模型的训练及其直播处理的方法、装置、设备和存储介质与流程
本发明实施例涉及图像识别技术,尤其涉及一种模型的训练及其直播处理的方法、装置、设备和存储介质。
背景技术:
随着互联网技术的爆炸式发展,各种图像、视频和直播网站如雨后春笋般涌现。人们接触到的东西也渐渐由文字变成了图像、视频或直播等更具表现力的内容。这些网站会产生大量的图像、直播视频数据,图像比文字包含更多的信息,同时也意味着更大的数据量。
以直播平台为例,主播客户端提供视频内容,直播平台通过审核人员对直播内容进行审核,当主播客户端的到达一定数量时,会产生大量的直播视频数据,因此需要大量的审核人员对视频进行审核。一般的,平台会采取事前审核与事后举报相结合的措施。即对部分有过违规行为的主播上传的直播视频进行事前审核。开通直播间的举报功能,由观众用户举报直播间主播的违规行为。
但由于某些视频内容的特殊性,一旦播出后不仅会影响观众的观感,还会造成不良的社会影响。因此对平台方的审核人员对直播内容的事前审核提出了更高的要求。但是人工审核的效率低,容易有错漏。
技术实现要素:
本发明提供一种模型的训练及其直播处理的方法、装置、设备和存储介质,以解决通过审核人员对直播内容进行人工审核效率低、有错漏的问题。
第一方面,本发明实施例提供了一种直播处理的方法,包括:
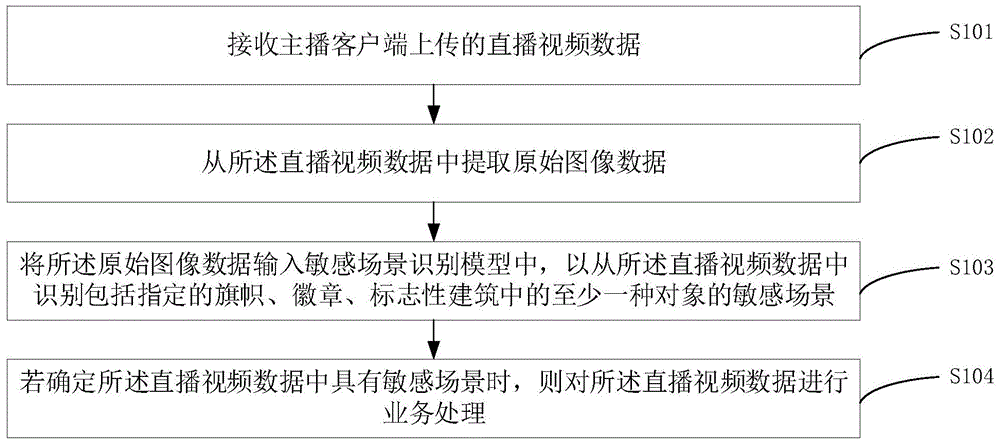
接收主播客户端上传的直播视频数据;
从所述直播视频数据中提取原始图像数据;
将所述原始图像数据输入敏感场景识别模型中,以从所述直播视频数据中识别包括指定的旗帜、徽章、标志性建筑中的至少一种对象的敏感场景;
若确定所述直播视频数据中具有敏感场景时,则对所述直播视频数据进行业务处理。
在此基础上,所述从所述直播视频数据中提取原始图像数据,包括:
确定目标时间;
每间隔所述目标时间,从所述直播视频数据中提取视频帧,以作为原始图像数据。
在此基础上,所述敏感场景识别模型包括主杆单元、第一稠密叠加单元、第二稠密叠加单元、第三稠密叠加单元、第四稠密叠加单元;
所述将所述原始图像数据输入敏感场景识别模型中,以从所述直播视频数据中识别包括指定的旗帜、徽章、标志性建筑中的至少一种数据的敏感场景,包括:
将所述原始图像数据输入主杆单元中进行降维处理,以输出第一图像向量;
将所述第一图像向量输入第一稠密叠加单元中提取第二图像向量;
将所述第二图像向量输入第二稠密叠加单元中提取第三图像向量;
将所述第三图像向量输入第三稠密叠加单元中提取第四图像向量;
将所述第四图像向量输入第四稠密叠加单元中提取第五图像向量;
基于所述第四图像向量与所述第五图像向量识别所述图像数据中具有的场景类别;
若所述场景类别为包括指定的旗帜、徽章、标志性建筑中的至少一种对象的敏感场景,则确定所述直播视频数据具有敏感场景。
在此基础上,所述基于所述第四图像向量与所述第五图像向量识别所述图像数据中具有的场景类别,包括:
计算所述第四图像向量的第一残差向量;
对所述第一残差向量进行池化操作,获得第一特征向量;
计算所述第五图像向量的第二残差向量;
对所述第二残差向量进行池化操作,获得第二特征向量;
结合所述第一特征向量与所述第二特征向量,获得目标特征向量;
对所述目标特征向量进行全连接操作,获得场景类别,所述场景类别关联概率;
基于所述概率确定所述图像数据中具有的场景类别。
在此基础上,所述对所述直播视频数据进行业务处理,包括:
确定所述直播视频数据中、所述原始图像数据中的目标区域,所述目标区域包括指定的旗帜、徽章、标志性建筑中的至少一种对象;
对所述目标区域进行模糊处理,以获得目标视频数据;
在指定的直播间发布所述目标视频数据。
在此基础上,所述对所述直播视频数据进行业务处理,包括:
确定在所述主播客户端登录的主播账号;
对所述主播账号进行封禁处理。
第二方面,本发明实施例还提供了一种敏感场景识别模型的训练方法,包括:
获取标记有场景类别的训练图像数据,所述场景类别至少具有包括指定的旗帜、徽章、标志性建筑中的至少一种的敏感场景类别;
针对直播对所述训练图像数据进行扩充;
将扩充后的训练图像数据输入至预设的敏感场景识别模型中,以预测所述训练图像数据的场景类别;
根据标记的场景类别与预测的场景类别对所述敏感场景识别模型进行更新。
在此基础上,所述针对直播对所述训练图像数据进行扩充,包括:
收集直播视频数据中的样本图像数据,所述样本图像数据不包括旗指定的旗帜、徽章、标志性建筑;
从所述训练图像数据提取表示指定的旗帜、徽章、标志性建筑中的至少一种对象的敏感图像数据;
将所述敏感图像数据与所述样本图像数据进行融合,作为新的训练图像数据。
在此基础上,所述将所述敏感图像数据与所述样本图像数据进行融合,作为新的训练图像数据,包括::
调整所述敏感图像数据的透明度;
将调整透明度之后的敏感图像数据与所述样本图像数据进行融合;
和/或,
调整所述敏感图像数据与所述样本图像数据在边界的差异;
将调整边界的差异之后的敏感图像数据与所述样本图像数据进行融合;
和/或,
将所述敏感图像数据进行运动模糊处理;
将运动模糊处理之后的敏感图像数据与所述样本图像数据进行融合;
或,
提取部分敏感图像数据;
对部分敏感图像数据进行缩放;
将缩放之后的部分敏感图像数据与所述样本图像数据进行融合。
第三方面,本发明实施例还提供了一种直播处理的装置,包括:
视频数据接收模块,用于接收主播客户端上传的直播视频数据;
