形处理单元(gpu)。如前所述,可以在gpu硬件上使用一种方法来执行高分辨率流体模拟,该方法在不求解纳维-斯托克斯等式的情况下强制流体不可压缩。所述模拟可能涉及几乎无限的模拟域内的数以千万计粒子。在一些实施例中,可以使用不可压缩性约束来对流体建模,该不可压缩性约束m指示当静止时(xi=0,vi=0),位于半径r内的粒子数不能大于m。如图2中的示例图像200所示,不可压缩性约束m是当静止时距任何一个粒子104的半径r内可以定位不超过10个粒子。然而,在不脱离本公开的范围的情况下,可以使用其他不可压缩性约束。
24.当流体被模拟为大量粒子时,每个粒子可能具有与其相关联的位置和速度向量。在一些实施例中,可以将流体模拟划分为一组步骤,这些步骤可以为正在渲染的场景的每一帧执行。可以执行该组步骤,以在帧的整个持续时间内更新每个粒子的位置和速度。在帧末端,更新后的位置和速度可用作后续帧期间粒子的初始位置和速度。下面结合图3a-6阐述与每个步骤相关联的细节。
25.在帧n的开始,一个或更多个处理器可以确定由被模拟的大量流体的流动引起的单个粒子104的运动,在一些实施例中也称为平流。如下所示,速度可以使用等式1为第n帧中的粒子i确定,并且粒子i在第n帧的位置可以使用等式2确定。如等式1所示,
在时间段δt内,速度可能等于第n帧开始时粒子i的初始速度加上外力(例如重力、粘度、表面张力、压力等的总和),其中时间段δt是一帧的持续时间。例如,如果场景以60帧/秒的速度运行,则时间段δt等于16.6毫秒。
26.如等式2所示,位置可能等于粒子i(例如,在帧n的开始处)的初始速度加上初始速度的平均值和时间段δt内的速度其中时间段δt是帧n的持续时间。一个或更多个处理器可以维护粒子位置表,该表将每个粒子104的速度和位置中的一个或更多个与帧n中的所有其他粒子104相关。一旦确定每个粒子的速度和位置一个或更多个处理器可以执行碰撞检测,如下面的等式3所示。在某些实现中,一个或更多个处理器可以通过使用例如有符号距离场(sdf)估计网格上的粘度和表面张力来执行碰撞检测。
[0027][0028][0029][0030]
为确定第n帧结束时粒子i的最终速度和最终位置(例如,这也是第n+1帧开始时粒子i的初始速度),一个或更多个处理器可以确定校正因子以便考虑在帧n期间作用在粒子104上的任何其他力。其他力可以包括例如落入盆地106的物体。例如,在帧n中,球开始落入盆地106并与一组粒子104碰撞。为了提供逼真的高分辨率流体模拟,一个或更多个处理器确定校正因子δ,以预测和显示由下落物体施加在一组粒子104上的力引起的水的运动。
[0031]
如下所示,可以使用等式4为第n帧中的粒子i确定最终速度并使用等式5确定第n帧中粒子i的最终位置如等式4所示,最终速度可等于帧n中粒子i的速度加上校正因子如等式5所示,在时间段δt内,粒子i在帧n末尾的最终位置可能等于位置加上修正因子其中时间段δt是帧n的持续时间。
[0032][0033][0034]
为了获得每个粒子104的校正因子δ,一个或更多个处理器可以生成密度张量和刚体掩模张量。密度张量和刚体掩模张量可以表示确定帧n中每个粒子104的校正因子δ的网络输入信道(例如,下面结合图04的)。
[0035]
例如,一个或更多个处理器可以在空间上将盆地106或盆地106中包含粒子104的区域划分为相等的体素302,如图3a中的示例图像300所示。在某些实现中,每个体素302可以是宽度、高度和深度等于上述关于不可压缩性约束m的半径r的立方体。一个或更多个处
理器可以将每个体素302中的粒子数量确定为普通和或加权和,其可至少部分地基于所确定的速度和位置以及不可压缩约束m。每个体素302中的粒子104的数量可以表示密度张量。
[0036]
在一些实施例中,一个或更多个处理器可以通过确定刚体306a、306b是否覆盖帧n中的任何体素302的中心点304来获得刚体掩模张量404,如图3b中的示例图像310所示。图3b中的示例图像310是图3a的示例图像300中y方向上体素302的最顶层俯视图。在具有中心点304的最顶层体素302之下的在y方向上共享中心点轴的所有体素302也可以被认为被刚体306a、306b覆盖,所述中心点304由刚体306a、306b覆盖。在一些实施例中,一个或更多个处理器可以通过将第一值(例如,1)分配给具有由刚体306a、306b覆盖的中心点304的每个体素302,并且通过将第二值(例如,0)分配给具有在帧n中仍然未被刚体306a、306b覆盖的中心点304的每个体素302,以获得刚体掩模张量。
[0037]
如上所述,密度张量402和刚体掩模张量404可以各自表示进入示例网络400的单个输入信道,如图4的示例图像所示。密度张量402中的每个体素可包含关于粒子104的密度、粒子104的位置或在帧n期间位于该体素内的粒子104的速度中的一个或更多个的信息。刚体掩模张量404可以用1或0来指定每个体素,以指示被刚体306a、306b覆盖的体素,如上文结合图3b所述。密度张量402和刚体掩模张量404可以沿x方向、y方向和z方向填充0,例如,以在应用卷积之后保持输出信道的相同尺寸。
[0038]
在图4所示的示例网络400中,一个或更多个处理器可以将一系列卷积406a、406b应用于密度张量402和刚体掩模张量404输入信道。卷积406a可以具有例如32个内核大小为3
×3×
3的滤波器,其输出具有32个信道的特征图408a。具有例如32个内核大小为3
×3×
3的滤波器的第二卷积406b可应用于特征图408a,其可输出具有32个信道的第二特征图408b。一个或更多个处理器可以将具有例如内核大小为3
×3×
3的32个滤波器的扩展卷积410应用于第二特征图408b,并输出具有32个信道的第三特征图408c。扩展卷积410可以提供网络400和包含在密度张量402和刚体掩模张量404中信息的增加的接受性视图。一个或更多个处理器可以应用另一个卷积406c,例如,具有32个内核滤波器3x3x3到第三特征图408c,并输出第四特征图408d。具有例如内核大小为1
×1×
1的32个信道的另一个卷积406d可以应用于第四特征图408d,并且输出具有32个信道的第五特征图408e。具有例如内核大小为1
×1×
1的24个信道的另一卷积406e可以应用于第五特征图408e,并输出具有24个信道的第六特征图408f。第六特征图408f可以具有dxhxwxc
·
r3的维度,其中d、h和w是空间维度,c是常数,并且r3是信道的数量。
[0039]
为了获得关于第六特征图408f中空间相邻信道的信息,一个或更多个处理器可以执行空间深度操作412,其中来自一个信道的信息与空间相邻信道相关,如图5的示例图像500所示。空间深度操作412可以产生具有维度rdxrhxrwxc的第七特征图414。一个或更多个处理器可以基于粒子位置图416和第七特征图414中的信息来执行最近预测池418。最近的预测池418可以输出具有针对帧n中的每个粒子104的校正因子δ的表420。
[0040]
在一些实施例中,一个或更多个处理器可以分别使用上面的等式4和5确定最终速度和最终位置以及表420中列出的校正因子δ。通过使用结合图4描述的网络从密度张量402和刚体掩模张量404提取信息信道,本公开的一个或更多个处理器可以执