原始数据提取模块,用于从所述直播视频数据中提取原始图像数据;
原始数据识别模块,用于将所述原始图像数据输入敏感场景识别模型中,以从所述直播视频数据中识别包括指定的旗帜、徽章、标志性建筑中的至少一种对象的敏感场景;
业务处理模块,用于若确定所述直播视频数据中具有敏感场景时,则对所述直播视频数据进行业务处理。
第四方面,本发明实施例还提供了一种敏感场景识别模型的训练装置,包括:
训练数据获取模块,用于获取标记有场景类别的训练图像数据,所述场景类别至少具有包括指定的旗帜、徽章、标志性建筑中的至少一种的敏感场景类别;
训练数据扩充模块,用于针对直播对所述训练图像数据进行扩充;
识别模型训练模块,用于将扩充后的训练图像数据输入至预设的敏感场景识别模型中,以预测所述训练图像数据的场景类别;
识别模型更新模块,用于根据标记的场景类别与预测的场景类别对所述敏感场景识别模型进行更新。
第五方面,本发明实施例还提供了一种电子设备,包括:
一个或多个处理器;
存储器,用于存储一个或多个程序;
当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现如第一方面所述的一种直播处理的方法,或,如第二方面所述的一种敏感场景识别模型的训练方法。
第六方面,本发明实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,其特征在于,该程序被处理器执行时实现如第一方面所述的一种直播处理的方法,或,如第二方面所述的一种敏感场景识别模型的训练方法。
本发明通过训练敏感场景识别模型,以从直播视频数据中识别包括指定的旗帜、徽章、标志性建筑中的至少一种对象的敏感场景,若确定直播视频数据中具有敏感场景时,则对直播视频数据进行业务处理的方式,通过机器模型辅助人工审核,减少了人力成本的消耗,提高对包括敏感场景的直播视频数据的准确率和辨识效率。
附图说明
图1为本发明实施例一提供的一种直播处理的方法的流程图;
图2为本发明实施例二提供的一种直播处理的方法的流程图;
图3为本发明实施例二提供的一种主干单元的结构图;
图4为本发明实施例二提供的一种稠密叠加模块的结构图;
图5为本发明实施例二提供的敏感场景识别模型的结构图;
图6为本发明实施例三提供的一种敏感场景识别模型的训练方法的流程图;
图7为本发明实施例三提供的一种神经网络的结构图;
图8为本发明实施例四提供的一种敏感场景识别模型的训练方法的流程图;
图9为本发明实施例四提供的一种获得新的训练数据的示意图;
图10为本发明实施例五提供的一种直播处理的装置;
图11为本发明实施例六提供的一种敏感场景识别模型的训练装置;
图12为本发明实施例七提供的一种电子设备的结构示意图。
具体实施方式
下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部结构。
实施例一
图1为本发明实施例一提供的一种直播处理的方法的流程图。本实施例适用于接收并识别主播客户端上传的直播视频数据中是否包括指定的旗帜、徽章、标志性建筑中的至少一种对象的敏感场景的场景。该方法可以由直播处理的装置来执行,该直播处理的装置可以由软件和/或硬件实现,可配置在计算机设备中,例如,服务器、工作站、个人电脑,等等,该方法具体包括如下步骤:
s101、接收主播客户端上传的直播视频数据。
客户端是为用户提供本地服务的程序。除了一些只在本地运行的应用程序之外,一般安装在普通的客户机上,需要与服务端互相配合运行。本实施例中的客户端可以安装在手机、平板电脑、计算机或任何一种可以配合服务器执行该方法的电子设备上。
在直播场景中,客户端可以分为主播客户端与观众客户端。主播客户端向服务器上传直播视频数据,观众客户端通过服务器观看直播视频数据。
在一可行的实现方式中,当主播客户端启动直播间的直播功能时,直播装置通过摄像设备采集主播用户的直播画面,以作为直播视频数据。
在一可行的实现方式中,当主播客户端启动直播间的直播功能时,直播装置通过录屏设备采集主播使用的直播装置的屏幕的画面,以作为直播视频数据。
应当理解的是,由于本实施例适用于主播进行直播的场景,因此在采集直播视频数据的同时,应当采集音频数据。
s102、从所述直播视频数据中提取原始图像数据。
原始图像数据是指用数值表示的各像素(pixel)的值的集合。确定原始图像数据是指将接收到直播视频数据行进处理,从中截取视频帧作为原始图像数据。
在一可行的实现方式中,按照预设的时间间隔,从直播视频数据中提取视频帧作为原始图像数据。
在一可行的实现方式中,接收观众用户对直播视频数据进行视频帧截取、获得的图像。
s103、将所述原始图像数据输入敏感场景识别模型中,以从所述直播视频数据中识别包括指定的旗帜、徽章、标志性建筑中的至少一种对象的敏感场景。
敏感场景识别模型可以是通过机器学习或者神经网络进行搭建的,本实施例对于敏感场景识别模型的搭建方式不做限制,该敏感场景识别模型用于从直播视频数据中识别包括指定的旗帜、徽章、标志性建筑中的至少一种对象的敏感场景。
其中,旗帜可以是指与敏感话题相关的旗帜,如表示国家或地区的旗帜、表示组织或团体的旗帜,等等。
徽章可以是代表国家的徽章、也可以是代表组织的徽章。
标志性建筑可以是地标性的建筑、表示国家或地区主权意识的建筑,等等。
敏感场景可以是在包含这些旗帜、徽章、标志性建筑等对象的场景中,可能会涉及一些敏感话题,比如涉及政治意识宣传的话题,等。
当然,上述对象只是作为示例,在实施本实施例时,可以根据实际情况设置其他对象,如指定的头像,用于表示与敏感话题相关的人物,本实施例对此不加以限制。另外,除了上述对象外,本领域技术人员还可以根据实际需要采用其它对象,本发明实施例对此也不加以限制。
在一种可行的实现方式中,敏感场景识别模型为cnn(convolutionalneuralnetwork,卷积神经网络)。cnn通常包含数目众多的卷积层、激活层、池化层等等。其中,每一层都将输入的数据经过层内存储的参数所表达的函数式进行计算,得到输出的数据,该输出的数据作为下一层输入的数据。
在一种可行的实现方式中,敏感场景识别模型为ann(artificialneuralnetwork,人工神经网络)。人工神经网络有多层和单层之分,每一层包含若干神经元,各神经元之间用带可变权重的有向弧连接,网络通过对已知信息的反复学习训练,通过逐步调整改变神经元连接权重的方法,达到处理信息、模拟输入输出之间关系的目的。它不需要知道输入输出之间的确切关系,不需大量参数,只需要知道引起输出变化的非恒定因素,即非常量性参数。因此与传统的数据处理方法相比,神经网络技术在处理模糊数据、随机性数据、非线性数据方面具有明显优势,对规模大、结构复杂、信息不明确的系统尤为适用。
在一种可行的实现方式中,敏感场景识别模型为svm(supportvectormachine,支持向量机)。通过训练样本建svm分类模型,并作用于测试样本输出检测结果。将提取得到的特征作为训练svm的输入样本x,将属于敏感场景或者不属于敏感场景记作为svm的输出y。(x,y)共同组成svm的训练样本对,进行svm训练。利用训练得到的svm模型,将提取得到的特征作为训练svm的输入样本x输入模型,进行识别(即原始图像数据属于敏感场景或者不属于敏感场景)。
在一种可行的实现方式中,敏感场景识别模型为逻辑回归模型。通过训练样本建立逻辑回归分类模型,并作用于测试样本输出检测结果。逻辑回归分类器(lr)的训练和分类识别。首先,将提取得到的特征作为训练lr的输入样本x,将属于敏感场景或者不属于敏感场景标记作为lr的输出y。(x,y)共同组成lr的训练样本对,进行lr训练。利用训练得到的lr模型,将提取得到的特征作为训练lr的输入样本x输入模型,进行识别(属于敏感场景或者不属于敏感场景)。
s104、若确定所述直播视频数据中具有敏感场景时,则对所述直播视频数据进行业务处理。
在本实施例中,可以预先约定内容审核规范,如果检测到直播视频数据中具有敏感场景,则可以按照该内容审核规范,对直播视频数据进行业务处理。
在一个示例中,在敏感场景中虽然出现指定的旗帜、徽章、标志性建筑等对象,但并非涉及敏感话题,则可以对具有敏感场景的直播视频数据进行处理,即模糊直播视频数据中的敏感对象、替换直播视频数据中的敏感对象。
在另一个示例中,在敏感场景中除了出现指定的旗帜、徽章、标志性建筑等对象,还涉及敏感话题,则可以对上传该直播视频数据的主播客户端登录的主播账号进行处理,即暂停向观众客户端分发该直播视频数据或者在一段时间内禁止主播账号进行直播。
当然,上述业务处理只是作为示例,在实施本实施例时,可以根据实际情况设置其他业务处理,如降低直播视频数据的排序、从而降低其曝光概率,本实施例对此不加以限制。另外,除了上述业务处理外,本领域技术人员还可以根据实际需要采用其它业务处理,本发明实施例对此也不加以限制。
本发明实施例通过训练敏感场景识别模型,以从直播视频数据中识别包括指定的旗帜、徽章、标志性建筑中的至少一种对象的敏感场景,若确定直播视频数据中具有敏感场景时,则对直播视频数据进行业务处理的方式,通过机器模型辅助人工审核,减少了人力成本的消耗,提高对包括敏感场景的直播视频数据的准确率和辨识效率。
实施例二
图2为本发明实施例二提供的一种直播处理的方法的流程图。本实施例是在实施例一的基础上进行的细化,详细描述了敏感场景识别模型的结构和识别出敏感场景的方法。该方法具体包括如下步骤:
s201、接收主播客户端上传的直播视频数据。
s202、确定目标时间。
目标时间是指从直播视频数据中、获取视频帧的时间间隔。如果目标时间设置得过短、会加重敏感场景识别模型的数据量、需要更高效的硬件进行支撑;如果目标时间设置得过长、虽然可以减轻敏感场景识别模型的数据量、但是可能造成对敏感场景的识别漏失。
可选的,将目标时间设定为2秒或者3秒。
s203、每间隔所述目标时间,从所述直播视频数据中提取视频帧,以作为原始图像数据。
具体的,每间隔2秒或3秒时间,从视频直播数据中提取视频帧,将该视频帧作为原始图像数据。
s204、将所述原始图像数据输入主杆单元中进行降维处理,以输出第一图像向量。
主干单元对输入图像进行初步的特征提取以及宽高降维操作。主干单元不同于利用高计算量进行降维操作的网络结构,例如resnet等利用7x7的卷积核进行特征降维,本实施例中所设计的主杆单元利用卷积操作与池化操作并行的方式进行特征降维,减少了计算量,加快了模型推断速度。
主干单元接收原始图像数据,进行第一次卷积,将第一次卷积的结果分为两部分进行处理,一部分继续进行卷积处理,一部分进行池化处理;将这两部分处理的结果进行拼接,将拼接结果输入卷积层进行处理,以获得第一图像向量。