行高分辨率流体模拟,而无需求解纳维-斯托克斯等式,因此可以实时使用。
[0041]
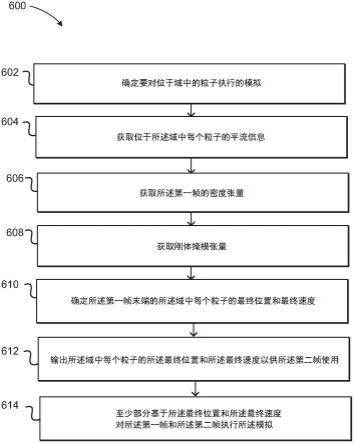
图6示出了根据各个实施例的用于训练可以使用的神经网络的示例过程600。应当理解,对于本文讨论的该过程和其他过程,除非另有说明,否则在各个实施例的范围内可以有以相似顺序或替代顺序或并行执行的附加、替代或更少的步骤。此外,尽管流体模拟被用作描述目的的主要用例,但各种其他模拟和应用可以利用如本文所讨论和建议的各种实施例的方面,如可能涉及头发模拟等。在该示例中,要执行的粒子模拟被确定602。这可以包括,例如,确定要作为计算机图形应用程序的一部分执行的流体模拟,以及其他这样的选项。可以确定604与位于盆地或域中的每个粒子相关联的运动信息,如上文结合等式1-3所述。可以获得604或生成第n帧的密度张量,诸如以上结合图3a描述的。密度张量可以表示所有粒子相对于体素的位置和/或速度。可以为帧n获得606或生成刚体掩模,诸如以上结合图3b描述的。可以确定帧n中每个粒子的最终位置和最终速度610,诸如以上结合等式4-5和图4描述的。可以输出帧n中每个粒子的最终位置和最终速度以用作帧n+1中的初始速度和初始位置,诸如以上结合等式4-5和图4描述的。可以至少部分地基于为每个粒子确定的最终速度和最终位置,来执行对第一和第二帧的模拟。
[0042]
推理和训练逻辑
[0043]
图7示出了用于执行与至少一个实施例相关联的推理和/或训练操作的推理和/或训练逻辑715。下面结合图7和图8提供关于推理和/或训练逻辑715的细节。
[0044]
在至少一个实施例中,推理和/或训练逻辑715可以包括但不限于代码和/或数据存储701,以存储前向和/或输出权重和/或输入/输出数据和/或其他参数以配置一个或更多个实施例的方面中训练和/或用于推理的神经元或神经网络的层。在至少一个实施例中,训练逻辑715可以包括或耦合到代码和/或数据存储器701,以存储图形代码或其他软件来控制时间和/或顺序,其中权重和/或其他参数信息将被加载以配置逻辑,包括整数和/或浮点单元(统称为算术逻辑单元(alu))。在至少一个实施例中,诸如图形代码之类的代码将权重或其他参数信息加载到基于架构的处理器alu中此代码对应的神经网络。在至少一个实施例中,代码和/或数据存储701存储在使用一个或更多个实施例的方面训练和/或推理期间的输入/输出数据和/或权重参数的前向传播期间结合一个或更多个实施例训练或使用的神经网络的每个层的权重参数和/或输入/输出数据。在至少一个实施例中,代码和/或数据存储701的任何部分都可以包括在其他片上或片外数据存储内,包括处理器的l1、l2或l3高速缓存或系统内存。
[0045]
在至少一个实施例中,代码和/或数据存储701的任何部分可以在一个或更多个处理器或其他硬件逻辑设备或电路的内部或外部。在至少一个实施例中,代码和/或数据存储701可以是高速缓存内存、动态随机可寻址内存(“dram”)、静态随机可寻址内存(“sram”)、非易失性内存(例如闪存)或其他存储。在至少一个实施例中,对代码和/或数据存储701是在处理器的内部还是外部的选择,例如,或者由dram、sram、闪存或某种其他存储类型组成,可以取决于存储片上或片外的可用存储空间,正在执行训练和/或推理功能的延迟要求,在神经网络的推理和/或训练中使用的数据批量大小或这些因素的某种组合。
[0046]
在至少一个实施例中,推理和/或训练逻辑715可以包括但不限于代码和/或数据存储705,以存储与在一个或更多个实施例的方面中被训练为和/或用于推理的神经网络的神经元或层相对应的反向和/或输出权重和/或输入/输出数据神经网络。在至少一个实施
例中,在使用一个或更多个实施例的方面训练和/或推理期间,代码和/或数据存储705存储在输入/输出数据和/或权重参数的反向传播期间结合一个或更多个实施例训练或使用的神经网络的每个层的权重参数和/或输入/输出数据。在至少一个实施例中,训练逻辑715可以包括或耦合到代码和/或数据存储器705,以存储图形代码或其他软件,以控制时序和/或顺序,其中将加载重量和/或其他参数信息以配置逻辑、包括整数和/或浮点单元(统称为算术逻辑单元(alu))。在至少一个实施例中,诸如图代码之类的代码根据该代码对应的神经网络架构,将权重或其他参数信息加载到处理器alu中。在至少一个实施例中,代码和/或数据存储705的任何部分可以与其他片上或片外数据存储一起包括,包括处理器的l1、l2或l3高速缓存或系统内存。在至少一个实施例中,代码和/或数据存储705的任何部分可以在一个或更多个处理器或其他硬件逻辑设备或电路上的内部或外部。在至少一个实施例中,代码和/或数据存储705可以是高速缓存内存、dram、sram、非易失性内存(例如闪存)或其他存储。在至少一个实施例中,代码和/或数据存储705是在处理器的内部还是外部的选择,例如,是由dram、sram、闪存还是其他某种存储类型组成,取决于可用存储是片上还是片外,正在执行的训练和/或推理功能的延迟要求,在神经网络的推理和/或训练中使用的数据批量大小或这些因素的某种组合。
[0047]
在至少一个实施例中,代码和/或数据存储701以及代码和/或数据存储705可以是分开的存储结构。在至少一个实施例中,代码和/或数据存储701以及代码和/或数据存储705可以是相同的存储结构。在至少一个实施例中,代码和/或数据存储701以及代码和/或数据存储705可以是部分相同的存储结构和部分分离的存储结构。在至少一个实施例中,代码和/或数据存储701和代码和/或数据存储705的任何部分可以与其他片上或片外数据存储包括在一起,包括处理器的l1、l2或l3高速缓存或系统内存。
[0048]
在至少一个实施例中,推理和/或训练逻辑715可以包括但不限于一个或更多个算术逻辑单元(“alu”)910(包括整数和/或浮点单位),用于至少部分地基于训练和/或推理代码(例如,图形代码)或由其指示来执行逻辑和/或数学运算,其结果可能会产生(例如,来自神经网络内部的层或神经元的输出值)存储在激活存储820中的激活,其是存储在代码和/或数据存储701和/或代码和/或数据存储805中的输入/输出和/或权重参数数据的函数。在至少一个实施例中,激活响应于执行指令或其他代码,由alu8执行的线性代数和/或基于矩阵的数学生成在激活存储820中存储的激活,其中存储在代码和/或数据存储805中和/或代码和/或数据存储801中的权重值用作具有其他值的操作数,例如偏置值、梯度信息、动量值或其他参数或超参数,可以将任何或所有这些存储在代码和/或数据存储805和/或代码和/或数据存储801或其他片上或片外存储中。
[0049]
在至少一个实施例中,一个或更多个处理器或其他硬件逻辑设备或电路中包括一个或更多个alu,而在另一实施例中,一个或更多个alu可以在处理器或其他硬件逻辑设备或使用它们(例如协处理器)的电路外。在至少一个实施例中,可以将一个或更多个alu包括在处理器的执行单元之内,或者以其他方式包括在由处理器的执行单元可访问的alu组中,该处理器的执行单元可以在同一处理器内或者分布在不同类型的不同处理器之间(例如,中央处理单元、图形处理单元、固定功能单元等)。在至少一个实施例中,代码和/或数据存储801、代码和/或数据存储805以及激活存储820可以在同一处理器或其他硬件逻辑设备或电路上,而在另一实施例中,它们可以在不同的处理器或其他硬件逻辑设备或电路或相同