具体的,图3为本发明实施例二提供的一种主干单元的结构图。该主干单元接收(input)原始图像数据,将该原始图像数据输入第一卷积层31,该第一卷积层31包括32种3×3的卷积核(core),步长(stride)为2。将经过该卷积层处理之后的数据分别输入第一分支与第二分支,第一分支包括两个顺序连接的卷积层(按照顺序依次记为第二卷积层32和第三卷积层33),第二卷积层32包括16种1×1的卷积核,步长(stride)为1、第三卷积层33包括32种3×3的卷积核,步长(stride)为2;第二分支包括一个最大池化层34,该最大池化层34包括2×2的核,步长(stride)为2。将经过第一分支与第二分支处理的向量输入滤波器级联层35(filterconcatenate)进行融合。将融合后的结果输入第四卷积层36,该第四卷积层36包括32种1×1的卷积核(core),步长(stride)为1,将第四卷积层输出的结果作为第一图像向量。
s205、将所述第一图像向量输入第一稠密叠加单元中提取第二图像向量。
s206、将所述第二图像向量输入第二稠密叠加单元中提取第三图像向量。
s207、将所述第三图像向量输入第三稠密叠加单元中提取第四图像向量。
s208、将所述第四图像向量输入第四稠密叠加单元中提取第五图像向量。
步骤s205-s208描述了通过稠密叠加单元不断对第一图像向量进行降维处理的过程,直到依次经过第一稠密叠加单元、第二稠密叠加单元、第三稠密叠加单元和第四稠密叠加单元的处理,获得第五图像向量。
在一种可行的实现方式中,稠密叠加模块接收特征向量后进行卷积处理,将进行卷积处理的结果与未做处理的特征向量进行融合,作为该稠密叠加模块输出的特征向量。
在一种可行的实现方式中,稠密叠加模块接收特征向量后,将该特征向量复制为三部分,第一部分不做处理,第二部分进行卷积处理,第三部分采用不同于第二部分的方式进行卷积处理,将第一部分、处理后的第二部分和处理后的第三部分的特征向量进行融合,作为该稠密叠加模块输出的特征向量。这种实现方式将一条厚度较大的分支改为两条厚度较小的分支组成,增加多了一条由卷积层串联在一起的分支,达到了拓宽了感受野(receptivefield),降低网络复杂度的目的。
具体的,图4为本发明实施例二提供的一种稠密叠加模块的结构图。该稠密叠加模块的前馈层41(previouslayer)接收特征向量后,将该特征向量复制为三部分。一部分依次输入拥有3×3的卷积核、步长(stride)为2k(k为一个自然数)的第五卷积层42和拥有3×3的卷积核、步长(stride)为k/2的第六卷积层43。一部分依次输入拥有1×1的卷积核、步长(stride)为2k的第七卷积层44和拥有3×3的卷积核、步长(stride)为k/2的第八卷积层45和拥有3×3的卷积核、步长(stride)为k/2的第九卷积层46。将第一部分、处理后的第二部分和处理后的第三部分的特征向量输入滤波器级联层47(filterconcatenate)进行融合,以输出特征向量。
具体的,在一可行的实现方式中,每个稠密叠加单元包括不同数量的稠密叠加模块。如第一稠密叠加单元设置为包括3个稠密叠加模块、第二稠密叠加单元设置为包括4个稠密叠加模块设置为包括8个稠密叠加模块、第三稠密叠加单元和第四稠密叠加单元设置为包括6个稠密叠加模块。
将第一图像向量输入包括3个稠密叠加模块第一稠密叠加单元中提取第二图像向量。将第二图像向量输入包括4个稠密叠加模块的第二稠密叠加单元中提取第三图像向量。将三图像向量输入包括8个稠密叠加模块的第三稠密叠加单元中提取第四图像向量。将第四图像向量输入包括6个稠密叠加模块的第四稠密叠加单元中提取第五图像向量。
在稠密叠加单元中设置不同数量的稠密叠加模块可以使得每一次降维处理侧重于第一图像向量的不同维度,能够极大限度的保留第一图像向量的不同维度的特征。
s209、基于所述第四图像向量与所述第五图像向量识别所述图像数据中具有的场景类别。
经典的分类网络一般都是利用特征提取网络的头部作为分类操作的特征输入(即本实施例中的第五图像向量),但由于直播场景中可能会出现类似新闻弹窗等小目标的场景,若只利用最高阶的语义信息(即第五图像向量),就不一定能达到高置信度的识别,从而达到推送给人工审核的目标要求。为了提高对小目标的识别能力,不仅利用第五图像向量的特征进行目标分类,还利用了拥有相对丰富细粒度信息的第四图像向量的特征进行分类特征提取。利用残差模块和全局平均池化操作得到各自对应特征向量,对两个向量进行拼接,最后根据拼接后的特征向量识别场景类别。
在一可行的实现方式中,该步骤包括下列子步骤:
s2091、计算所述第四图像向量的第一残差向量。
s2092、对所述第一残差向量进行池化操作,获得第一特征向量。
s2093、计算所述第五图像向量的第二残差向量。
s2094、对所述第二残差向量进行池化操作,获得第二特征向量。
s2095、结合所述第一特征向量与所述第二特征向量,获得目标特征向量。
s2096、对所述目标特征向量进行全连接操作,获得场景类别,所述场景类别关联概率。
s2097、基于所述概率确定所述图像数据中具有的场景类别。
残差向量可以通过残差神经网络提取,残差神经网络是指可以获得残差数据的学习网络。两个残差学习网络分支表示两个以上的残差学习网络分支独立对各自输入的数据进行处理,独立获得残差数据。