和不同处理器或其他硬件逻辑设备或电路的某种组合中。在至少一个实施例中,激活存储820的任何部分可以与其他片上或片外数据存储包括在一起,包括处理器的l1、l2或l3高速缓存或系统内存。此外,推理和/或训练代码可以与处理器或其他硬件逻辑或电路可访问的其他代码一起存储,并可以使用处理器的提取、解码、调度、执行、退出和/或其他逻辑电路来提取和/或处理。
[0050]
在至少一个实施例中,激活存储820可以是高速缓存内存、dram、sram、非易失性内存(例如,闪存)或其他存储。在至少一个实施例中,激活存储820可以完全地或部分地在一个或更多个处理器或其他逻辑电路内部或外部。在至少一个实施例中,可以取决于片上或片外可用的存储,进行训练和/或推理功能的延迟要求,在推理和/或训练神经网络中使用的数据的批量大小或这些因素的某种组合,选择激活存储820是处理器的内部还是外部,例如,或者包含dram、sram、闪存或其他存储类型。在至少一个实施例中,图8中所示的推理和/或训练逻辑715可以与专用集成电路(“asic”)结合使用,例如来自google的处理单元、来自graphcore
tm
的推理处理单元(ipu)或来自intelcorp的(例如“lakecrest”)处理器。在至少一个实施例中,图8所示的推理和/或训练逻辑715可与中央处理单元(“cpu”)硬件,图形处理单元(“gpu”)硬件或其他硬件(例如现场可编程门阵列(“fpga”))结合使用。
[0051]
图8示出了根据至少一个各种实施例的推理和/或训练逻辑815。在至少一个或更多个实施例中,推理和/或训练逻辑815可以包括但不限于硬件逻辑,其中计算资源被专用或以其他方式唯一地连同对应于神经网络内的一层或更多层神经元的权重值或其他信息一起使用。在至少一个实施例中,图8中所示的推理和/或训练逻辑815可以与专用集成电路(asic)结合使用,例如来自google的处理单元,来自graphcore
tm
的推理处理单元(ipu)或来自intelcorp的(例如“lakecrest”)处理器。在至少一个实施例中,图8中所示的推理和/或训练逻辑815可以与中央处理单元(cpu)硬件、图形处理单元(gpu)硬件或其他硬件(例如现场可编程门阵列(fpga))结合使用。在至少一个实施例中,推理和/或训练逻辑815包括但不限于代码和/或数据存储801以及代码和/或数据存储805,其可以用于存储代码(例如图形代码)、权重值和/或其他信息,包括偏置值、梯度信息、动量值和/或其他参数或超参数信息。在图8中所示的至少一个实施例中,代码和/或数据存储801以及代码和/或数据存储805中的每一个都分别与专用计算资源(例如计算硬件802和计算硬件806)相关联。在至少一个实施例中,计算硬件802和计算硬件806中的每一个包括一个或更多个alu,这些alu仅分别对存储在代码和/或数据存储801和代码和/或数据存储805中的信息执行数学函数(例如线性代数函数),执行函数的结果被存储在激活存储820中。
[0052]
在至少一个实施例中,代码和/或数据存储801和805以及相应的计算硬件802和806中的每一个分别对应于神经网络的不同层,使得从代码和/或数据存储801和计算硬件802的一个“存储/计算对801/802”得到的激活提供作为代码和/或数据存储805和计算硬件806的下一个“存储/计算对805/806”的输入,以便反映神经网络的概念组织。在至少一个实施例中,每个存储/计算对801/802和805/806可以对应于一个以上的神经网络层。在至少一个实施例中,在推理和/或训练逻辑815中可以包括在存储计算对801/802和805/806之后或与之并行的附加存储/计算对(未示出)。
[0053]
诸如关于图8所讨论的推理和训练逻辑可用于训练一个或更多个神经网络,以分析视频数据的媒体流或文件,这可能对应于游戏玩法数据。这些可在所描述的硬件结构815上运行的神经网络可用于推断以检测对象或事件,以及基于这些检测到的对象或事件的数据推断事件类型。可以针对不同的游戏、游戏类型、视频内容类型或事件类型以及其他此类选项训练不同的神经网络或机器学习模型。
[0054]
数据中心
[0055]
图9示出了示例数据中心900,其中可以使用至少一个实施例。在至少一个实施例中,数据中心900包括数据中心基础设施层910、框架层920、软件层930和应用层940。
[0056]
在至少一个实施例中,如图9所示,数据中心基础设施层910可以包括资源协调器912、分组的计算资源914和节点计算资源(“节点c.r.”)916(1)-916(n),其中“n”代表任何完整的正整数。在至少一个实施例中,节点c.r.916(1)-916(n)可以包括但不限于任何数量的中央处理单元(“cpu”)或其他处理器(包括加速器、现场可编程门阵列(fpga)、图形处理器等),内存设备(例如动态只读内存),存储设备(例如固态硬盘或磁盘驱动器),网络输入/输出(“nwi/o”)设备,网络交换机,虚拟机(“vm”),电源模块和冷却模块等。在至少一个实施例中,节点c.r.916(1)-916(n)中的一个或更多个节点c.r.可以是具有一个或更多个上述计算资源的服务器。
[0057]
在至少一个实施例中,分组的计算资源914可以包括容纳在一个或更多个机架内的节点c.r.的单独分组(未示出),或者容纳在各个地理位置的数据中心内的许多机架(也未示出)。分组的计算资源914内的节点c.r.的单独分组可以包括可以被配置或分配为支持一个或更多个工作负载的分组的计算、网络、内存或存储资源。在至少一个实施例中,可以将包括cpu或处理器的几个节点c.r.分组在一个或更多个机架内,以提供计算资源来支持一个或更多个工作负载。在至少一个实施例中,一个或更多个机架还可以包括任何数量的电源模块、冷却模块和网络交换机,以任意组合。
[0058]
在至少一个实施例中,资源协调器922可以配置或以其他方式控制一个或更多个节点c.r.916(1)-916(n)和/或分组的计算资源914。在至少一个实施例中,资源协调器922可以包括用于数据中心900的软件设计基础结构(“sdi”)管理实体。在至少一个实施例中,资源协调器可以包括硬件、软件或其某种组合。
[0059]
在至少一个实施例中,如图9所示,框架层920包括作业调度器1022、配置管理器1024、资源管理器1026和分布式文件系统1028。在至少一个实施例中,框架层920可以包括支持软件层930的软件1022和/或应用程序层940的一个或更多个应用程序942的框架。在至少一个实施例中,软件1022或应用程序942可以分别包括基于web的服务软件或应用程序,例如由amazonwebservices,googlecloud和microsoftazure提供的服务或应用程序。在至少一个实施例中,框架层920可以是但不限于一种免费和开放源软件网络应用框架,例如可以利用分布式文件系统1028来进行大范围数据处理(例如“大数据”)的apachesparktm(以下称为“spark”)。在至少一个实施例中,作业调度器1022可以包括spark驱动器,以促进对数据中心900的各个层所支持的工作负载进行调度。在至少一个实施例中,配置管理器1024可以能够配置不同的层,例如软件层930和包括spark和用于支持大规模数据处理的分布式文件系统1028的框架层920。在至少一个实施例中,资源管理器1026能够管理映射到或分配用于支持分布式文件系统1028和作业调度器1022的集群或分组计算资源。在至少一个实施
例中,集群或分组计算资源可以包括数据中心基础设施层910上的分组的计算资源914。在至少一个实施例中,资源管理器1026可以与资源协调器912协调以管理这些映射的或分配的计算资源。
[0060]
在至少一个实施例中,包括在软件层930中的软件1022可以包括由节点c.r.916(1)-916(n)的至少一部分,分组计算资源914和/或框架层920的分布式文件系统1028使用的软件。一种或更多种类型的软件可以包括但不限于internet网页搜索软件、电子邮件病毒扫描软件、数据库软件和流视频内容软件。
[0061]
在至少一个实施例中,应用层940中包括的一个或更多个应用程序942可以包括由节点c.r.916(1)-916(n)的至少一部分、分组的计算资源914和/或框架层920的分布式文件系统1028使用的一种或更多种类型的应用程序。一种或更多种类型的应用程序可以包括但不限于任何数量的基因组学应用程序,认知计算和机器学习应用程序,包括训练或推理软件,机器学习框架软件(例如pytorch、tensorflow、caffe等)或其他与一个或更多个实施例结合使用的机器学习应用程序。
[0062]
在至少一个实施例中,配置管理器1024、资源管理器1026和资源协调器912中的任何一个可以基于以任何技术上可行的方式获取的任何数量和类型的数据来实现任何数量和类型的自我修改动作。在至少一个实施例中,自我修改动作可以减轻数据中心900的数据中心操作员做出可能不好的配置决定并且可以避免数据中心的未充分利用和/或执行差的部分。
[0063]
在至少一个实施例中,数据中心900可以包括工具、服务、软件或其他资源,以根据本文所述的一个或更多个实施例来训练一个或更多个机器学习模型或者使用一个或更多个机器学习模型来预测或推理信息。例如,在至少一个实施例中,可以通过使用上文关于数据中心900描述的软件和计算资源,根据神经网络架构通过计算权重参数来训练机器学习模型。在至少一个实施例中,通过使用通过本文所述的一种或更多种训练技术计算出的权重参数,可以使用上面与关于数据中心900所描述的资源,使用对应于一个或更多个神经网络的经训练的机器学习模型来推理或预测信息。
[0064]
在至少一个实施例中,数据中心可以使用cpu、专用集成电路(asic)、gpu、fpga或其他硬件来使用上述资源来执行训练和/或推理。此外,上述的一个或更多个软件和/或硬件资源可以配置成一种服务,以允许用户训练或执行信息推理,例如图像识别、语音识别或其他人工智能服务。
[0065]
推理和/或训练逻辑715用于执行与一个或更多个实施例相关联的推理和/或训练操作。下面结合图8和/或图9提供关于推理和/或训练逻辑715的细节。在至少一个实施例中,推理和/或训练逻辑715可以在系统图9中使用,至少部分地基于使用神经网络训练操作、神经网络功能和/或架构或本文所述的神经网络用例计算出的权重参数来推理或预测操作。
[0066]
计算机系统
[0067]
图10是示出根据至少一个实施例示例性计算机系统的框图,该示例性计算机系统可以是具有互连的设备和组件的系统,片上系统(soc)或它们的某种形成有处理器的组合1000,该处理器可以包括执行单元以执行指令。在至少一个实施例中,根据本公开,例如本文所述的实施例,计算机系统1000可以包括但不限于组件,例如处理器1002,其执行单元包
括逻辑以执行用于过程数据的算法。在至少一个实施例中,计算机系统1000可以包括处理器,例如可从加利福尼亚圣塔克拉拉的英特尔公司(intelcorporationofsantaclara,california)获得的处理器家族、xeontm、xscaletm和/或strongarmtm,core
tm
或nervana
tm
微处理器,尽管也可以使用其他系统(包括具有其他微处理器的pc、工程工作站、机顶盒等)。在至少一个实施例中,计算机系统1000可以执行可从华盛顿州雷蒙德市的微软公司(microsoftcorporationofredmond,wash.)获得的windows操作系统版本,尽管其他操作系统(例如unix和linux)、嵌入式软件和/或图形用户界面也可以使用。
[0068]
实施例可以用在其他设备中,例如手持设备和嵌入式应用。手持设备的一些示例包括蜂窝电话、互联网协议(internetprotocol)设备、数码相机、个人数字助理(“pda”)和手持pc。在至少一个实施例中,嵌入式应用可以包括微控制器、数字信号处理器(“dsp”)、片上系统、网络计算机(“netpc”)、机顶盒、网络集线器、广域网(“wan”)交换机,或根据至少一个实施例可以执行一个或更多个指令的任何其他系统。
[0069]
在至少一个实施例中,计算机系统1000可包括但不限于处理器1002,该处理器1002可包括但不限于一个或更多个执行单元1008,以根据本文描述的技术执行机器学习模型训练和/或推理。在至少一个实施例中,计算机系统10是单处理器台式机或服务器系统,但是在另一实施例中,计算机系统10可以是多处理器系统。在至少一个实施例中,处理器1002可以包括但不限于复杂指令集计算机(“cisc”)微处理器、精简指令集计算(“risc”)微处理器、超长指令字(“vliw”)微处理器、实现指令集组合的处理器,或任何其他处理器设备,例如数字信号处理器。在至少一个实施例中,处理器1002可以耦合到处理器总线1010,该处理器总线1010可以在处理器1002与计算机系统1000中的其他组件之间传输数据信号。
[0070]
在至少一个实施例中,处理器1002可以包括但不限于1级(“l1”)内部高速缓存内存(“cache”)1004。在至少一个实施例中,处理器1002可以具有单个内部高速缓存或多级内部缓存。在至少一个实施例中,高速缓存内存可以驻留在处理器1002的外部。根据特定的实现和需求,其他实施例也可以包括内部和外部高速缓存的组合。在至少一个实施例中,寄存器文件1006可以在各种寄存器中存储不同类型的数据,包括但不限于整数寄存器、浮点寄存器、状态寄存器和指令指针寄存器。
[0071]
在至少一个实施例中,包括但不限于执行整数和浮点运算的逻辑的执行单元1008,其也位于处理器1002中。在至少一个实施例中,处理器1002还可以包括微码(“ucode”)只读内存(“rom”),用于存储某些宏指令的微代码。在至少一个实施例中,执行单元1008可以包括用于处理封装指令集1009的逻辑。在至少一个实施例中,通过将封装指令集1009包括在通用处理器1002的指令集中,以及要执行指令的相关电路,可以使用通用处理器1002中的封装数据来执行许多多媒体应用程序使用的操作。在一个或更多个实施例中,可以通过使用处理器的数据总线的全宽度来在封装的数据上执行操作来加速和更有效地执行许多多媒体应用程序,这可能不需要在处理器的数据总线上传输较小的数据单元来一次执行一个数据元素的一个或更多个操作。