池化操作的作用在于可以保留主要的特征,同时减少下一层的参数和计算量,防止过拟合;保持某种不变性,包括translation(平移),rotation(旋转),scale(尺度),常用的有平均池化操作和最大池化操作。
结合第一特征向量与第二特征向量的方式可以是通过全连接层(fullconnect,fc)来实现,全连接层可以起到将学到的“分布式特征表示”映射到样本标记空间的作用。
s210、若所述场景类别为包括指定的旗帜、徽章、标志性建筑中的至少一种对象的敏感场景,则确定所述直播视频数据具有敏感场景。
具体的,图5为本发明实施例二提供的敏感场景识别模型的结构图。该敏感场景识别模型包括依次连接的主干单元51、第一稠密叠加单元521、第二稠密叠加单元522、第三稠密叠加单元523、第四稠密叠加单元524、第一残差模块531、第二残差模块532、第一池化模块541、第二池化模块542、第一场景类别、第一特征向量551、第二特征向量552、目标特征向量56和场景类别57。
主干单元51接收原始图像数据(picture)后,进行第一次卷积,将第一次卷积的结果分为两部分进行处理,一部分继续进行卷积处理,一部分进行池化处理;将这两部分处理的结果进行拼接,将拼接结果输入卷积层进行处理,以获得第一图像向量。将第一图像向量输入包括3个稠密叠加模块第一稠密叠加单元521中提取第二图像向量。将第二图像向量输入包括4个稠密叠加模块的第二稠密叠加单元522中提取第三图像向量。将三图像向量输入包括8个稠密叠加模块的第三稠密叠加单元523中提取第四图像向量。将第四图像向量输入包括6个稠密叠加模块的第四稠密叠加单元524中提取第五图像向量。
通过第二残差模块532计算第四图像向量的第一残差向量。通过第二池化模块542对第一残差向量进行池化操作,获得第一特征向量551。通过第一残差模块531计算所述第五图像向量的第二残差向量。通过第一池化模块541对第二残差向量进行池化操作,获得第二特征向量552。s2095、结合所述第一特征向量551与所述第二特征向量552,获得目标特征向量56。场景类别57包括敏感场景571与非敏感场景572。通过全连接层起到将目标特征向量56映射到敏感场景571与非敏感场景572的作用。
使用敏感场景识别模型可以降低模型计算量,降低模型参数的设置同时增加模型的精确度。
s211、确定所述直播视频数据中、所述原始图像数据中的目标区域,所述目标区域包括指定的旗帜、徽章、标志性建筑中的至少一种对象。
s212、对所述目标区域进行模糊处理,以获得目标视频数据。
s213、在指定的直播间发布所述目标视频数据。
目标区域是指包括指定的旗帜、徽章、标志性建筑中的至少一种对象的区域。一般的,可以选取对象的轮廓点,在轮廓点的基础上向外均匀扩张一部分,将扩张后的区域作为目标区域。
进行模糊处理的方式可以是对目标区域进行高斯迷糊等,也可以是使用带模糊效果的蒙版对目标区域进行遮挡。将进行模糊处理后的直播视频数据作为目标视频数据。
使用目标视频数据替换直播视频数据,在该直播视频数据关联的直播间中进行发布,以使订阅该直播间的观众客户端可以接收到目标视频数据。
步骤s211-s213描述了通过模糊局部的方式对直播视频数据进行业务处理的方式。这样的处理方式一般适用于直播视频数据中偶然出现指定的旗帜、徽章、标志性建筑中的至少一种对象的情况。如主播家为了迎接节日放置了一面指定的旗帜,在直播时,该指定的旗帜出现在摄像头的采集范围中,此时可以通过模糊局部的方式对直播视频数据的指定的旗帜进行模糊处理。这样不需要对直播间的直播视频进行停止分发的操作,使得观众用户具有流场的观看体验。
s214、确定在所述主播客户端登录的主播账号。
s215、对所述主播账号进行封禁处理。
步骤s214-s215描述了通过封禁处理的方式对主播客户端登录的主播账号进行业务处理的方式。这样的处理方式一般适用于直播视频数据中长时间或者大面积的出现指定的旗帜、徽章、标志性建筑中的至少一种对象的情况。如主播为了宣传某些思想,使用了指定的旗帜,在直播时,该指定的旗帜出现在摄像头的采集范围中,此时可以通过对直播间的直播视频进行停止分发的操作,减少该主播对观众的影响。同时对主播账号进行封禁处理,从根本上杜绝某些思想的传播。
步骤s211-s213与步骤s214-s215分别是对直播视频数据进行业务处理的方式,可以择一使用、也可以组合使用,但是在使用时没有顺序关系。
实施例三
图6为本发明实施例三提供的一种敏感场景识别模型的训练方法的流程图。本实施例适用于对标记有场景类别的训练图像数据进行扩展后,训练预设的敏感场景识别模型的场景。该方法可以由敏感场景识别模型的训练装置来执行,该敏感场景识别模型的训练装置可以由软件和/或硬件实现,可配置在计算机设备中,例如,服务器、工作站、个人电脑,等等,该方法具体包括如下步骤:
s301、获取标记有场景类别的训练图像数据,所述场景类别至少具有包括指定的旗帜、徽章、标志性建筑中的至少一种的敏感场景类别。
具体的,可以通过爬虫工具在提供图片的网站或者社交论坛上爬取包括指定的旗帜、徽章、标志性建筑中的至少一种的图片。在视频网站中下载包括指定的旗帜、徽章、标志性建筑中的至少一种的视频,并从中提取视频帧作为图片。
对图片进行标记处理,将标记后的图片与标记结果一起作为训练图像数据。一般的,训练图像数据包括正数据与负数据,正数据指场景类别至少具有包括指定的旗帜、徽章、标志性建筑中的至少一种的敏感场景类别的图片及其标注。负数据则是不包括指定的旗帜、徽章、标志性建筑中任何一种的图片及其标注。一般的,正数据可以标注为敏感场景,负数据可以标注为非敏感场景。