[0072]
在至少一个实施例中,执行单元1008也可以用在微控制器、嵌入式处理器、图形设备、dsp和其他类型的逻辑电路中。在至少一个实施例中,计算机系统1000可以包括但不限于内存1020。在至少一个实施例中,内存1020可以被实现为动态随机存取内存(“dram”)设
备、静态随机存取内存(“sram”)设备、闪存设备或其他存储设备。在至少一个实施例中,内存1020可以存储由处理器1002可以执行的由数据信号表示的指令1019和/或数据1021。
[0073]
在至少一个实施例中,系统逻辑芯片可以耦合到处理器总线1010和内存1020。在至少一个实施例中,系统逻辑芯片可以包括但不限于内存控制器集线器(“mch”)1016,并且处理器1002可以经由处理器总线1010与mch1016通信。在至少一个实施例中,mch1016可以提供到内存1020的高带宽内存路径1018以用于指令和数据存储以及用于图形命令、数据和纹理的存储。在至少一个实施例中,mch1016可以在处理器1002、内存1020和计算机系统1000中的其他组件之间启动数据信号,并且在处理器总线1010、内存1020和系统i/o1022之间桥接数据信号。在至少一个实施例中,系统逻辑芯片可以提供用于耦合到图形控制器的图形端口。在至少一个实施例中,mch1016可以通过高带宽内存路径1018耦合到内存1020,并且图形/视频卡1112可以通过加速图形端口(acceleratedgraphicsport)(“agp”)互连1114耦合到mch1016。
[0074]
在至少一个实施例中,计算机系统1000可以使用系统i/o1022作为专有集线器接口总线来将mch1016耦合到i/o控制器集线器(“ich”)1030。在至少一个实施例中,ich1030可以通过本地i/o总线提供与某些i/o设备的直接连接。在至少一个实施例中,本地i/o总线可以包括但不限于用于将外围设备连接到内存1020、芯片组和处理器1002的高速i/o总线。示例可以包括但不限于音频控制器1029、固件集线器(“flashbios”)1028、无线收发器1026、数据存储1024、包含用户输入的传统i/o控制器1023和键盘接口、串行扩展端口1027(例如通用串行总线(usb))和网络控制器1034。数据存储1024可以包括硬盘驱动器、软盘驱动器、cd-rom设备、闪存设备或其他大容量存储设备。
[0075]
在至少一个实施例中,图10示出了包括互连的硬件设备或“芯片”的系统,而在其他实施例中,图10可以示出示例性片上系统(“soc”)。在至少一个实施例中,图10中示出的设备可以与专有互连、标准化互连(例如,pcie)或其某种组合互连。在至少一个实施例中,计算机系统1000的一个或更多个组件使用计算快速链路(cxl)互连来互连。
[0076]
推理和/或训练逻辑715用于执行与一个或更多个实施例相关的推理和/或训练操作。下面结合图8和/或图9提供关于推理和/或训练逻辑715的细节。在至少一个实施例中,推理和/或训练逻辑715可以在图10的系统中使用,用于至少部分地基于使用神经网络训练操作、神经网络功能和/或架构或本文所述的神经网络用例计算的权重参数来推理或预测操作。
[0077]
在示例用例中,可能有多个玩家使用单个服务器在多人游戏中进行游戏,诸如可能涉及在该服务器上使用nvidiageforcenow。在至少一些实施例中,可以在一台或什至多台计算机或客户端设备上的geforcenow基础设施内执行流体模拟,并且可以与游戏服务器共享该流体状态。在这样的用例中,玩家的客户端设备可以在给定级别内从他们的相机提供渲染。因此,本文讨论的方法是可扩展的,并且可以在多台机器上并行执行,其中每台机器都可以在其子域上工作并执行相应的推理。
[0078]
图11是示出根据至少一个实施例的用于利用处理器1110的电子设备1100的框图。在至少一个实施例中,电子设备1100可以是,例如但不限于,笔记本电脑、塔式服务器、机架服务器、刀片服务器、膝上型计算机、台式机、平板电脑、移动设备、电话、嵌入式计算机或任何其他合适的电子设备。
[0079]
在至少一个实施例中,系统1100可以包括但不限于通信地耦合到任何合适数量或种类的组件、外围设备、模块或设备的处理器1110。在至少一个实施例中,处理器1110使用总线或接口耦合,诸如1℃总线、系统管理总线(“smbus”)、低引脚数(lpc)总线、串行外围接口(“spi”)、高清音频(“hda”)总线、串行高级技术附件(“sata”)总线、通用串行总线(“usb”)(1、2、3版)或通用异步接收器/发送器(“uart”)总线。在至少一个实施例中,图11示出了系统,该系统包括互连的硬件设备或“芯片”,而在其他实施例中,图11可以示出示例性片上系统(“soc”)。在至少一个实施例中,图11中所示的设备可以与专有互连线、标准化互连(例如,pcie)或其某种组合互连。在至少一个实施例中,图11的一个或更多个组件使用计算快速链路(cxl)互连线来互连。
[0080]
在至少一个实施例中,图11可以包括显示器1124、触摸屏1125、触摸板1130、近场通信单元(“nfc”)1145、传感器集线器1140、热传感器1246、快速芯片组(“ec”)1135、可信平台模块(“tpm”)1138、bios/固件/闪存(“bios,fwflash”)1122、dsp1160、驱动器1120(例如固态磁盘(“ssd”)或硬盘驱动器(“hdd”))、无线局域网单元(“wlan”)1150、蓝牙单元1152、无线广域网单元(“wwan”)1156、全球定位系统(gps)1155、相机(“usb3.0相机”)1154(例如usb3.0相机)和/或以例如lpddr3标准实现的低功耗双倍数据速率(“lpddr”)内存单元(“lpddr3”)1112。这些组件可以各自以任何合适的方式实现。
[0081]
在至少一个实施例中,其他组件可以通过以上讨论的组件通信地耦合到处理器1110。在至少一个实施例中,加速度计1141、环境光传感器(“als”)1142、罗盘1143和陀螺仪1144可以可通信地耦合到传感器集线器1140。在至少一个实施例中,热传感器1139、风扇1137、键盘1246和触摸板1130可以通信地耦合到ec1135。在至少一个实施例中,扬声器1163、耳机1164和麦克风(“mic”)1165可以通信地耦合到音频单元(“音频编解码器和d类放大器”)1164,其又可以通信地耦合到dsp1160。在至少一个实施例中,音频单元1164可以包括例如但不限于音频编码器/解码器(“编解码器”)和d类放大器。在至少一个实施例中,sim卡(“sim”)1157可以通信地耦合到wwan单元1156。在至少一个实施例中,组件(诸如wlan单元1150和蓝牙单元1152以及wwan单元1156)可以被实现为下一代形式因素(ngff)。
[0082]