s302、针对直播对所述训练图像数据进行扩充。
与一般的视频数据相比,直播视频数据具有其特殊性。尤其是主播是通过录屏软件对直播装置的屏幕进行录制,作为直播视频数据时,需要考虑桌面背景和弹窗的情况。需要对训练图像数据加入人工合成的图片,扩充训练图像数据,增加鲁棒性与泛化性。
对此,首先从收集的具有指定的旗帜、徽章、标志性建筑代表性的一部分图片中,对指定的旗帜、徽章、标志性建筑进行像素级别精细化的抠取。再收集一批直播中出现的正常直播场景图像,对这两部分进行随机的融合,得到一批合成图像样本。
s303、将扩充后的训练图像数据输入至预设的敏感场景识别模型中,以预测所述训练图像数据的场景类别。
s304、根据标记的场景类别与预测的场景类别对所述敏感场景识别模型进行更新。
步骤s303-s304描述了训练与优化敏感场景识别模型的方法。
预设的敏感场景识别模型可以是通过深度学习的理论构建的神经网络模型。深度学习中的神经网络通常由不同功能的层构成,以计算机视觉中使用的cnn(convolutionalneuralnetwork,卷积神经网络)为例,cnn通常包含数目众多的卷积层、激活层、池化层等等。
其中,每一层都将输入的数据经过层内存储的参数所表达的函数式进行计算,得到输出的数据,该输出的数据作为下一层输入的数据。
因此,如图7所示,神经网络可以看作是一种函数映射,而神经网络的训练过程是一个函数优化求解的过程。优化求解的目标就是不断更新该神经网络所包含的参数,将已标注的样本作为输入的数据,经过神经网络的计算,输出的数据和标注之间的损失值最小。神经网络训练的过程就是参数更新的过程:计算目标函数在当前参数的梯度方向,然后根据损失值和学习速率,计算参数的更新幅度,在梯度相反方向更新参数。
本发明实施例通过获取标记有场景类别的训练图像数据,并对训练图像数据进行扩充的方式扩大了训练图像数据的数量。针对直播对训练图像数据进行扩充,可以有效的应对直播场景复杂多样,而且面对的出现情况比较复杂的情况。
实施例四
图8为本发明实施例四提供的一种敏感场景识别模型的训练方法的流程图。本实施例是在实施例三的基础上进行的细化,详细描述了针对直播对训练图像数据进行扩充的具体方法。
该方法具体包括如下步骤:
s401、获取标记有场景类别的训练图像数据,所述场景类别至少具有包括指定的旗帜、徽章、标志性建筑中的至少一种的敏感场景类别。
s402、收集直播视频数据中的样本图像数据,所述样本图像数据不包括旗指定的旗帜、徽章、标志性建筑。
从直播视频数据中、收集可以代表直播场景的图片。尤其是包括桌面背景、弹出窗口、主播背景等的图片。当然,这些图片中不包括旗指定的旗帜、徽章、标志性建筑。
s403、从所述训练图像数据提取表示指定的旗帜、徽章、标志性建筑中的至少一种对象的敏感图像数据。
对训练图像数据中包括的指定的旗帜、徽章、标志性建筑中进行抠图处理,以获得不同场景下、指定的旗帜、徽章、标志性建筑这些敏感图像数据的不同表现形式。
s404、将所述敏感图像数据与所述样本图像数据进行融合,作为新的训练图像数据。
将不同场景下、指定的旗帜、徽章、标志性建筑的不同表现形式与从直播视频数据中、收集可以代表直播场景的图片进行融合,以获的新的训练数据。
图9为本发明实施例四提供的一种获得新的训练数据的示意图。标记有场景类别的训练图像数据61中的敏感图像数据62被抠取。将该被抠取的敏感图像数据与从直播视频数据中、收集可以代表直播场景的图片63进行融合,以获得新的训练图像数据64。
在一可行的实现方式中,进行融合的方式包括基于透明度的融合、基于插入边界平缓的融合、基于抖动模糊的融合和基于局部插入的融合。
上述敏感图像数据与样本图像数据进行融合的方式是基于一定的概率触发,有可能新的训练图像数据有多种合成方式,亦有可能新的训练图像数据只包括一种合成方式。
其中,基于透明度的融合可以是调整敏感图像数据的透明度,将调整透明度之后的敏感图像数据与所述样本图像数据进行融合。具体的,可以通过把rgb格式的敏感图像数据转化为rgba格式,调成alpha通道从而改变敏感图像数据的透明度,再与所述样本图像数据进行融合。
其中,基基于插入边界平缓的融合可以是调整敏感图像数据与样本图像数据在边界的差异,将调整边界的差异之后的敏感图像数据与样本图像数据进行融合。具体的,泊松分布适合于描述单位时间(或空间)内随机事件发生的次数。利用泊松方程,调整敏感图像数据与样本图像数据边界像素的差异,让敏感图像数据与样本图像数据无缝融合在一起,减少融合边界的差异性,让融合后的图像更为自然。
其中,基于抖动模糊的融合可以是将所述敏感图像数据进行运动模糊处理,将运动模糊处理之后的敏感图像数据与样本图像数据进行融合。由于直播场景中的秀场场景大多是利用手机户外拍摄,画面通常是运动甚至抖动的,而且挥舞指定的旗帜等场景也会造成画面的剧烈运动。因此在数据合成中,加入了运动模糊,增强数据集的泛化能力。
其中,基于局部插入的融合可以是将部分敏感图像数据进行缩放,将缩放之后的部分敏感图像数据与所述样本图像数据进行融合。直播中出现的弹窗,或者小区域出现敏感图像数据,又或者只出现一部分的敏感图像数据,例如出现折叠的指定的旗帜、露出一部分的徽章等等,这都是直播中经常遇到的案例,因此对合成数据,加入一定的图像变化以及裁剪是十分有必要的。
s405、将扩充后的训练图像数据输入至预设的敏感场景识别模型中,以预测所述训练图像数据的场景类别。
s406、根据标记的场景类别与预测的场景类别对所述敏感场景识别模型进行更新。
实施例五
图10为本发明实施例五提供的一种直播处理的装置,包括:视频数据接收模块51、原始数据提取模块52、原始数据识别模块53和业务处理模块54。其中:
视频数据接收模块51,用于接收主播客户端上传的直播视频数据;
原始数据提取模块52,用于从所述直播视频数据中提取原始图像数据;
原始数据识别模块53,用于将所述原始图像数据输入敏感场景识别模型中,以从所述直播视频数据中识别包括指定的旗帜、徽章、标志性建筑中的至少一种对象的敏感场景;
业务处理模块54,用于若确定所述直播视频数据中具有敏感场景时,则对所述直播视频数据进行业务处理。
本发明实施例通过训练敏感场景识别模型,以从直播视频数据中识别包括指定的旗帜、徽章、标志性建筑中的至少一种对象的敏感场景,若确定直播视频数据中具有敏感场景时,则对直播视频数据进行业务处理的方式,通过机器模型辅助人工审核,减少了人力成本的消耗,提高对包括敏感场景的直播视频数据的准确率和辨识效率。
在上述实施例的基础上,原始数据提取模块52包括:
目标时间确定子模块,用于确定目标时间;
视频帧提取子模块,用于每间隔所述目标时间,从所述直播视频数据中提取视频帧,以作为原始图像数据。
在上述实施例的基础上,所述敏感场景识别模型包括主杆单元、第一稠密叠加单元、第二稠密叠加单元、第三稠密叠加单元、第四稠密叠加单元,原始数据识别模块53包括:
降维处理子模块,用于将所述原始图像数据输入主杆单元中进行降维处理,以输出第一图像向量;
第二图像向量提取子模块,用于将所述第一图像向量输入第一稠密叠加单元中提取第二图像向量;
第三图像向量提取子模块,用于将所述第二图像向量输入第二稠密叠加单元中提取第三图像向量;
第四图像向量提取子模块,用于将所述第三图像向量输入第三稠密叠加单元中提取第四图像向量;
第五图像向量提取子模块,用于将所述第四图像向量输入第四稠密叠加单元中提取第五图像向量;
场景类别识别子模块,用于基于所述第四图像向量与所述第五图像向量识别所述图像数据中具有的场景类别;
敏感场景确定子模块,用于若所述场景类别为包括指定的旗帜、徽章、标志性建筑中的至少一种对象的敏感场景,则确定所述直播视频数据具有敏感场景。
在上述实施例的基础上,场景类别识别子模块包括:
第一残差向量计算单元,用于计算所述第四图像向量的第一残差向量;
第一特征向量获取单元,用于对所述第一残差向量进行池化操作,获得第一特征向量;
第二残差向量计算单元,用于计算所述第五图像向量的第二残差向量;
第二特征向量获取单元,用于对所述第二残差向量进行池化操作,获得第二特征向量;
目标特征向量获取单元,用于结合所述第一特征向量与所述第二特征向量,获得目标特征向量;
场景概率确定单元,用于对所述目标特征向量进行全连接操作,获得场景类别,所述场景类别关联概率;
场景类别确定单元,用于基于所述概率确定所述图像数据中具有的场景类别。
在上述实施例的基础上,业务处理模块54包括:
目标区域确定子模块,用于确定所述直播视频数据中、所述原始图像数据中的目标区域,所述目标区域包括指定的旗帜、徽章、标志性建筑中的至少一种对象;
目标视频数据获取子模块,用于对所述目标区域进行模糊处理,以获得目标视频数据;
目标视频数据发布子模块,用于在指定的直播间发布所述目标视频数据。
在上述实施例的基础上,业务处理模块54包括:
主播账号确定子模块,用于确定在所述主播客户端登录的主播账号;
封禁处理子模块,用于对所述主播账号进行封禁处理。
本实施例提供的一种直播处理的装置可用于执行上述任一实施例提供的一种直播处理的方法,具有相应的功能和有益效果。
实施例六
图11为本发明实施例六提供的一种敏感场景识别模型的训练装置,包括:训练数据获取模块61、训练数据扩充模块62、识别模型训练模块63和识别模型更新模块64。其中:
训练数据获取模块61,用于获取标记有场景类别的训练图像数据,所述场景类别至少具有包括指定的旗帜、徽章、标志性建筑中的至少一种的敏感场景类别;
训练数据扩充模块62,用于针对直播对所述训练图像数据进行扩充;
识别模型训练模块63,用于将扩充后的训练图像数据输入至预设的敏感场景识别模型中,以预测所述训练图像数据的场景类别;
识别模型更新模块64,用于根据标记的场景类别与预测的场景类别对所述敏感场景识别模型进行更新。
本发明实施例通过获取标记有场景类别的训练图像数据,并对训练图像数据进行扩充的方式扩大了训练图像数据的数量。针对直播对训练图像数据进行扩充,可以有效的应对直播场景复杂多样,而且面对的出现情况比较复杂的情况。
在上述实施例的基础上,训练数据扩充模块62包括:
样本数据收集子模块,用于收集直播视频数据中的样本图像数据,所述样本图像数据不包括旗指定的旗帜、徽章、标志性建筑;
对象提取子模块,用于从所述训练图像数据提取表示指定的旗帜、徽章、标志性建筑中的至少一种对象的敏感图像数据;
数据融合子模块,用于将所述敏感图像数据与所述样本图像数据进行融合,作为新的训练图像数据。
在上述实施例的基础上,数据融合子模块包括:
透明度融合单元,用于调整所述敏感图像数据的透明度;将调整透明度之后的敏感图像数据与所述样本图像数据进行融合;
和/或,