推理和/或训练逻辑715用于执行与一个或更多个实施例相关联的推理和/或训练操作。下面结合图8和/或图9提供关于推理和/或训练逻辑715的细节。在至少一个实施例中,推理和/或训练逻辑715可以在系统图11中使用,用于至少部分地基于使用神经网络训练操作、神经网络功能和/或架构或本文所述的神经网络用例计算的权重参数来推理或预测操作。
[0083]
图12示出了根据至少一个实施例的计算机系统1200。在至少一个实施例中,计算机系统1200配置为实现贯穿本公开描述的各种过程和方法。
[0084]
在至少一个实施例中,计算机系统1200包括但不限于至少一个中央处理单元(“cpu”)1202,该中央处理单元(“cpu”)1202连接到使用任何合适协议实现的通信总线1210,诸如pci(“外围设备互联”)、外围组件互连express(“pci-express”)、agp(“加速图形端口”)、超传输或任何其他总线或点对点通信协议。在至少一个实施例中,计算机系统1200包括但不限于主内存1204和控制逻辑(例如,实现为硬件、软件或其组合),并且数据可以采取随机存取内存(“ram”)的形式存储在主内存1204中。在至少一个实施例中,网络接口子系统(“网络接口”)1222提供到其他计算设备和网络的接口,用于从计算机系统1200接收数据
并将数据传输到其他系统。
[0085]
在至少一个实施例中,计算机系统1200在至少一个实施例中包括但不限于输入设备1208、并行处理系统1212和显示设备1206,它们可以使用阴极视线管(“crt”)、液晶显示器(“lcd”)、发光二极管(“led”)、等离子显示器或其他合适的显示技术实现。在至少一个实施例中,从输入设备1208(诸如键盘、鼠标、触摸板、麦克风等)接收用户输入。在至少一个实施例中,前述模块中的每一个可以位于单个半导体平台上以形成处理系统。
[0086]
推理和/或训练逻辑715用于执行与一个或更多个实施例相关联的推理和/或训练操作。下面结合图8和/或图9提供关于推理和/或训练逻辑715的细节。在至少一个实施例中,推理和/或训练逻辑715可以在系统图12中使用,以至少部分地基于使用神经网络训练操作、神经网络功能和/或架构或本文所述的神经网络用例计算出的权重参数来进行推理或预测操作。
[0087]
图13示出了示范性架构,其中,多个gpu1310-1313通过高速链路1340-1343(例如,总线、点对点互连等)通信地耦合至多个多核处理器1305-1306。在一个实施例中,高速链路1340-1343支持4gb/s、30gb/s、80gb/s或更高的通信吞吐量。可以使用不同互连协议,包括但不限于pcie4.0或5.0和nvlink2.0。
[0088]
此外,在一个实施例中,两个或更多个gpu1310-1313通过高速链路1329-1330互连,高速链路1329-1330可以使用与用于高速链路1340-1343的协议/链路相同或不同的协议/链路来实现。类似地,两个或更多个多核心处理器1305可以通过高速链路1328连接,该高速链路可以是以20gb/s、30gb/s、120gb/s或更高的速度运行的对称多处理器(smp)总线。可替代地,可以使用类似的协议/链路(例如,通过公共互连结构)来完成图13a中所示的各种系统组件之间的所有通信。
[0089]
在一个实施例中,每个多核心处理器1305分别经由存储器互连1326-1327通信地耦合到处理器存储器1301-1302,并且每个gpu1310-1313分别通过gpu存储器互连1350-1353通信地耦合到gpu存储器1320-1323。存储器互连1326-1327和1350-1353可以利用相同或不同的存储器访问技术。作为示例而非限制,处理器存储器1301-1302和gpu存储器1320-1323可以是易失性存储器,诸如动态随机存取存储器(dram)(包括堆叠的dram)、图形ddrsdram(gddr)(例如gddr5、gddr6),或高带宽存储器(hbm),和/或可以是非易失性存储器,例如3dxpoint或nano-ram。在至少一个实施例中,处理器存储器1301-1302的某些部分可以是易失性存储器,而另一部分可以是非易失性存储器(例如,使用两级存储器(2lm)层次结构)。
[0090]
如下文所述,尽管各种处理器1305-1306和gpu1310-1313可以分别物理地耦合到特定存储器1301-1302、1320-1323,可以实现统一存储器架构,其中相同的虚拟系统地址空间(也称为“有效地址”空间)分布在各个物理存储器之间。例如,处理器存储器1301-1302可以各自包含64gb的系统存储器地址空间,并且gpu存储器1320-1323可以各自包含32gb的系统存储器地址空间,从而在本示例中,导致总计256gb的可寻址存储器大小。
[0091]
图13示出了根据一个示例性实施例的用于多核心处理器1407和图形加速模块1446之间互连的附加细节。图形加速模块1446可以包括集成在线路卡上的一个或更多个gpu芯片,该线路卡经由高速链路1440耦合到处理器1407。图形加速模块1446可以集成在作为处理器1407的同一封装或芯片上。
[0092]
在至少一个实施例中,示出的处理器1407包括多个核心1460a-1460d,每个核心都具有转换后备缓冲区1461a-1461d和一个或更多个高速缓存1462a-1462d。在至少一个实施例中,核心1460a-1460d可以包括未示出的各种其他组件,用于执行指令和处理数据。高速缓存1462a-1462d可以包括级别1(l1)和级别2(l2)高速缓存。此外,一个或更多个共享高速缓存1456可以被包括在高速缓存1462a-1462d中,并且由各组核心1460a-1460d共享。例如,处理器1407的一个实施例包括24个核心,每个核心具有其自己的l1高速缓存,十二个共享的l2高速缓存,和十二个共享的l3高速缓存。在该实施例中,两个相邻核心共享一个或更多个l2和l3高速缓存。处理器1407和图形加速模块1446与系统存储器1414连接,该系统存储器1414可以包括图13中的处理器存储器1301-1302。
[0093]
通过一致性总线1464经由核心间通信为存储在各个高速缓存1462a-1462d、1456和系统存储器1414中的数据和指令维护一致性,如图14所示。例如,每个高速缓存可以具有与其相关联的高速缓存一致性逻辑/电路,以响应于检测到对特定高速缓存行的读取或写入通过一致性总线1464进行通信。在一个示例中,通过一致性总线1464实现高速缓存监听协议,以监听(snoop)高速缓存访问。
[0094]
在一个实施例中,代理电路1425将图形加速模块1446通信地耦合到一致性总线1464,从而允许图形加速模块1446作为核心1460a-1460d的对等方参与高速缓存一致性协议。特别地,接口1435通过高速链路1440(例如,pcie总线、nvlink等)提供到代理电路1425的连接,并且接口1437将图形加速模块1446连接到链路1440。
[0095]