插入融合单元,用于调整所述敏感图像数据与所述样本图像数据在边界的差异;将调整边界的差异之后的敏感图像数据与所述样本图像数据进行融合;
和/或,
模糊融合单元,用于将所述敏感图像数据进行运动模糊处理;将运动模糊处理之后的敏感图像数据与所述样本图像数据进行融合;
和/或,
局部融合单元,用于对部分敏感图像数据进行缩放;将缩放之后的部分敏感图像数据与所述样本图像数据进行融合。
本实施例提供的一种敏感场景识别模型的训练装置可用于执行上述任一实施例提供的一种敏感场景识别模型的训练方法,具有相应的功能和有益效果。
实施例七
图12为本发明实施例七提供的一种电子设备的结构示意图。如图12所示,该电子设备包括处理器70、存储器71、通信模块72、输入装置73和输出装置74;电子设备中处理器70的数量可以是一个或多个,图12中以一个处理器70为例;电子设备中的处理器70、存储器71、通信模块72、输入装置73和输出装置74可以通过总线或其他方式连接,图12中以通过总线连接为例。
存储器71作为一种计算机可读存储介质,可用于存储软件程序、计算机可执行程序以及模块,如本实施例中的一种直播处理的方法对应的模块(例如,一种直播处理的装置中的视频数据接收模块51、原始数据提取模块52、原始数据识别模块53和业务处理模块54)。又如本实施例中的一种敏感场景识别模型的训练方法对应的模块(例如,一种敏感场景识别模型的训练装置中的训练数据获取模块61、训练数据扩充模块62、识别模型训练模块63和识别模型更新模块64)。
处理器70通过运行存储在存储器71中的软件程序、指令以及模块,从而执行电子设备的各种功能应用以及数据处理,即实现上述的一种直播处理的方法,或者,一种敏感场景识别模型的训练方法。
存储器71可主要包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需的应用程序;存储数据区可存储根据电子设备的使用所创建的数据等。此外,存储器71可以包括高速随机存取存储器,还可以包括非易失性存储器,例如至少一个磁盘存储器件、闪存器件、或其他非易失性固态存储器件。在一些实例中,存储器71可进一步包括相对于处理器70远程设置的存储器,这些远程存储器可以通过网络连接至电子设备。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
通信模块72,用于与显示屏建立连接,并实现与显示屏的数据交互。输入装置73可用于接收输入的数字或字符信息,以及产生与电子设备的用户设置以及功能控制有关的键信号输入。
本实施例提供的一种电子设备,可执行本发明任一实施例提供的一种直播处理的方法,或者,一种敏感场景识别模型的训练方法,具体相应的功能和有益效果。
实施例八
本发明实施例八还提供一种包含计算机可执行指令的存储介质,所述计算机可执行指令在由计算机处理器执行时用于执行一种直播处理的方法,该方法包括:
接收主播客户端上传的直播视频数据;
从所述直播视频数据中提取原始图像数据;
将所述原始图像数据输入敏感场景识别模型中,以从所述直播视频数据中识别包括指定的旗帜、徽章、标志性建筑中的至少一种对象的敏感场景;
若确定所述直播视频数据中具有敏感场景时,则对所述直播视频数据进行业务处理。
或者,用于执行一种敏感场景识别模型的训练方法,该方法包括:
获取标记有场景类别的训练图像数据,所述场景类别至少具有包括指定的旗帜、徽章、标志性建筑中的至少一种的敏感场景类别;
针对直播对所述训练图像数据进行扩充;
将扩充后的训练图像数据输入至预设的敏感场景识别模型中,以预测所述训练图像数据的场景类别;
根据标记的场景类别与预测的场景类别对所述敏感场景识别模型进行更新。
当然,本发明实施例所提供的一种包含计算机可执行指令的存储介质,其计算机可执行指令不限于如上所述的方法操作,还可以执行本发明任一实施例所提供的一种直播处理的方法,或者,一种敏感场景识别模型的训练方法中的相关操作。
通过以上关于实施方式的描述,所属领域的技术人员可以清楚地了解到,本发明可借助软件及必需的通用硬件来实现,当然也可以通过硬件实现,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在计算机可读存储介质中,如计算机的软盘、只读存储器(read-onlymemory,rom)、随机存取存储器(randomaccessmemory,ram)、闪存(flash)、硬盘或光盘等,包括若干指令用以使得一台计算机电子设备(可以是个人计算机,服务器,或者网络电子设备等)执行本发明各个实施例所述的方法。
值得注意的是,上述一种直播处理的装置,或者,一种敏感场景识别模型的训练装置的实施例中,所包括的各个单元和模块只是按照功能逻辑进行划分的,但并不局限于上述的划分,只要能够实现相应的功能即可;另外,各功能单元的具体名称也只是为了便于相互区分,并不用于限制本发明的保护范围。
注意,上述仅为本发明的较佳实施例及所运用技术原理。本领域技术人员会理解,本发明不限于这里所述的特定实施例,对本领域技术人员来说能够进行各种明显的变化、重新调整和替代而不会脱离本发明的保护范围。因此,虽然通过以上实施例对本发明进行了较为详细的说明,但是本发明不仅仅限于以上实施例,在不脱离本发明构思的情况下,还可以包括更多其他等效实施例,而本发明的范围由所附的权利要求范围决定。
- 还没有人留言评论。精彩留言会获得点赞!