在一个示例中,加速器集成电路1436代表图形加速模块的多个图形处理引擎1431-1432,n,提供高速缓存管理、存储器访问、上下文管理和中断管理服务。在至少一个实施例中,图形处理引擎1431-1432,n可各自包括单独的图形处理单元(gpu)。图形处理引擎1431-1432,n选择性地可以包括gpu内的不同类型的图形处理引擎,诸如图形执行单元、媒体处理引擎(例如,视频编码器/解码器)、采样器和blit引擎。在至少一个实施例中,图形加速模块1446可以是具有多个图形处理引擎1431-1432,n的gpu,或者图形处理引擎1431-1432,n可以是集成在通用封装、线路卡或芯片上的各个gpu。
[0096]
在一个实施例中,加速器集成电路1436包括存储器管理单元(mmu)1439,用于执行各种存储器管理功能,例如虚拟到物理存储器转换(也称为有效到真实存储器转换),还包括用于访问系统存储器1514的存储器访问协议。mmu1439还可包括转换后备缓冲区(“tlb”)(未示出),用于高速缓存虚拟/有效到物理/真实地址转换。在一个示例中,高速缓存1438可以存储命令和数据,用于图形处理引擎1431-1432,n有效地访问。在一个实施例中,将存储在高速缓存1438和图形存储器1433-1434,m中的数据与核心高速缓存1462a-1462d、1456和系统存储器1514保持一致。如前所述,可以经由代表高速缓存1438和图形存储器1433-1434,m的代理电路1425来完成该任务(例如,将与处理器高速缓存1462a-1462d、1456上的高速缓存行的修改/访问有关的更新发送到高速缓存1438,并从高速缓存1438接收更新)。
[0097]
图14中的一组寄存器1445存储由图形处理引擎1431-1432,n执行的线程的上下文数据,并且上下文管理电路1448管理线程上下文。例如,上下文管理电路1448可以执行保存和恢复操作,以在上下文切换期间保存和恢复各个线程的上下文(例如,其中保存第一线程并且存储第二线程,以便可以由图形处理引擎执行第二线程)。例如,上下文管理电路1448在上下文切换时,可以将当前寄存器值存储到存储器中的(例如,由上下文指针标识的)指
定区域。然后,当返回上下文时可以恢复寄存器值。在一个实施例中,中断管理电路1447接收并处理从系统设备接收的中断。
[0098]
在一个实现方式中,mmu1439将来自图形处理引擎1431的虚拟/有效地址转换为系统存储器1514中的真实/物理地址。加速器集成电路1436的一个实施例支持多个(例如,4、8、16)图形加速器模块1446和/或其他加速器设备。图形加速器模块1446可以专用于在处理器1407上执行的单个应用程序,或者可以在多个应用程序之间共享。在一个实施例中,呈现了虚拟化的图形执行环境,其中图形处理引1431-1432,n的资源与多个应用程序或虚拟机(vm)共享。在至少一个实施例中,可以基于处理要求和与vm和/或应用程序相关联的优先级,将资源细分为“切片”,其被分配给不同的vm和/或应用程序。
[0099]
在至少一个实施例中,加速器集成电路1436作为图形加速模块1446的系统的桥来执行,并提供地址转换和系统存储器高速缓存服务。另外,加速器集成电路1436可以为主机处理器提供虚拟化设施,以管理图形处理引擎1431-1432,n的虚拟化、中断和存储器管理。
[0100]
由于图形处理引擎1431-1432,n的硬件资源被明确地映射到主机处理器1407看到的真实地址空间,因此任何主机处理器都可以使用有效地址值直接寻址这些资源。在至少一个实施例中,加速器集成电路1436的一个功能是物理分离图形处理引擎1431-1432,n,使得它们在系统看来为独立的单元。
[0101]
在至少一个实施例中,一个或更多个图形存储器1433-1434,m分别耦合到每个图形处理引擎1431-1432,n。图形存储器1433-1434,m存储指令和数据,所述指令和数据由每个图形处理引擎1431-1432,n处理。图形存储器1433-1434,m可以是易失性存储器,例如dram(包括堆叠的dram)、gddr存储器(例如,gddr5,gddr6)或hbm,和/或可以是非易失性存储器,例如3dxpoint或nano-ram。
[0102]
在一个实施例中,为了减少链路1440上的数据流量,使用偏置技术以确保存储在图形存储器1433-1434,m中的数据是图形处理引擎1431-1432,n最常使用的,并且最好核心1460a-1460d不使用(至少不经常使用)的数据。类似地,偏置机制试图将核心(并且优选地不是图形处理引擎1431(-1)-1431(n))需要的数据保持在高速缓存1462a-1462d、1456和系统存储器1414中。
[0103]
在至少一个实施例中,单个半导体平台可以指唯一的单一的基于半导体的集成电路或芯片。在至少一个实施例中,可以使用具有增加的连接性的多芯片模块,其模拟芯片上的操作,并且相对于利用中央处理单元(“cpu”)和总线实施方式进行了实质性的改进。在至少一个实施例中,根据用户的需求,各种模块也可以分开放置或以半导体平台的各种组合放置。
[0104]
在至少一个实施例中,将以机器可读的可执行代码或计算机控制逻辑算法的形式的计算机程序存储在主内存1404和/或辅助存储中。根据至少一个实施例,如果由一个或更多个处理器执行,则计算机程序使系统1400能够执行各种功能。在至少一个实施例中,内存1404、存储和/或任何其他存储是计算机可读介质的可能示例。在至少一个实施例中,辅助存储可以指代任何合适的存储设备或系统,例如硬盘驱动器和/或可移除存储驱动器,代表软盘驱动器、磁带驱动器、光盘驱动器、数字多功能盘(“dvd”)驱动器、记录设备、通用串行总线(“usb”)闪存等。在至少一个实施例中,各种先前附图的架构和/或功能是在cpu;并行处理系统;能够具有至少两个cpu的能力的至少一部分的集成电路;并行处理系统;芯片组
(例如,一组设计成工作并作为执行相关功能的单元出售的集成电路等);以及集成电路的任何适当组合的环境中实现的。
[0105]
在至少一个实施例中,各种先前附图的架构和/或功能在通用计算机系统、电路板系统、专用于娱乐目的的游戏控制台系统、专用系统等的环境中实现。在至少一个实施例中,计算机系统可以采取台式计算机、膝上型计算机、平板电脑、服务器、超级计算机、智能电话(例如,无线,、手持设备)、个人数字助理(“pda”)、数码相机、车辆、头戴式显示器、手持式电子设备、移动电话设备、电视、工作站、游戏机、嵌入式系统和/或任何其他类型的逻辑的形式。此类硬件可用于执行应用程序和代码以支持本文讨论的各种类型的处理、分析和存储。例如,给定的计算机系统可能会执行游戏并分析游戏输出的视频以确定事件,然后将此事件数据上传到远程服务器进行分析或存储。在其他实施例中,视频数据流可由托管涉及若干不同客户端设备游戏的游戏服务器生成,并且该数据流可由另一服务器或计算机系统分析以确定在游戏玩法中发生的事件。在一些实施例中,该事件数据然后可以由相同的或又一个服务器或计算机系统用于处理,例如生成精彩视频或视频剪辑。
[0106]
其他变型在本公开的精神内。因此,尽管公开的技术易于进行各种修改和替代构造,但是其某些示出的实施例在附图中示出并且已经在上面进行了详细描述。但是,应当理解,无意将公开内容限制为所公开的一种或更多种特定形式,而是相反,其意图是涵盖落入如所附权利要求书所定义的公开内容的精神和范围内的所有修改、替代构造和等同物。
[0107]
除非另有说明,除非另有说明或显然与上下文明显矛盾,而不是作为术语的定义,否则在描述所公开的实施例的环境中(特别是在所附权利要求的环境中)对术语“一”,“一个”和“该”以及类似指代的使用应解释为涵盖单数和复数。术语“包含”,“具有”,“包括”和“内含”应解释为开放式术语(意思是“包括但不限于”)。术语“连接”在未经修改时指的是物理连接,应理解为部分或全部包含在,连接到或连接在一起的部分或全部,即使有任何介入。除非在此另外指出,否则本文中数值范围的引用仅旨在用作分别指代落入该范围内的每个单独值的速记方法,并且每个单独值都被并入说明书中,就如同其在本文中被单独叙述一样。除非环境另外指出或矛盾,否则术语“组”(例如“一组项目”)或“子集”的使用应解释为包括一个或更多个成员的非空集合。此外,除非环境另外指出或矛盾,否则相应集合的术语“子集”不一定表示相应集合的适当子集,而是子集和相应集合可以相等。
[0108]
除非以其他方式明确指出或与环境明显矛盾,否则诸如“a、b和c中的至少一个”或“a、b和c的至少一个”形式的词组等联合语言在环境中理解为通常用来表示项目,术语等可以是a或b或c,也可以是a和b和c集合的任何非空子集。例如,在具有三个成员,连接短语“a、b和c中的至少一个”和“a、b和c的至少一个”是指以下任意集合:{a},{b},{c},{a,b},{a,c},{b,c},{a,b,c}。因此,这种联合语言通常不意图暗示某些实施例要求存在a中的至少一个、b中的至少一个和c中的至少一个。另外,除非另有说明或与环境矛盾,否则术语“多个”表示复数的状态(例如,“多个项目”表示多个项目)。复数是至少两个项目,但是当明确地或通过环境指示时可以是多个。此外,除非另有说明或从环境中清楚得知,否则短语“基于”是指“至少部分基于”而不是“仅基于”。
[0109]
除非本文另外指出或与环境明显矛盾,否则本文描述的过程的操作可以任何合适的序列执行。在至少一个实施例中,诸如本文所述的那些过程(或其变形和/或其组合)的过程在配置有可执行指令的一个或更多个计算机系统的控制下执行,并且被实现为代码(例
如,可执行指令、一个或更多个计算机程序或一个或更多个应用程序)通过硬件或其组合在一个或更多个处理器上共同执行。在至少一个实施例中,代码例如以计算机程序的形式存储在计算机可读存储介质上,该计算机程序包括可由一个或更多个处理器执行的多个指令。在至少一个实施例中,计算机可读存储介质是非暂时性计算机可读存储介质,其不包括暂时性信号(例如,传播的瞬态电或电磁传输),但包括暂时性信号的收发器中的非暂时性数据存储电路(例如,缓冲区、高速缓存和队列)。在至少一个实施例中,代码(例如,可执行代码或源代码)被存储在其上存储有可执行指令的一组一个或更多个非暂时性计算机可读存储介质(或用于存储可执行指令的其他内存)上,当由计算机系统的一个或更多个处理器执行(即,由于被执行)而导致的计算机系统执行本文所述的操作。在至少一个实施例中,一组非暂时性计算机可读存储介质包括多个非暂时性计算机可读存储介质以及缺少所有代码的多个非暂时性计算机可读存储介质的一个或更多个单个非暂时性存储介质,而多个非暂时性计算机可读存储介质共同存储所有代码。在至少一个实施例中,执行可执行指令,使得不同的指令由不同的处理器执行,例如,非暂时性计算机可读存储介质存储指令,并且主中央处理单元(“cpu”)执行一些指令,而图形处理单元(“gpu”)执行其他指令。在至少一个实施例中,计算机系统的不同组件具有单独的处理器,并且不同的处理器执行指令的不同子集。
[0110]
因此,在至少一个实施例中,计算机系统被配置为实现单独地或共同地执行本文所描述的过程的操作的一个或更多个服务,并且这样的计算机系统配置有能够实现操作的适用的硬件和/或软件。此外,实现本公开的至少一个实施例的计算机系统是单个设备,并且在另一实施例中,是一种分布式计算机系统,其包括以不同方式操作的多个设备,使得分布式计算机系统执行本文所述的操作,并且使得单个设备不执行所有操作。
[0111]
本文提供的任何和所有示例或示例性语言(例如,“诸如”)的使用仅旨在更好地阐明本公开的实施例,并且不对公开的范围构成限制,除非另有声明。说明书中的任何语言都不应被解释为表示对于实施公开必不可少的任何未要求保护的要素。
[0112]
本文引用的所有参考文献,包括出版物、专利申请和专利,均以引用的方式并入本文,如同每个参考文献被单独且具体地指出以引用的方式并入本文一样。
[0113]
在描述和权利要求中,可以使用术语“耦合”和“连接”及其派生词。应当理解,这些术语可能不旨在作为彼此的同义词。相反,在特定示例中,“连接”或“耦合”可用于指示两个或更多个元件彼此直接或间接物理或电接触。“耦合”也可能意味着两个或更多个元素彼此不直接接触,但仍彼此协作或交互。
[0114]
除非另外特别说明,否则可以理解,在整个说明书中,诸如“处理”、“计算”、“运算”、“确定”等,是指计算机或计算系统的动作和/或过程。或类似的电子计算设备,将计算系统的寄存器和/或内存中表示为物理量(例如电子)的数据处理和/或转换为类似表示为计算系统的内存、寄存器或其他此类信息存储、传输或显示设备中的物理量的其他数据。
[0115]
以类似的方式,术语“处理器”可以指处理来自寄存器和/或内存的电子数据并将该电子数据转换成可以存储在寄存器和/或内存中的其他电子数据的任何设备或设备的一部分。作为非限制性示例,“处理器”可以是cpu或gpu。“计算平台”可以包括一个或更多个处理器。如本文所使用的,“软件”过程可以包括例如随时间执行工作的软件和/或硬件实体,诸如任务、线程和智能代理。而且,每个过程可以指代多个过程,以连续地或间歇地序列地
或并行地执行指令。因为系统可以体现一种或更多种方法并且方法可以被认为是系统,术语“系统”和“方法”在本文中可互换使用。
[0116]
在本文件中,可以参考获得、获取、接收或将模拟或数字数据输入子系统、计算机系统或计算机实现的机器中。可以以多种方式来完成获得、获取、接收或输入模拟和数字数据,例如通过接收作为函数调用或对应用程序接口的调用的参数的数据。在一些实施方式中,获得、获取、接收或输入模拟或数字数据的过程可以通过经由串行或并行接口传输数据来完成。在另一实施方式中,可以通过经由计算机网络将数据从提供实体传输到获取实体来完成获得、获取、接收或输入模拟或数字数据的过程。也可以参考提供、输出、传输、发送或呈现模拟或数字数据。在各种示例中,提供、输出、传输、发送或呈现模拟或数字数据的过程可以通过将数据作为函数调用的输入或输出参数,应用程序编程接口或进程间通信机制的参数进行传输来实现。
[0117]
尽管上面的讨论阐述了所描述的技术的示例实现,但是其他架构(神经网络或其他)可以用于实现所描述的功能,并且意图在本公开的范围内。此外,尽管出于讨论目的在上面定义了具体的责任分配,但是根据情况,可以以不同的方式分配和划分各种功能和职责。
[0118]
此外,尽管已经用针对结构特征和/或方法动作的语言描述了主题,但是应该理解,所附权利要求书所要求保护的主题不必限于所描述的特定特征或动作。而是,公开了特定的特征和动作作为实现权利要求的示例性形式。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1